Introduction
(1)问题描述:
super resolution(SP)问题:Gallery是 high resolution(HR),Probe是 low resolution(LR)。

(2)当前存在的问题:
① 当前的半耦合(semi-coupled)矩阵学习是解决SR复原,而不是直接进行行人重识别;
② 行人图片存在噪声,直接使用半耦合矩阵学习无法很好的刻画特征空间。
(3)Contribution:
① 提出一个新的半耦合低秩判别矩阵学习方法(semi-coupled low-rank discriminant dictionary learning approach,SLD2L),该方法从图像特征中学习得到高低分辨率字典对,将低分辨率特征映射到高分辨率特征;
② 提出一个多视角 SLD2L 方法,对不同类别的特征学习出不同的特征对。
Brief Review
(1)SR问题中的耦合字典训练:
目标函数:

其中 xi 和 yi 为HR和LR的一对,且![]() ,γ 是平衡因子,Dx 和 Dy 为耦合字典,K 为原子数量,N 为训练样本数量,a 为编码系数。
,γ 是平衡因子,Dx 和 Dy 为耦合字典,K 为原子数量,N 为训练样本数量,a 为编码系数。
(2)行人重识别问题中的半监督耦合字典学习(SSCDL):
假定 x = {x1, x2, ..., xn}, y = {y1, y2, ..., ym},目标函数:
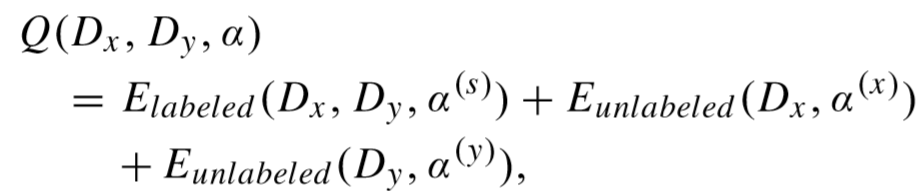
其中 α(x),α(y) 为无标签样本的系数矩阵,α(s) 为带标签样本的共享系数矩阵。
(3)半耦合矩阵学习(SCDL):
目标函数:
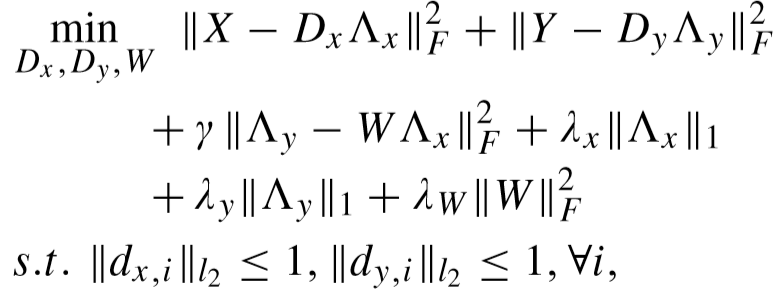
其中 γ、λx、λy、λW 为平衡因子,dx,i,dy,i 为字典矩阵的原子,Λx、Λy 为编码系数矩阵,W 为映射矩阵。
Semi-coupled low-rank discriminant dictionary learning(SLD2L)
(1)问题定义:
CA 表示相机A拍摄的HR行人图像,CB 表示相机B拍摄的LR行人图像,并生成相机A的LR图像 CA',即和 CB 含有相同的分辨率。
在实际中,低分辨率在不同区域的影响是不一样的,如在单一色调的区域影响较小,在复杂纹理的区域影响较大,因此可以考虑将图像划分为若干patch,并对patch进行聚类,对每个聚类学习一个子字典(sub-dictionary)和映射函数。文章对 CA' 和 CB 进行划分patch,并使用K-means聚类,在依据 CA' 的聚类结果,将 CA 划分的patch聚入其中。
定义第 i 个聚类的HR、LR的字典为 DHi、DLi, 第 i 个聚类的映射矩阵为 Vi,获得字典集合有:DH = [DH1, DH2, ..., DHc],DL = [DL1, DL2, ..., DLc],映射矩阵集合有 V = {V1, V2, ..., Vc},c 为聚类数量.
其它参数定义:

(2)方法概述:

目标函数:
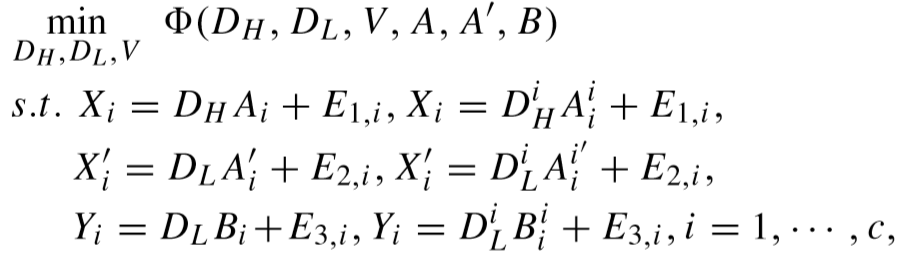
其中的约束条件为:学习的字典能够非常好的表示训练样本的内在特征,E1,i,E2,i,E3,i 表示噪声。
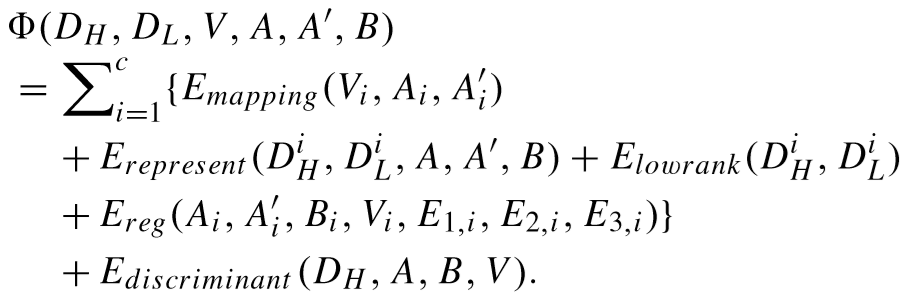
其中:
映射项:![]()
子字典表征能力项:
(为了让第 i 个子字典对除了第 i 个聚类外的特征,具有较差的表征能力)
低秩正则化项:![]()
正则化项:![]()
区分度项: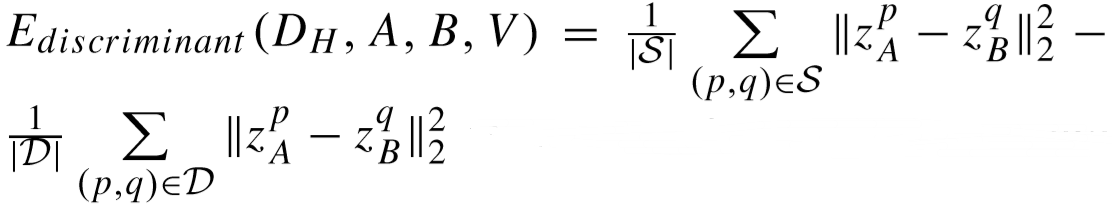
