本章内容
1、模块简介
2、把模块当做脚本执行
3、模块的寻找
4、python 包
5、编译python文件
6、json & pickle
7、shelve 模块
8、time & datetime
9、random 模块
10、os 模块
11、sys 模块
12、shutil 模块
13、configparser 模块
14、hashlib 模块
15、re 模块
16、paramiko
17、logging
模块简介
模块的分类
1、标准库
2、开源模块
3、自定一模块
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。但其实import加载的模块分为四个通用类别:
1、 使用python编写的代码(.py文件)
2 、已被编译为共享库或DLL的C或C++扩展
3 、包好一组模块的包
4 、使用C编写并链接到python解释器的内置模块
导入模块的本质就是把python文件解释一遍
导入包的本质就是执行该包下的__init__.py文件
python中多次导入某个模块,并不会在内存中加载多次,而是直接读取内存当中的import spam #导入这个模块后就会运行此模块,并放置到内存中,详细的解释如下:
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句)
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
实例文件:spam.py, 文件spam.py,模块名spam


print('from the spam.py') money=1000 def read1(): print('spam->read1->money',money) def read2(): print('spam->read2 calling read') read1() def change(): global money money=0
测试一:money与spam.money不冲突
import spam money=10 print(spam.money) ''' 执行结果: from the spam.py 1000 '''
测试二:read1与spam.read1不冲突
import spam def read1(): print('========') spam.read1() ''' 执行结果: from the spam.py spam->read1->money 1000 '''
测试三:执行spam.change()操作的全局变量money仍然是spam中的
import spam money=1 spam.change() print(money) ''' 执行结果: from the spam.py 1 '''
其实这说明了什么,说明了模块干模块的事,不受你调用者的影响。
1.为模块名起别名,相当于m1=1;m2=m1
1 import spam as sm 2 print(sm.money)
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如
1 if file_format == 'xml': 2 import xmlreader as reader 3 elif file_format == 'csv': 4 import csvreader as reader 5 data=reader.read_date(filename)
2. 在一行导入多个模块
1 import sys,os,re
3.from spam import read1,read2
单项导入进来函数的变量不会被当前环境中定义重复的变量所冲突,还是引用自己的? 如果当前环境中的函数有和调用的重名的,则当前的函数会覆盖调用来的函数,
下面上小丽:
#测试一:导入的函数read1,执行时仍然回到spam.py中寻找全局变量money #test.py from spam import read1 money=1000 read1() ''' 执行结果: from the spam.py spam->read1->money 1000 '''
#测试二:导入的函数read2,执行时需要调用read1(),仍然回到spam.py中找read1()
#test.py
from spam import read2
def read1():
print('==========')
read2()
'''
执行结果:
from the spam.py
spam->read2 calling read
spam->read1->money 1000
'''
#测试三:导入的函数read1,被当前位置定义的read1覆盖掉了
#test.py
from spam import read1
def read1():
print('==========')
read1()
'''
执行结果:
from the spam.py
==========
'''
需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系,如下:
理解吗?,我还没有理解,先看小丽吧
1 from spam import money,read1 2 money=100 #将当前位置的名字money绑定到了100 3 print(money) #打印当前的名字 4 read1() #读取spam.py中的名字money,仍然为1000 5 6 ''' 7 from the spam.py 8 100 9 spam->read1->money 1000 10 '''
4. 也支持as
1 from spam import read1 as read
5. 也支持导入多行
1 from spam import (read1, 2 read2, 3 money)
6.from spam import *
*你肯定想是全部的意思,那和import spam 有什么区别呢?当然会有区别的!
区别:import spam会把spam中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用__all__来控制*(用来发布新版本)
在spam.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
小知识点:
考虑到性能的原因,每个模块只被导入一次,放入字典sys.module中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块。 如果只是测试环境下,那可以使用importlib.reload()的方法去reload,后面自己研究吧,还不知道咋用
把模块当做脚本执行
运行python脚本有两种方式:
1.直接python a.py
2.import a
这两种有何区别呢?
在spam.py中添加 print (__name__),打印出来的结果是什么?是 __main__
下面再在其他脚本中import spam,运行打印出来的结果是什么? 是 spam
总结一下:
当做脚本运行时 __name__ 等于 ‘__main__’
当做模块运行时 __name__ 等于 ‘spam’
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
print ('文件被当做脚本执行时出发的代码,可以用于函数功能的测试,别人在导入模块的时候测试代码是不会被执行的')
模块的寻找
当import模块的时候,这个模块的查找顺序:
1.首先在内置中查找,(built-in)
2.然后去sys.path目录中去找, 其中的 ‘ ’表示当前的目录,这个sys.path的value中是可以append、insert,其他的环境路径的。查找顺序是从头到位,如有重复,第一个生效。
至于.egg文件是由setuptools创建的包,这是按照第三方python库和扩展时使用的一种常见格式,.egg文件实际上只是添加了额外元数据(如版本号,依赖项等)的.zip文件。
关系目录如下:

以上图的关系为例,在aa.py 中导入父级目录下的bb模块,则需要把祖父级的目录添加到环境变量中,如下:
import sys,os mulu = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.insert(0,mulu)
import bb
如果想在aa.py中导入modes目录下的bb模块,则需要把祖父级的目录添加到环境变量中,然后 from modes import bb
包的寻找
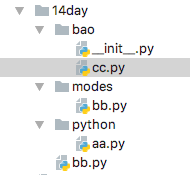
现在需要在aa.py中导入bao中的cc模块。
1、在bao的__init__.py中 写入 from . import cc
2、添加14day的路径到环境变量中
3、在aa.py中import bao
4、在aa.py中调用cc中的Iambao函数, bao.cc.Iambao()
导入的优化
import modes
然后下面
modes.func()
modes.func()
..........
这样引用的话效率不高,优化方法直接 from modes import func ,然后再直接调用func的方法
python 包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
关于包相关的导入语句也分为import和from ... import ...两种
注意事项:
需要遵循的原则
1.凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,
如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
import

from ... import ...
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,
如:from a import b.c是错误语法
from glance.api import policy
policy.get()
__init__.py 文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有*。此处是想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件
中定义__all___:

1 #在__init__.py中定义
2 x=10
3
4 def func():
5 print('from api.__init.py')
6
7 __all__=['x','func','policy']
此时我们在于glance同级的文件中执行from glance.api import *就导入__all__中的内容
再运行如下代码时就会生效了
from glance.api import *
policy.get()
print(x)
编译python文件
为了提高模块的加载速度,Python缓存编译的版本,每个模块在__pycache__目录的以module.version.pyc的形式命名,通常包含了python的版本号,如在CPython版本3.3,关于spam.py的编译版本将被缓存成
__pycache__/spam.cpython-33.pyc,这种命名约定允许不同的版本,不同版本的Python编写模块共存。Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
提示:
1.模块名区分大小写,foo.py与FOO.py代表的是两个模块
2.你可以使用-O或者-OO转换python命令来减少编译模块的大小
1 -O转换会帮你去掉assert语句 2 -OO转换会帮你去掉assert语句和__doc__文档字符串 3 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。
3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才
是更快的
4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,
因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件
2 3 python -m compileall /module_directory 递归着编译 4 如果使用python -O -m compileall /module_directory -l则只一层 5 6 命令行里使用compile()函数时,自动使用python -O -m compileall 7 8 详见:https://docs.python.org/3/library/compileall.html#module-compileall
Json & pickle
用于序列化的两个模块
- json, 用于字符串和python数据类型间进行转换
- pickle,用于python特有的类型和python的数据类型之间的转换
