Anomaly detection(异常检测)
1、问题定义:假设数据集{x(1), x(2), ..., x(3)}表示的数据都是正常的,则判断xtest是否异常。
若概率值 p(xtest) < ε,则表示异常;若 p(xtest) ≥ ε ,则表示正常。
2、Gaussian Distribution(高斯分布 / 正态分布):
(1)分布:X ~ N(μ,σ²) μ为均值,σ²为方差.

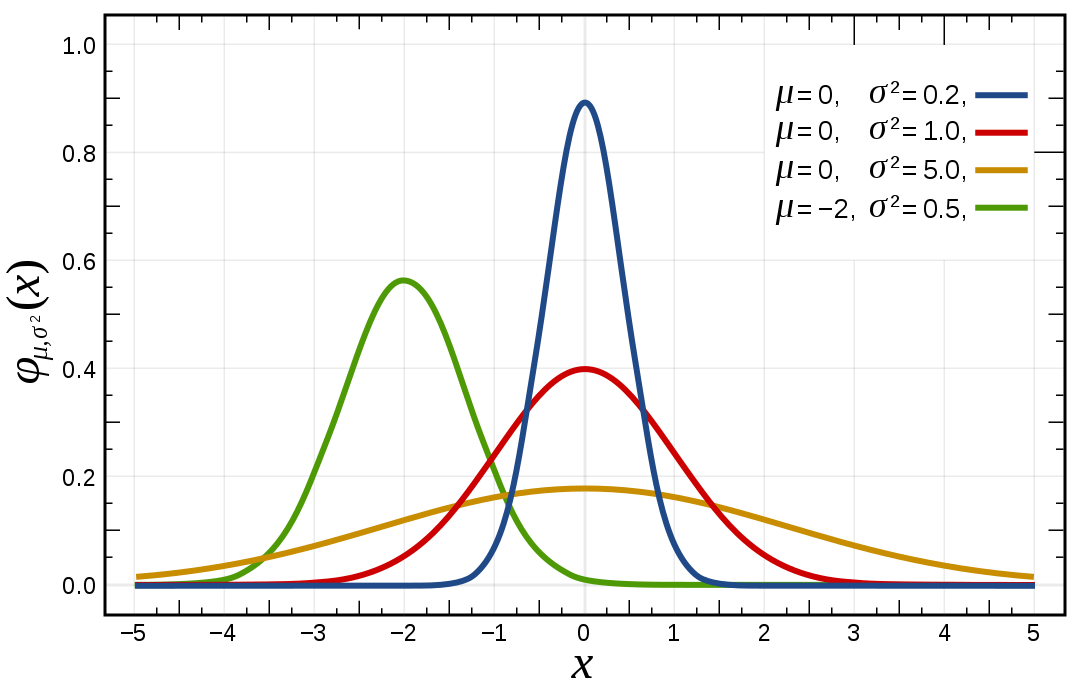
(2)Parameter estimation(参数估计):
给定数据集,估算出 μ 和 σ 的值.
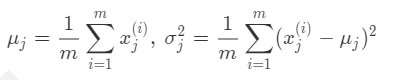
3、应用高斯分布实现异常检测算法:
训练集:{x(1), x(2), ..., x(m)},每一个数据都是 n 维向量.
建立模型:p(x) = p(x1; μ1, σ1²) p(x2; μ2, σ2²) p(x3; μ3, σ3²) ... p(xn; μn, σn²)
算法流程:

4、开发异常检测系统:
(1)使用带标签的数据集,y = 0表示正常,y = 1表示异常,即:
![]()
(2)训练集表示所有正常的样本集合(视为不带标签),设置交叉验证集和测试集:
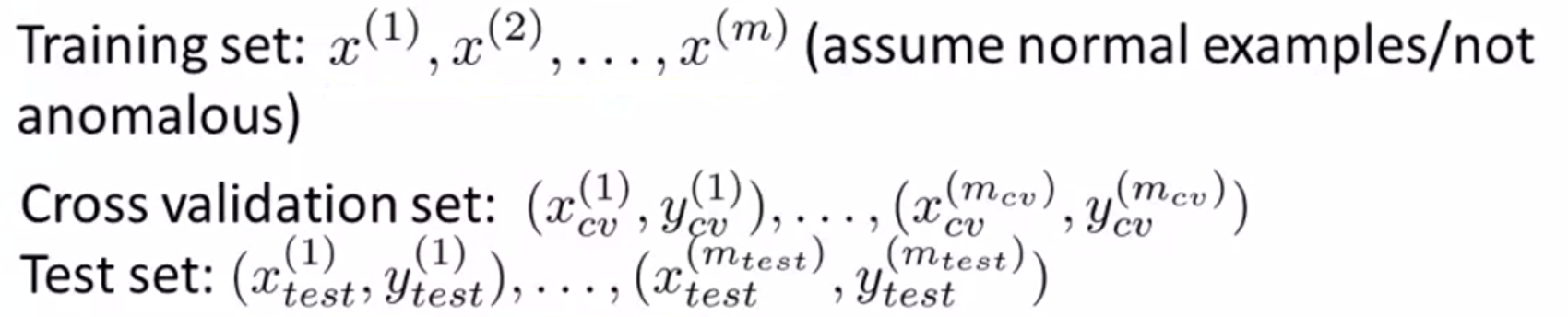
举例:如果一共10000个正常数据,20个异常数据:
![]()
可以通过交叉验证集选择较好的 ε 参数. 选择算法评估结果最好的(F1-score最高).
(3)算法评估:
由于异常的数据占极少数,因此是倾斜类的情况,不能仅仅通过计算预测的准确率来评估系统。需要计算 precision、recall,并计算F1-score.
5、异常检测与监督学习的区别:
既然异常检测也带有便签,为什么不直接用逻辑回归等方法进行分类预测呢?
| 异常检测 | y = 1 的样本极少,而 y = 0 的样本极多. |
| 异常的种类很多,可能在以往的数据中都没有出现过. | |
| 应用于:欺诈检测、生产次品检测、监测数据中心等. | |
| 监督学习 | 大量的正负样本. |
| 有足够的样本让算法感知到不同种类的特征. | |
| 应用于:垃圾邮件检测、天气预测、分类等. |
6、特征量的选择:
(1)特征量的调整:
在对特征向量建模时,需要使得 xi 服从正态分布,或者接近于正态分布,如下图所示:

若不服从正态分布,则需要进行修正,如下图所示:

(2)误差分析:
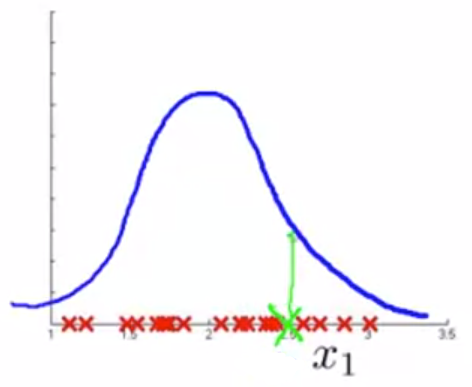
当某一个数据处于异常,但是系统并没有检测出,即 p(x) 取值仍然较大,则可能原因是特征较少。
如下图所示,当只有一个特征量时,p(x) 值较高,但拓展特征量后,发现它处在了高斯分布的外围区域.
7、Multivariate gaussian distribution(多元高斯分布):
(1)问题背景:
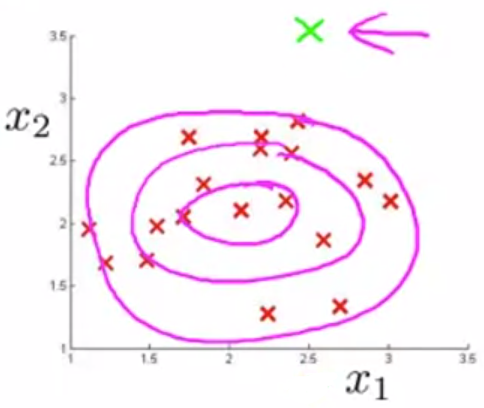
在监测数据中心的例子中,有两个特征 x1 和 x2,当出现一个异常的样本,它有较低的CPU load和较高的Memory Use,在 