基本的增删改查


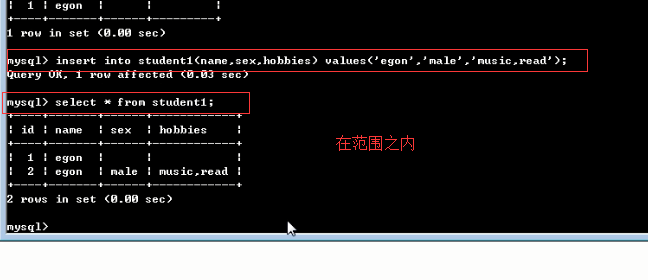
#1 操作文件夹(库) 增 create database db1 charset utf8; 查 show databases; show create database db1; 改 alter database db1 charset gbk; 删 drop database db1; #2 操作文件(表) 切换到文件夹下:use db1 增 create table t1(id int,name char(10))engine=innodb; create table t2(id int,name char(10))engine=innodb default charset utf8; 查 show tables; show create table t1; desc t1;#查看表结构 改 alter table t1 add age int; alter table t1 modify name char(12); 删 drop table t1; #3 操作文件的一行行内容(记录) 增 insert into db1.t1 values(1,'egon1'),(2,'egon2'),(3,'egon3'); insert into db1.t1(name) values('egon1'),('egon2'),('egon3'); 查 select * from t1; select name from t1; select name,id from t1; 改 update t1 set name='SB' where id=4; update t1 set name='SB' where name='alex'; 删 delete from t1 where id=4; #对于清空表记录有两种方式,但是推荐后者 delete from t1; truncate t1; #当数据量比较大的情况下,使用这种方式,删除速度快 #自增id create table t5(id int primary key auto_increment,name char(10)); create table t4(id int not null unique,name char(10)); create table t5(id int primary key auto_increment insert into t5(name) values ('egon5'), ('egon6'), ('egon7'), ('egon8'), ('egon9'), ('egon10'), ('egon11'), ('egon12'), ('egon13'); #拷贝表结构 create table t7 select * from t5 where 1=2; alter table t7 modify id int primary key auto_increment; insert into t7(name) values ('egon1'), ('egon2'), ('egon3'), ('egon4'), ('egon5'), ('egon6'), ('egon7'), ('egon8'), ('egon9'), ('egon10'), ('egon11'), ('egon12'), ('egon13'); delete from t7 where id=1; #删记录 update t7 set name=''; #修改字段对应的值
今日内容:
1、数据类型
2、约束条件
多对一
多对多
一对一
3、单表查询
select *from t1 where 条件;
一、今日内容:
1、创建表
#语法: create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的



2、数据类型


#1. 数字: 整型:tinyinit int bigint 小数: float :在位数比较短的情况下不精准 double :在位数比较长的情况下不精准 0.000001230123123123 存成:0.000001230000 decimal:(如果用小数,则用推荐使用decimal) 精准 内部原理是以字符串形式去存 #2. 字符串: char(10):简单粗暴,浪费空间,存取速度快 root存成root000000 varchar:精准,节省空间,存取速度慢 sql优化:创建表时,定长的类型往前放,变长的往后放 比如性别 比如地址或描述信息 >255个字符,超了就把文件路径存放到数据库中。 比如图片,视频等找一个文件服务器,数据库中只存路径或url。 #3. 时间类型: 最常用:datetime #4. 枚举类型与集合类型
(1)整数类型
整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存储年龄,等级,id,各种号码等
======================================== tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号: 0 ~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 ======================================== int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号: 0 ~ 4294967295 ======================================== bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号: -9223372036854775808 ~ 9223372036854775807 无符号: 0 ~ 18446744073709551615 复制代码
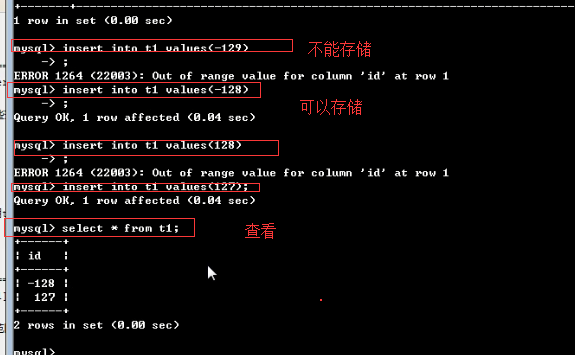
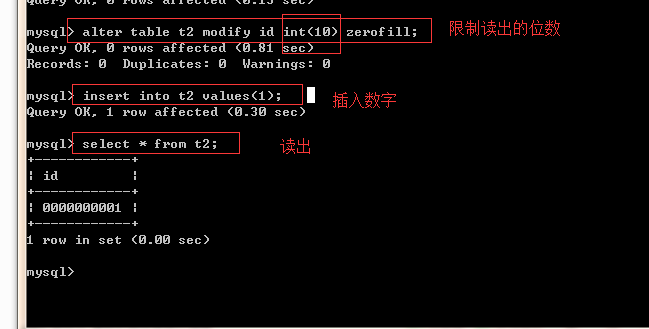
=========有符号和无符号tinyint========== #tinyint默认为有符号 MariaDB [db1]> create table t1(x tinyint); #默认为有符号,即数字前有正负号 MariaDB [db1]> desc t1; MariaDB [db1]> insert into t1 values -> (-129), -> (-128), -> (127), -> (128); MariaDB [db1]> select * from t1; +------+ | x | +------+ | -128 | #-129存成了-128 | -128 | #有符号,最小值为-128 | 127 | #有符号,最大值127 | 127 | #128存成了127 +------+ #设置无符号tinyint MariaDB [db1]> create table t2(x tinyint unsigned); MariaDB [db1]> insert into t2 values -> (-1), -> (0), -> (255), -> (256); MariaDB [db1]> select * from t2; +------+ | x | +------+ | 0 | -1存成了0 | 0 | #无符号,最小值为0 | 255 | #无符号,最大值为255 | 255 | #256存成了255 +------+ ============有符号和无符号int============= #int默认为有符号 MariaDB [db1]> create table t3(x int); #默认为有符号整数 MariaDB [db1]> insert into t3 values -> (-2147483649), -> (-2147483648), -> (2147483647), -> (2147483648); MariaDB [db1]> select * from t3; +-------------+ | x | +-------------+ | -2147483648 | #-2147483649存成了-2147483648 | -2147483648 | #有符号,最小值为-2147483648 | 2147483647 | #有符号,最大值为2147483647 | 2147483647 | #2147483648存成了2147483647 +-------------+ #设置无符号int MariaDB [db1]> create table t4(x int unsigned); MariaDB [db1]> insert into t4 values -> (-1), -> (0), -> (4294967295), -> (4294967296); MariaDB [db1]> select * from t4; +------------+ | x | +------------+ | 0 | #-1存成了0 | 0 | #无符号,最小值为0 | 4294967295 | #无符号,最大值为4294967295 | 4294967295 | #4294967296存成了4294967295 +------------+ ==============有符号和无符号bigint============= MariaDB [db1]> create table t6(x bigint); MariaDB [db1]> insert into t5 values -> (-9223372036854775809), -> (-9223372036854775808), -> (9223372036854775807), -> (9223372036854775808); MariaDB [db1]> select * from t5; +----------------------+ | x | +----------------------+ | -9223372036854775808 | | -9223372036854775808 | | 9223372036854775807 | | 9223372036854775807 | +----------------------+ MariaDB [db1]> create table t6(x bigint unsigned); MariaDB [db1]> insert into t6 values -> (-1), -> (0), -> (18446744073709551615), -> (18446744073709551616); MariaDB [db1]> select * from t6; +----------------------+ | x | +----------------------+ | 0 | | 0 | | 18446744073709551615 | | 18446744073709551615 | +----------------------+ ======用zerofill测试整数类型的显示宽度============= MariaDB [db1]> create table t7(x int(3) zerofill); MariaDB [db1]> insert into t7 values -> (1), -> (11), -> (111), -> (1111); MariaDB [db1]> select * from t7; +------+ | x | +------+ | 001 | | 011 | | 111 | | 1111 | #超过宽度限制仍然可以存 +------+
1)验证小整数类型
有符号改成无符号


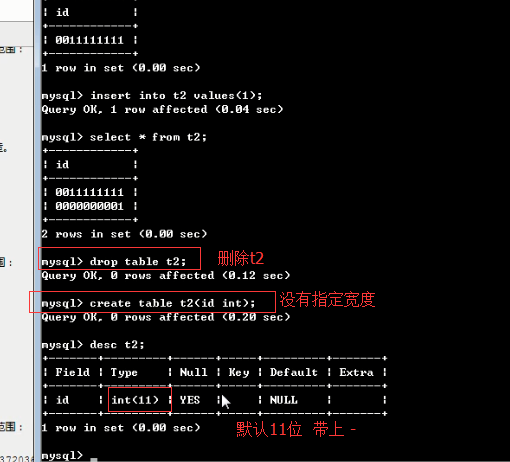
2)验证 int 类型
验证 int 类型的宽度
3) 大整数的验证
注意:为该类型指定宽度时,仅仅只是指定查询结果的显示宽度,与存储范围无关,存储范围如下
其实我们完全没必要为整数类型指定显示宽度,使用默认的就可以了
默认的显示宽度,都是在最大值的基础上加1
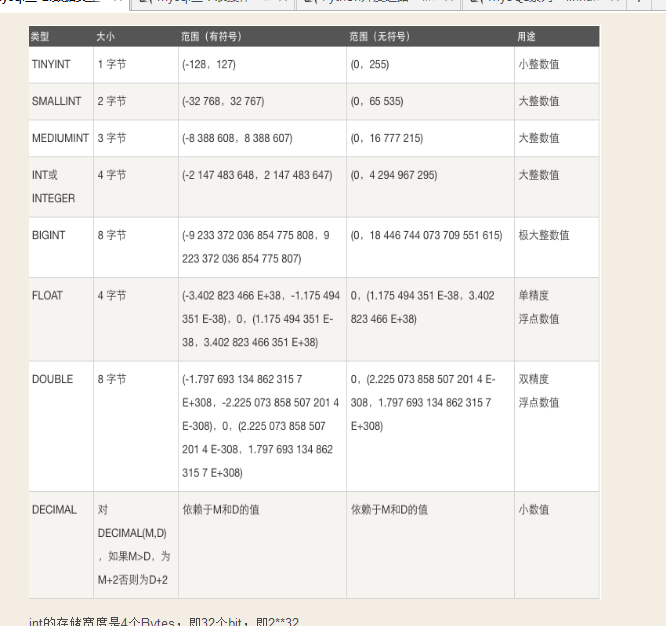
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
(2)浮点型
定点数类型 DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重、体质参数等
====================================== #FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 定义: 单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30 有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 无符号: 1.175494351E-38 to 3.402823466E+38 精确度: **** 随着小数的增多,精度变得不准确 **** ====================================== #DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 定义: 双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30 有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 精确度: ****随着小数的增多,精度比float要高,但也会变得不准确 **** ====================================== decimal[(m[,d])] [unsigned] [zerofill] 定义: 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 精确度: **** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型 decaimal能够存储精确值的原因在于其内部按照字符串存储。 复制代码