Json模块提供了四个功能: dumps、dump 、loads 、load
pickle模块提供了四个功能: dumps 、dump 、loads 、load
json 序列化与反序列化的两种形式
1 序列化: 2 import json 3 4 data = {'k1':'python','k2':'nihao'} 5 6 with open('abc','w') as f: 7 f.write(json.dumps(data)) 8 9 10 反序列化: 11 import json 12 13 with open('abc','r') as f: 14 data = json.loads(f.read()) 15 16 print(data['k2']) 17 18 ------------- another way ----------------- 19 序列化 20 import json 21 22 data = {'k1':'python','k2':'nihao'} 23 24 with open('abc','w') as f: 25 json.dump(data,f) 26 27 28 反序列化 29 import json 30 31 with open('abc','r') as f: 32 data = json.load(f) 33 34 print(data)
json只能处理简单的类型,如果字典里面包含函数它就处理不了了,需要pickle
pickle 序列化与反序列化的两种形式
序列化: import pickle def func(): print('hello python') data = {'k1':'python','k2':'nihao','k3':func} with open('abc','wb') as f: print( pickle.dumps(data)) f.write(pickle.dumps(data)) 反序列化: import pickle def func(): print('hello python') with open('abc','rb') as f: data = pickle.loads(f.read()) print(data['k3']()) ------------- another way --------------- 序列化: import pickle def func(): print('hello python') data = {'k1':'python','k2':'nihao','k3':func} with open('abc','wb') as f: print( pickle.dumps(data)) pickle.dump(data,f) 反序列化: import pickle def func(): print('hello python') with open('abc','rb') as f: data = pickle.load(f) print(data['k3']())
shelve 模块
shelve这个module,感觉比pickle用起来更简单一些,它也是一个用来持久化Python对象的简单工具。当我们写程序的时候如果不想用关系数据库那么重量级的东东去存储数据,不妨可以试试用shelve。shelf也是用key来访问的,使用起来和字典类似。shelve其实用anydbm去创建DB并且管理持久化对象的。
#存数据 import shelve s = shelve.open('test_shelf.db') try: s['key1'] = { 'int': 10, 'float':9.5, 'string':'Sample data' } finally: s.close() #取数据 import shelve s = shelve.open('test_shelf.db') try: existing = s['key1'] #or existing = s.get('key1') finally: s.close() print existing
更详细操作详见
http://www.cnblogs.com/frankzs/p/5949645.html
time & datetime
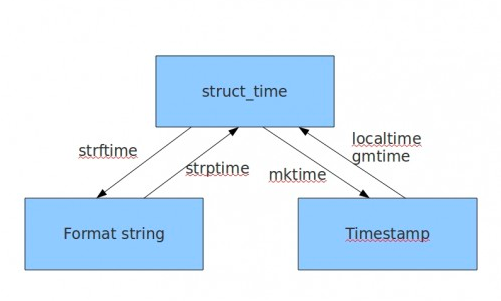
转换关系如下:
import time #生成timestamp print(time.time()) 结果: 1504661691.904563 #生成struct_time 本地时间 print(time.localtime()) print(time.localtime(time.time())) 结果: time.struct_time(tm_year=2017, tm_mon=9, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=51, tm_wday=2, tm_yday=249, tm_isdst=0) time.struct_time(tm_year=2017, tm_mon=9, tm_mday=6, tm_hour=9, tm_min=34, tm_sec=51, tm_wday=2, tm_yday=249, tm_isdst=0) #struct_time to timestamp print(time.mktime(time.localtime())) 结果: 1504661691.0 #timestamp to struct_time #格林威治时间 print(time.gmtime()) print(time.gmtime(time.time())) 结果: time.struct_time(tm_year=2017, tm_mon=9, tm_mday=6, tm_hour=1, tm_min=34, tm_sec=51, tm_wday=2, tm_yday=249, tm_isdst=0) time.struct_time(tm_year=2017, tm_mon=9, tm_mday=6, tm_hour=1, tm_min=34, tm_sec=51, tm_wday=2, tm_yday=249, tm_isdst=0) #format_time to struct_time print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) 结果: time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, tm_wday=3, tm_yday=125, tm_isdst=-1) #生成format_time print(time.strftime("%Y-%m-%d %X")) print(time.strftime("%Y-%m-%d %X",time.localtime())) 结果: 2017-09-06 09:34:51 2017-09-06 09:34:51
