搜狗微信爬虫项目
目录
一、需求分析
1、概述
1.1 项目简介
- 基于搜狗微信搜索的微信公众号爬虫接口
2、需求分析
-
获取公众号信息
-
通过api,输入特定公众号,能查找相关信息
-
相关信息
{ 'public_name':str # 公众号名称 'wechat_id':str # 微信id "public_qrcode": url # 二维码 'public_image': url # 公众号图片 'authentication':str # 认证 'introduction': str #简介 } -
效果示例
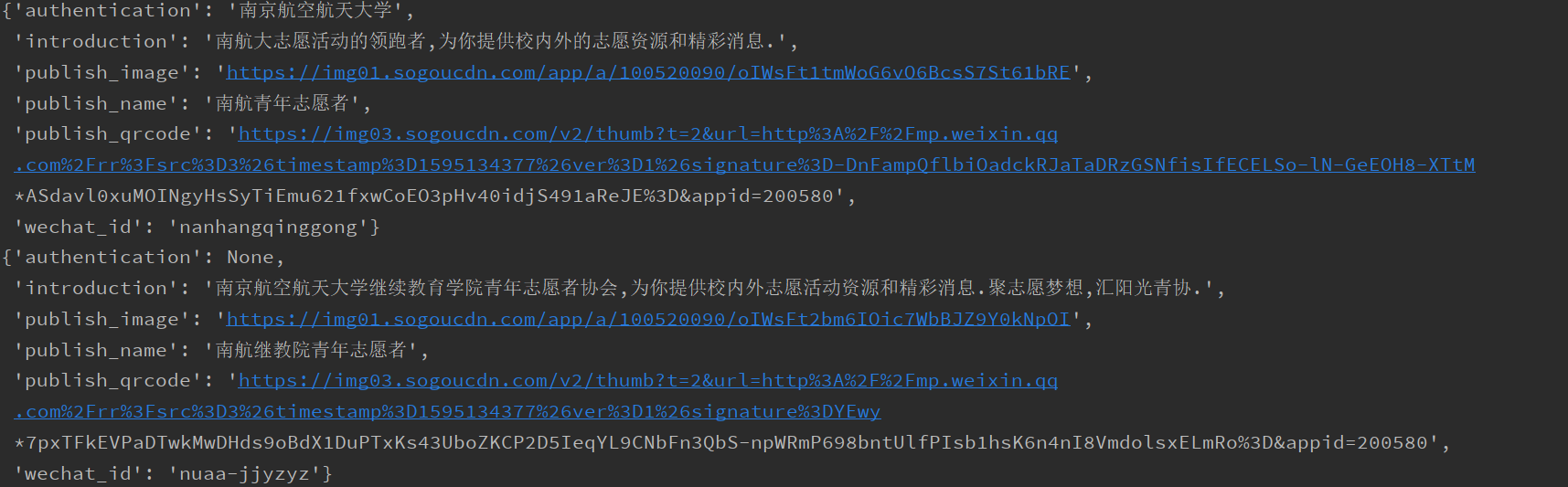
-
-
通过公众号名称搜索该公众号的所有文章
-
图片示例
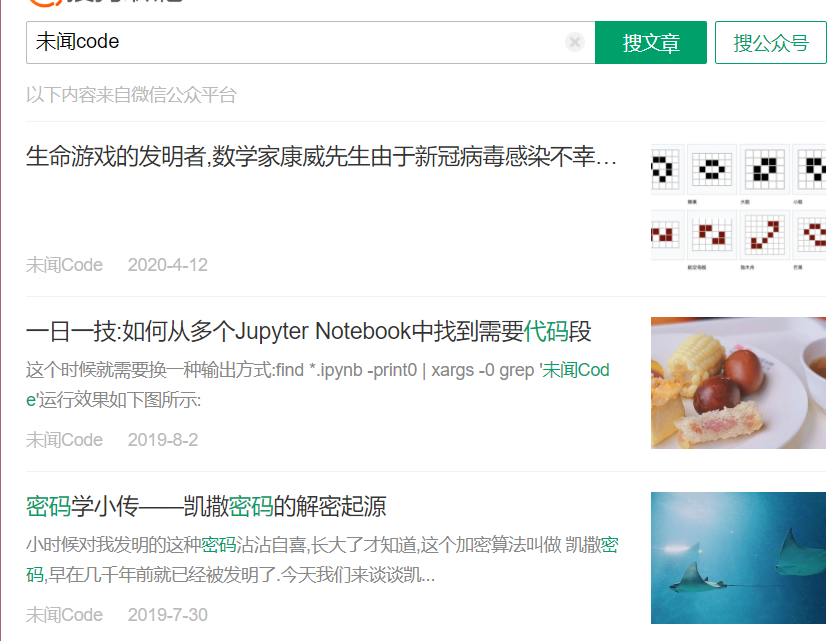
-
相关信息
{ 'article': { 'title': '', # 文章标题 'url': '', # 文章链接 'imgs': '', # 文章图片list 'abstract': '', # 文章摘要 'time': int # 文章推送时间 10位时间戳 }, 'gzh': { 'public_name':str # 公众号名称 'wechat_name':str # 微信名称 'wechat_id':str # 微信id "public_qrcode": url # 二维码 'public_image': url # 公众号二维码 'authentication':str # 认证 'introduction': str #简介 } }
-
二、数据来源分析
1、概述
1.1 目的
- 找到数据来源入口,并分析出相关的依赖
2、数据来源分析
2.1 首页
-
图片示例

-
url分析
-
url:
https://weixin.sogou.com/weixin?type=1&s_from=input&query=南航青年志愿者&ie=utf8&_sug_=n&_sug_type_= -
参数解析
- type区分类型
- type=1搜索公众号
- type=2搜索文章
- query为查询参数,需要通过
urllib.parse.quote()进行转换
- type区分类型
-
type=1时
- url:
https://weixin.sogou.com/weixin?type=1&s_from=input&query=南航青年志愿者&ie=utf8&_sug_=n&_sug_type_=
- url:
-
type=2时
- url:
[https://weixin.sogou.com/weixin?query=%E6%9C%AA%E9%97%BBcode&_sug_type_=&s_from=input&_sug_=n&type=2&page=1&ie=utf8](https://weixin.sogou.com/weixin?query=未闻code&_sug_type_=&s_from=input&_sug_=n&type=2&page=1&ie=utf8)
- url:
-
三、代码编写
1、获取公众号信息
-
效果示例
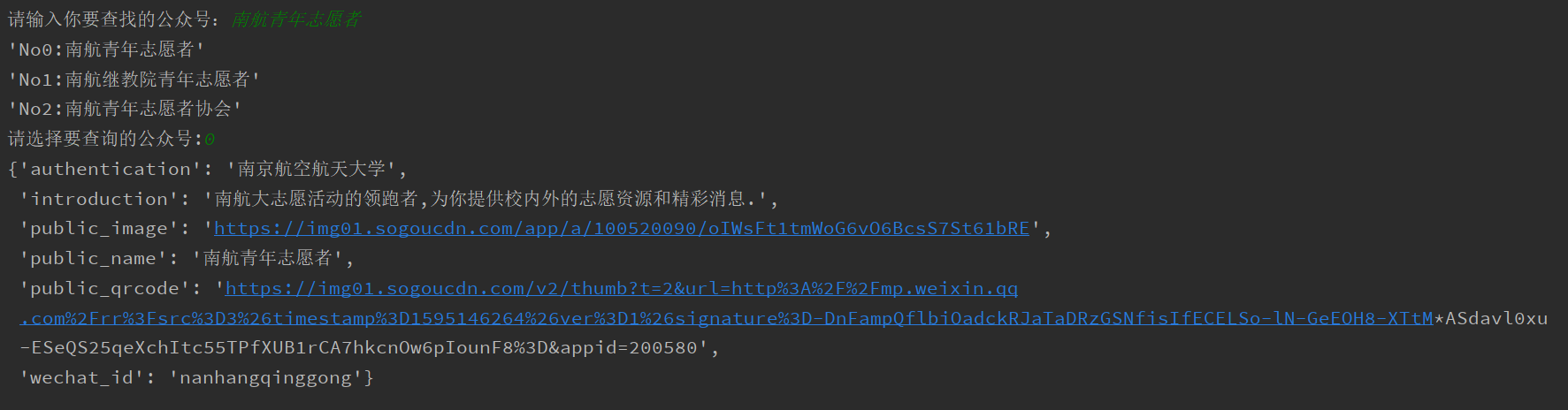
-
代码
import requests from urllib import parse from lxml import etree from pprint import pprint def process_list_content(content: list): if content: content_str = str() for a_str in content: content_str += a_str return content_str else: return None def process_html_str(html_str): html_str = etree.HTML(html_str) li_list = html_str.xpath('//ul[contains(@class, "news-list2")]/li') public_info = list() for li in li_list: item = dict() public_name = li.xpath('.//p[contains(@class, "tit")]/a//text()') item["public_name"] = process_list_content(public_name) wechat_id = li.xpath('.//p[contains(@class, "info")]/label/text()') item["wechat_id"] = wechat_id[0] if wechat_id else None publish_qrcode = li.xpath('.//div[contains(@class,"ew-pop")]//span[@class="pop"]/img[1]/@src') item["public_qrcode"] = publish_qrcode[0] if publish_qrcode else None publish_image = li.xpath('.//div[contains(@class,"ew-pop")]//span[@class="pop"]/img[2]/@src') item["public_image"] = "https:" + publish_image[0] if publish_image else None authentication = li.xpath('.//i[@class="identify"]/../text()') item['authentication'] = authentication[1] if authentication else None introduction = li.xpath('.//dl[1]/dd//text()') item["introduction"] = process_list_content(introduction) public_info.append(item) return public_info def public_search(public_name: str): public_name = parse.quote(public_name) base_url = "https://weixin.sogou.com/weixin?type=1&s_from=input&query={}&ie=utf8&_sug_=n&_sug_type_=" url = base_url.format(public_name) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36", } response = requests.get(url=url, headers=headers) if response.ok: return process_html_str(response.text) def public_search_api(public_name): public_info = public_search(public_name) for info in public_info: pprint("No{}:{}".format(public_info.index(info), info["public_name"])) num = int(input("请选择要查询的公众号:")) return public_info[num] def run(): public_name = input("请输入你要查找的公众号:") public_info = public_search_api(public_name) pprint(public_info) if __name__ == "__main__": # public_name = input("请输入你要查找的公众号:") # public_search_api(public_name) run()
2、获取公众号的文章信息
-
效果示例
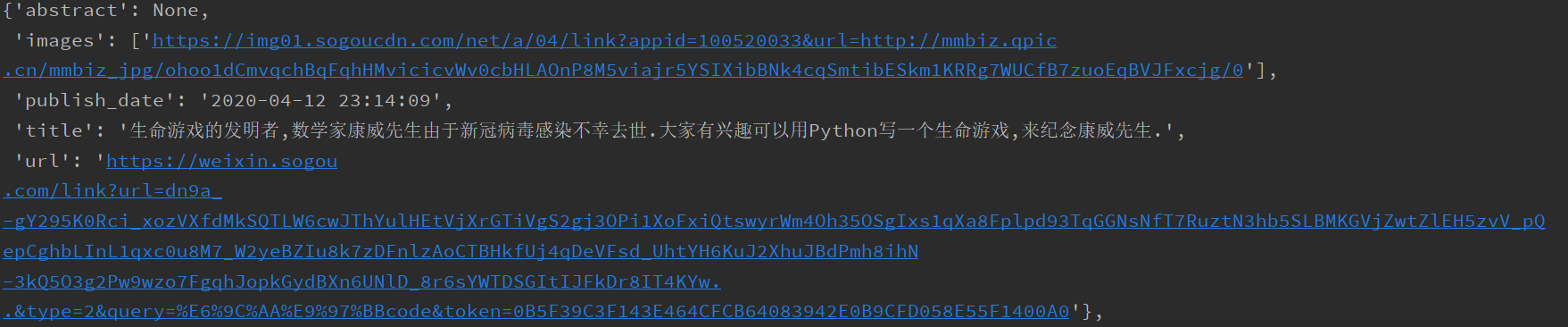
-
代码
from gevent import monkey monkey.patch_all() from gevent.pool import Pool import requests import time from urllib import parse from lxml import etree from pprint import pprint def process_list_content(content: list): if content: content_str = str() for a_str in content: content_str += a_str return content_str else: return None def process_timestamp(content: int): return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(content)) def process_html_str(html_str: str): html_str = etree.HTML(html_str) li_list = html_str.xpath('//ul[contains(@class,"news-list")]/li') article_list = list() for li in li_list: article = dict() title = li.xpath('.//div[contains(@class,"txt-box")]/h3/a//text()') article['title'] = title[0] if title else None url = li.xpath('.//div[contains(@class,"txt-box")]/h3/a/@href') article['url'] = "https://weixin.sogou.com" + url[0] if url else None images = li.xpath('.//div[contains(@class,"img-box")]//img/@src') article['images'] = ['https:' + i for i in images] if images else None abstract = li.xpath('.//p[contains(@class,"txt-info")]/text()') article['abstract'] = process_list_content(abstract) timestamp = li.xpath('.//div[@class="s-p"]/@t') article['publish_date'] = process_timestamp(int(timestamp[0])) if timestamp else None article_list.append(article) return article_list def process_prepare_work(public_name: str): public_name = parse.quote(public_name) base_url = "https://weixin.sogou.com/weixin?type=2&s_from=input&query={}&ie=utf8&_sug_=n&_sug_type_=&page={}" url_list = [base_url.format(public_name, i) for i in range(1, 11)] return url_list def process_request(url): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36", } try: response = requests.get(url=url, headers=headers) if response.ok: article_s = process_html_str(response.text) return article_s except Exception: pass def public_article(public_name: str): url_list = process_prepare_work(public_name) pool = Pool(3) article_list = pool.map(process_request, url_list) a = list() for a_ in article_list: for a__ in a_: a.append(a__) return a if __name__ == "__main__": public_name = "未闻code" article_list = public_article(public_name) pprint(article_list)
3、通过公众号名字,获取公众号信息和其前100篇文章
-
效果示例
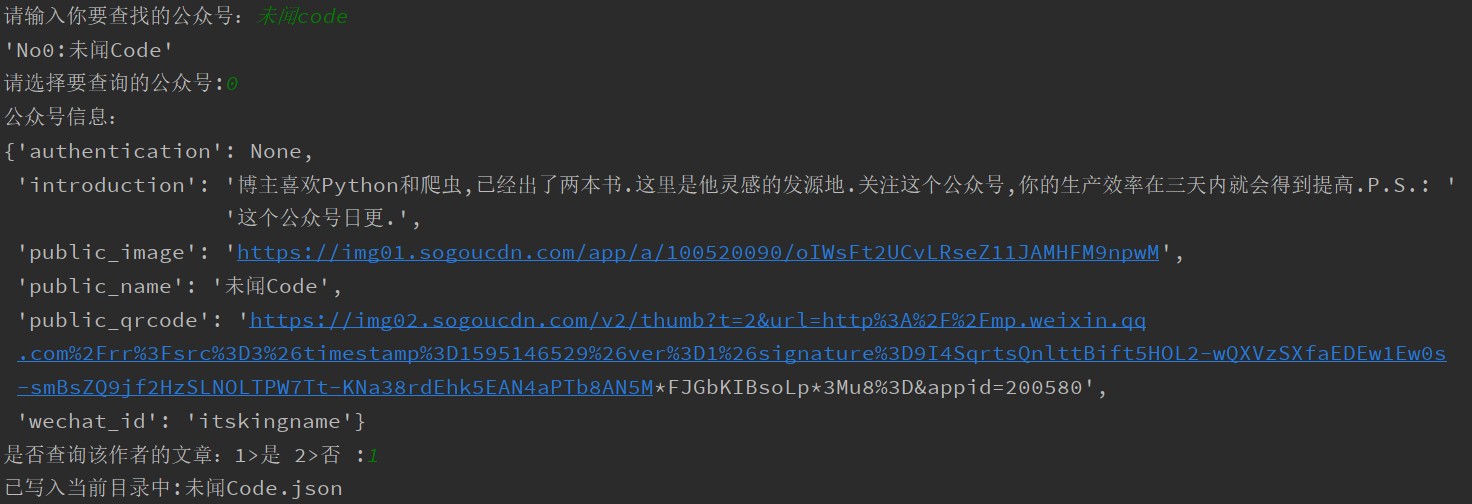
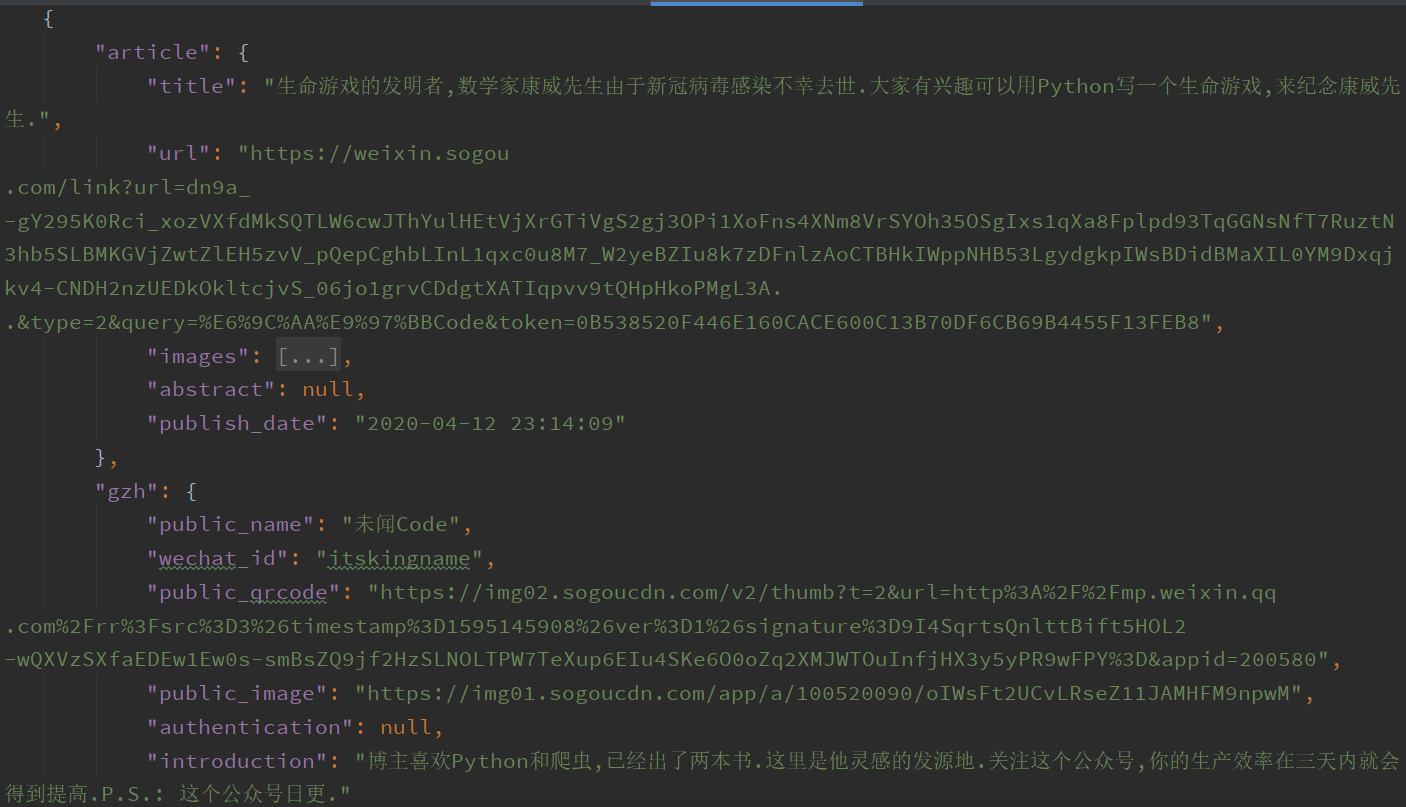