mysql> create table t1(x float(256,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t1(x float(256,30)); ERROR 1439 (42000): Display width out of range for column 'x' (max = 255) mysql> create table t1(x float(255,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> create table t2(x double(255,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> create table t3(x decimal(66,31)); ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30. mysql> create table t3(x decimal(66,30)); ERROR 1426 (42000): Too-big precision 66 specified for 'x'. Maximum is 65. mysql> create table t3(x decimal(65,30)); #建表成功 Query OK, 0 rows affected (0.02 sec) mysql> show tables; +---------------+ | Tables_in_db1 | +---------------+ | t1 | | t2 | | t3 | +---------------+ 3 rows in set (0.00 sec) mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1 Query OK, 1 row affected (0.01 sec) mysql> insert into t2 values(1.1111111111111111111111111111111); Query OK, 1 row affected (0.00 sec) mysql> insert into t3 values(1.1111111111111111111111111111111); Query OK, 1 row affected, 1 warning (0.01 sec) mysql> select * from t1; #随着小数的增多,精度开始不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111164093017600000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111200000000000000 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数 +----------------------------------+ | x | +----------------------------------+ | 1.111111111111111111111111111111 | +----------------------------------+ 1 row in set (0.00 sec)


1)默认是有符号的
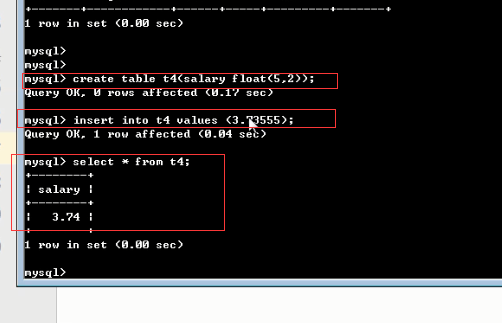
2) 无符号


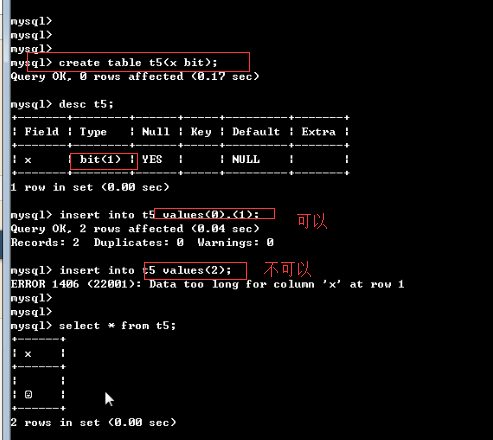
(3) bit(位) 类型(了解)
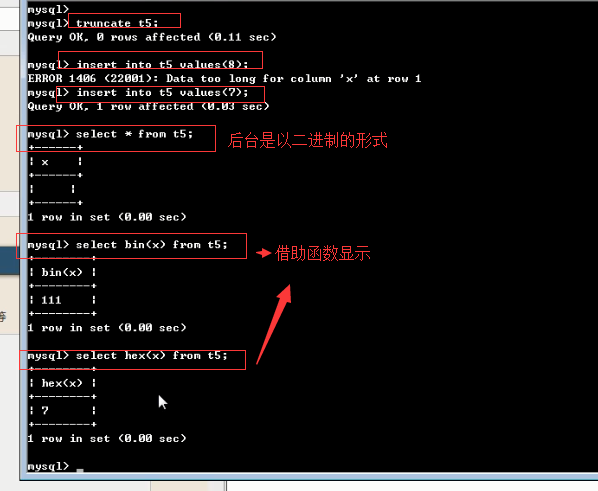
BIT(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。
注意:对于位字段需要使用函数读取
bin()显示为二进制
hex()显示为十六进制
MariaDB [db1]> create table t9(id bit); MariaDB [db1]> desc t9; #bit默认宽度为1 +-------+--------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+--------+------+-----+---------+-------+ | id | bit(1) | YES | | NULL | | +-------+--------+------+-----+---------+-------+ MariaDB [db1]> insert into t9 values(8); MariaDB [db1]> select * from t9; #直接查看是无法显示二进制位的 +------+ | id | +------+ | | +------+ MariaDB [db1]> select bin(id),hex(id) from t9; #需要转换才能看到 +---------+---------+ | bin(id) | hex(id) | +---------+---------+ | 1 | 1 | +---------+---------+ MariaDB [db1]> alter table t9 modify id bit(5); MariaDB [db1]> insert into t9 values(8); MariaDB [db1]> select bin(id),hex(id) from t9; +---------+---------+ | bin(id) | hex(id) | +---------+---------+ | 1 | 1 | | 1000 | 8 | +---------+---------+
(4)字符串类型
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html #注意:char和varchar括号内的参数指的都是字符的长度 #char类型:定长,简单粗暴,浪费空间,存取速度快 字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节) 存储: 存储char类型的值时,会往右填充空格来满足长度 例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储 检索: 在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';) #varchar类型:变长,精准,节省空间,存取速度慢 字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html) 存储: varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来 强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用) 如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255) 如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535) 检索: 尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html CHAR 和 VARCHAR 是最常使用的两种字符串类型。 一般来说 CHAR(N)用来保存固定长度的字符串,对于 CHAR 类型,N 的范围 为 0 ~ 255 VARCHAR(N)用来保存变长字符类型,对于 VARCHAR 类型,N 的范围为 0 ~ 65 535 CHAR(N)和 VARCHAR(N) 中的 N 都代表字符长度,而非字节长度。 ps:对于 MySQL 4.1 之前的版本,如 MySQL 3.23 和 MySQL 4.0,CHAR(N)和 VARCHAR (N)中的 N 代表字节长度。 #CHAR类型 对于 CHAR 类型的字符串,MySQL 数据库会自动对存储列的右边进行填充(Right Padded)操作,直到字符串达到指定的长度 N。而在读取该列时,MySQL 数据库会自动将 填充的字符删除。有一种情况例外,那就是显式地将 SQL_MODE 设置为 PAD_CHAR_TO_ FULL_LENGTH,例如: mysql> CREATE TABLE t ( a CHAR(10)); Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO t SELECT 'abc'; Query OK, 1 row affected (0.03 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> SELECT a,HEX(a),LENGTH(a) FROM tG; *************************** 1. row *************************** a: abc HEX(a): 616263 LENGTH (a): 3 1 row in set (0.00 sec) mysql> SET SQL_MODE='PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT a,HEX(a),LENGTH(a) FROM tG; *************************** 1. row *************************** a: abc HEX(a): 61626320202020202020 LENGTH (a): 10 1 row in set (0.00 sec) 在上述这个例子中,先创建了一张表 t,a 列的类型为 CHAR(10)。然后通过 INSERT语句插入值“abc”,因为 a 列的类型为 CHAR 型,所以会自动在后面填充空字符串,使其长 度为 10。接下来在通过 SELECT 语句取出数据时会将 a 列右填充的空字符移除,从而得到 值“abc”。通过 LENGTH 函数看到 a 列的字符长度为 3 而非 10。 接着我们将 SQL_MODE 显式地设置为 PAD_CHAR_TO_FULL_LENGTH。这时再通过 SELECT 语句进行查询时,得到的结果是“abc ”,abc 右边有 7 个填充字符 0x20,并通 过 HEX 函数得到了验证。这次 LENGTH 函数返回的长度为 10。需要注意的是,LENGTH 函数返回的是字节长度,而不是字符长度。对于多字节字符集,CHAR(N)长度的列最多 可占用的字节数为该字符集单字符最大占用字节数 *N。例如,对于 utf8 下,CHAR(10)最 多可能占用 30 个字节。通过对多字节字符串使用 CHAR_LENGTH 函数和 LENGTH 函数, 可以发现两者的不同,示例如下: mysql> SET NAMES gbk; Query OK, 0 rows affected (0.03 sec) mysql> SELECT @a:='MySQL 技术内幕 '; Query OK, 0 rows affected (0.03 sec) mysql> SELECT @a,HEX(@a),LENGTH(@a),CHAR_LENGTH(@a)G; ***************************** 1. row **************************** a: MySQL 技术内幕 HEX(a): 4D7953514CBCBCCAF5C4DAC4BB LENGTH (a): 13 CHAR_LENGTH(a): 9 1 row in set (0.00 sec) 变 量 @ a 是 g b k 字 符 集 的 字 符 串 类 型 , 值 为 “ M y S Q L 技 术 内 幕 ”, 十 六 进 制 为 0x4D7953514CBCBCCAF5C4DAC4BB,LENGTH 函数返回 13,即该字符串占用 13 字节, 因为 gbk 字符集中的中文字符占用两个字节,因此一共占用 13 字节。CHAR_LENGTH 函数 返回 9,很显然该字符长度为 9。 #VARCHAR类型 VARCHAR 类型存储变长字段的字符类型,与 CHAR 类型不同的是,其存储时需要在 前缀长度列表加上实际存储的字符,该字符占用 1 ~ 2 字节的空间。当存储的字符串长度小 于 255 字节时,其需要 1 字节的空间,当大于 255 字节时,需要 2 字节的空间。