1. Classic networks
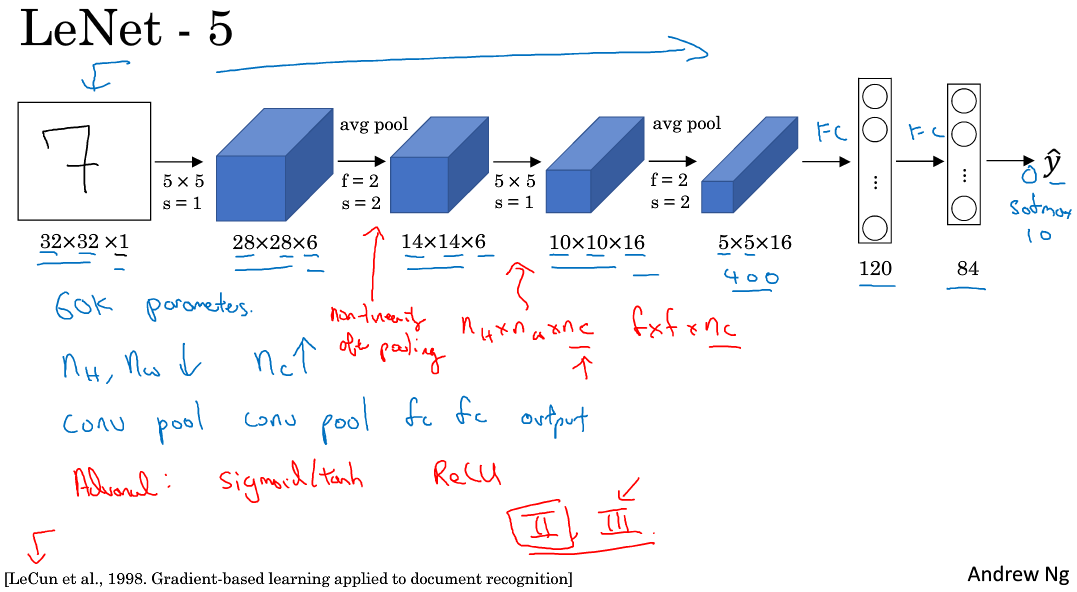
(1)LeNet-5
该LeNet模型总共包含了大约6万个参数。当时Yann LeCun提出的LeNet-5模型池化层使用的是average pool,而且各层激活函数一般是Sigmoid或tanh。现在,一般池化层使用Max pool,激活函数用ReLU。
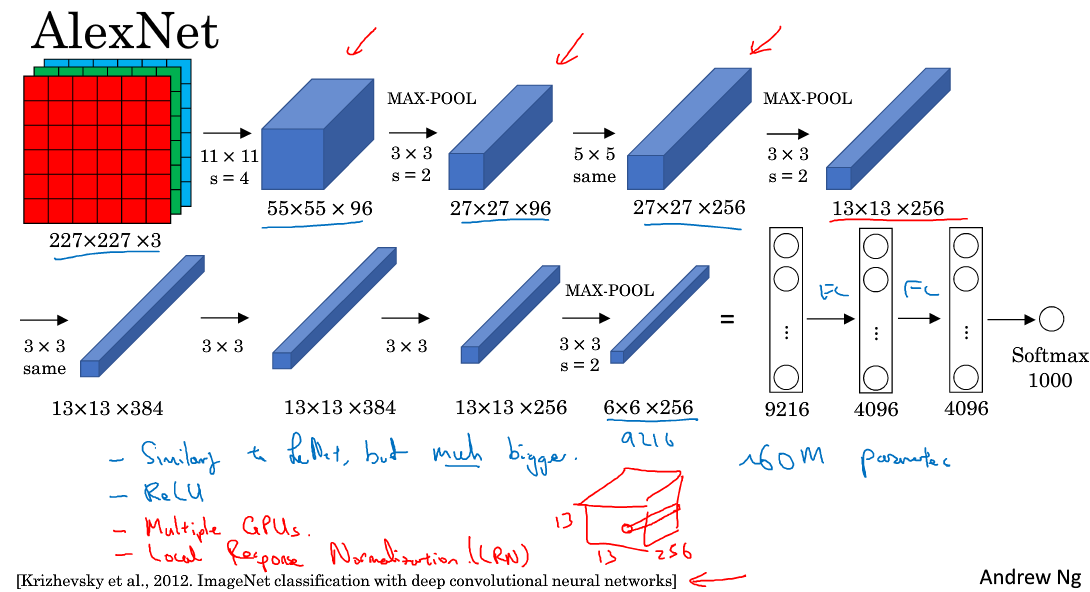
(2)AlexNet
图中same的意思是用padding填充使输出图像与输入图像保持大小一致。AlexNet模型与LeNet-5模型类似,只是要复杂一些,总共包含了大约6千万个参数。同样可以根据实际情况使用激活函数ReLU。原作者还提到了一种优化技巧,叫做Local Response Normalization(LRN)。 而在实际应用中,LRN的效果并不突出
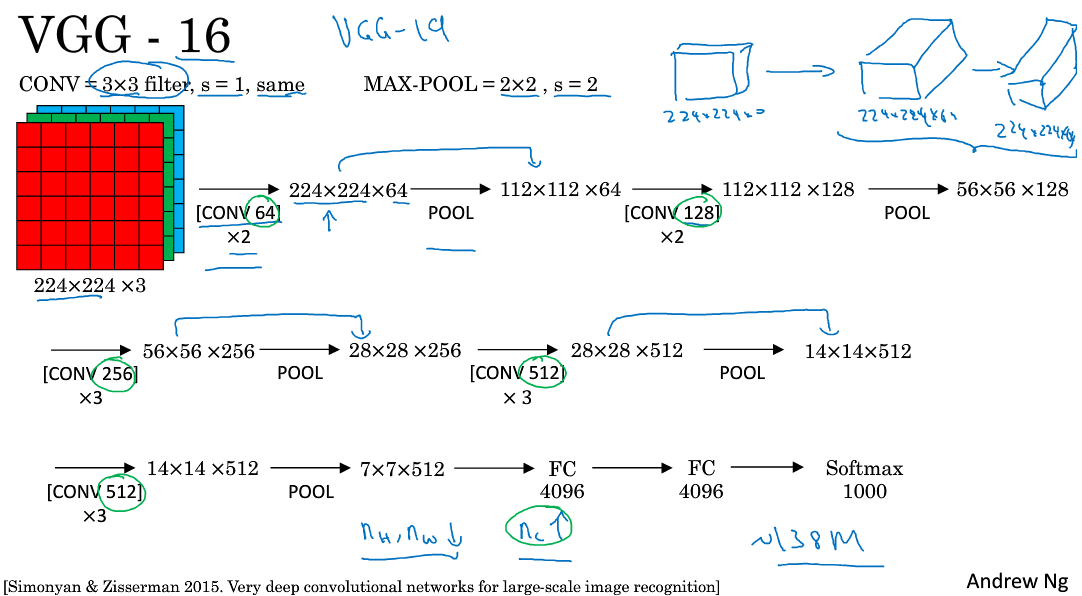
(3)VGG-16
VGG中所有卷积都采用了padding填充使输出图像尺寸与输入图像一样,所有filter都是3x3,步长为1,图中CONV 64x2表示用64个filter卷积2次,其他同理。
