
ROW_NUMBER()
row_number会为查询出来的每一行记录生成一个序号,依次顺序排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
SELECT id, score, row_number() OVER (ORDER BY id DESC) AS 'row_number' FROM scores;
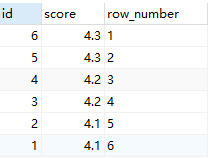
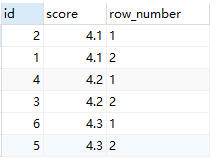
SELECT id, score, row_number() OVER (partition by score ORDER BY id DESC) AS 'row_number' FROM scores;
RANK()
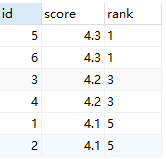
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。rank与row_number函数不同的是,rank函数考虑到over子句中排序字段值相同的情况,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
DENSE_RANK()
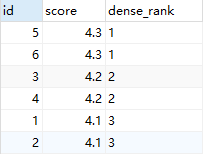
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
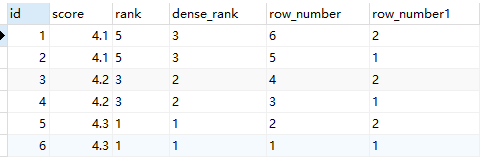
SELECT id, score , rank() OVER (ORDER BY score DESC) AS 'rank' , dense_rank() OVER (ORDER BY score DESC) AS 'dense_rank' , row_number() OVER (ORDER BY id DESC) AS 'row_number' , row_number() OVER (partition by score ORDER BY id DESC) AS 'row_number1' FROM scores order by id
关于Partition by:
Parttion by关键字是数据库分析性函数的一部分,用于给结果集进行分区。它和聚合函数Group by不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而Group by是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。
TIPS:
使用rank over()的时候,空值是最大的,如果排序字段为null, 可能造成null字段排在最前面,影响排序结果。
可以这样:rank() over(partition by student order by score desc nulls last)