ThreadPool,DummyPool 线程池
ProcessPool 进程池
threading 线程
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
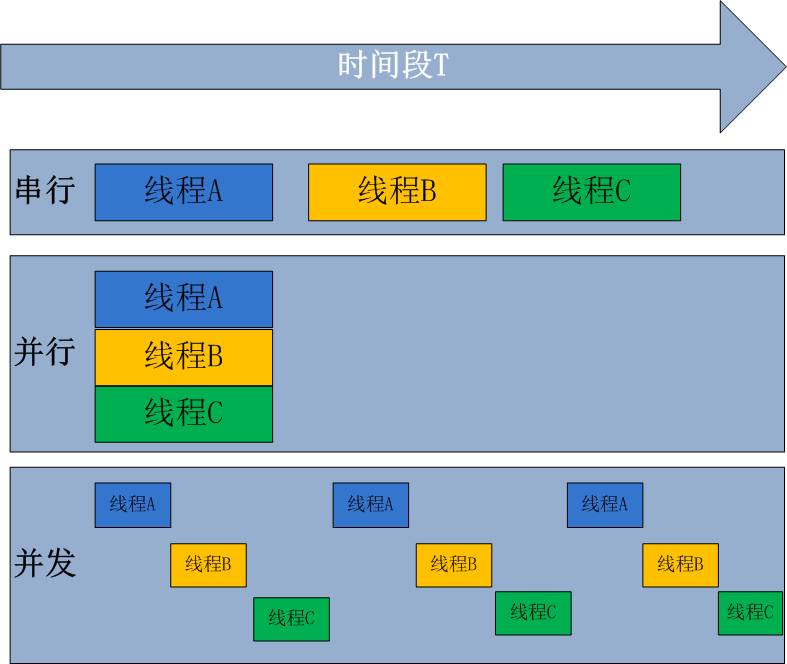
并行处理(Parallel Processing)是计算机系统中能同时执行两个或更多个处理的一种计算方法
并发处理(concurrency Processing):指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机(CPU)上运行,但任一个时刻点上只有一个程序在处理机(CPU)上运行
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以说,并行是并发的子集
from multiprocessing.pool import ThreadPool
from multiprocessing.dummy import Pool as DummyPool
from multiprocessing import Pool as ProcessPool
使用:
def run(i):
i = i * i
# return i # return和不return对进程池运行速度会有比较大影响,不return效率更高
def thread_pool(num):
p = ThreadPool(num)
start_time = time.time()
ret = p.map(run, range(max_range))
p.close()
p.join()
print("thread_pool %d, costTime: %fs ret.size: %d" % (num, (time.time() - start_time), len(ret)))
def dummy_pool(num):
p = DummyPool(num)
start_time = time.time()
ret = p.map(run, range(max_range))
p.close()
p.join()
print("dummy_pool %d, costTime: %fs ret.size: %d" % (num, (time.time() - start_time), len(ret)))
def process_pool(num):
p = ProcessPool(num)
start_time = time.time()
ret = p.map(run, range(max_range))
p.close()
p.join()
print("process_pool %d, costTime: %fs ret.size: %d" % (num, (time.time() - start_time), len(ret)))
if __name__ == "__main__":
for i in range(1, 9):
thread_pool(i)
dummy_pool(i)
process_pool(i)
print("=====")
threadpool 线程池
pip install threadpool
pool = ThreadPool(poolsize)
requests = makeRequests(some_callable, list_of_args, callback)
[pool.putRequest(req) for req in requests]
pool.wait() 第一行定义了一个线程池,表示最多可以创建poolsize这么多线程;
第二行是调用makeRequests创建了要开启多线程的函数,以及函数相关参数和回调函数,其中回调函数可以不写,default是无,也就是说makeRequests只需要2个参数就可以运行;
第三行用法比较奇怪,是将所有要运行多线程的请求扔进线程池,[pool.putRequest(req) for req in requests]等同于
for req in requests:
pool.putRequest(req)
第四行是等待所有的线程完成工作后退出。
多参数:
import threadpool
def hello(m, n, o):
print("m = %s, n = %s, o = %s" % (m, n, o))
if __name__ == '__main__':
# 方法1
lst_vars_1 = ['1', '2', '3']
lst_vars_2 = ['4', '5', '6']
func_var = [(lst_vars_1, None), (lst_vars_2, None)]
# 方法2
dict_vars_1 = {'m': '1', 'n': '2', 'o': '3'}
dict_vars_2 = {'m': '4', 'n': '5', 'o': '6'}
func_var = [(None, dict_vars_1), (None, dict_vars_2)]
pool = threadpool.ThreadPool(3)
# 参数必须是包含2个元素的元组,第一个解析list,第二个解析dict
# (*request.args, **request.kwds)
requests = threadpool.makeRequests(hello, func_var)
[pool.putRequest(req) for req in requests]
pool.wait()
#output
m = 1, n = 2, o = 3
m = 4, n = 5, o = 6threading
import threading
import time
def countNum(n): # 定义某个线程要运行的函数
print("running on number:%s" %n)
time.sleep(3)
if __name__ == '__main__':
t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例
t2 = threading.Thread(target=countNum,args=(34,))
t1.start() #启动线程
t2.start()
print("ending!")继承形式:
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num=num
def run(self):
print("running on number:%s" %self.num)
time.sleep(3)
t1=MyThread(56)
t2=MyThread(78)
t1.start()
t2.start()
t1.join() # 在子线程t1完成运行之前,这个子线程的父线程将一直被阻塞。
t2.join() # 在子线程t2完成运行之前,这个子线程的父线程将一直被阻塞。
#join([time]) 可选超时时间
print("ending")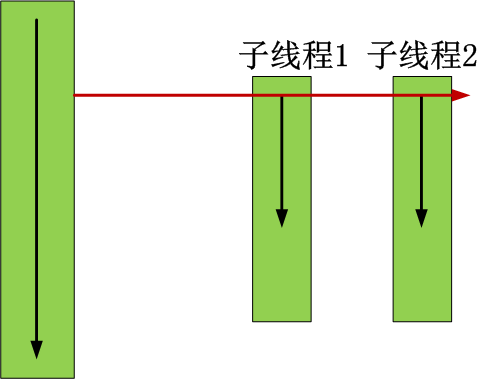
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
同步
Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间.
import threading
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
threadLock = threading.Lock()
threads = []
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.start()
t.join()
print ("退出主线程")