VGG-16网络的一大优点是简化了神经网络的结构,16是卷积层和全连接层的总数,一共1.38亿个参数,虽然神经网络很大,但是结构很简单很规整。缺点就是需要训练的特征数量巨大。
这篇论文很吸引人的一点是,它揭示了图像缩小的比例和信道增加的比例是有规律且相关。
2.Residual networks 残差网络
神经网络层数越多,网络越深,就越容易梯度消失和梯度爆炸,解决方法之一就是残差网络。
人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。
(1)Residual block残差块
Residual Networks由许多隔层相连的神经元子模块组成,我们称之为Residual block。单个Residual block的结构如下图所示:
【1】shortcut捷径
【2】skip connection跳远连接
跳远连接和捷径类似,它一次跳过一层或多层,可以作用到网络的更深处。
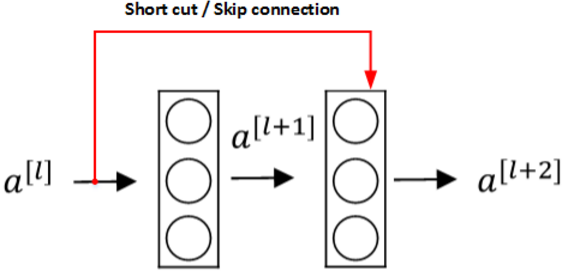
![如上图捷径就是a[l]跳过a[l+1]和z[l+2]一起生成a[l+2]](https://img-blog.csdnimg.cn/20181029100102222.)
