加入开源中国也有超过三年的时间了,觉得开源中国已经越办越好了,突然很想知道它究竟有多好,我是不是开源中国最老的用户,我有176个开源中国的积分能够排名第几,带着这些问题,我抓取了部分开源中国的用户信息,做了一个简单的分析。
数据获取
要获得用户数据,可以通过开源中国的网页来进行。这个是我的主页面

这个页面包含了用户的基本信息,包括用户名,积分,粉丝,关注等等。
点击粉丝链接可以获得所有的粉丝的情况

然后我们就可以通过这些链接,迭代的找到所有相关连的数据了。
工具选取
requests是一个非常好用的python的http/rest的客户端,比之python自带的urllib要好用很多,推荐使用。
pyquery是用来解析和操纵html和DOM文档,提供类似jquery的语法,比诸如beatifulSoap要好用不少,尤其如果你是一个前段开发者,熟悉jquery,那就更方便了。大家可以参考我的另一篇博客了解更多的背景信息。
爬取网页数据
为了抓取网页的内容,我们可用chrome自带的工具来查看网页的DOM结构:

核心的代码如下:
def get_user_info(url):
try:
r = requests.get(url + "/fans", headers=headers)
doc = pq(r.text)
user_info = dict()
# get user information
user_info["url"] = url
user_info["nickname"] = doc.find(".user-info .nickname").text()
user_info["post"] = doc.find(".user-info .post").text()
user_info["address"] = doc.find(".user-info .address").text()
user_info["score"] = doc.find(".integral .score-num").text()
user_info["fans_number"] = doc.find(".fans .score-num").text()
user_info["follow_number"] = doc.find(".follow .score-num").text()
join_time = doc.find(".join-time").text()
user_info["join_time"] = join_time[
4:15].encode("ascii", "ignore").strip()
# get fans
user_info["fans"] = get_relations(doc)
# get follows, fellow is a wrong spelling
rf = requests.get(url + "/fellow", headers=headers)
user_info["follow"] = get_relations(pq(rf.text))
return user_info
except Exception as e:
return Noneget_user_info() 方法通过给定的用户url来获取用户信息,首先利用requests的get方法得到用户网页,然后用pyquery抽取出昵称nickname,职位post,地址address,积分score,粉丝数fans_number,关注数follow_number。并得到所有的关注和粉丝的url。这里有一件事比较尴尬,关注的url模式中,关注的英文单词拼错了,应该是follow,而实际上使用的却是fellow,前端程序员也要学好英语呀!
def get_relations(basedoc):
result = list()
try:
doc = basedoc
fans = doc.find(".fans-item")
flist = [fans.eq(i) for i in range(len(fans))]
while True:
for fan in flist:
username = fan.find(".username").text()
url = fan.find(".username a").attr("href")
result.append({"name": username, "link": url})
pages = doc.find("#friend-page-pjax a")
if len(pages) == 0:
break
last_link = pages.eq(len(pages) - 1).attr("href")
last_number = pages.eq(len(pages) - 1).text()
if last_number.encode("utf-8").isdigit():
break
r = requests.get(BASE_URL + "/" + last_link, headers=headers)
doc = pq(r.text)
fans = doc.find(".fans-item")
flist = [fans.eq(i) for i in range(len(fans))]
return result
except Exception as e:
return resultget_relations()方法通过循环的方式找到所有的关注或粉丝的url链接。
最后实现一个抓数据的类Scraper:
class Scarper(threading.Thread):
def __init__(self, threadName, queue):
super(Scarper, self).__init__(name=threadName)
self._stop = False
self._base_url = BASE_URL
self._base_user = "masokol"
self._check_point = dict()
self._task_queue = queue
def _pull(self, url):
user = get_user_info(url)
if user is None:
return
self._write(user)
for u in user["fans"]:
logger.debug("check a fan {}".format(json.dumps(u)))
if not self._check_point.has_key(u["link"]):
logger.debug("put one task {}".format(u["link"]))
self._task_queue.put(u)
for u in user["follow"]:
logger.debug("check a follow {}".format(json.dumps(u)))
if not self._check_point.has_key(u["link"]):
logger.debug("put one task {}".format(u["link"]))
self._task_queue.put(u)
def _write(self, user):
if self._check_point.has_key(user["url"]):
return
logger.debug(json.dumps(user))
# TODO support unicode logging here
logger.info("name={}, join={}, post={}, address={}, score={}, fans_number={}, follow_number={}".format(
user["nickname"].encode("utf8"),
user["join_time"],
user["post"].encode("utf8"),
user["address"].encode("utf8"),
user["score"].encode("utf8"),
user["fans_number"].encode("utf8"),
user["follow_number"].encode("utf8")))
self._check_point[user["url"]] = True
def init(self):
url = self._base_url + "/" + self._base_user
r = requests.get(url, headers=headers)
self._pull(url)
def run(self):
global IS_TERM
logger.debug("start working")
try:
while True:
logger.debug("pull one task ...")