所以,对 于单字节的 latin1 来说,CHAR(10)和 VARCHAR(10)最大占用的存储空间是不同的, CHAR(10)占用 10 个字节这是毫无疑问的,而 VARCHAR(10)的最大占用空间数是 11 字节,因为其需要 1 字节来存放字符长度。 ------------------------------------------------- 注意 对于有些多字节的字符集类型,其 CHAR 和 VARCHAR 在存储方法上是一样的,同样 需要为长度列表加上字符串的值。对于 GBK 和 UTF-8 这些字符类型,其有些字符是以 1 字节 存放的,有些字符是按 2 或 3 字节存放的,因此同样需要 1 ~ 2 字节的空间来存储字符的长 度。 ------------------------------------------------- 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样,例如: mysql> CREATE TABLE t ( a CHAR(10), b VARCHAR(10)); Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO t SELECT 'a','a'; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> SELECT a=b FROM tG; *************************** 1. row *************************** a=b: 1 1 row in set (0.00 sec) mysql> SET SQL_MODE='PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT a=b FROM tG; *************************** 1. row *************************** a=b: 1 1 row in set (0.00 sec)

测试前了解两个函数
length:查看字节数
char_length:查看字符数
1)验证

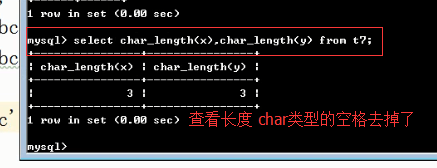
1. char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形
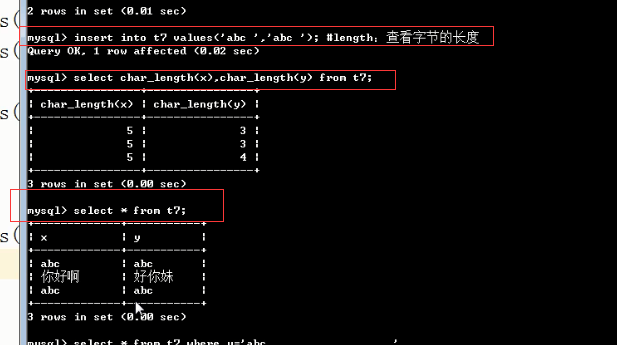
mysql> create table t1(x char(5),y varchar(5)); Query OK, 0 rows affected (0.26 sec) #char存5个字符,而varchar存4个字符 mysql> insert into t1 values('你瞅啥 ','你瞅啥 '); Query OK, 1 row affected (0.05 sec) mysql> SET sql_mode=''; Query OK, 0 rows affected, 1 warning (0.00 sec) #在检索时char很不要脸地将自己浪费的2个字符给删掉了,装的好像自己没浪费过空间一样,而varchar很老实,存了多少,就显示多少 mysql> select x,char_length(x),y,char_length(y) from t1; +-----------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-----------+----------------+------------+----------------+ | 你瞅啥 | 3 | 你瞅啥 | 4 | +-----------+----------------+------------+----------------+ 1 row in set (0.00 sec) #略施小计,让char现出原形 mysql> SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH'; Query OK, 0 rows affected (0.00 sec) #这下子char原形毕露了...... mysql> select x,char_length(x),y,char_length(y) from t1; +-------------+----------------+------------+----------------+ | x | char_length(x) | y | char_length(y) | +-------------+----------------+------------+----------------+ | 你瞅啥 | 5 | 你瞅啥 | 4 | +-------------+----------------+------------+----------------+ 1 row in set (0.00 sec) #char类型:3个中文字符+2个空格=11Bytes #varchar类型:3个中文字符+1个空格=10Bytes mysql> select x,length(x),y,length(y) from t1; +-------------+-----------+------------+-----------+ | x | length(x) | y | length(y) | +-------------+-----------+------------+-----------+ | 你瞅啥 | 11 | 你瞅啥 | 10 | +-------------+-----------+------------+-----------+ 1 row in set (0.00 sec)

mysql> select concat('数据: ',x,'长度: ',char_length(x)),concat(y,char_length(y) ) from t1; +------------------------------------------------+--------------------------+ | concat('数据: ',x,'长度: ',char_length(x)) | concat(y,char_length(y)) | +------------------------------------------------+--------------------------+ | 数据: 你瞅啥 长度: 5 | 你瞅啥 4 | +------------------------------------------------+--------------------------+ 1 row in set (0.00 sec)
