raid技术分类可以分为基于软件raid技术和基于硬件raid技术
raid又分为raid-0、raid-1、raid-5和raid-10
Raid有”廉价磁盘冗余阵列”的意思,就是利用多块廉价的硬盘组成磁盘组,让数据分部储存在这些硬盘里面,从而达到读取和写入加速的目的;也可以用作数 据的冗余,当某块硬盘损毁后,其他硬盘可以通过冗余数据计算出损坏磁盘的数据,这样就提高了数据储存的安全性。可以提供较普通磁盘更高的速度、安全性,所 以服务器在安装时都会选择创建RAID。RAID的创建有两种方式:软RAID(通过操作系统软件来实现)和硬RAID(使用硬件阵列卡)。
软raid技术
在Linux下安装系统的过程中或者安装系统后通过自带的软件就能实现raid功能,使用软raid可省去购买硬件raid控制器和附件就能极大地增强磁 盘的IO性能和可靠性,由于是用软件实现的raid功能,所以它配置灵活,管理方便,同时使用软件raid,还可以将几个物理磁盘合并成一个更大的虚拟设备,从而达到性能改进和数据冗余的目的
硬raid技术
基于硬件raid解决方案比基于软件raid技术在使用性能和服务性能上会更胜一筹,具体表现在检测和修复多位错误的能力,错误磁盘自动检测和阵列重建等方面,从安全性能考虑,基于硬件的raid解决方案也是更安全的,因此,在实际的生产场景工作中,基于硬件的raid解决方案应该是我们的首选,互联网公司常用的生产dell服务器,默认就会支持raid0,1。如果raid5,10就需要买raid卡(或者个别配置自带有,购买前,看参数)
与lvm区别
LVM(Logical Volume Manager)是Linux环境下对硬盘分区进行管理的一种机制,可以实现多块硬盘空间的动态划分和调整,跨硬盘储存文件等功能。常用于装备大量硬盘并随时需要增加或删除硬盘的环境,也同样适于仅有一、两块硬盘的环境。(可以灵活的管理磁盘容量,让磁盘分区随意变大变小,便于管理磁盘剩余的容量)如果过于强调性能和备份,还是优先选择硬件raid功能
磁盘阵列可以把多个磁盘驱动器通过不同的连接方式连接在一起协同办公,大大提高了读写速度,同时把磁盘系统的可靠性提高到接近无措的境界,使其可靠性极高。
用raid最直接的好处是:
提高数据安全性
提升数据读写性能
提供更大的单一逻辑磁盘数据容量存储
RAID-0

RAID-0 :striping(条带模式)特点:在读写的时候可以实现并发,所以相对其读写性能最好,每个磁盘都保存了完整数据的一部分,读取也采用并行方式,磁盘 数量越多,读取和写入速度越快。因为没有冗余,一个硬盘坏掉全部数据丢失。至少两块硬盘才能组成Raid0阵列。
容量:所有硬盘之和。磁盘利用率为100%。
生产应用场景
1、负载均衡集群下面的多个相同RS节点服务器
2、分布式文件存储下面的主节点或CHUNK server
3、MySQL主从复制的多个slave服务器
4、对性能要求很高,对冗余要求很低的相关业务
RAID-1

RAID-1 :mirroring(镜像卷),至少需要两块硬盘,raid大小等于两个raid分区中最小的容量(最好将分区大小分为一样),数据有冗余,在存储时同时写入两块硬盘,实现了数据备份;
磁盘利用率为50%,即2块100G的磁盘构成RAID1只能提供100G的可用空间。
RAID-5

特点:采用奇偶校验,可靠性强,磁盘校验和被散列到不同的磁盘里面,增加了读写速率。只有当两块磁盘同时丢失时,数据才无法恢复,至少三块硬盘并且硬盘大小应该相等才能组成Raid5阵列。
容量:所有硬盘容量之和减去其中一块硬盘的容量,被减去的容量被分配到三块硬盘的不同区域用来存放数据校验信息。
RAID-10