(其中 S 和 D 表示正样本对和负样本对,![]() 表示 CA 第 p 个图片的重构特征,
表示 CA 第 p 个图片的重构特征,![]() 表示 CB 第q 个图片的重构特征,n 为每张图片的patch数)
表示 CB 第q 个图片的重构特征,n 为每张图片的patch数)
(3)优化算法:
① 固定 DH、DL、V,更新 A、A'、B:
初始化字典和映射矩阵:字典采用PCA偏差进行初始化,映射矩阵采用单位矩阵初始化;
编码系数计算如下,其中d()表示为区分度项的计算函数:
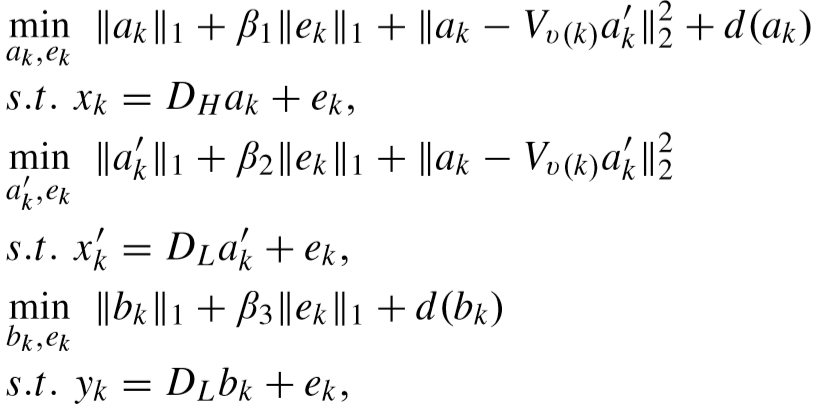
解法:
对于第一个优化目标,转化为如下问题:
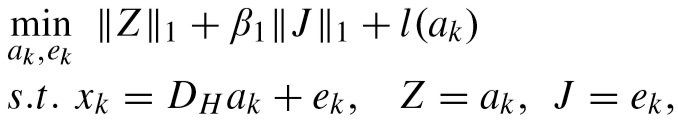
其中![]()
可以转为增广拉格朗日乘子问题(Augmented Lagrange Multiplier problem)【传送门】,即:
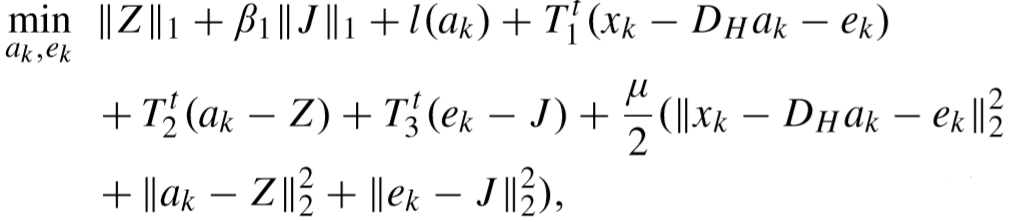
【具体解法在该论文的引用[47][50]中介绍,尚未阅读】
第二第三个优化目标同理。
② 固定 DHj、DLj、A、A’、B、V(其中 j ≠ i),更新 DHi 和 DLi:
由于受到约束条件![]() 、
、![]() 、
、![]() 等影响,
等影响,![]() 、
、![]() 、
、![]() 也要进行更新。定义:
也要进行更新。定义:![]()
![]() ,DHi 和 DLi 的更新过程如下:
,DHi 和 DLi 的更新过程如下:

其中:

且:![]()
![]()
解法:
将 DHi 的目标函数更新为:
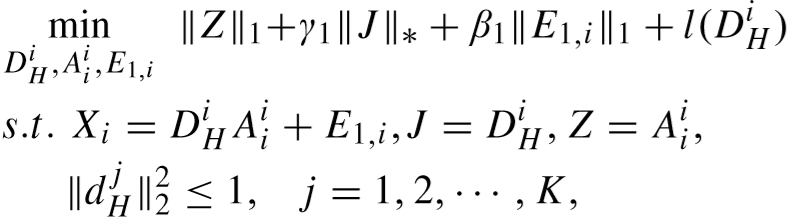
其中:![]()
转化为拉格朗日乘子问题:

DLi 的解法同理。
③ 固定 DHi、DLi、A、A'、B、Vj(j ≠ i),更新 Vi:
![]()
其中 ![]()
![]()
令:![]() ,则目标函数转化为:
,则目标函数转化为:
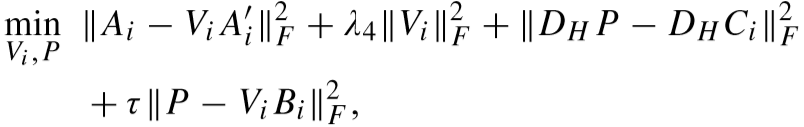
