对于加深网络层数带来的问题,(gradient diffuse 局部最优等)可以使用逐层预训练(pre-training)的方法来避免
Stack-Autoencoder是一种逐层贪婪(Greedy layer-wise training)的训练方法,逐层贪婪的主要思路是每次只训练网络中的一层,即首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,把已经训练好的前 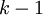 层固定,然后增加第
层固定,然后增加第  层(也就是将已经训练好的前 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
层(也就是将已经训练好的前 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差).
逐层贪婪的训练方法取得成功要归功于以下几方面:
1)数据获取:虽然获取有标签数据的代价是昂贵的,但获取大量的无标签数据是容易的。自学习方法(self-taught learning)的潜力在于它能通过使用大量的无标签数据来学习到更好的模型。该方法使用无标签数据来学习得到所有层(不包括用于预测标签的最终分类层)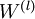 的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
2)更优的局部极值:当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上。然后我们可以从这些位置出发进一步微调权重。从经验上来说,以这些位置为起点开始梯度下降更有可能收敛到比较好的局部极值点,这是因为无标签数据已经提供了大量输入数据中包含的模式的先验信息。
stack autoencoder 就是一种逐层贪婪的训练算法。该网络由一个多层稀疏自编码网络组成,前一层自编码器的输出作为后一层自编码器的输入。对于一个N层自编码栈式神经网络,用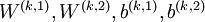 表示第 个自编码器对应的
表示第 个自编码器对应的 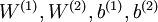 参数,该网络的编码过程如下:
参数,该网络的编码过程如下:
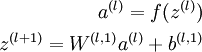
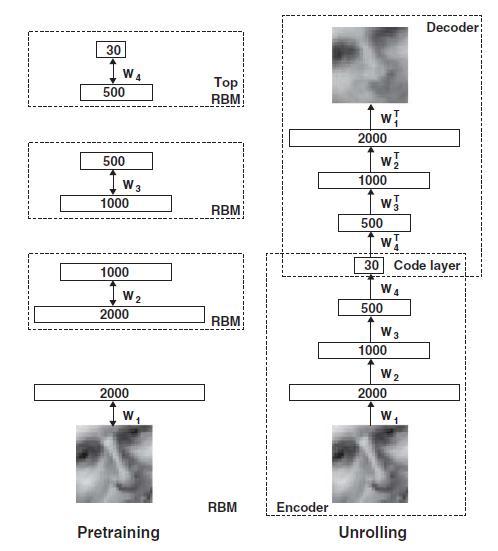
SAE每个hidden layer有两组参数,分别用来编码和解码,解码也即将多层自编码器还原为之前的结果,借鉴hinton老爷子06年 science 上的RBM的图:
SAE对应的解码步骤如下:
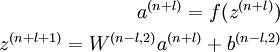
如上公式中,
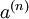 是最深层隐藏单元的激活值,其包含了我们感兴趣的信息,也是对输入数据的更高阶的表示。通过将 作为softmax分类器的输入特征,可以将栈式自编码神经网络中学到的特征用于分类问题。
是最深层隐藏单元的激活值,其包含了我们感兴趣的信息,也是对输入数据的更高阶的表示。通过将 作为softmax分类器的输入特征,可以将栈式自编码神经网络中学到的特征用于分类问题。
为了更好的获取栈式自编码神经网络参数,采用逐层贪婪训练法进行训练。先利用原始输入来训练网络的第一层,得到其参数 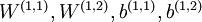 ;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数
;然后网络第一层将原始输入转化成为由隐藏单元激活值组成的向量(假设该向量为A),接着把A作为第二层的输入,继续训练得到第二层的参数 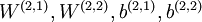 ;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练,在训练每一层参数的时候,会固定其它各层参数保持不变。为了得到更好的结果,在预训练过程完成之后,可以通过反向传播算法同时调整所有层的参数以改善结果,这个过程一般被称作“微调(fine-tuning)”。使用逐层贪婪训练方法将参数训练到快要收敛时,应该使用微调。反之,如果直接在随机化的初始权重上使用微调,那么会得到不好的结果,因为参数会收敛到局部最优。预训练会使模型参数位于参数空间之中的比较好的位置,以此来求得比较优的解。在只进行分类的情况下,惯用的做法是丢掉栈式自编码网络的“解码”层,直接把最后一个隐藏层的 作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层( W(k,1) )了。
;最后,对后面的各层同样采用的策略,即将前层的输出作为下一层输入的方式依次训练,在训练每一层参数的时候,会固定其它各层参数保持不变。为了得到更好的结果,在预训练过程完成之后,可以通过反向传播算法同时调整所有层的参数以改善结果,这个过程一般被称作“微调(fine-tuning)”。使用逐层贪婪训练方法将参数训练到快要收敛时,应该使用微调。反之,如果直接在随机化的初始权重上使用微调,那么会得到不好的结果,因为参数会收敛到局部最优。预训练会使模型参数位于参数空间之中的比较好的位置,以此来求得比较优的解。在只进行分类的情况下,惯用的做法是丢掉栈式自编码网络的“解码”层,直接把最后一个隐藏层的 作为特征输入到softmax分类器进行分类,这样,分类器(softmax)的分类错误的梯度值就可以直接反向传播给编码层( W(k,1) )了。
下面看一个四层网络的训练过程:
1)用原始数据训练第一个自编码器,会从原始输入中得到一阶特征表示h(1)(k).