x1 和 x2的正态分布图中可以看出,该样本含有较高的 p(x1) 和 p(x2),也就是有较高的 p(x),并不会被判定为异常.
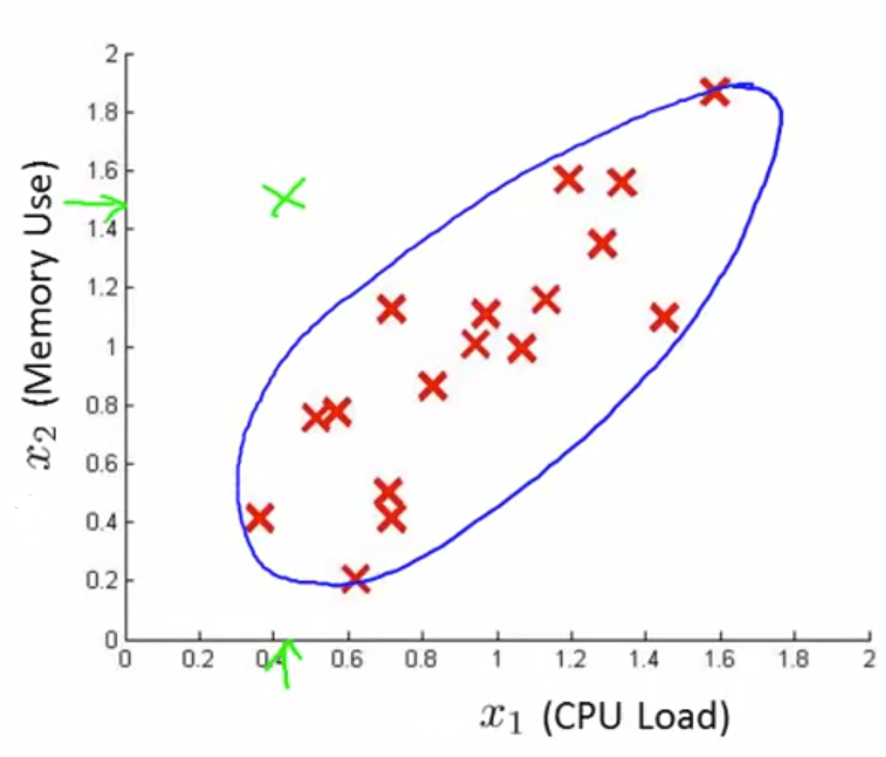
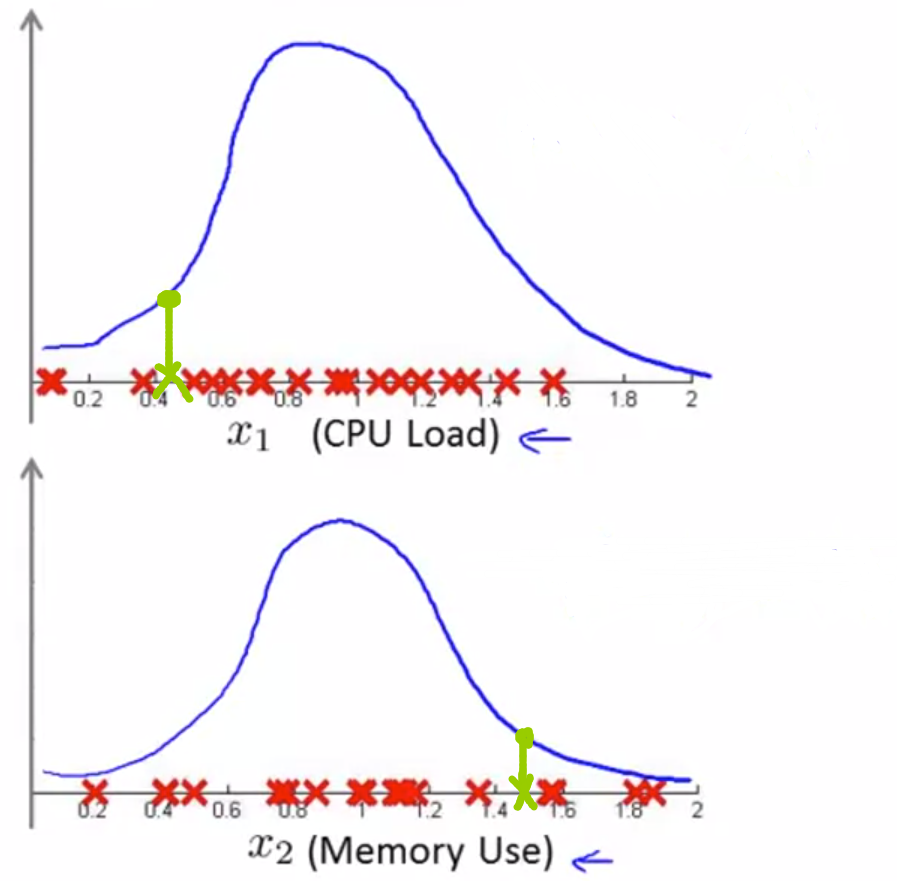
原因分析:我们倾向于认为两个特征所构成的区域具有较为均匀的概率分布.
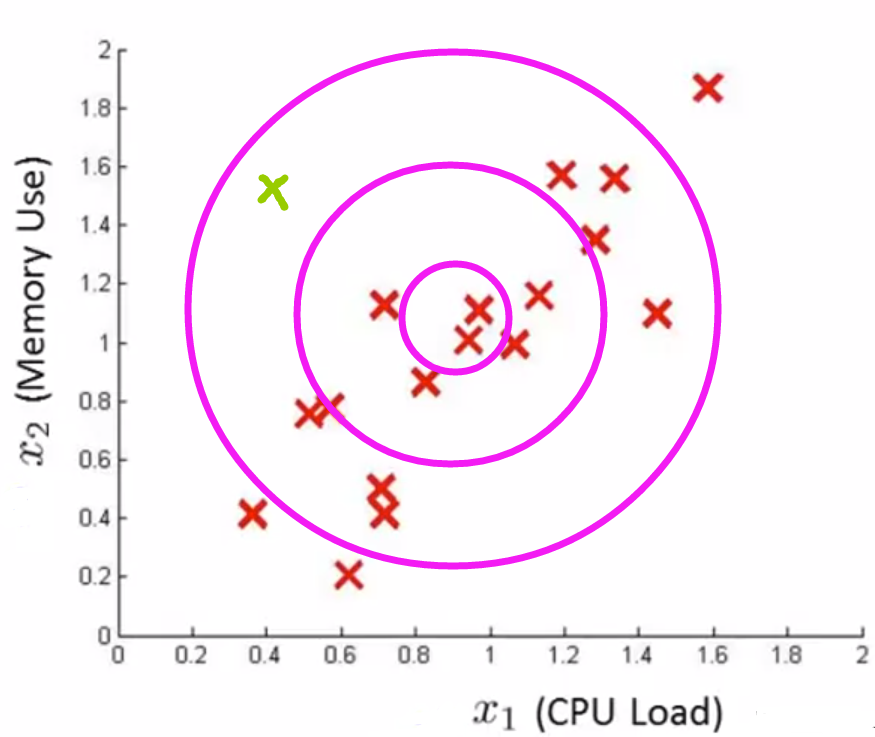
(2)算法改进:
X的协方差矩阵,第 i 行第 j 列表示 xi 和 xj 的协方差,
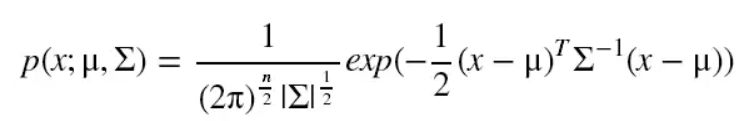
举例:

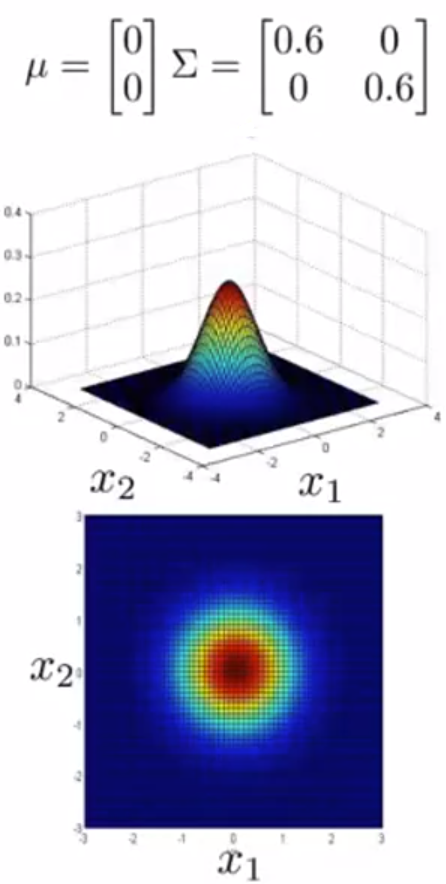
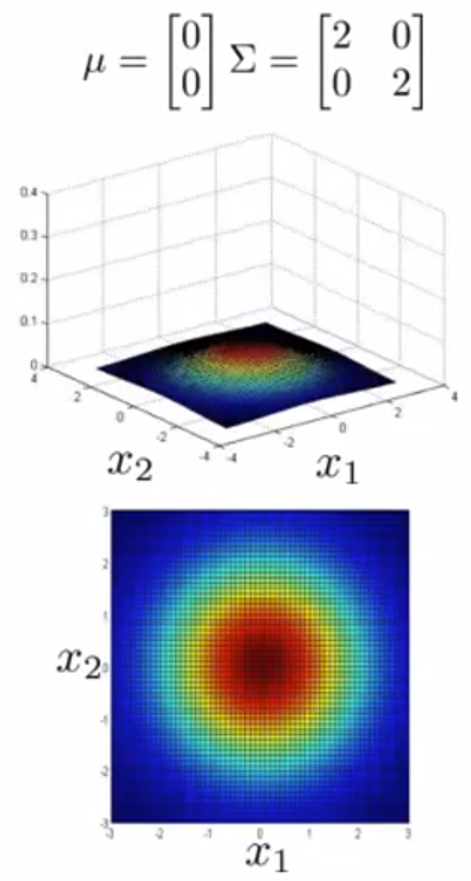