-
代码
from pprint import pprint import json from sougoweixin.test.public_article_test import public_article from sougoweixin.test.public_search_test import public_search_api def add_info_article(public_aritcle_list, public_info): public_aritcle_info_list = list() for public_aritcle in public_aritcle_list: item = dict() item["article"] = public_aritcle item['gzh'] = public_info public_aritcle_info_list.append(item) return public_aritcle_info_list def save_info_to_file(article_info, author_info): file_name = author_info['public_name']+"的文章" with open('{}.json'.format(file_name), 'a+', encoding='utf8') as f: f.write(json.dumps(article_info, ensure_ascii=False, indent=4)) def process_console(): public_name = input("请输入你要查找的公众号:") public_info = public_search_api(public_name) print("公众号信息:") pprint(public_info) num = input("是否查询该作者的文章:1>是 2>否 :") if num == "1": public_article_list = public_article(public_info['public_name']) public_article_list = add_info_article(public_article_list, public_info) save_info_to_file(public_article_list, public_info) print("已写入当前目录中:{}.json".format(public_info['public_name'])) else: print("欢迎再次使用") if __name__ == "__main__": process_console()
四、总结
1、总结
- 通过搜狗微信的第三方接口,获取对应信息,并不困难
- 在获取文章的发布时间时,只能拿到时间戳,通过
time.strftime("fmt", time.localtime(timestamp))进行转换,便能拿到 - 通过本例,熟悉了
gevent的使用,当使用协程池时,对应函数,返回值是一个值组成的列表 - 实现了,通过公众号名称进行搜索时,相关公众号的选择
- 可能是未登录,未见反爬虫措施(已使用user_agent)
2、改进
- 目前只能拿到当前公众号的前100篇文章,需要登录才能获取更多的文章信息````