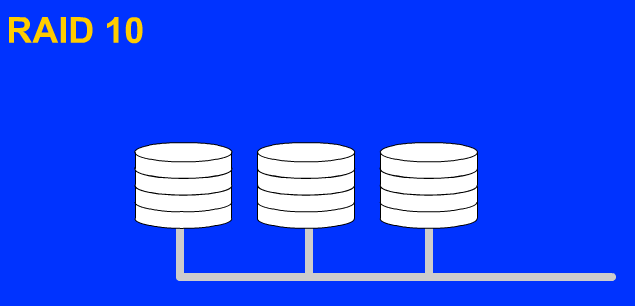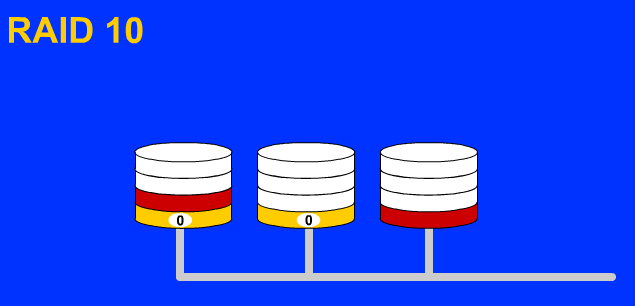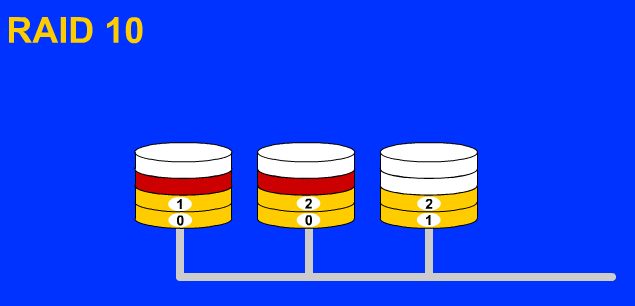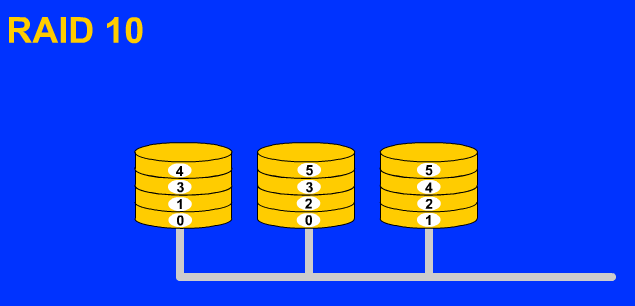
Raid10(Raid1+Raid0)是现在比较常用的一种磁盘阵列级别,它的容错好,读写数据效率较高,但经费相对也较高。
特 点:备份和并发式存取数据,可靠性强。D1、D2组成一个阵列Raid1,其中D1是数据盘,D2是备份盘;D3、D4也组成一个Raid1,其中D3是 数据盘,D4是备份盘;在这个基础上将D1、D2作为一个整体,将D3、D4也作为一个整体,这两个整体之间再组成一个Raid0阵列。这样不仅仅读取数 据会非常快,并发写入的速度也会随着磁盘的增多而变快。至少四块硬盘并且每块硬盘大小应该相等才能组成Raid10阵列。
容量:所有硬盘容量之和的一半(一半写数据,一半用来备份数据)。
raid命令行管理
CentOS7中mdadm默认已安装,如果没有安装,可以使用yum安装
主要用到的命令:mdadm
参数: -C或–creat 建立一个新阵列 -r 移除设备 -A 激活磁盘阵列 -l 或–level= 设定磁盘阵列的级别 -D或–detail 打印阵列设备的详细信息 -n或–raid-devices= 指定阵列成员(分区/磁盘)的数量 -s或–scan 扫描配置文件或/proc/mdstat得到阵列缺失信息 -x或–spare-devicds= 指定阵列中备用盘的数量 -f将设备状态定为故障 -c或–chunk= 设定阵列的块chunk大小 ,单位为KB -a或–add 添加设备到阵列 -G或–grow 改变阵列大小或形态 -v –verbose 显示详细信息
案例:创建一个raid10+冗余盘
共7块盘,创建一个raid 10 使用4块盘,热备2块,使用中1块出现故障,热备顶上,再加一块热备,把坏的T下来
1.创建raid阵列
1 [root@localhost ~]# mdadm -C /dev/md0 -a yes -l 10 -n 4 -x 2 /dev/sd{b,c,d,e,f,g}
2.查看raid阵列信息
1 [root@localhost ~]# cat /proc/mdstat 2 Personalities : [raid10] 3 md0 : active raid10 sdg[5](S) sdf[4](S) sde[3] sdd[2] sdc[1] sdb[0] 4 41910272 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU] 5 [=====>...............] resync = 27.5% (11542784/41910272) finish=2.4min speed=206250K/sec 6 7 unused devices: <none> 8 // 四块盘在用,两块S热备
3.生成配置文件
1 [root@localhost ~]# mdadm -D --scan > /etc/mdadm.conf
4.格式化挂载使用
1 [root@localhost ~]# mkfs.ext4 /dev/md0 2 [root@localhost ~]# mkdir /data 3 [root@localhost ~]# mount /dev/md0 /data/ 4 [root@localhost ~]# df -h 5 Filesystem Size Used Avail Use% Mounted on 6 /dev/mapper/vg0-root 20G 333M 19G 2% / 7 tmpfs 491M 0 491M 0% /dev/shm 8 /dev/sda1 190M 34M 147M 19% /boot 9 /dev/mapper/vg0-usr 9.8G 1.9G 7.4G 21% /usr 10 /dev/mapper/vg0-var 20G 113M 19G 1% /var 11 /dev/md0 40G 48M 38G 1% /data 12 //我一块20G,raid10一半数据,一半备份数据