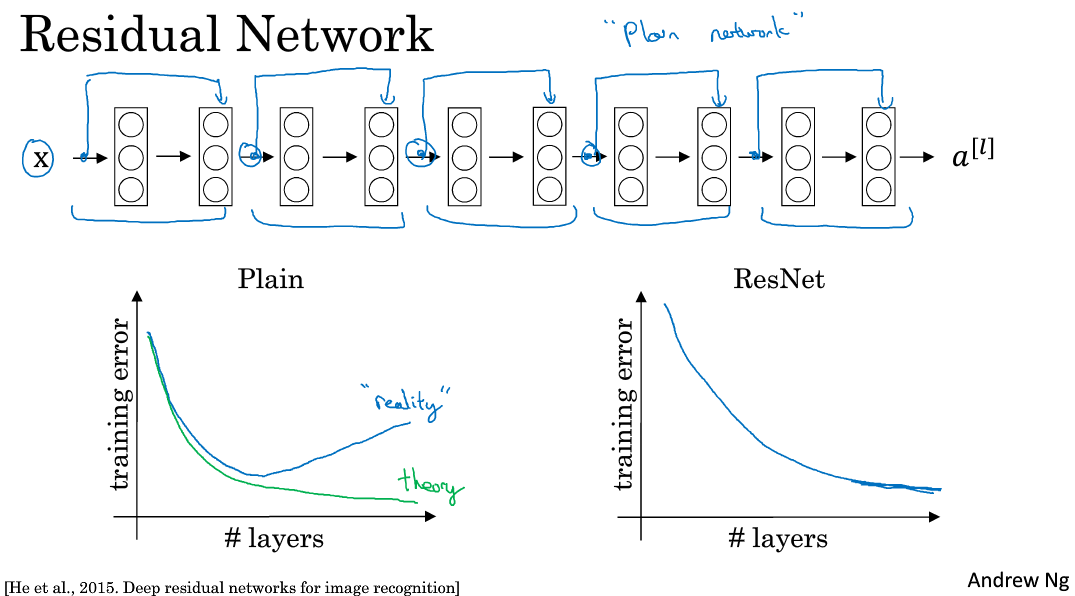
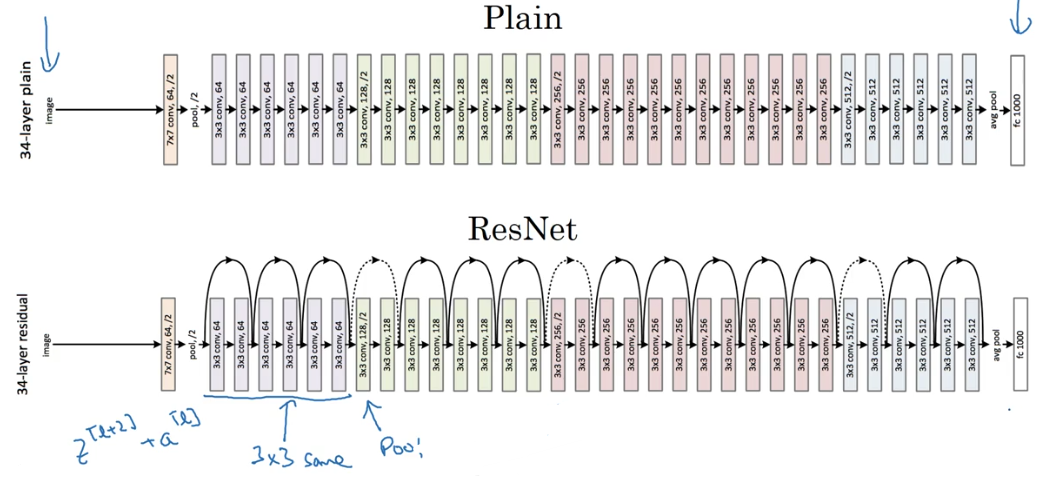
实验表明,这种模型结构对于训练非常深的神经网络,效果很好。另外,为了便于区分,我们把非Residual Networks称为Plain Network。与Plain Network相比,Residual Network能够训练更深层的神经网络,有效避免发生发生梯度消失和梯度爆炸。从下面两张图的对比中可以看出,随着神经网络层数增加,Plain Network实际性能会变差,training error甚至会变大。然而,Residual Network的训练效果却很好,training error一直呈下降趋势。
3.Why ResNets Work
(1)为什么残差网络能起作用?
如上图,给一个很大的神经网络增加了两层,可以看出如果发生梯度消失,那么相当于将(a^{[l]})复制给(a^{[l+2]})(激活函数为ReLU的情况下),即恒等函数,也就是新增加的两层即使在最坏的情况下也不会导致网络性能下降,而且恒等函数的计算也是极为简单的,所以残差网络有利于构建更深的神经网络。
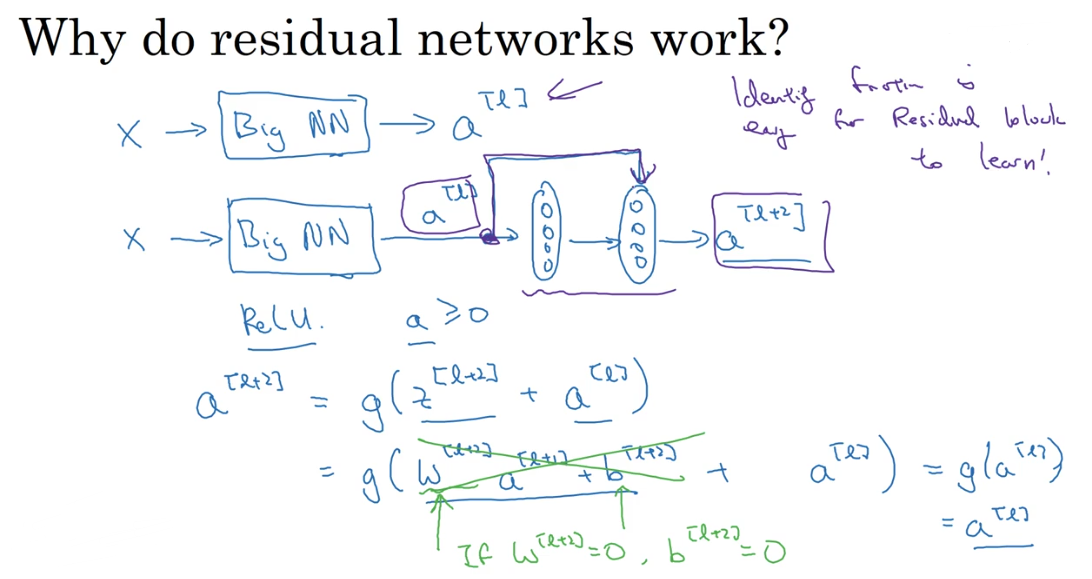
这样,看似很深的神经网络,其实由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系,模型本身也就能“容忍”更深层的神经网络了。而且从性能上来说,这两层额外的Residual blocks也不会降低Big NN的性能。
2)如果(a^{[l]})层和(a^{[l+2]})维度不同应该怎么办?
ResNets同类型层之间,例如CONV layers,大多使用same类型,保持维度相同。如果是不同类型层之间的连接,例如CONV layer与POOL layer之间,如果维度不同,则引入权重矩阵(W_s)。
假设(a^{[l]})维度((n^{[l]},1),a^{[l+2]})维度是((n^{[l+2]},1)),权重矩阵(W_s(n^{[l+2]},n^{[l]})),矩阵可以通过后向传播学习获得,也可以是填充值为0的固定矩阵。
4. Networks in Networks and 1x1 Convolutions
(1) 1x1的卷积核/网络中的网络