struct_time元组元素结构
属性 值 tm_year(年) 比如2011 tm_mon(月) 1 - 12 tm_mday(日) 1 - 31 tm_hour(时) 0 - 23 tm_min(分) 0 - 59 tm_sec(秒) 0 - 61 tm_wday(weekday) 0 - 6(0表示周日) tm_yday(一年中的第几天) 1 - 366 tm_isdst(是否是夏令时) 默认为-1
format time结构化表示
| 格式 | 含义 |
| %a | 本地(locale)简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化月份名称 |
| %B | 本地完整月份名称 |
| %c | 本地相应的日期和时间表示 |
| %d | 一个月中的第几天(01 - 31) |
| %H | 一天中的第几个小时(24小时制,00 - 23) |
| %I | 第几个小时(12小时制,01 - 12) |
| %j | 一年中的第几天(001 - 366) |
| %m | 月份(01 - 12) |
| %M | 分钟数(00 - 59) |
| %p | 本地am或者pm的相应符 |
| %S | 秒(01 - 61) |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 |
| %x | 本地相应日期 |
| %X | 本地相应时间 |
| %y | 去掉世纪的年份(00 - 99) |
| %Y | 完整的年份 |
| %Z | 时区的名字(如果不存在为空字符) |
| %% | ‘%’字符 |
工作应用场景:
1、时间戳转化为指定的日期格式
#方法一: timeStamp = 1381419600 timeArray = time.localtime(timeStamp) otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) otherStyletime == "2013-10-10 23:40:00" #方法二: import datetime timeStamp = 1381419600 dateArray = datetime.datetime.utcfromtimestamp(timeStamp) otherStyleTime = dateArray.strftime("%Y-%m-%d %H:%M:%S") otherStyletime == "2013-10-10 23:40:00"
生成固定格式的时间表示格式

print(time.asctime(time.localtime())) print(time.ctime(time.time())) 结果: Wed Sep 6 10:06:13 2017 Wed Sep 6 10:06:13 2017
datetime模块
datetime模块重新封装了time模块,提供了更多的结构,提供的类有:date,time,datetime,timedelta,tzinfo
方法目前看着有点乱,详细的可参考
http://www.cnblogs.com/tkqasn/p/6001134.html
random模块
#random的基本用法 import random #生成0到1之间的随机数 print(random.random()) #生成1到9之间的任意随机数 print(random.randint(1,9)) #与randint的区别就是不包含9 print(random.randrange(1,9)) #在字符串中随机做选择 print(random.choice('hello,python')) #在前面的类表中随机选择三个数 print(random.sample([1,2,3,4,5],3))
#获取随机浮点数
print(random.uniform(1,10))
结果:
5.8712373299744325
#洗牌# 列表的顺序会发生改变 items = [1,2,3,4,5,6,7] print(items) #[1, 2, 3, 4, 5, 6, 7] random.shuffle(items) print(items) #[1, 4, 7, 2, 5, 3, 6]生成随机验证码
import random choicecode = "" for i in range(4): current = random.randint(0,4) if current == i: temp = chr(random.randint(65,90)) #数字通过chr转换为ascii中的字符 else: temp = random.randint(0,9) choicecode += str(temp) print(choicecode)
os模块
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1]
shutil 模块