迭代更新如下:

上式是一个岭回归问题,求解为:
![]()
下式求解为:
![]()
(4)算法总结:

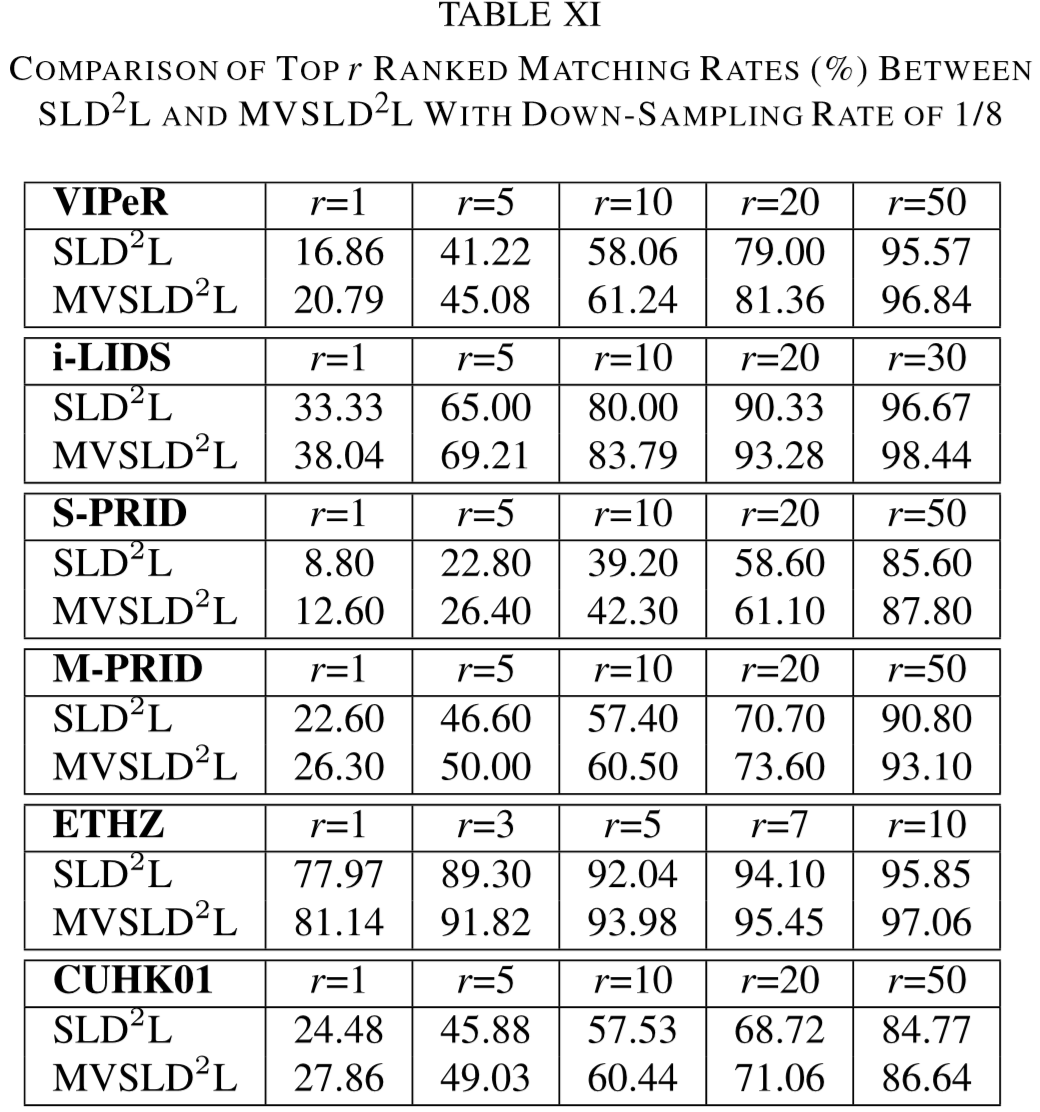
Multi-view SLD2L(MVSLD2L)
通过实验发现,不同的特征提取对于高低分辨率的映射效果是不同的。
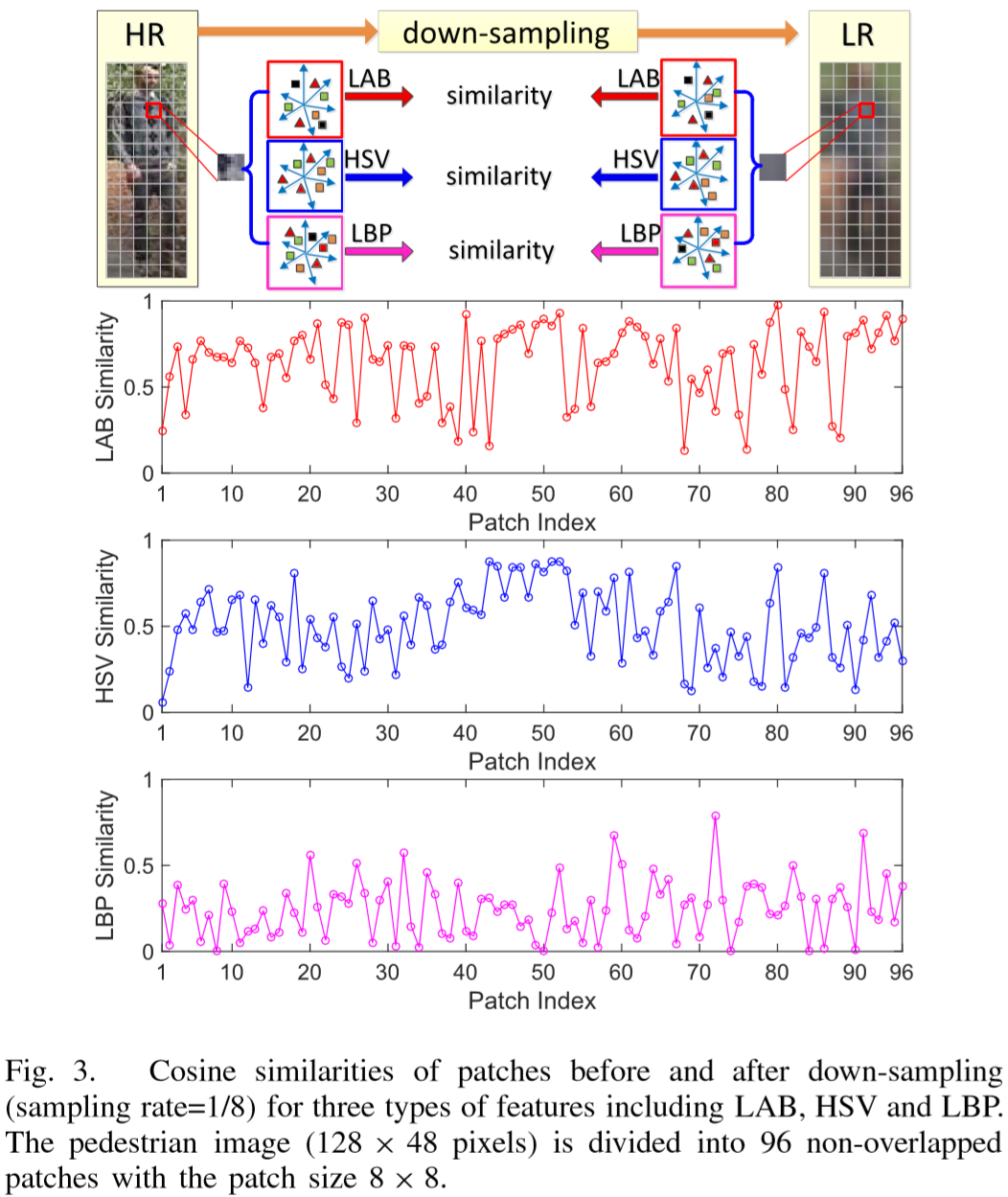
MVSLD2L 针对不同类型的特征学习不同的映射矩阵,即:对于每个patch,都提取 HSV、LAB、LBP特征,并学习对应的映射矩阵。
变量定义更新:
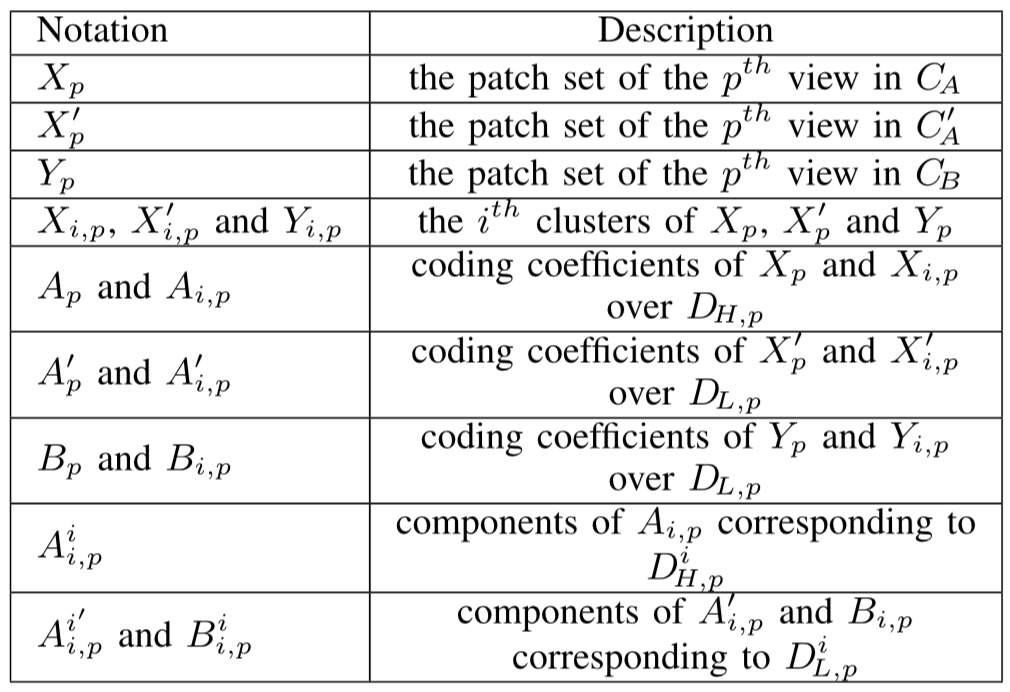