Min Lin, Qiang Chen等人提出了一种新的CNN结构,即1x1 Convolutions,也称Networks in Networks。这种结构的特点是滤波器算子filter的维度为1x1。对于单个filter, 1x1的维度,意味着卷积操作等同于乘积操作。
对于多个filters,1x1 Convolutions的作用实际上类似全连接层的神经网络结构, 效果等同于Plain Network中(a^{[l]})到(a^{[l+1]})的过程, 这点还是比较好理解的。
下面动态图更能理解,只不过filter size为3x3,把他看成1x1就好了
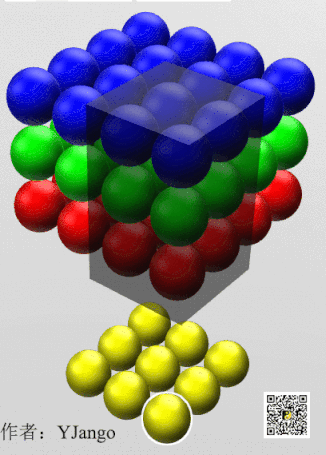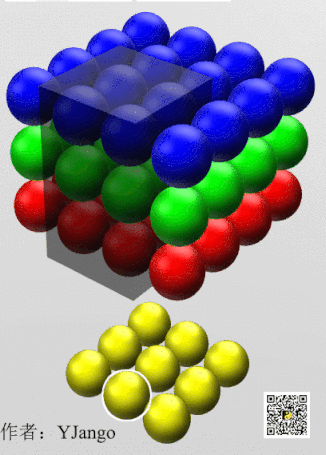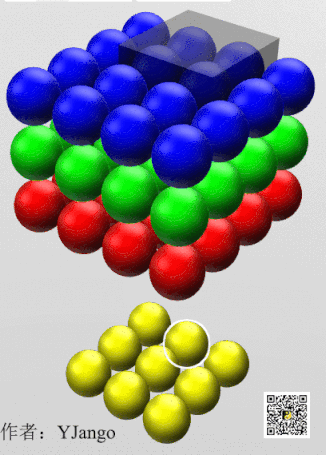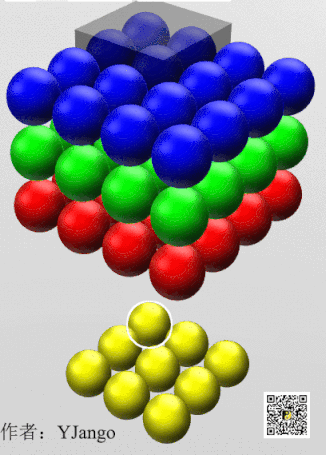
下面举例讲述其应用:
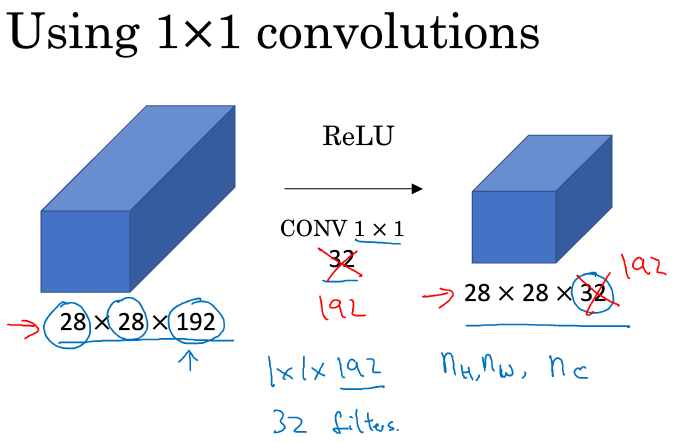
对于一幅图像,若要压缩它的高宽,可以通过pooling池化,那么如果信道数目太多呢,可以用network in network,如下图,用32个1x1x192的卷积核可以将图像通道从192压缩到32:
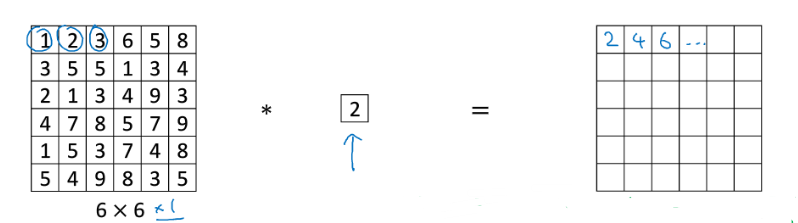