shutil.copyfile( src, dst) 从源src复制到dst中去。当然前提是目标地址是具备可写权限。抛出的异常信息为IOException. 如果当前的dst已存在的话就会被覆盖掉 shutil.move( src, dst) 移动文件或重命名 shutil.copymode( src, dst) 只是会复制其权限其他的东西是不会被复制的 shutil.copystat( src, dst) 复制权限、最后访问时间、最后修改时间 shutil.copy( src, dst) 复制一个文件到一个文件或一个目录 shutil.copy2( src, dst) 在copy上的基础上再复制文件最后访问时间与修改时间也复制过来了,类似于cp –p的东西 shutil.copy2( src, dst) 如果两个位置的文件系统是一样的话相当于是rename操作,只是改名;如果是不在相同的文件系统的话就是做move操作 shutil.copytree( olddir, newdir, True/Flase) 把olddir拷贝一份newdir,如果第3个参数是True,则复制目录时将保持文件夹下的符号连接,如果第3个参数是False,则将在复制的目录下生成物理副本来替代符号连接 shutil.rmtree( src ) 递归删除一个目录以及目录内的所有内容
ConfigParser 模块
ConfigParser 是用来读取配置文件的包
hashlib 模块
python2中分别是md5 和 sha, python3中统一为hashlib
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?') print md5.hexdigest() 结果: d26a53750bc40b38b65a520292f69306 如果数据量很大,可以分多次调用update() md5 = hashlib.md5() md5.update('how to use md5 in ') md5.update('python hashlib?') print md5.hexdigest()
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in ') sha1.update('python hashlib?') print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
def calc_md5(password): return get_md5(password + 'the-Salt')
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
re 模块
re.match #从左往右匹配,相当于 ^wa ....... re.match('C.*',"Chen321Ronghua123") #这样是可以匹配到的 re.match('R.*',"Chen321Ronghua123") #这样匹配不到了,不会去匹配Ronghuang.... re.seach #与match不同的地方就是,他不会从头去匹配比较 re.seach('R.*',"Chen321Ronghua123") #这样就可以匹配到了,但它只会从头往后匹配,匹配到一个就停止。 re.findall re.findall('[0-9]{1,3}',"aa1x2a345aaa") #匹配所有,这样就会匹配到所有的数字了, findall #没有.group()方法,直接输出[],上面的三种可以用 re.group()来显示返回结果 re.split re.split('[0-9]','abc1de3gh') #以数字做分割符,分割后面的字符串 re.sub re.sub('[0-9]','|','abc12de3f45GH',count=2) #以数字做分隔符,用‘|’来替换这个分割符,来对后面的字符串做处理,count是处理的个数。 (...){2}(...){3} #分组绑定 re.search('(abc){2}(||=){2}',"alexabcabc||=||=") re.search('(?P<province>[0-9]{2})(?P<city>[0-9]{2})(?P<xian>[0-9]{2})','371481199306143242') 输出结果直接在后面.groupdict() 如果要取某个值在后面加上.groupdict('city')
paramiko
paramiko是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接。
由于使用的是python这样的能够跨平台运行的语言,所以所有python支持的平台,如Linux, Solaris, BSD, MacOS X, Windows等,paramiko都可以支持,因此,如果需要使用SSH从一个平台连接到另外一个平台,进行一系列的操作时,paramiko是最佳工具之一。
安装
安装paramiko需要先安装一个依赖包叫PyCrypto的模块。PyCrypto是python编写的加密工具包,支持的各种加密算法(主要有:MD2 128 bits;MD4 128 bits;MD5 128 bits;RIPEMD 160 bits;SHA1 160 bits;SHA256 256 bits;AES 16, 24, or 32 bytes/16 bytes;ARC2 Variable/8 bytes;Blowfish Variable/8 bytes;CAST Variable/8 bytes;DES 8 bytes/8 bytes ;DES3 (Triple DES) 16 bytes/8 bytes;IDEA 16 bytes/8 bytes ;RC5 Variable/8 bytes等等。)
1、pip install pycrypto
2、pip install paramiko
sample
import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='c1.salt.com', port=22, username='XXXX', password='123') # 执行命令 stdin, stdout, stderr = ssh.exec_command('df') # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close()
sshClient封装Transport
import paramiko transport = paramiko.Transport(('hostname', 22)) transport.connect(username='XXXX', password='123') ssh = paramiko.SSHClient() ssh._transport = transport stdin, stdout, stderr = ssh.exec_command('df') print stdout.read() transport.close()
