1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
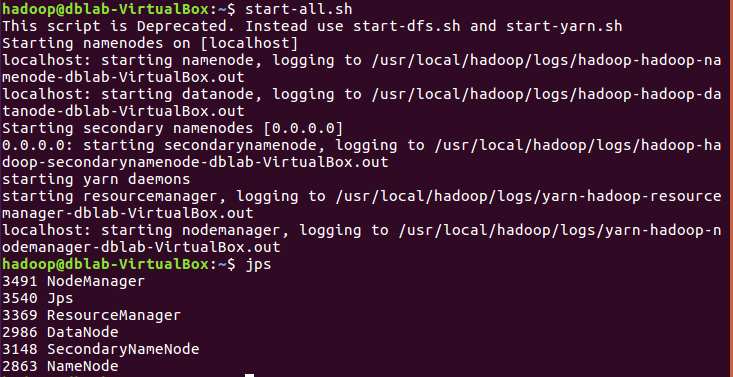
启动hadoop:
|
1
2
|
start-all.shjps |
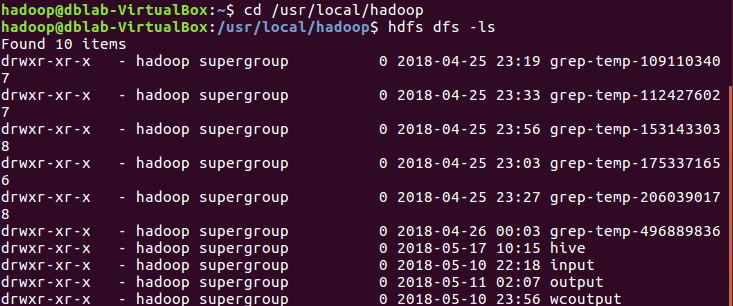
查看hdfs上的文件夹:
|
1
2
|
cd /usr/local/hadoophdfs dfs -ls |
将本地系统hadoop文件夹里的英文版故事LittlePrince.txt上传至hdfs的hive文件夹中:
|
1
|
hdfs dfs -put ~/hadoop/LittlePrince.txt hive |

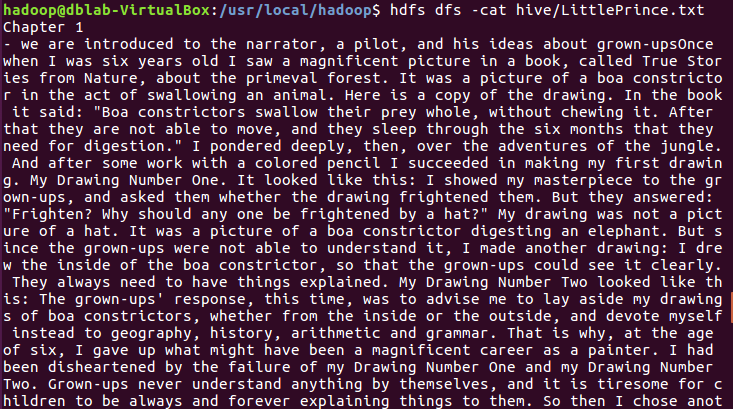
查看hdfs上的LittlePrince.txt文件内容:
|
1
|
hdfs dfs -cat hive/LittlePrince.txt |
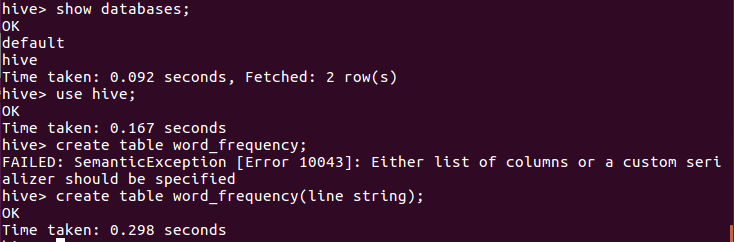
启动hive:
|
1
|
hive |

创建文档表word_frequency:
|
1
2
3
|
show databases;use hive;create table word_frequency(line string); |
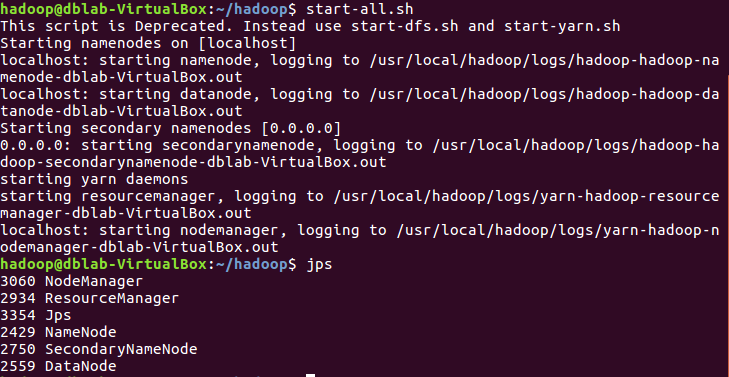
启动hadoop:
|
1
2
|
start-all.shjps |
将本地系统hadoop文件夹里的jieba.csv上传至hdfs的hive文件夹中:
|
1
2
|
cd /usr/local/hadoophdfs dfs -put ~/hadoop/jieba.csv hive |

查看hdfs上的jieba.csv文件前20条数据的内容:
|
1
|
hdfs dfs -cat hive/jieba.csv | head -20 |
启动hive:
|
1
|
hive |
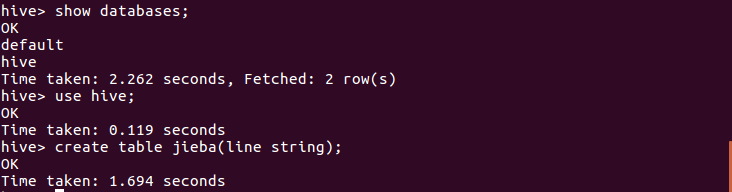
在数据库hive里创建文档表jieba:
|
1
2
3
|
show databases;use hive;create table jieba(line string); |
导入文件内容到表jieba:
|
1
|
load data inpath '/user/hadoop/hive/jieba.csv' overwrite into table jieba; |

查看表的总数据条数:
|
1
|
select count(*) from jieba; |