1.爬虫简介
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
简单来说就是通过编写脚本模拟浏览器发起请求获取数据。

2.爬虫分类
(1)通用网络爬虫(General Purpose Web Crawler):爬取一整张页面源码数据. 抓取系统(爬虫)
(2)聚焦网络爬虫(Focused Web Crawler):爬取的是一张页面中局部的数据(数据解析)
(3)增量式网络爬虫(Incremental Web Crawler):用于监测网站数据更新的情况,从而爬取网站中最新更新出来的数据
(4)深层网络爬虫(Deep Web Crawler):Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
3.反爬机制与反反爬策略
爬虫:使用任何技术手段,批量获取网站信息的一种方式。
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。
(1)robots.txt协议
(2)UA(User-Agent用户访问网站时候的浏览器标识)限制


1 #随机请求头 2 from fake_useragent import UserAgent 3 ua = UserAgent() 4 headers = {'User-Agent': ua.random}
(3)ip限制(限制ip访问频率和次数进行反爬)-------------构造自己的 IP 代理池,然后每次访问时随机选择代理
(4)Ajax动态加载-------使用审查元素分析”请求“对应的链接:在url请求的response中进行局部搜索当前内容,如果没有就点击左边任意请求,进行ctrl+f全局搜索,找到对应的请求(抓包工具推荐:fiddler)
(5)验证码反爬虫或者模拟登陆
(6)cookie限制
4.http/https常用的请求头部信息
User-Agent:请求载体的身份标识
Connection:连接状态(keep-alive/close)
Content-Type:请求数据类型(text/json...)
5.HTTPS:http+加密
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
(1)对称秘钥加密
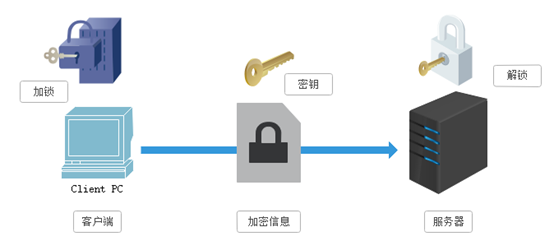
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,客户端在发送请求时将请求数据和加密方式一起发送给服务器。密钥在传输中间虽然是被加密的,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。
(2)非对称秘钥加密