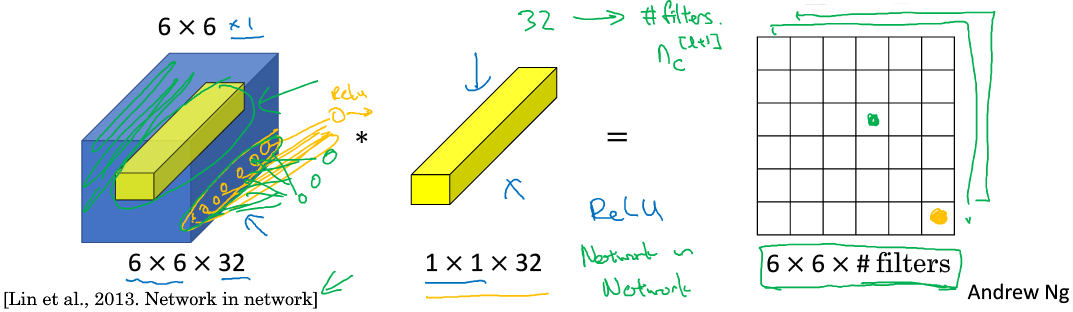
5.谷歌 Inception网络简介
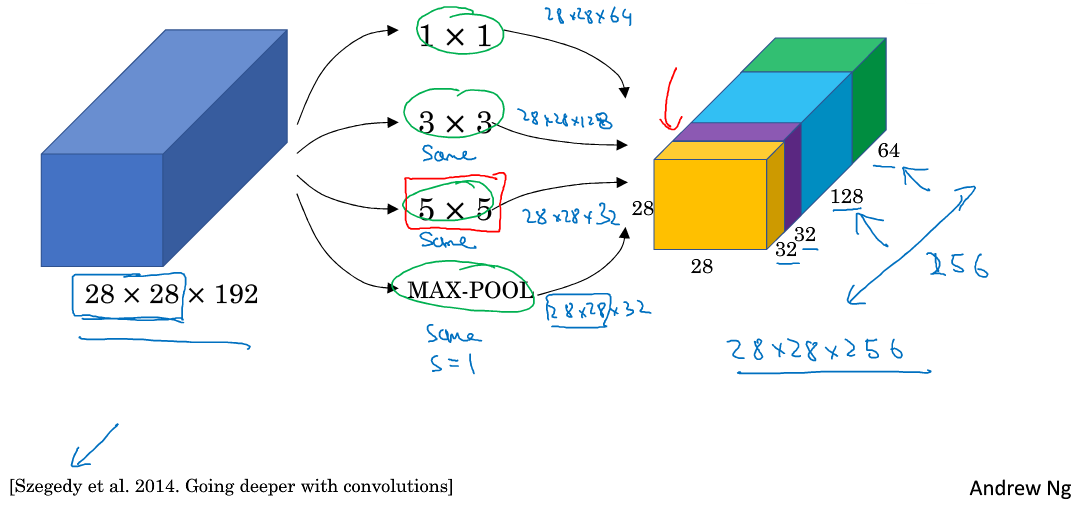
之前我们介绍的CNN单层的滤波算子filter尺寸是固定的,1x1或者3x3等。而Inception Network在单层网络上可以使用多个不同尺寸的filters,进行same convolutions,把各filter下得到的输出拼接起来。除此之外,还可以将CONV layer与POOL layer混合,同时实现各种效果。但是要注意使用same pool。
Inception Network由Christian Szegedy, Wei Liu等人提出。与其它只选择单一尺寸和功能的filter不同,Inception Network使用不同尺寸的filters并将CONV和POOL混合起来,将所有功能输出组合拼接,再由神经网络本身去学习参数并选择最好的模块。
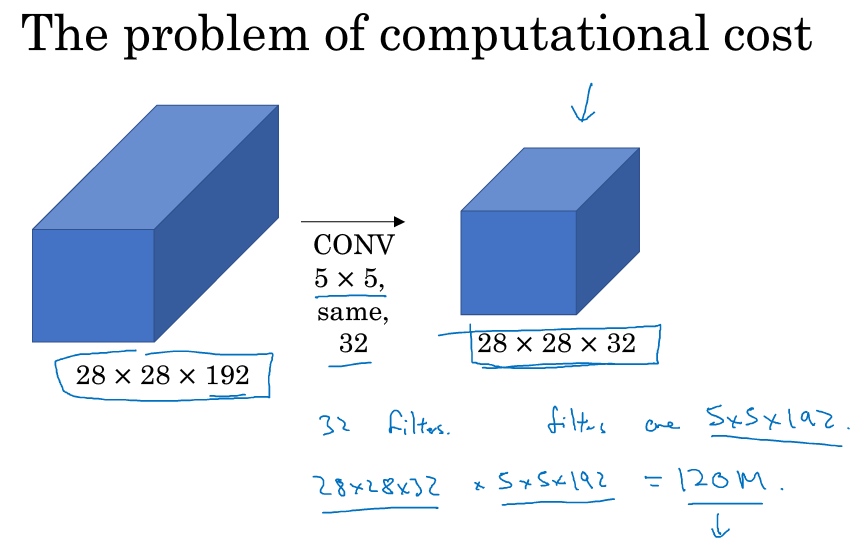
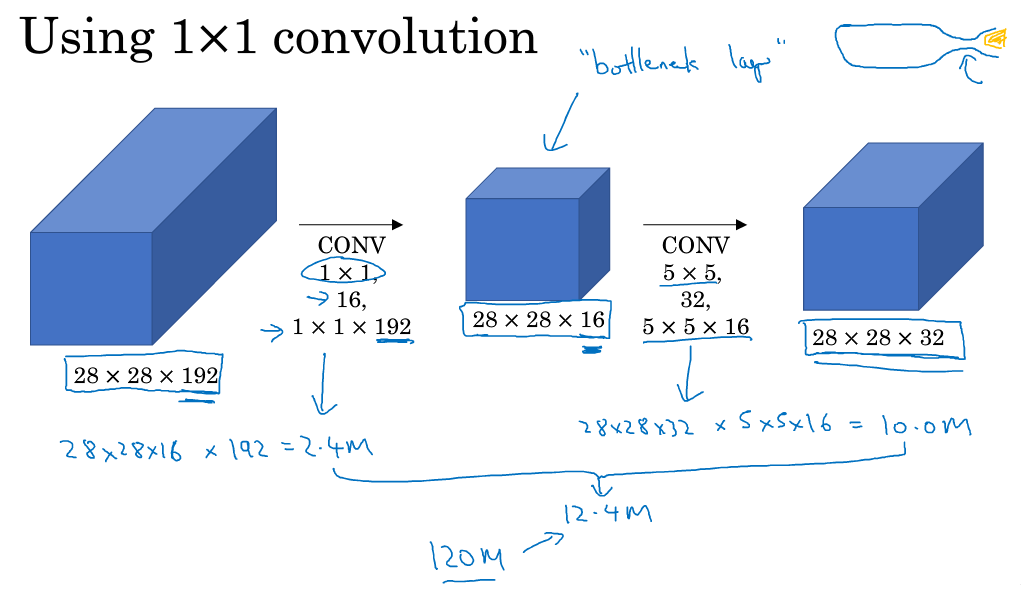
Inception Network在提升性能的同时,会带来计算量大的问题。例如下面这个例子:
此CONV layer需要的计算量为:28x28x32x5x5x192=120m,其中m表示百万单位。可以看出但这一层的计算量都是很大的。为此,我们可以引入1x1 Convolutions来减少其计算量,结构如下图所示:
通常我们把该1x1 Convolution称为“瓶颈层”(bottleneck layer)。引入bottleneck layer之后,总共需要的计算量为:28x28x16x192+28x28x32x5x5x16=12.4m。明显地,虽然多引入了1x1 Convolution层,但是总共的计算量减少了近90%,效果还是非常明显的。由此可见,1x1 Convolutions还可以有效减少CONV layer的计算量,同时只要合理构建,不会影响网络性能。
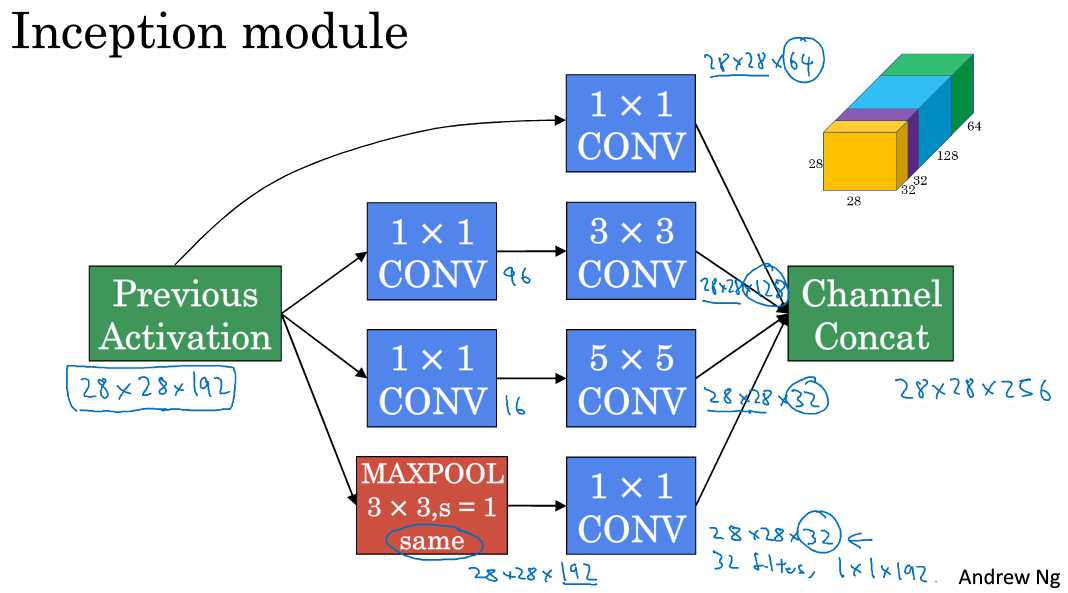
6. Inception网络
(1)下面是Inception的一个单元,需要注意的是池化时保持尺寸不变,同时池化不能改变通道数导致通道特别多,所以在其后面添加了1×1卷积核压缩通道。
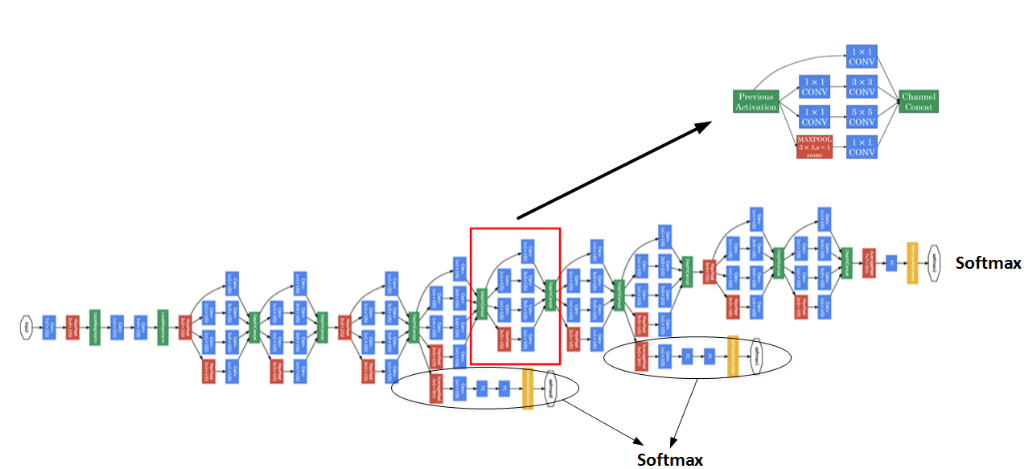
多个Inception modules组成Inception Network,效果如下图所示:
上述Inception Network除了由许多Inception modules组成之外,值得一提的是网络中间隐藏层也可以作为输出层Softmax,有利于防止发生过拟合。
7 Transfer Learning 【参考机器学习策略(二)】
(1)下载别人的模型,以前预训练的权重来初始化,同时将输出层根据自己的需要来修改,比如说分三种类别(已经包括其它了),那么输出为3个单元的sotfmax。