item = self._task_queue.get(False)
logger.debug("get one task {} ".format(json.dumps(item)))
self._pull(item["link"])
time.sleep(0.1)
if IS_TERM:
break
except KeyboardInterrupt:
sys.exit()
except Exception as e:
print e这里面有几个点要注意下:
- 起始用户我选用了“masokol”,理论上选哪个用户作为起始用户关系不大,假定所有的用户都是关联的,当然这个假定不一定成立。也许存在一个孤岛,孤岛里的用户和其它用户都不关联。如果起始用户在这个孤岛里,那么就只能抓取顾岛内的用户。
- 利用队列构造生产者消费者模型,这样做的好处是可以利用多线程来提高抓取效率,但是实际操作中,我并没有开多线程,因为不希望给oschina带来太多的网络负载。大家如果要运行我的程序也请注意,友好使用,不要编程ddos攻击。另外利用queue可以把递归调用变为循环,避免stack overflow
- checkpoint用来记录抓取的历史,避免重复抓数据。这里是用url作为key的一个数据字典dict来做checkpoint
完整的代码请参考 https://github.com/gangtao/oschina_user_analysis
这里是一个数据抓取程序的最简单实现,若要做到真正好用,有以下几点需要考虑:
- 持久化任务队列
在该实现中,任务队列在内存中,这样就很难做分布式的扩展,也没办法做到错误恢复,如果程序或数据抓取的节点出问题,则抓取中断。可以考虑使用Kafka,RabbitMQ,SQS,Kenisis来实现这个任务队列 - 持久化checkpoint
同样的内存内的checkpoint虽然效率高可是无法从错误中恢复,而且如果数据量大,还存在内存不够用的情况 - 提高并发
在本实现中,并没有利用并发来提高数据吞吐,主要是不想给oschina带来高的负载。通过配置多线程/多进程等手段,可以有效的提高数据抓取的吞吐量。 - 优化异常处理
在该实现中,大部分错误都没有处理,直接返回。 - 利用云和无服务
利用云或者无服务(serverless,例如AWS Lamba)技术可以把数据采集服务化,并且可以做到高效的扩展。
数据分析
利用Splunk可以高效的分析日志文件,我在我的Splunk中创建了一个文件的Monitor,这样就可以一边抓取数据,一边分析啦。
这里关键的设置是sourcetype=oschina_user
好了上分析结果:

以上几个指标是已分析的用户数,平均积分,平均粉丝数和平均关注数。我的176分和105个粉丝都刚好超过平均值一点点呀。
下面是对应的SPL(Splunk Processing Language),因为日志输出是使用的key=value格式,不需要额外抽取,直接可以用SPL来分析。
sourcetype=oschina_user | stats count
sourcetype=oschina_user | stats avg(score)