服务器生成加密的公钥和解密的私钥,将公钥发送给客户端,客户端在请求时直接发送通过公钥加密的请求数据即可。
公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥;
非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
(3)数字秘钥证书:
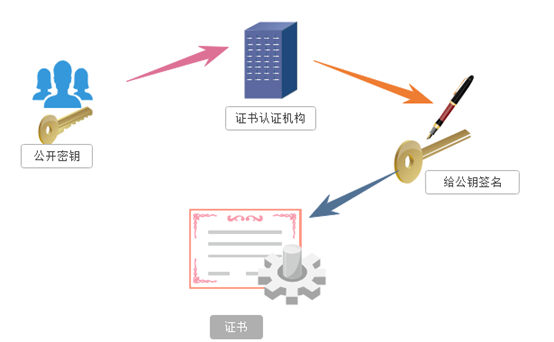
服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起。
服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
6.简单的数据爬取(requests模块)
分析确定url--------->模拟发起请求--------------->获取响应数据-------------------->数据持久化
(1)搜狗首页爬取(get无参数)
1 import requests 2 from fake_useragent import UserAgent#伪造UA(pip install fake-useragent) 3 4 useragent=UserAgent() 5 6 headers={ 7 'UserAgent':useragent.random#随机生成UA 8 } 9 url='https://www.sogou.com/' 10 response=requests.get(url,headers=headers) 11 # print(response.text) 12 with open('sogou.html','w',encoding='utf-8')as f: 13 f.write(response.text)
(2)搜狗搜索内容爬取(get带动态参数params,指定响应数据编码格式)
1 import requests 2 from fake_useragent import UserAgent#伪造UA(pip install fake-useragent) 3 4 useragent=UserAgent() 5 headers={ 6 'UserAgent':useragent.random#随机生成UA 7 } 8 9 url='https://www.sogou.com/web' 10 keyword=input('请输入查询关键字>>>') 11 params={ 12 'query':keyword 13 } 14 response=requests.get(url,params=params,headers=headers) 15 # print(response.content)#输出源码格式-------二进制 16 # print(response.text)#输出文本格式--------编码格式问题乱码 17 # print(response.json())#输出json格式------非json报错 18 19 response.encoding='utf-8'#指定响应数据格式,然后输出 20 print(response.text)
(3)肯德基餐厅位置爬取(post带参数data)
1 # http://www.kfc.com.cn/kfccda/storelist/index.aspx 2 import requests 3 from fake_useragent import UserAgent#伪造UA(pip install fake-useragent) 4 5 useragent=UserAgent() 6 7 headers={ 8 'UserAgent':useragent.random#随机生成UA 9 } 10 url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' 11 city=input('请输入查询城市>>>') 12 data={ 13 'cname':'', 14 'pid':'', 15 'keyword':city, 16 'pageIndex':'1', 17 'pageSize':'100', 18 } 19 20 response=requests.post(url,data=data,headers=headers) 21 for i in response.json()['Table1']: 22 print(i['addressDetail'])
(4)药监总局企业详细信息爬取(ajax+post+data)
1 #http://125.35.6.84:81/xk/药监总局 2 import requests 3 4 num=1 5 headers={ 6 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' 7 } 8 url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' 9 data={ 10 'on':' true', 11 'page':num, 12 'pageSize':' 15', 13 'productName':' ', 14 'conditionType':' 1', 15 'applyname':' ', 16 'applysn':' ', 17 } 18 19 response=requests.post(url=url,data=data,headers=headers) 20 data_json=response.json() 21 li=data_json['list'] 22 23 pageCount=data_json['pageCount'] 24 num+=1 25 26 while num <=pageCount: 27 print(num) 28 response = requests.post(url=url, data=data, headers=headers) 29 li+=response.json()['list'] 30 # print(li) 31 num+=1 32 33 34 url_detail='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' 35 with open('detail.txt','w',encoding='utf-8')as f: 36 for i in li: 37 data_detail={ 38 'id':i['ID'], 39 } 40 response_detail=requests.post(url=url_detail,data=data_detail,headers=headers) 41 42 f.write(response_detail.text+' ')
(5)豆瓣动作片评爬取
1 # https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=&qq-pf-to=pcqq.c2c 2 import json 3 import time 4 5 import requests 6 7 headers={ 8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' 9 } 10 11 START=0 12 END=2000#如果循环爬取,起始位置数据计数会有大量重复,因此设置起始值爬取 13 f=open('豆瓣动作片评分.txt','w',encoding='utf-8') 14 15 url=f'https://movie.douban.com/j/chart/top_list' 16 params={ 17 'type':'5', 18 'interval_id':'100:90', 19 'action':'', 20 'start':START, 21 'limit':END, 22 } 23 response = requests.get(url=url, params=params, headers=headers) 24 data=response.json() 25 26 for movie in data: 27 f.write(f'{movie["rank"]} {movie["title"]} {movie["score"]} ') 28 29 f.close()
(6)图片爬取两种方式(urlib和requests)
1 import requests 2 from fake_useragent import UserAgent#伪造UA(pip install fake-useragent) 3 4 useragent=UserAgent() 5 6 headers={ 7 'UserAgent':useragent.random#随机生成UA 8 } 9 10 url='http://img3.duitang.com/uploads/item/201508/25/20150825001947_fQ8Bi.thumb.700_0.jpeg' 11 response=requests.get(url,headers=headers) 12 with open('1.jpg','wb')as f: 13 f.write(response.content)
1 # (2)urlib爬取图片,直接存储,不能设置请求头 2 from urllib import request 3 url='http://img3.duitang.com/uploads/item/201508/25/20150825001947_fQ8Bi.thumb.700_0.jpeg' 4 response=request.urlretrieve(url,filename='2.jpg')