目标函数更新:
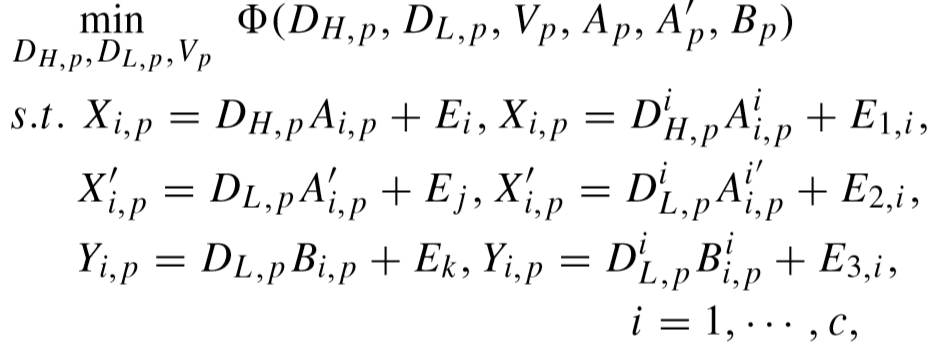
采用上述方法解出每种特征的字典和映射矩阵。
Super-resolution person re-identification with learning dictionaries and mappings
(1)采用SLD2L的行人重识别:
① 将Probe中LR图像映射到HR特征中:
定义 yi 为第 i 个patch的特征:
![]()
聚类索引 j 通过以下函数计算:
![]()
将特征 yi 映射到HR特征中:
![]()
② 重构Gallery中的图像的特征:
![]()