基于公钥密钥连接:
import paramiko private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='c1.salt.com', port=22, username='wupeiqi', key=private_key) # 执行命令 stdin, stdout, stderr = ssh.exec_command('df') # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close()
import paramiko private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') transport = paramiko.Transport(('hostname', 22)) transport.connect(username='wupeiqi', pkey=private_key) ssh = paramiko.SSHClient() ssh._transport = transport stdin, stdout, stderr = ssh.exec_command('df') transport.close()
import paramiko from io import StringIO key_str = """-----BEGIN RSA PRIVATE KEY----- MIIEpQIBAAKCAQEAq7gLsqYArAFco02/55IgNg0r7NXOtEM3qXpb/dabJ5Uyky/8 NEHhFiQ7deHIRIuTW5Zb0kD6h6EBbVlUMBmwJrC2oSzySLU1w+ZNfH0PE6W6fans H80whhuc/YgP+fjiO+VR/gFcqib8Rll5UfYzf5H8uuOnDeIXGCVgyHQSmt8if1+e 7hn1MVO1Lrm9Fco8ABI7dyv8/ZEwoSfh2C9rGYgA58LT1FkBRkOePbHD43xNfAYC tfLvz6LErMnwdOW4sNMEWWAWv1fsTB35PAm5CazfKzmam9n5IQXhmUNcNvmaZtvP c4f4g59mdsaWNtNaY96UjOfx83Om86gmdkKcnwIDAQABAoIBAQCnDBGFJuv8aA7A ZkBLe+GN815JtOyye7lIS1n2I7En3oImoUWNaJEYwwJ8+LmjxMwDCtAkR0XwbvY+ c+nsKPEtkjb3sAu6I148RmwWsGncSRqUaJrljOypaW9dS+GO4Ujjz3/lw1lrxSUh IqVc0E7kyRW8kP3QCaNBwArYteHreZFFp6XmtKMtXaEA3saJYILxaaXlYkoRi4k8 S2/K8aw3ZMR4tDCOfB4o47JaeiA/e185RK3A+mLn9xTDhTdZqTQpv17/YRPcgmwz zu30fhVXQT/SuI0sO+bzCO4YGoEwoBX718AWhdLJFoFq1B7k2ZEzXTAtjEXQEWm6 01ndU/jhAasdfasdasdfasdfa3eraszxqwefasdfadasdffsFIfAsjQb4HdkmHuC OeJrJOd+CYvdEeqJJNnF6AbHyYHIECkj0Qq1kEfLOEsqzd5nDbtkKBte6M1trbjl HtJ2Yb8w6o/q/6Sbj7wf/cW3LIYEdeVCjScozVcQ9R83ea05J+QOAr4nAoGBAMaq UzLJfLNWZ5Qosmir2oHStFlZpxspax/ln7DlWLW4wPB4YJalSVovF2Buo8hr8X65 lnPiE41M+G0Z7icEXiFyDBFDCtzx0x/RmaBokLathrFtI81UCx4gQPLaSVNMlvQA 539GsubSrO4LpHRNGg/weZ6EqQOXvHvkUkm2bDDJAoGATytFNxen6GtC0ZT3SRQM WYfasdf3xbtuykmnluiofasd2sfmjnljkt7khghmghdasSDFGQfgaFoKfaawoYeH C2XasVUsVviBn8kPSLSVBPX4JUfQmA6h8HsajeVahxN1U9e0nYJ0sYDQFUMTS2t8 RT57+WK/0ONwTWHdu+KnaJECgYEAid/ta8LQC3p82iNAZkpWlGDSD2yb/8rH8NQg 9tjEryFwrbMtfX9qn+8srx06B796U3OjifstjJQNmVI0qNlsJpQK8fPwVxRxbJS/ pMbNICrf3sUa4sZgDOFfkeuSlgACh4cVIozDXlR59Z8Y3CoiW0uObEgvMDIfenAj 98pl3ZkCgYEAj/UCSni0dwX4pnKNPm6LUgiS7QvIgM3H9piyt8aipQuzBi5LUKWw DlQC4Zb73nHgdREtQYYXTu7p27Bl0Gizz1sW2eSgxFU8eTh+ucfVwOXKAXKU5SeI +MbuBfUYQ4if2N/BXn47+/ecf3A4KgB37Le5SbLDddwCNxGlBzbpBa0= -----END RSA PRIVATE KEY-----""" private_key = paramiko.RSAKey(file_obj=StringIO(key_str)) transport = paramiko.Transport(('10.0.1.40', 22)) transport.connect(username='wupeiqi', pkey=private_key) ssh = paramiko.SSHClient() ssh._transport = transport stdin, stdout, stderr = ssh.exec_command('df') result = stdout.read() transport.close() print(result)
SFTPClient
用于连接远程服务器并执行上传下载
基于用户名密码上传下载