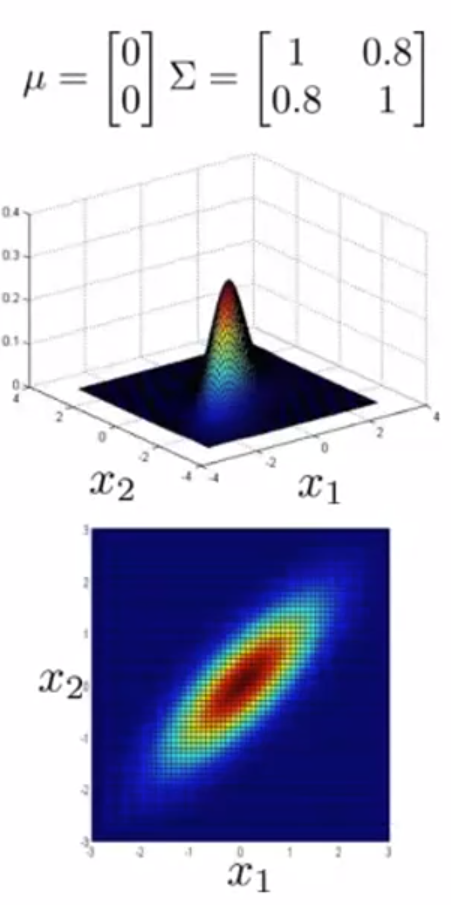


(3)应用多元高斯分布:
① 计算参数,拟合模型:![]()
② 对于新样本计算 p(x):![]()
若 p(x) 小于阈值,则判定为异常点.
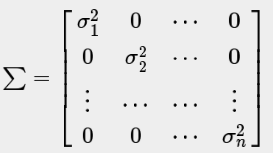
(4)多元高斯分布模型与常规高斯分布模型的联系:
常规高斯分布模型对应多元高斯分布模型的情况:Σ 非对角线元素全为0.
对于误差情况,一种方法是增加特征量(上文已阐述),另一种方法是使用多元高斯模型自动捕捉不同特征量之间的相关性.
|
常规高斯分布 Original model |
计算量小,n 较大的情况也适用. |
| 即时样本数 m 较少也适用. | |
|
多元高斯分布 Multivariate gaussian |
Σ 计算量大,适用于 n 较小的情况. |
|
必须满足 m > n,否则 Σ 不可逆. 要求 m >> n. |
Σ 不可逆的两种情况:① 不满足 m > n; ② 有冗余的特征量.
Recommender systems(推荐系统)
1、以电影推荐系统举例:一共编号1 2 3 4四个人,5部电影(前3部为爱情类,后2部为动作类),评分由0-5,可见编号1、2更喜欢爱情类电影,编号3、4更喜欢动作类电影。

符号定义:
nu:用户的数量;
nm:电影的数量;
r(i, j):如果用户 j 已经对电影 i 进行评分,那么 r(i, j) = 1,否则 r(i, j) = 0;
y(i, j):用户 j 对电影 i 的评分(仅对 r(i, j) = 1的定义).
推荐系统的原理:根据已知的数据,预测出带问号的空缺数据的可能值.
2、基于内容的推荐系统:
(1)原理:
使用两种特征量,x1表示爱情电影的程度,x2表示动作电影的程度.

设 x0 = 1,第 i 部电影设为 x(i),例如 x(1) = [1 0.9 0]T. 用 n 表示特征数量,即 n = 2. 第 j 个用户评价过的电影数量为 m(j).
若观众的打分预测是独立的线性回归问题,则每一个用户 j 都有特征参数 θ(j),其为 n+1 维向量. 对于电影 i 的打分为 (θ(j))Tx(i).
现对第1个用户的第3部电影的评分进行预测:
x(3) = [1 0.99 0]T
θ(1) = [0 5 0]T
value = (θ(1))Tx(3) = 4.95
(2)参数 θ 的训练:(本来求和公式前的常数是 1/(2m(j)),但为了计算方面,将 m(j) 去除,不影响结果)


3、Collaborative filtering(协同过滤):
又名 Low rank matrix factorization (低秩矩阵分解)
(1)问题描述:
假设不知道电影的各个指数(如爱情电影指数、动作电影指数等),仅仅使用上述的方法,无法进行预测. 但若已知用户对各类电影的喜好程度,即已知 θ,则可以预测出各类电影的指数.


(2)目标描述:

即

利用 θ 和 x 的重复计算和迭代,收敛到一组合适的电影特征.
简化问题,可以定义新的代价函数 J,将问题转换为:
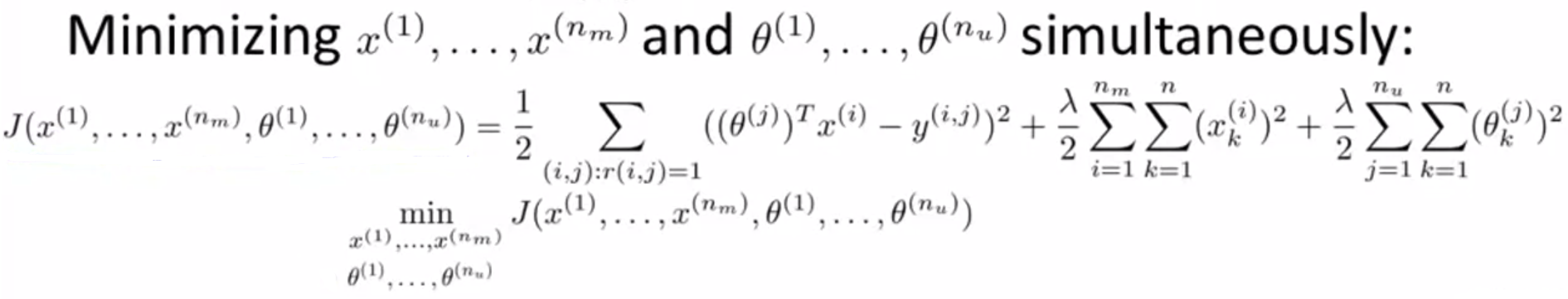
(3)算法流程:
① 初始化 x(1), ..., x(nm) 和 θ(1), ..., θ(nu),初始值设置为一个较小的随机数(类似于神经网络,使得各个参数初始化值不一样);
② 使用梯度下降法,最小化 J(这里没有考虑 x0、θ0,即 k 从1开始):
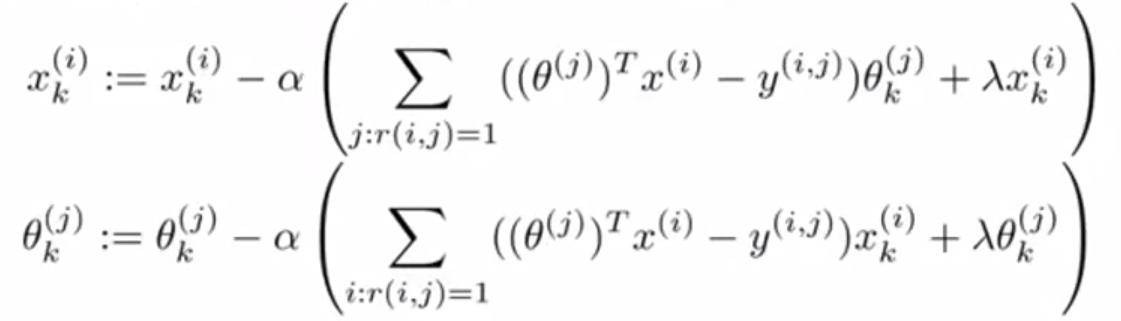
③ 若对一个用户进行预测,给出了参数 θ 或者电影的指数 x,则可以使用 θTx 进行预测评分.
(4)电影推荐的向量化实现:
① 将打分数据转为矩阵 Y:

一般化预测评分矩阵:
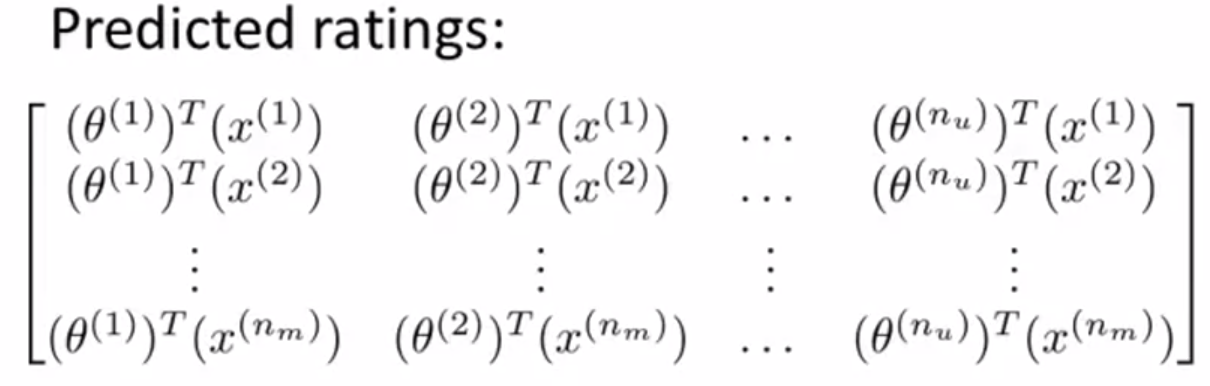
② 电影特征矩阵:x(i) 表示第 i 部电影的特征向量,是一列,(x(i))T 将列向量转为行向量.
X = [ (x(1))T (x(2))T ... (x(nm))T]T
每一个用户的参数 θ 同理构成矩阵 Θ,θ(j) 表示第 j 个用户,是一列,(θ(j))T 将列向量转为行向量.
Θ = [(θ(1))T (θ(2))T ... (θ(nu))T]T (结构类似 X )
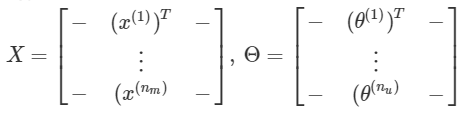
③ 在使用协同过滤算法求得 X 和 Θ 后,预测评分矩阵为 XΘT.
由于 XΘT 有低秩属性,因此命名:低秩矩阵分解算法.
④ 寻找电影 i 的相关电影,即寻找若干个电影 j ,使得最小化![]()
4、推荐系统的实现细节:均值归一化:
(1)问题背景:当第五个用户对于数据中的电影一部都没看过,即下图的情况:
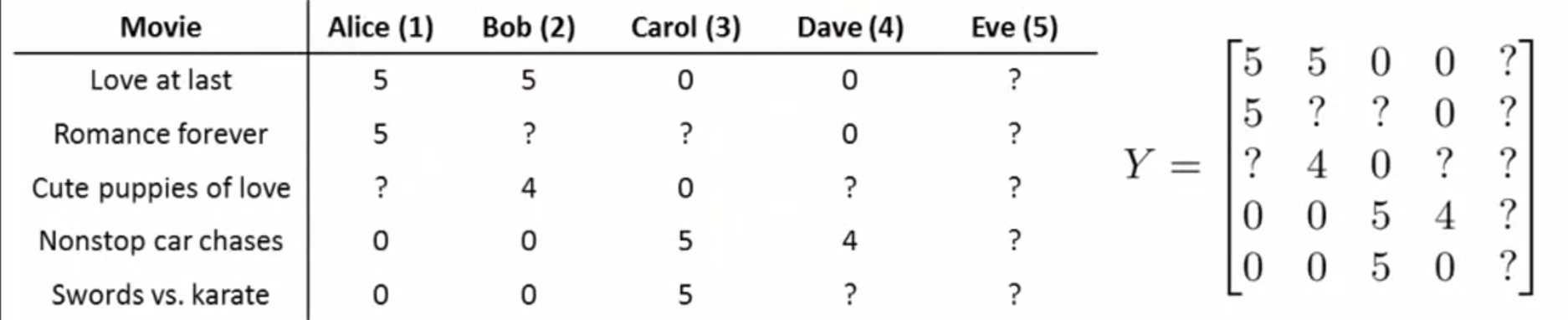
那么当计算 θ(5) 时,根据目标函数的定义:![]()
目标函数转为最小化 λ/2 * [(θ1(5))² + (θ2(5))²],
有此会得出解 θ(5) = [0 0]T
最后的预测结果是把所有电影评分为 0.
(2)解决方法:均值归一化
对于原矩阵 Y,减去均值 μ,将得到的新 Y 矩阵作为样本数据进行学习,得到 Θ 和 X,在进行预测. 在预测结果加上μ,即 XΘT + μ. 如下图:

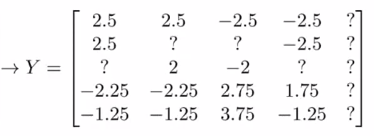
含义:一无所知的新用户,把电影的平均评分作为预测评分进行推荐.