2. 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样,,但这不适用于like
Values in CHAR and VARCHAR columns are sorted and compared according to the character set collation assigned to the column. All MySQL collations are of type PAD SPACE. This means that all CHAR, VARCHAR, and TEXT values are compared without regard to any trailing spaces. “Comparison” in this context does not include the LIKE pattern-matching operator, for which trailing spaces are significant. For example: mysql> CREATE TABLE names (myname CHAR(10)); Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO names VALUES ('Monty'); Query OK, 1 row affected (0.00 sec) mysql> SELECT myname = 'Monty', myname = 'Monty ' FROM names; +------------------+--------------------+ | myname = 'Monty' | myname = 'Monty ' | +------------------+--------------------+ | 1 | 1 | +------------------+--------------------+ 1 row in set (0.00 sec) mysql> SELECT myname LIKE 'Monty', myname LIKE 'Monty ' FROM names; +---------------------+-----------------------+ | myname LIKE 'Monty' | myname LIKE 'Monty ' | +---------------------+-----------------------+ | 1 | 0 | +---------------------+-----------------------+ 1 row in set (0.00 sec)
总结:
#常用字符串系列:char与varchar 注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡 #其他字符串系列(效率:char>varchar>text) TEXT系列 TINYTEXT TEXT MEDIUMTEXT LONGTEXT BLOB 系列 TINYBLOB BLOB MEDIUMBLOB LONGBLOB BINARY系列 BINARY VARBINARY text:text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 mediumtext:A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. longtext:A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters.
补充了解部分

大的文件,可以把文件放在本机上 在数据库中存放路径就可以
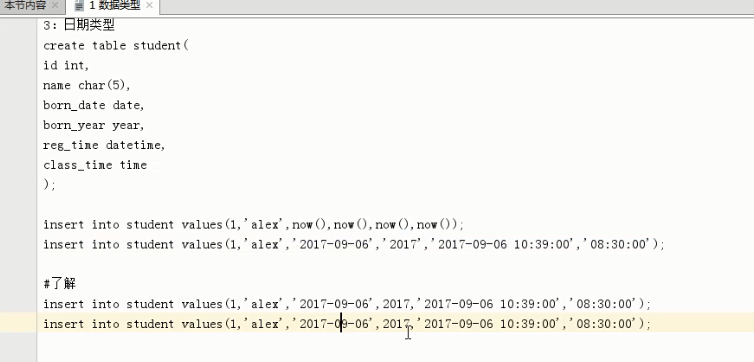
(5)日期类型
DATE TIME DATETIME TIMESTAMP YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
YEAR YYYY(1901/2155) DATE YYYY-MM-DD(1000-01-01/9999-12-31) TIME HH:MM:SS('-838:59:59'/'838:59:59') DATETIME YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) TIMESTAMP YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
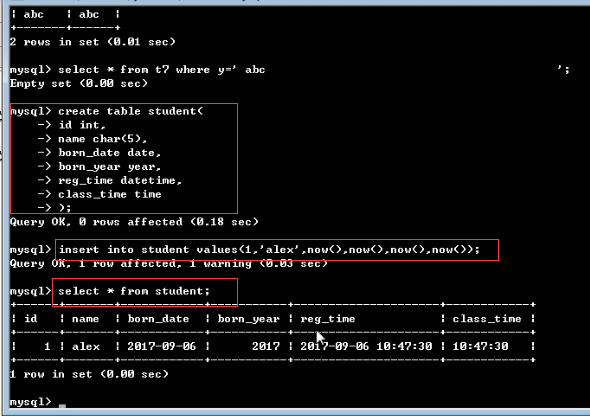
============year=========== MariaDB [db1]> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4) MariaDB [db1]> insert into t10 values -> (1900), -> (1901), -> (2155), -> (2156); MariaDB [db1]> select * from t10; +-----------+ | born_year | +-----------+ | 0000 | | 1901 | | 2155 | | 0000 | +-----------+ ============date,time,datetime=========== MariaDB [db1]> create table t11(d date,t time,dt datetime); MariaDB [db1]> desc t11; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | d | date | YES | | NULL | | | t | time | YES | | NULL | | | dt | datetime | YES | | NULL | | +-------+----------+------+-----+---------+-------+ MariaDB [db1]> insert into t11 values(now(),now(),now()); MariaDB [db1]> select * from t11; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 | +------------+----------+---------------------+ ============timestamp=========== MariaDB [db1]> create table t12(time timestamp); MariaDB [db1]> insert into t12 values(); MariaDB [db1]> insert into t12 values(null); MariaDB [db1]> select * from t12; +---------------------+ | time | +---------------------+ | 2017-07-25 16:29:17 | | 2017-07-25 16:30:01 | +---------------------+ ============注意啦,注意啦,注意啦=========== 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 2. 