import paramiko transport = paramiko.Transport(('hostname',22)) transport.connect(username='wupeiqi',password='123') sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put('/tmp/location.py', '/tmp/test.py') # 将remove_path 下载到本地 local_path sftp.get('remove_path', 'local_path') transport.close()
import paramiko private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') transport = paramiko.Transport(('hostname', 22)) transport.connect(username='wupeiqi', pkey=private_key ) sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put('/tmp/location.py', '/tmp/test.py') # 将remove_path 下载到本地 local_path sftp.get('remove_path', 'local_path') transport.close()
#!/usr/bin/env python # -*- coding:utf-8 -*- import paramiko import uuid class Haproxy(object): def __init__(self): self.host = '172.16.103.191' self.port = 22 self.username = 'wupeiqi' self.pwd = '123' self.__k = None def create_file(self): file_name = str(uuid.uuid4()) with open(file_name,'w') as f: f.write('sb') return file_name def run(self): self.connect() self.upload() self.rename() self.close() def connect(self): transport = paramiko.Transport((self.host,self.port)) transport.connect(username=self.username,password=self.pwd) self.__transport = transport def close(self): self.__transport.close() def upload(self): # 连接,上传 file_name = self.create_file() sftp = paramiko.SFTPClient.from_transport(self.__transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put(file_name, '/home/wupeiqi/tttttttttttt.py') def rename(self): ssh = paramiko.SSHClient() ssh._transport = self.__transport # 执行命令 stdin, stdout, stderr = ssh.exec_command('mv /home/wupeiqi/tttttttttttt.py /home/wupeiqi/ooooooooo.py') # 获取命令结果 result = stdout.read() ha = Haproxy() ha.run()
logging
logging模块简介
Python的logging模块提供了通用的日志系统,可以方便第三方模块或者是应用使用。这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP GET/POST,SMTP,Socket等,甚至可以自己实现具体的日志记录方式。
logging模块提供logger,handler,filter,formatter 方法。
- logger:提供日志接口,供应用代码使用。logger最长用的操作有两类:配置和发送日志消息。可以通过logging.getLogger(name)获取logger对象,如果不指定name则返回root对象,多次使用相同的name调用getLogger方法返回同一个logger对象。
- handler:将日志记录(log record)发送到合适的目的地(destination),比如文件,socket等。一个logger对象可以通过addHandler方法添加0到多个handler,每个handler又可以定义不同日志级别,以实现日志分级过滤显示。
- filter:提供一种优雅的方式决定一个日志记录是否发送到handler。
- formatter:指定日志记录输出的具体格式。formatter的构造方法需要两个参数:消息的格式字符串和日期字符串,这两个参数都是可选的。
logging用法解析
1. 初始化 logger = logging.getLogger("endlesscode"),getLogger()方法后面最好加上所要日志记录的模块名字,后面的日志格式中的%(name)s 对应的是这里的模块名字
2. 设置级别 logger.setLevel(logging.DEBUG),Logging中有NOTSET < DEBUG < INFO < WARNING < ERROR < CRITICAL这几种级别,日志会记录设置级别以上的日志
3. Handler,常用的是StreamHandler和FileHandler,windows下你可以简单理解为一个是console和文件日志,一个打印在CMD窗口上,一个记录在一个文件上
4. formatter,定义了最终log信息的顺序,结构和内容,我喜欢用这样的格式 '[%(asctime)s] [%(levelname)s] %(message)s', '%Y-%m-%d %H:%M:%S',