sourcetype=oschina_user | stats avg(fans_number)
sourcetype=oschina_user | stats avg(follow_number)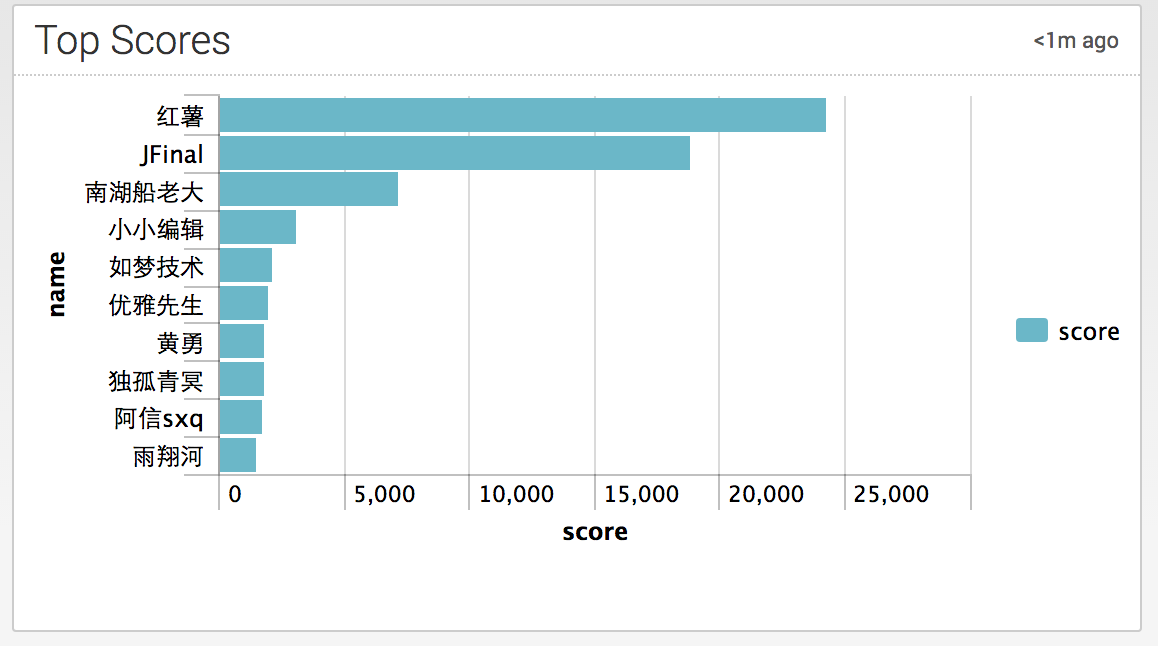
sourcetype=oschina_user | table name, score | sort -score | head 10这张表是最高积分榜,红薯两万多分是自己改得数据库吧,太不像话了。另外几位大神,jfinal是量子通信的技术副总裁;南湖船老大失业中,大概不想透漏工作信息吧,小小编辑就不说了,如梦技术是皕杰 - 后端工程师。

sourcetype=oschina_user | stats count by addr0 | sort -count | head 5(注意:这里的addr0字段需要额外的从地址字段中抽取出来,因为原字段包含省份/地区两级信息)
用户来自哪里,北广上占据前三不意外,上海排第三要加油呦。

sourcetype=oschina_user | table name, fans_number |sort - fans_number | head 5
sourcetype=oschina_user | stats count by post | sort -count | head 5
sourcetype=oschina_user | table name, follow_number | sort -follow_number | head 5