插入年份时,尽量使用4位值 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 MariaDB [db1]> create table t12(y year); MariaDB [db1]> insert into t12 values -> (50), -> (71); MariaDB [db1]> select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+ ============综合练习=========== MariaDB [db1]> create table student( -> id int, -> name varchar(20), -> born_year year, -> birth date, -> class_time time, -> reg_time datetime); MariaDB [db1]> insert into student values -> (1,'alex',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"), -> (2,'egon',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"), -> (3,'wsb',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13"); MariaDB [db1]> select * from student; +------+------+-----------+------------+------------+---------------------+ | id | name | born_year | birth | class_time | reg_time | +------+------+-----------+------------+------------+---------------------+ | 1 | alex | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 | | 2 | egon | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 | | 3 | wsb | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 | +------+------+-----------+------------+------------+---------------------+
(5)枚举与集合
字段的值只能在给定范围中选择,如单选框,多选框
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
枚举类型(enum) An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.) 示例: CREATE TABLE shirts ( name VARCHAR(40), size ENUM('x-small', 'small', 'medium', 'large', 'x-large') ); INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); 集合类型(set) A SET column can have a maximum of 64 distinct members. 示例: CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
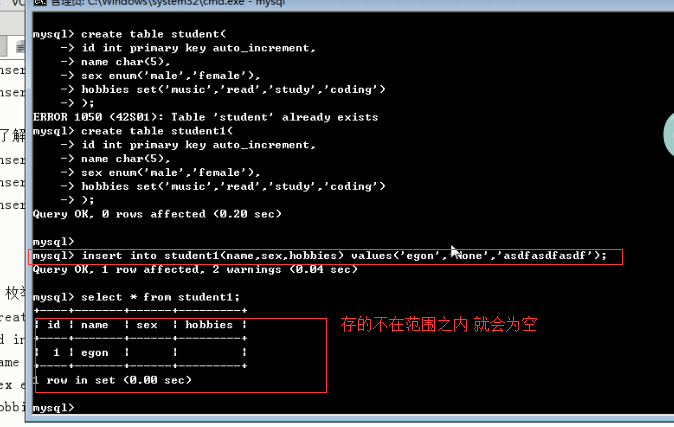
MariaDB [db1]> create table consumer( -> name varchar(50), -> sex enum('male','female'), -> level enum('vip1','vip2','vip3','vip4','vip5'), #在指定范围内,多选一 -> hobby set('play','music','read','study') #在指定范围内,多选多 -> ); MariaDB [db1]> insert into consumer values -> ('egon','male','vip5','read,study'), -> ('alex','female','vip1','girl'); MariaDB [db1]> select * from consumer; +------+--------+-------+------------+ | name | sex | level | hobby | +------+--------+-------+------------+ | egon | male | vip5 | read,study | | alex | female | vip1 | | +------+--------+-------+------------+


三、约束
1、
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
说明
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值 2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值 sex enum('male','female') not null default 'male' age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20 3. 是否是key 主键 primary key 外键 foreign key 索引 (index,unique...)
