无偏估计:估计量的均值等于真实值,即具体每一次估计值可能大于真实值,也可能小于真实值,而不能总是大于或小于真实值(这就产生了系统误差)。
估计量评价的标准:
(1)无偏性 如上述
(2)有效性 有效性是指估计量与总体参数的离散程度。如果两个估计量都是无偏的,那么离散程度较小的估计量相对而言是较为有效的。即虽然每次估计都会大于或小于真实值,但是偏离的程度都更小的估计更优。
(3)一致性 又称相合性,是指随着样本容量的增大,估计量愈来愈接近总体参数的真值。
为什么方差的分母是n-1?
结论: 这个问题本身概念混淆了。如果已知全部的数据,那么均值和方差可以直接求出。但是对一个随机变量X,需要估计它的均值和方差,此时才用分母为n-1的公式来估计他的方差,因此分母是n-1才能使对方差的估计(而不是方差)是无偏的。因此,这个问题应该改为,为什么随机变量的方差的估计的分母是n-1?
如果我们已经知道了全部的数据,那就可以求出均值μ,sigma,此时就是常规的分母为n的公式直接求,这并不是估计!
现在,对于一个随机变量X,我们要去估计它的期望和方差。
期望的估计就是样本的均值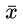
现在,在估计的X的方差的时候,如果我们预先知道真实的期望μ,那么根据方差的定义:

这时分母为n的估计是正确的,就是无偏估计!
但是,在实际估计随机变量X的方差的时候,我们是不知道它的真实期望的,而是用期望的估计值去估计方差,那么:
去估计方差,那么:
所以把分母从n换成n-1,就是把对方差的估计稍微放大一点点。至于为什么是n-1,而不是n-2,n-3,...,有严格的数学证明。
无偏估计虽然在数学上更好,但是并不总是“最好”的估计,在实际中经常会使用具有其它重要性质的有偏估计。