%(name)s Logger的名字
%(levelname)s 文本形式的日志级别
%(message)s 用户输出的消息
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(levelno)s 数字形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
5. 记录 使用object.debug(message)来记录日志
下面来写一个实例,在CMD窗口上只打出error以上级别的日志,但是在日志中打出debug以上的信息
# 第一步,创建一个logger logger = logging.getLogger('My_test') logger.setLevel(logging.DEBUG) # 建立一个filehandler来把日志记录在文件里,级别为debug以上 fh = logging.FileHandler('test.log') fh.setLevel(logging.DEBUG) # 建立一个streamhandler来把日志打在CMD窗口上,级别为error以上 ch = logging.StreamHandler() ch.setLevel(logging.ERROR) # 设置日志格式 formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(filename)s - %(module)s - %(message)s") ch.setFormatter(formatter) fh.setFormatter(formatter) #将相应的handler添加在logger对象中 logger.addHandler(ch) logger.addHandler(fh) # 开始打日志 logger.debug("debug message") logger.info("info message") logger.warn("warn message") logger.error("error message") logger.critical("critical message") #运行结果 #屏幕上输出了 2017-09-27 09:33:29,764 - My_test - ERROR - test.py - test - error message 2017-09-27 09:33:29,764 - My_test - CRITICAL - test.py - test - critical message #日志文件中输出了 2017-09-27 09:33:29,763 - My_test - DEBUG - test.py - test - debug message 2017-09-27 09:33:29,764 - My_test - INFO - test.py - test - info message 2017-09-27 09:33:29,764 - My_test - WARNING - test.py - test - warn message 2017-09-27 09:33:29,764 - My_test - ERROR - test.py - test - error message 2017-09-27 09:33:29,764 - My_test - CRITICAL - test.py - test - critical message
如果想在控制台输出的信息有颜色,可以 import ctypes
当一个项目比较大的时候,不同的文件中都要用到Log,可以考虑将其封装为一个类来使用
import logging import ctypes import os class Logger: def __init__(self,path,clevel = logging.DEBUG,Flevel = logging.DEBUG): self.logger = logging.getLogger(path) self.logger.setLevel(logging.DEBUG) fmt = logging.Formatter('[%(asctime)s] [%(levelname)s] %(message)s', '%Y-%m-%d %H:%M:%S') #设置屏幕输出日志 sh = logging.StreamHandler() sh.setFormatter(fmt) sh.setLevel(clevel) #设置日志文件 fh = logging.FileHandler(path) fh.setFormatter(fmt) fh.setLevel(Flevel) self.logger.addHandler(sh) self.logger.addHandler(fh) def debug(self,message): self.logger.debug(message) def info(self,message): self.logger.info(message) def warning(self,message): self.logger.warning(message) def error(self,message): self.logger.error(message) def critial(self,message): self.logger.critical(message) if __name__ == '__main__': logtest = Logger('test.log',logging.ERROR,logging.DEBUG) logtest.debug('this is debug message') logtest.info('this is info message') logtest.warning('this is warning message') logtest.error('this is error message') logtest.critial('this is critial message')
每次再调用的时候实例化一个对象就可以了
logobj = Logger(‘filename',clevel,Flevel)