关于约束的练习
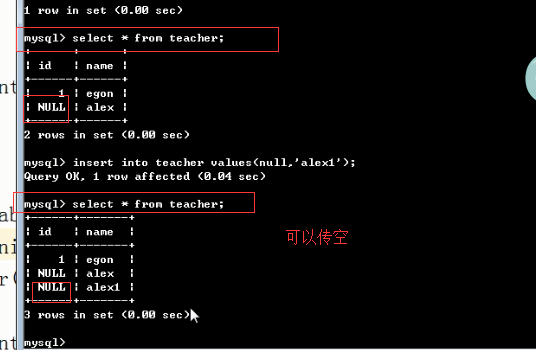
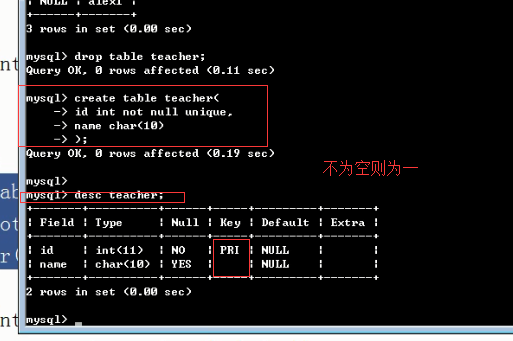
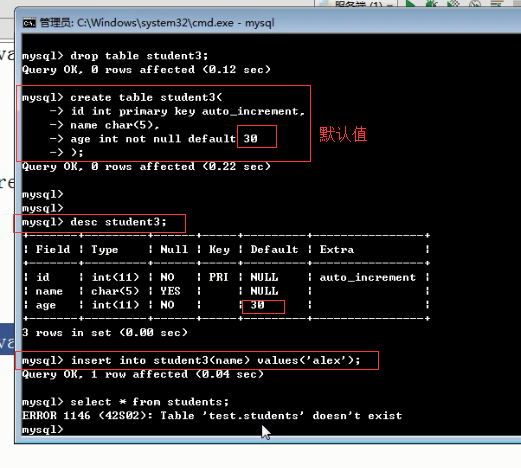
1 not null 与default create table student2( id int primary key auto_increment, name char(5), sex enum('male','female') not null default 'female' ); insert into student2(name) values('alex'); create table student3( id int primary key auto_increment, name char(5), age int not null default 30 ); insert into student3(name) values('alex'); 2 unique #单列唯一 create table teacher( id int not null unique, name char(10) ); insert into teacher values(1,'egon'); insert into teacher values(1,'alex'); #多列唯一 #255.255.255.255 create table services( id int primary key auto_increment, name char(10), host char(15), port int, constraint host_port unique(host,port) ); insert into services values('ftp','192.168.20.17',8080); insert into services values('httpd','192.168.20.17',8081); #auto_increment_offset:偏移量 create table dep( id int primary key auto_increment, name char(10) ); insert into dep(name) values('IT'),('HR'),('SALE'),('Boss'); create table dep1( id int primary key auto_increment, name char(10) )auto_increment=10; insert into dep1(name) values('IT'),('HR'),('SALE'),('Boss'); #auto_increment_increment:步长 create table dep2( id int primary key auto_increment, name char(10) ); set session auto_increment_increment=2; #会话级,只对当前会话有效 set global auto_increment_increment=2; #全局,对所有的会话都有效 insert into dep1(name) values('IT'),('HR'),('SALE'),('Boss'); #auto_increment_offset:偏移量+auto_increment_increment:步长 注意:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 set session auto_increment_offset=2; set session auto_increment_increment=3; show variables like '%auto_in%'; create table dep3( id int primary key auto_increment, name char(10) ); insert into dep3(name) values('IT'),('HR'),('SALE'),('Boss'); #foreign key #!!!先建被关联的表,并且被关联的字段必须唯一 create table dep( id int primary key auto_increment, name varchar(50), comment varchar(100) ); create table emp_info( id int primary key auto_increment, name varchar(20), dep_id int, constraint fk_depid_id foreign key(dep_id) references dep(id) on delete cascade on update cascade ); #先给被关联的表初始化记录 insert into dep values (1,'欧德博爱技术有限事业部','说的好...'), (2,'艾利克斯人力资源部','招不到人'), (3,'销售部','卖不出东西'); insert into emp_info values (1,'egon',1), (2,'alex1',2), (3,'alex2',2), (4,'alex3',2), (5,'李坦克',3), (6,'刘飞机',3), (7,'张火箭',3), (8,'林子弹',3), (9,'加特林',3)
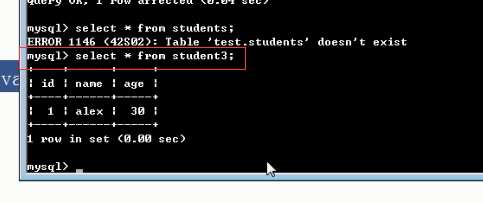
2)单列唯一