(2)冻结别人训练好的参数,在深度学习框架中可能参数是trainableParameter=0,或者freeze=1等,视实际框架而定。
(3)一个重要技巧是:数据量少时只训练最后一层,这时可以将图片输入,然后将最后一层前的输出存到硬盘中,因为这些值是不会改变的。然后在用这些值作为输入训练最后一层,这样不要每次都经过前面的网络,训练会大大加快。
(4)当数据量越来越大时,从后往前可以训练更多的层,极端情况下是所有层的参数都参与训练。
8 Data Augmentation
常用的Data Augmentation方法是对已有的样本集进行Mirroring和Random Cropping。
(1)镜像、随机裁剪、旋转、剪切、扭曲
(2)色彩转换(如给一些通道加值)
(3)在实际使用过程中可以使用多线程,一些线程从硬盘中取出数据,然后进行数据扩充,再传入其他线程进行训练,这样就可以并行实现了。
9 计算机视觉现状
(1)对于计算机视觉而言,其实当前的数据量是远远不够的,所以需要设计出一些更复杂的网络,以及人工去调整非常多的超参数,其本质都是因为数据量不够;假设数据量非常够的时候,网络也好,超参数也好都可以使用更简单的架构和调整。
(2)再次强调多多使用迁移学习,站在巨人的肩膀上。另外如果要自己设计研究全新的网络可能需要自己从头开始训练。
(3)为了在竞赛中取得好成绩,常常是以巨大的计算量为代价的(如用多个网络计算输出取平均),这在实际应用中不太实用。