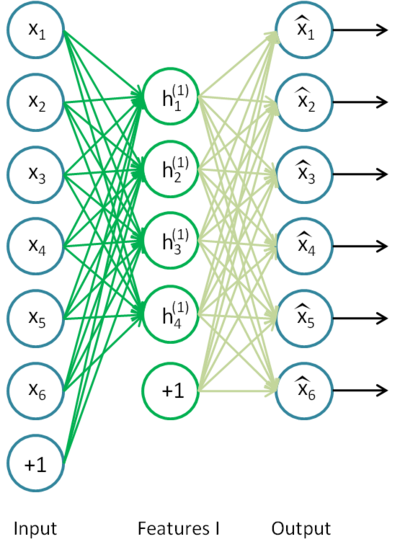
2)把h(1)(k)当做第二个隐层的输入,会从原始特征中得到二阶特征表示h(2)(k).

3)将h(1)(k).送入softmax分类器,得到分类结果。
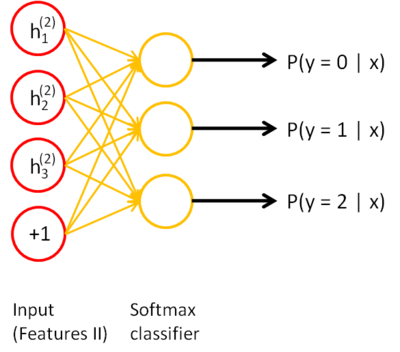
4)将上述过程联合起来,就形成了如下图所示的4层自编码网络。
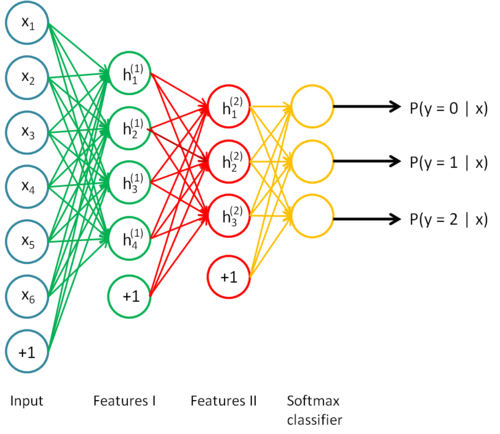
最后,用matlab构建一个4层的stack autoencoder来进行MNIST手写数据库的识别,通过“fine-tuning”,会显著提升模型的性能。
1)首先读取MNIST数据,初始化网络参数,输入层,两个隐藏层,隐层的平均激活度 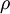 ,正则参数
,正则参数 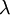 ,稀疏权重
,稀疏权重 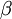 。
。
2)用L-BFGS训练第二层(即第一个hidden layer),求得W(1),然后用该参数求得第二层的输出a(2)
3)以a(2)作为输入层,第三层(即第二个hidden layer)作为隐层,来train一个sparse autoencoder, 求得W(2),然后用该参数求得softmax层的输如a(3)
3)用a(3)来训练 softmax模型,得到W(3)
5)用x(i)作为输入,y(i)作为标签,通过fun-tuning整个网络
6)用该网络进行预测,对MNIST准确率讲道理应该有98%以上
matlab代码:
%% STEP 0: 初始化参数与常量
%
% Here we define and initialise some constants which allow your code
% to be used more generally on any arbitrary input.
% We also initialise some parameters used for tuning the model.
inputSize = 28 * 28; % Size of input vector (MNIST images are 28x28)
numClasses = 10; % Number of classes (MNIST images fall into 10 classes)
lambda = 1e-4; % Weight decay parameter
%%======================================================================
%% STEP 1: Load data
%
% In this section, we load the input and output data.
% For softmax regression on MNIST pixels,
% the input data is the images, and
% the output data is the labels.
%
% Change the filenames if you've saved the files under different names
% On some platforms, the files might be saved as
% train-images.idx3-ubyte / train-labels.idx1-ubyte
images = loadMNISTImages('mnist/train-images-idx3-ubyte');
labels = loadMNISTLabels('mnist/train-labels-idx1-ubyte');
labels(labels==0) = 10; % 注意下标是1-10,所以需要 把0映射到10
inputData = images;
% For debugging purposes, you may wish to reduce the size of the input data
% in order to speed up gradient checking.
% Here, we create synthetic dataset using random data for testing
DEBUG = true; % Set DEBUG to true when debugging.
if DEBUG
inputSize = 8;
inputData = randn(8, 100);%randn产生每个元素均为标准正态分布的8*100的矩阵
labels = randi(10, 100, 1);%产生1-10的随机数,产生100行,即100个标签
end
% Randomly initialise theta
theta = 0.005 * randn(numClasses * inputSize, 1);
%%======================================================================
%% STEP 2: Implement softmaxCost
%
% Implement softmaxCost in softmaxCost.m.
[cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, inputData, labels);
%%======================================================================
%% STEP 3: Gradient checking
%
% As with any learning algorithm, you should always check that your
% gradients are correct before learning the parameters.
%
% h = @(x) scale * kernel(scale * x);
% 构建一个自变量为x,因变量为h,表达式为scale * kernel(scale * x)的函数。即
% h=scale* kernel(scale * x),自变量为x
if DEBUG
numGrad = computeNumericalGradient( @(x) softmaxCost(x, numClasses, ...
inputSize, lambda, inputData, labels), theta);
% Use this to visually compare the gradients side by side
disp([numGrad grad]);
% Compare numerically computed gradients with those computed analytically
diff = norm(numGrad-grad)/norm(numGrad+grad);
disp(diff);
% The difference should be small.
% In our implementation, these values are usually less than 1e-7.
% When your gradients are correct, congratulations!
end
%%======================================================================
%% STEP 4: Learning parameters
%
% Once you have verified that your gradients are correct,
% you can start training your softmax regression code using softmaxTrain
% (which uses minFunc).
options.maxIter = 100;
softmaxModel = softmaxTrain(inputSize, numClasses, lambda, ...
inputData, labels, options);
% Although we only use 100 iterations here to train a classifier for the
% MNIST data set, in practice, training for more iterations is usually
% beneficial.
%%======================================================================
%% STEP 5: Testing
%
% You should now test your model against the test images.
% To do this, you will first need to write softmaxPredict
% (in softmaxPredict.m), which should return predictions
% given a softmax model and the input data.
images = loadMNISTImages('mnist/t10k-images-idx3-ubyte');
labels = loadMNISTLabels('mnist/t10k-labels-idx1-ubyte');
labels(labels==0) = 10; % Remap 0 to 10
inputData = images;
% You will have to implement softmaxPredict in softmaxPredict.m
[pred] = softmaxPredict(softmaxModel, inputData);
acc = mean(labels(:) == pred(:));
fprintf('Accuracy: %0.3f%%
', acc * 100);
% Accuracy is the proportion of correctly classified images
% After 100 iterations, the results for our implementation were:
%
% Accuracy: 92.200%
%
% If your values are too low (accuracy less than 0.91), you should check
% your code for errors, and make sure you are training on the
% entire data set of 60000 28x28 training images
% (unless you modified the loading code, this should be the case)
end
%%%%对应STEP 2: Implement softmaxCost
function [cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, data, labels)
% numClasses - the number of classes
% inputSize - the size N of the input vector
% lambda - weight decay parameter
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
% labels - an M x 1 matrix containing the labels corresponding for the input data
theta = reshape(theta, numClasses, inputSize);% 转化为k*n的参数矩阵
numCases = size(data, 2);%或者data矩阵的列数,即样本数
% M = sparse(r, c, v) creates a sparse matrix such that M(r(i), c(i)) = v(i) for all i.
% That is, the vectors r and c give the position of the elements whose values we wish
% to set, and v the corresponding values of the elements
% labels = (1,3,4,10 ...)^T
% 1:numCases=(1,2,3,4...M)^T
% sparse(labels, 1:numCases, 1) 会产生
% 一个行列为下标的稀疏矩阵
% (1,1) 1
% (3,2) 1
% (4,3) 1
% (10,4) 1
%这样改矩阵填满后会变成每一列只有一个元素为1,该元素的行即为其lable k
%1 0 0 ...
%0 0 0 ...
%0 1 0 ...
%0 0 1 ...
%0 0 0 ...
%. . .