5.模拟故障一个磁盘
1 [root@localhost ~]# du -sh /data/ 2 1.4M /data/ 3 //输入命令或者直接把硬盘断开连接 4 [root@localhost ~]# mdadm /dev/md0 -f /dev/sdb 5 mdadm: set /dev/sdb faulty in /dev/md0 6 [root@localhost ~]# cat /proc/mdstat 7 Personalities : [raid10] 8 md0 : active raid10 sdg[5] sdf[4](S) sde[3] sdd[2] sdc[1] sdb[0](F) 9 41910272 blocks super 1.2 512K chunks 2 near-copies [4/3] [_UUU] 10 [=>...................] recovery = 6.6% (1400064/20955136) finish=1.6min speed=200009K/sec 11 12 unused devices: <none> 13 // sdb (F) 故障状态了,原来sdg的S没有了,说明,已经顶上去了 14 [root@localhost ~]# du -sh /data/ 15 1.4M /data/ 16 //数据没有丢失
6.把坏的T下去,把新硬盘加上去
1 //把故障硬盘卸载下来 2 [root@localhost ~]# mdadm -r /dev/md0 /dev/sdb 3 mdadm: hot removed /dev/sdb from /dev/md0 4 //添加新的硬盘 5 [root@localhost ~]# mdadm -a /dev/md0 /dev/sdh 6 mdadm: added /dev/sdh 7 8 [root@localhost ~]# cat /proc/mdstat 9 Personalities : [raid10] 10 md0 : active raid10 sdh[6](S) sdg[5] sdf[4](S) sde[3] sdd[2] sdc[1] 11 41910272 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU] 12 //查看状态,已经发现新硬盘,旧硬盘已经没有了 13 unused devices: <none> 14 [root@localhost ~]# mdadm -D /dev/md0 15 Number Major Minor RaidDevice State 16 5 8 96 0 active sync set-A /dev/sdg 17 1 8 32 1 active sync set-B /dev/sdc 18 2 8 48 2 active sync set-A /dev/sdd 19 3 8 64 3 active sync set-B /dev/sde 20 21 4 8 80 - spare /dev/sdf 22 6 8 112 - spare /dev/sdh 23 //阵列还是原来的,没变