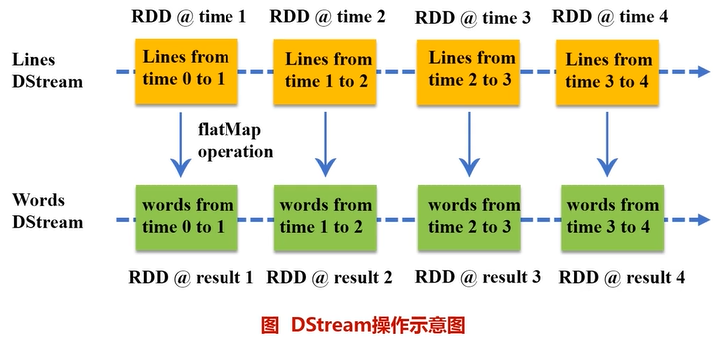
一、Spark Streaming工作机制

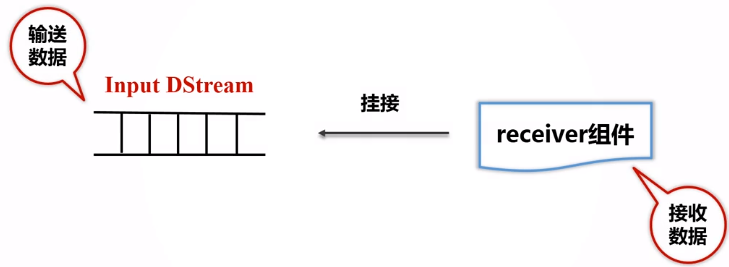
- 在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的task跑在一个Executor上;
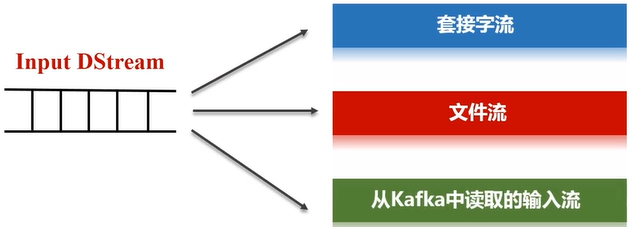
- 每个Receiver都会负责一个input DStream(比如从文件中读取数据的文件流,比如套接字流,或者从Kafka中读取的一个输入流等等);
- Spark Streaming通过input DStream与外部数据源进行连接,读取相关数据。
二、Spark Streaming程序的基本步骤
1.通过创建输入DStream来定义输入源;
2.通过对DStream应用转换操作和输出操作来定义流计算;
3.用streamingContext.start()来开始接收数据和处理流程;
4.通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束);
5.可以通过streamingContext.stop()来手动结束流计算进程。
三、创建StreamingContext对象
如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。
(1)可以从一个SparkConf对象创建一个StreamingContext对象登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkConext,也就是sc。因此,可以采用如下方式来创建StreamingContext对象:【ssc是streamingcontext的缩写,sc是sparkcontext的缩写,Seconds(1)表示每隔1s去切分数据流】

(2)如果是编写一个独立的Spark Streaming程序,而不是在spark-shell中运行,则需要通过如下方式创建StreamingContext对象:

参考文献: