github地址:https:/github.com/muzhailong/wc.git
第一次写博客很不容易,也算是一个好的开始吧。
1. 个人作业要求
作业简述:根据WordCount的需求描述,先编程实现,再编写单元测试,最后撰写博客。
参数及其约定如下:
基本功能:

扩展功能:
wc.exe -s //递归处理目录下符合条件的文件 wc.exe -a file.c //返回更复杂的数据(代码行 / 空行 / 注释行) wc.exe -e stopList.txt // 停用词表,统计文件单词总数时,不统计该表中的单词
高级功能:
wc.exe -x //该参数单独使用,如果命令行有该参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、单词数、行数等全部统计信息。
2. 完成作业过程:
1.写PSP,根据自己的能力还有任务量写就ok
| PSP阶段 | 预计耗时(分钟) | 实际耗时(分钟) |
| 计划 | 10h | 15h |
| .估计这个任务需要时间 | 10h | 15h |
| 开发 | 9h | 13h |
| .需求分析(包括学习新技术) | 5 | 20 |
| .生成设计文档 | 15 | 30 |
| .设计复审 | 10 | 15 |
| .代码规范 | 10 | 10 |
| .具体设计 | 7h | 10 |
| .具体编码 | 10 | 10h |
| .代码复审 | 30 | 15 |
| .测试 | 40 | 80 |
| 报告 | 1h | 2h |
| .测试报告 | 25 | 1.5h |
| .计算工作量 | 15 | 10 |
| .事后总结并提出改进计划 | 20 | 20 |
| 合计 | 10h | 15h |
2.解题思路
我刚看到题目的时候,感觉很简单(确实很简单除了需求不清楚以外没有太难的地方),我就按照文档写,我就先写了Parameter这个类(同时调试),
然后我就看是写Parameter这个类,一边写一边调试就ok,然后我又把ui加上也就是View这个类。其中就是在从控制台到ui对接的时候出现了一点问题(需求不 明),就是这样很快的就完成了。(没有找资料)
3.实现过程
我使用的是java,总体上来说在编写代码的过程中没有遇到障碍,就按照需求文档无脑实现就ok。
说一下自己的代码:
先说一下代码的总体结构:
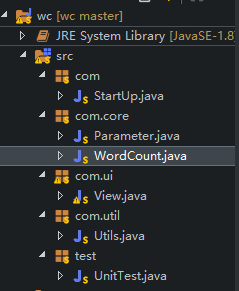
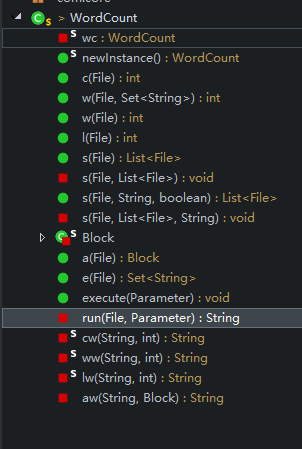
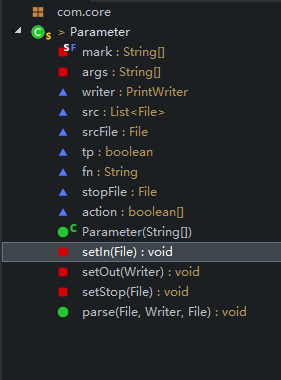
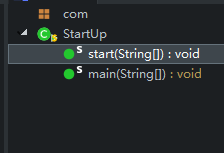
类:
StartUp.java:程序的启动类,没什么其他功能
main调用StartUp
Parameter.java:解析参数类
setIn:设置输入流
setOut:设置输出流
setStop:设置停用词文件
parse:调用上面的三个方法,实现解析参数
WordCount.java:实现具体的功能
方法的名字和参数的名字一样。例如:c:就是字符记数
其中的execute方法最终调用已经解析过Parameter对象
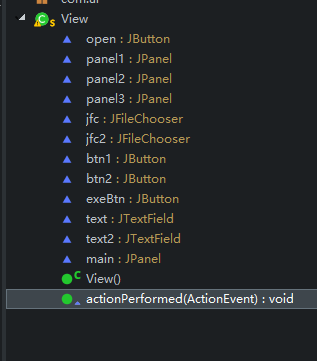
View.java:没什么用就是提供一个界面罢了
actionPerformed:事件处理
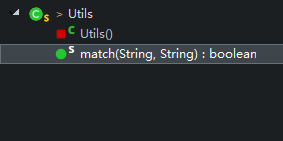
Utils.java:提供工具方法(后面会看到我在里面用到了一个动态规划算法来解决通配符的匹配问题)
match:通配符的匹配
关键方法:
com.core.Parameter.parse();
4.代码说明
先介绍一下具体功能的实现(也就是Parameter.java)
参数“-c”:很简单,就是将指定文件读出来然后一行一行的读计数就ok,贴一下自己的代码
1 public int c(File f) { 2 if (!f.exists()) 3 return -1; 4 BufferedReader reader = null; 5 int res = 0; 6 try { 7 reader = new BufferedReader(new FileReader(f)); 8 String s = null; 9 while ((s = reader.readLine()) != null) { 10 res += s.length(); 11 } 12 } catch (FileNotFoundException e2) { 13 e2.printStackTrace(); 14 } catch (IOException e1) { 15 e1.printStackTrace(); 16 } finally { 17 try { 18 reader.close(); 19 } catch (IOException e1) { 20 // TODO Auto-generated catch block 21 e1.printStackTrace(); 22 } 23 } 24 return res; 25 }
参数“-w”,单词记数也很easy,就是最开始的时候需求说的不是很清楚(空格和“,”是分隔符号,回车换行是不是分隔符号没有说,自己很纠结)实现原理和字符计数差不多,就是在每一行读出来之后是有那个split方法将字符串 切割,然后遍历这个数组,结合到后面的停用词表,可以在遍历的时候进行判断,代码:
1 public int l(File f) { 2 if (!f.exists()) 3 return -1; 4 BufferedReader reader = null; 5 int res = 0; 6 try { 7 reader = new BufferedReader(new FileReader(f)); 8 while (reader.readLine() != null) { 9 ++res; 10 } 11 } catch (FileNotFoundException e) { 12 e.printStackTrace(); 13 } catch (IOException e) { 14 e.printStackTrace(); 15 } finally { 16 try { 17 reader.close(); 18 } catch (IOException e) { 19 // TODO Auto-generated catch block 20 e.printStackTrace(); 21 } 22 } 23 return res; 24 }
参数“-l”这个就跟简单了,不多说上代码:
public int l(File f) { if (!f.exists()) return -1; BufferedReader reader = null; int res = 0; try { reader = new BufferedReader(new FileReader(f)); while (reader.readLine() != null) { ++res; } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { reader.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } return res; }
参数“-o”:就是将输出流对象改变一下。
参数“-s”:递归查找目录下的所有文件,也比较简单是一个最基本的递归,上代码
1 private void s(File dir, List<File> list, String pattern) { 2 if (dir == null) 3 return; 4 5 if (dir.isFile()) { 6 if (Utils.match(pattern, dir.getName())) 7 ; 8 { 9 list.add(dir); 10 } 11 return; 12 } 13 for (File temp : dir.listFiles()) { 14 if (temp.isFile() && Utils.match(pattern, temp.getName())) { 15 list.add(temp); 16 } else if (temp.isDirectory()) { 17 s(temp, list, pattern); 18 } 19 } 20 }
参数“-a”:不多说上代码
1 private static class Block { 2 int codeLine; 3 int emptyLine; 4 int noteLine; 5 6 public Block(int codeLine, int emptyLine, int noteLine) { 7 this.codeLine = codeLine; 8 this.emptyLine = emptyLine; 9 this.noteLine = noteLine; 10 } 11 } 12 13 public Block a(File f) { 14 int codeLine = 0, emptyLine = 0, noteLine = 0; 15 BufferedReader reader = null; 16 try { 17 reader = new BufferedReader(new FileReader(f)); 18 String s = null; 19 while ((s = reader.readLine()) != null) { 20 s = s.trim(); 21 if (s.length() == 0) { 22 ++emptyLine; 23 } else { 24 if (s.startsWith("//")) { 25 ++noteLine; 26 } else { 27 ++codeLine; 28 } 29 } 30 } 31 } catch (FileNotFoundException e) { 32 e.printStackTrace(); 33 } catch (IOException e) { 34 e.printStackTrace(); 35 } finally { 36 try { 37 reader.close(); 38 } catch (IOException e) { 39 e.printStackTrace(); 40 } 41 } 42 43 return new Block(codeLine, emptyLine, noteLine); 44 }
参数“-e”:思路也很简单,就是先把停用词表中的每一个词保存到HashSet中然后遍历的时候判断一下,代码如下:
1 public Set<String> e(File f) { 2 Set<String> set = new HashSet<String>(); 3 BufferedReader reader = null; 4 if (!f.exists()) 5 return set; 6 try { 7 reader = new BufferedReader(new FileReader(f)); 8 9 String s = null; 10 while ((s = reader.readLine()) != null) { 11 set.add(s); 12 } 13 } catch (FileNotFoundException e1) { 14 // TODO Auto-generated catch block 15 e1.printStackTrace(); 16 } catch (IOException e1) { 17 // TODO Auto-generated catch block 18 e1.printStackTrace(); 19 } finally { 20 try { 21 reader.close(); 22 } catch (IOException e1) { 23 // TODO Auto-generated catch block 24 e1.printStackTrace(); 25 } 26 } 27 return set; 28 }
参数“-x”:就是解析参数的时候发现了“-x”启动UI界面。
参数解析的具体实现:
我的思路是这样的从main函数中有一个String数组类型的args参数就是我们敲的命令行,使用一个action数组,通过查找args是否存在已有的“-c”,“-w”等然后设置action相应位表示拥有具体参数。当然也可以查找“-o” 然后它 之后就是输出文件,“-e”他之后就是停用词文件,命令行必须保证先输入文件在其他文件参数之前。ok上代码:
1 private static final String[] mark = 2 new String[] "-c", "-w", "-l", "-o", "-a", "-s", "-e", "-x" };
1 boolean[] action = new boolean[mark.length];
1 public void parse(File in, Writer out, File stopFile) { 2 Arrays.fill(action, false); 3 List<String> list = Arrays.asList(args); 4 5 setIn(in); 6 setOut(out); 7 setStop(stopFile); 8 9 if (list.contains(mark[5])) { 10 if (!tp) { 11 File t=srcFile.getAbsoluteFile().getParentFile(); 12 src = WordCount.newInstance().s(t, srcFile.getName(), true); 13 } else { 14 src = WordCount.newInstance().s(new File("./").getAbsoluteFile(), fn, true); 15 } 16 17 } else { 18 if (!tp) { 19 src.add(srcFile); 20 } else { 21 src = WordCount.newInstance().s(new File("./").getAbsoluteFile(), fn, false); 22 } 23 } 24 25 Set<String> st = new HashSet<String>(); 26 st.addAll(Arrays.asList(args)); 27 28 for (int i = 0; i < mark.length; ++i) { 29 if (st.contains(mark[i])) { 30 action[i] = true; 31 } 32 } 33 }
通过解析参数准备环境(例如输入输出文件,停用词文件等)然后最后转到WordCount.java去实现
1 public void execute(Parameter p) { 2 StringBuilder res = new StringBuilder(); 3 for (File f : p.src) { 4 res.append(run(f, p)); 5 } 6 p.writer.write(res.toString()); 7 p.writer.flush(); 8 } 9 10 private String run(File f, Parameter p) { 11 StringBuilder sb = new StringBuilder(); 12 if (p.action[0]) { 13 sb.append(cw(f.getName(), c(f))); 14 } 15 16 if (p.action[1]) { 17 if(!p.action[6]) { 18 sb.append(ww(f.getName(), w(f))); 19 }else { 20 sb.append(ww(f.getName(), w(f,e(p.stopFile)))); 21 } 22 } 23 24 if (p.action[2]) { 25 sb.append(lw(f.getName(), l(f))); 26 } 27 28 if (p.action[4]) { 29 sb.append(aw(f.getName(), a(f))); 30 } 31 return sb.toString(); 32 }
在贴一下UI界面的代码吧(界面布局的代码省略了):
1 public void actionPerformed(ActionEvent e) { 2 if (e.getSource().equals(btn1)) { 3 jfc.setFileSelectionMode(0); 4 int state = jfc.showOpenDialog(null); 5 if (state == 1) { 6 return; 7 } else { 8 File f = jfc.getSelectedFile(); 9 text.setText(f.getAbsolutePath()); 10 } 11 } else if (e.getSource().equals(btn2)) { 12 jfc2.setFileSelectionMode(0); 13 int state = jfc2.showOpenDialog(null); 14 if (state == 1) { 15 return; 16 } else { 17 File f = jfc2.getSelectedFile(); 18 text2.setText(f.getAbsolutePath()); 19 } 20 } else if (e.getSource().equals(exeBtn)) { 21 String fp = text.getText(); 22 String st = text2.getText(); 23 File in = new File(fp); 24 BufferedWriter writer; 25 try { 26 writer = new BufferedWriter(new FileWriter(st)); 27 String cmd = "wc.exe -c -l - w -a"; 28 Parameter p = new Parameter(cmd.split(" ")); 29 p.parse(in, writer, null); 30 WordCount.newInstance().execute(p); 31 } catch (IOException e1) { 32 // TODO Auto-generated catch block 33 e1.printStackTrace(); 34 }finally { 35 System.exit(0); 36 } 37 } 38 }
最后最后说一下Utils中的一个算法
问题:一个字符串S包含“*”(其中“*”表示匹配0个或者多个字符)另一个字符串 T不包含“*”,判断他们是否匹配。
例如:
S="abc*a",T=“abcccca” 匹配
S=“abc*a” T=“acbccca” 不匹配
具体算法使用动态规划dp[i][j]表示S的前i个字符与T的前j个字符是否匹配,关键是状态转移方程是
dp[i][j]=dp[i-1][j-1]&&S[i-1]==T[j-1] (S[i-1]!='*')
dp[i][j]=dp[i][j-1]||dp[i-1][j] (S[i-1]=='*')
1 public static boolean match(String p,String t) { 2 int len1=p.length(); 3 int len2=t.length(); 4 boolean[][]dp=new boolean[len1+1][len2+1]; 5 dp[0][0]=true; 6 7 for(int i=1;i<=len1;++i) { 8 char pc=p.charAt(i-1); 9 dp[i][0]=dp[i-1][0]&&pc=='*'; 10 for(int j=1;j<=len2;++j) { 11 char tc=t.charAt(j-1); 12 if(pc=='*') { 13 dp[i][j]=dp[i-1][j]||dp[i][j-1]; 14 }else { 15 dp[i][j]=dp[i-1][j-1]&&pc==tc; 16 } 17 } 18 } 19 return dp[len1][len2]; 20 }
5.测试设计过程
进行单元测试示例代码如下(可以直接看注释)
高风险的地方:通配符匹配算法,字符、行数、单词计数
1 package test; 2 3 import java.io.File; 4 5 import com.StartUp; 6 import com.core.WordCount; 7 8 public class UnitTest { 9 10 // WordCount.c(); 11 public static void testC() { 12 System.out.println(WordCount.newInstance() 13 .c(new File("1.txt")));//文件存在 14 } 15 public static void testC2() {//文件不存在 16 System.out.println(WordCount. 17 newInstance().c(new File("131.txt"))); 18 } 19 public static void testC3() {//文件为null 20 System.out.println(WordCount. 21 newInstance().c(null)); 22 } 23 24 25 //WordCount.w()测试 26 public static void testW1() {//没有停用词表 27 System.out.println(WordCount. 28 newInstance().w(new File("1.txt"),null)); 29 } 30 31 public static void testW2() {//文件不存在 32 System.out.println(WordCount. 33 newInstance().w(new File("2112.txt"),null)); 34 } 35 36 public static void testW3() { 37 System.out.println(WordCount.//文件为空 38 newInstance().w(null,null)); 39 } 40 41 42 //WordCount.l()测试 43 public static void testl1() { 44 System.out.println(WordCount.//ok 45 newInstance().l(new File("1.txt"))); 46 } 47 48 public static void testl2() { 49 System.out.println(WordCount.//文件不存在 50 newInstance().l(new File("1dfdas.txt"))); 51 } 52 53 public static void testl3() { 54 System.out.println(WordCount.//文件不存在 55 newInstance().l(null)); 56 } 57 58 //WordCount.a()测试 59 60 public static void testa1() { 61 System.out.println(WordCount.//ok 62 newInstance().a(new File("1.txt"))); 63 } 64 65 public static void testa2() { 66 System.out.println(WordCount.//文件不存在 67 newInstance().a(new File("1dfdas.txt"))); 68 } 69 70 public static void testa3() { 71 System.out.println(WordCount.//文件为null 72 newInstance().a(null)); 73 } 74 public static void main(String[] args) { 75 testC(); 76 testC2(); 77 testC3(); 78 testW1(); 79 testW2(); 80 testW3(); 81 testl1(); 82 testl2(); 83 testl3(); 84 testa1(); 85 testa2(); 86 testa3(); 87 } 88 }
6.测试脚本
1 package test; 2 3 public class TestScript { 4 5 static String f = "D:\project\homework\wc\wc\wcProject\BIN\wc.exe";//可执行文件的位置 6 7 public static void test(String cmd) { 8 Runtime rt = Runtime.getRuntime(); 9 try { 10 rt.exec(f + " " + cmd); 11 } catch (IOException e) { 12 // TODO Auto-generated catch block 13 e.printStackTrace(); 14 } 15 } 16 17 public static void testC() {//测试字符的数目 18 String cmd = "wc.exe -c 1.txt"; 19 test(cmd); 20 } 21 22 public static void testL() {//测试字符的数目、行数 23 String cmd = "wc.exe -c -l 1.txt"; 24 test(cmd); 25 } 26 27 public static void testW() {//测试字符的数目、行数、单词数 28 String cmd = "wc.exe -c -l -w 1.txt"; 29 test(cmd); 30 } 31 32 public static void testO() {//测试字符的数目、行数、单词数、输出文件 33 String cmd = "wc.exe -c -l -w 1.txt -o 2.txt"; 34 test(cmd); 35 } 36 37 public static void testS() {//测试字符的数目、行数、单词数、输出文件、递归目录 38 String cmd = "wc.exe -c -l -w -s *.txt -o 2.txt"; 39 test(cmd); 40 } 41 42 public static void testA() {//测试字符的数目、行数、单词数、输出文件、递归目录、特殊结构 43 String cmd = "wc.exe -c -l -w -a -s *.txt -o 2.txt"; 44 test(cmd); 45 } 46 47 public static void testE() {//测试字符的数目、行数、单词数、输出文件、递归目录、特殊结构、停用词表 48 String cmd = "wc.exe -c -l -w -a -s *.txt -e stop.txt -o 2.txt"; 49 test(cmd); 50 } 51 52 public static void testX() {//测试字符的数目、行数、单词数、输出文件、递归目录、特殊结构、停用词表、图形界面 53 String cmd = "wc.exe -x"; 54 test(cmd); 55 } 56 57 public static void main(String[] args) { 58 // testC(); 59 // testL(); 60 // testW(); 61 // testO(); 62 // testS(); 63 // testA(); 64 // testE(); 65 testX(); 66 } 67 68 }
7.引用链接(没有引用别人的代码)
3.总结报告:
感觉自己好菜呀,需要努力!