拥有最多粉丝和关注数的的信息。Post是职业信息,都是程序员毫无新意。
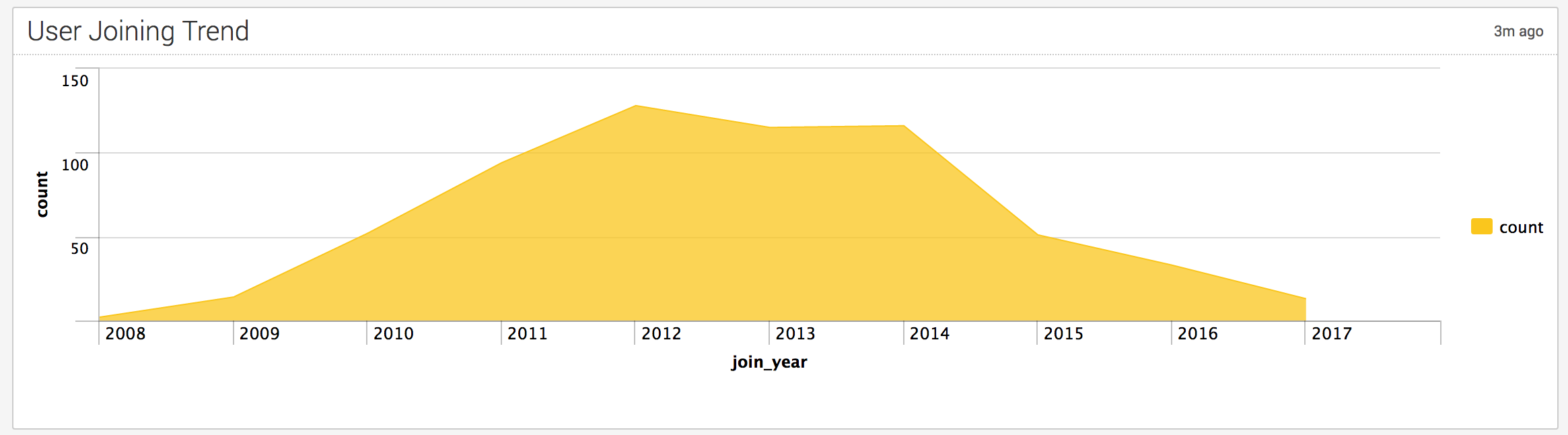
sourcetype=oschina_user | stats count by join_year | sort join_year(注意:这里的join_year字段需要额外的从join字段抽取出来。)
这个厉害了,是用户加入oschina的趋势图,2014年以后咋是下降的呢,难道是发展的不好?我是不是发现了什么?红薯要加油了呀!也许是我抓取的用户数量还太少,不能反应真实情况吧。
我的爬虫还在慢慢跑,有了最新的发现会告诉大家!
后记
最新的数据更新到4800,后面不一定会继续抓数据,大家看看就好。
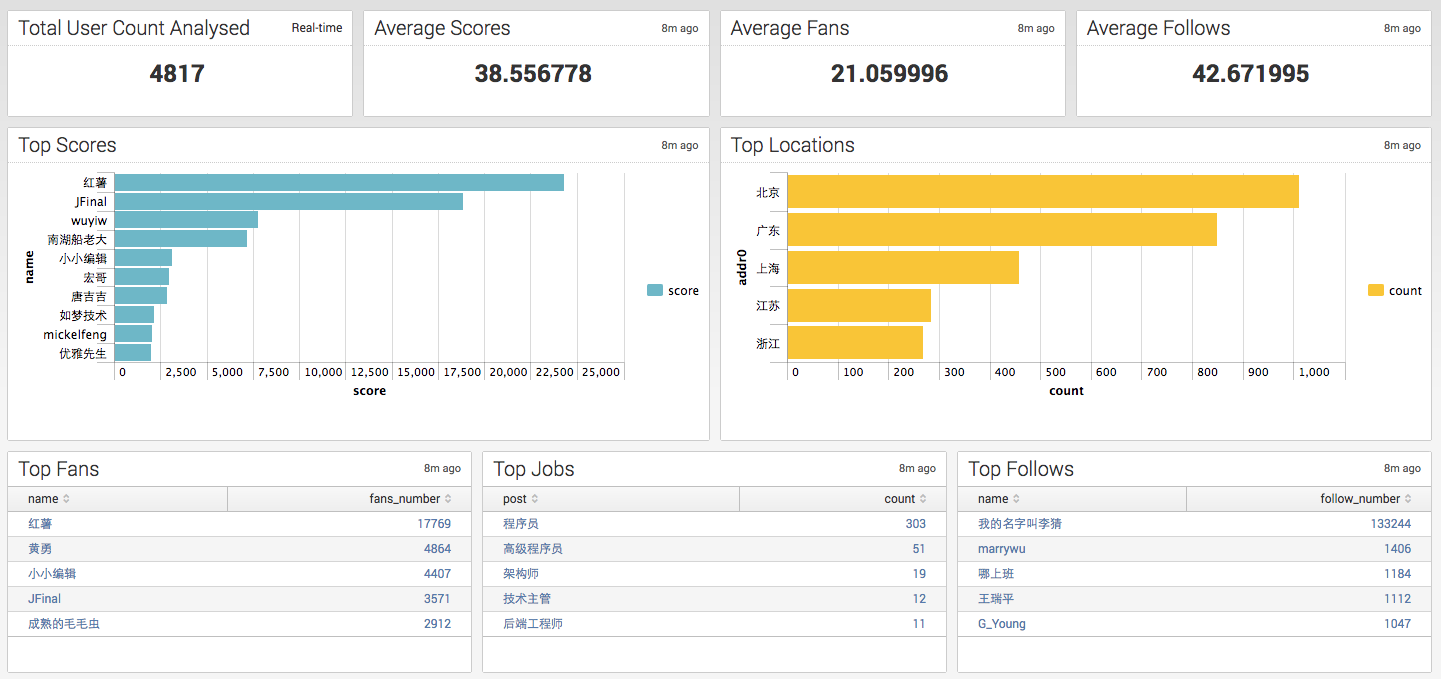
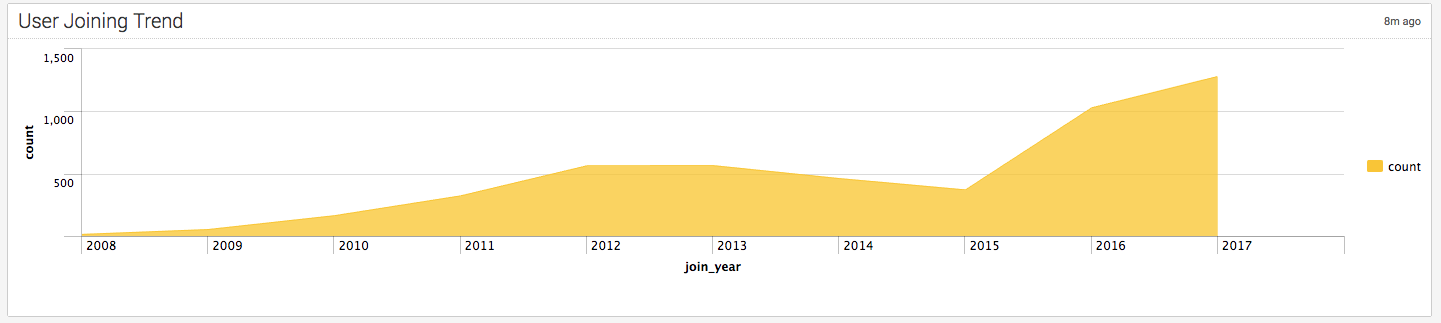
- Top Rank的排名变化不大
- 平局积分下降到38.5,平均粉丝数下降到21,看来我开始抓取的用户都是核心用户,积分高,粉丝多
- 这个“我的名字叫李猜”关注了13万用户,你想干啥?
- 最新的数据现实开源中国用户数量增长显著,17年这还不到一半,新用户的数量明显超过了2016,恭喜红薯了
- 还有很多可以抓去的信息,例如用户性别,发表的博客数量等等,留个大家去扩展吧。
- 应红薯的要求,代码也放到了码云上 http://git.oschina.net/gangtao/oschina_user_analysis
- Splunk真的是太好用了(此处应有掌声)