%上矩阵为10*M的 ,即 groundTruth 矩阵
groundTruth = full(sparse(labels, 1:numCases, 1));
cost = 0;
% 每个参数的偏导数矩阵
thetagrad = zeros(numClasses, inputSize);
% theta(k*n) data(n*m)
%theta * data = k*m , 第j行第i列为theta_j^T * x^(i)
%max(M)产生一个行向量,每个元素为该列中的最大值,即对上述k*m的矩阵找出m列中每列的最大值
M = bsxfun(@minus,theta*data,max(theta*data, [], 1)); % 每列元素均减去该列的最大值,见图-
M = exp(M); %求指数
p = bsxfun(@rdivide, M, sum(M)); %sum(M),对M中的元素按列求和
cost = -1/numCases * groundTruth(:)' * log(p(:)) + lambda/2 * sum(theta(:) .^ 2);%损失函数值
%groundTruth 为k*m ,data'为m*n,即theta为k*n的矩阵,n代表输入的维度,k代表类别,即没有隐层的
%输入为n,输出为k的神经网络
thetagrad = -1/numCases * (groundTruth - p) * data' + lambda * theta; %梯度,为 k *
% ------------------------------------------------------------------
% Unroll the gradient matrices into a vector for minFunc
grad = [thetagrad(:)];
end
%%%%对应STEP 3: Implement softmaxCost
% 函数的实际参数是这样的J = @(x) softmaxCost(x, numClasses, inputSize, lambda, inputData, labels)
% 即函数的形式参数J以x为自变量,别的都是以默认的值为相应的变量
function numgrad = computeNumericalGradient(J, theta)
% theta: 参数,向量或者实数均可
% J: 输出值为实数的函数. 调用y = J(theta)将会返回函数在theta处的值
% numgrad初始化为0,与theta维度相同
numgrad = zeros(size(theta));
EPSILON = 1e-4;
% theta是一个行向量,size(theta,1)是求行数
n = size(theta,1);
%产生一个维度为n的单位矩阵
E = eye(n);
for i = 1:n
% (n,:)代表第n行,所有的列
% (:,n)代表所有行,第n列
% 由于E是单位矩阵,所以只有第i行第i列的元素变为EPSILON
delta = E(:,i)*EPSILON;
%向量第i维度的值
numgrad(i) = (J(theta+delta)-J(theta-delta))/(EPSILON*2.0);
end
%%%%对应STEP 4: Implement softmaxCost
function [softmaxModel] = softmaxTrain(inputSize, numClasses, lambda, inputData, labels, options)
%softmaxTrain Train a softmax model with the given parameters on the given
% data. Returns softmaxOptTheta, a vector containing the trained parameters
% for the model.
%
% inputSize: the size of an input vector x^(i)
% numClasses: the number of classes
% lambda: weight decay parameter
% inputData: an N by M matrix containing the input data, such that
% inputData(:, i) is the ith input
% labels: M by 1 matrix containing the class labels for the
% corresponding inputs. labels(c) is the class label for
% the cth input
% options (optional): options
% options.maxIter: number of iterations to train for
if ~exist('options', 'var')
options = struct;
end
if ~isfield(options, 'maxIter')
options.maxIter = 400;
end
% initialize parameters,randn(M,1)产生均值为0,方差为1长度为M的数组
theta = 0.005 * randn(numClasses * inputSize, 1);
% Use minFunc to minimize the function
addpath minFunc/
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% softmaxCost.m satisfies this.
minFuncOptions.display = 'on';
[softmaxOptTheta, cost] = minFunc( @(p) softmaxCost(p, ...
numClasses, inputSize, lambda, ...
inputData, labels), ...
theta, options);
% Fold softmaxOptTheta into a nicer format
softmaxModel.optTheta = reshape(softmaxOptTheta, numClasses, inputSize);
softmaxModel.inputSize = inputSize;
softmaxModel.numClasses = numClasses;
end
%%%%对应 STEP 5: Implement predict
function [pred] = softmaxPredict(softmaxModel, data)
% softmaxModel - model trained using softmaxTrain
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
%
% Your code should produce the prediction matrix
% pred, where pred(i) is argmax_c P(y(c) | x(i)).
% Unroll the parameters from theta
theta = softmaxModel.optTheta; % this provides a numClasses x inputSize matrix
pred = zeros(1, size(data, 2));
%C = max(A)
%返回一个数组各不同维中的最大元素。
%如果A是一个向量,max(A)返回A中的最大元素。
%如果A是一个矩阵,max(A)将A的每一列作为一个向量,返回一行向量包含了每一列的最大元素。
%根据预测函数找出每列的最大值即可。
[nop, pred] = max(theta * data);
end