③ 采用欧氏距离计算,对Probe图像与Grallery图像进行匹配。
(2)采用 MVSLD2L 进行行人重识别:(主要流程同上,在重构特征部分改进如下)

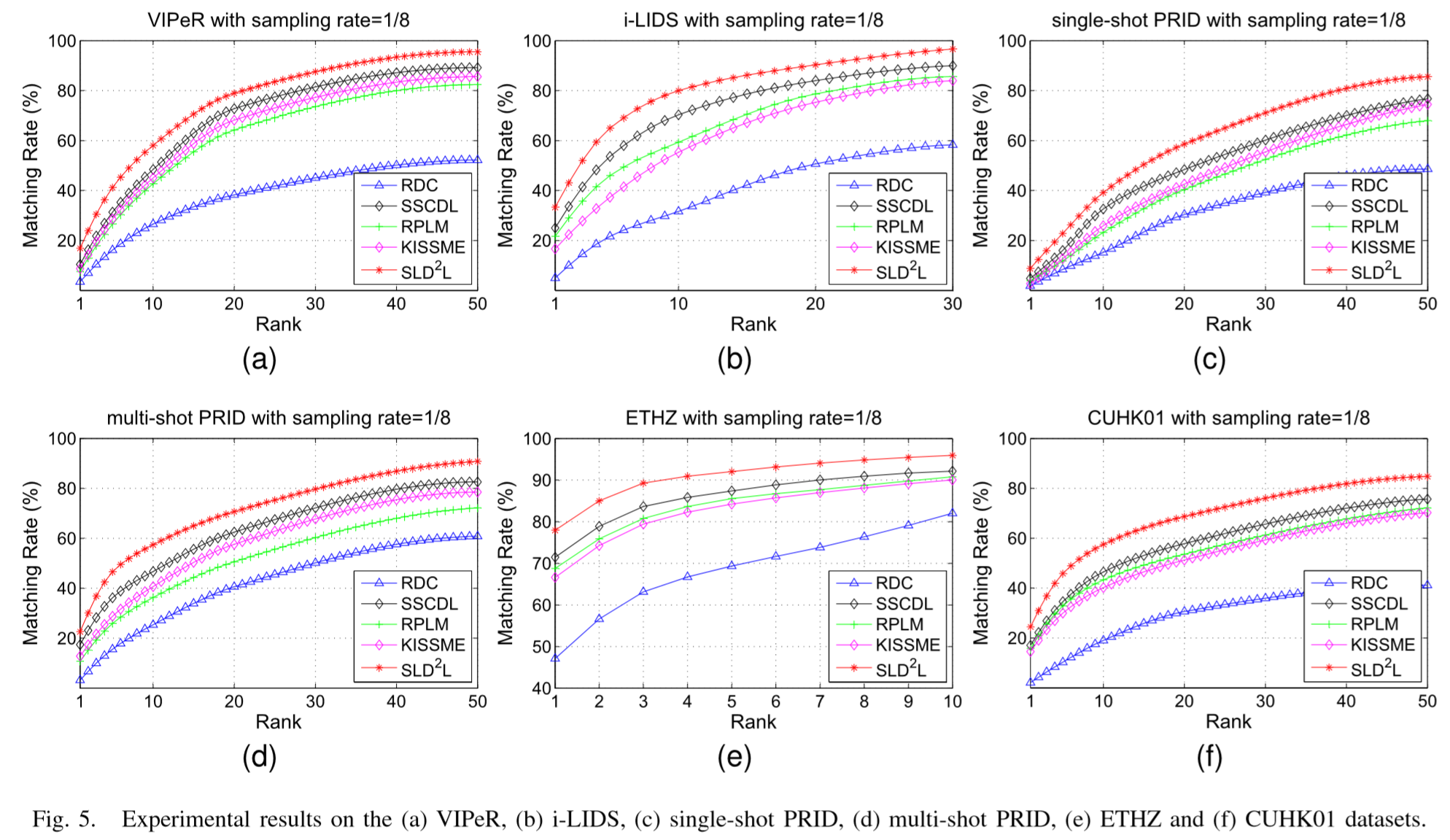
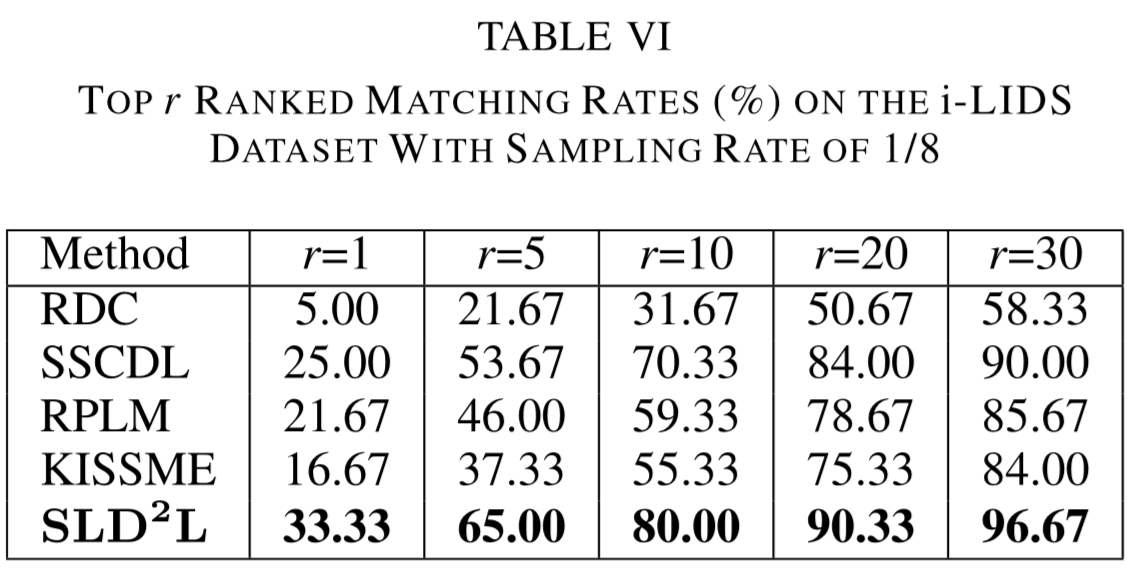
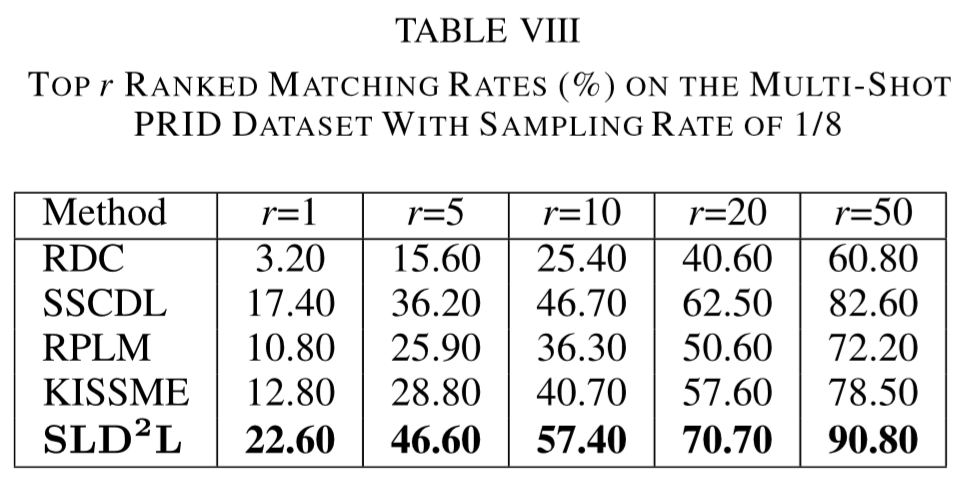
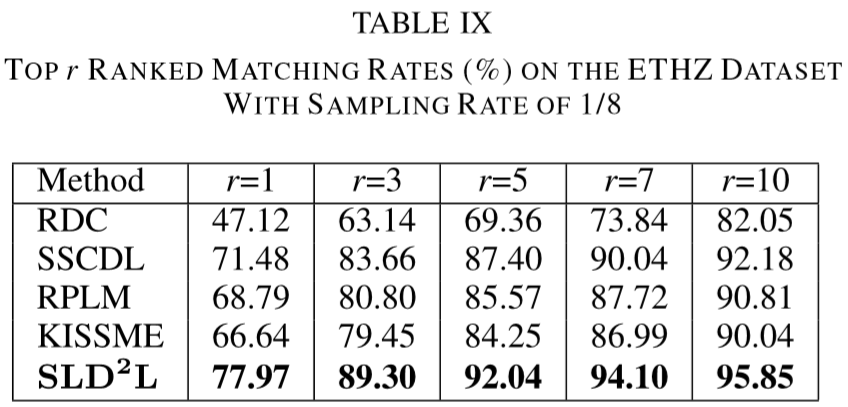
Experimental results
(1)实验设置:
① 数据集:VIPeR、PRID、CUHK01、i-LIDS、ETHZ;
② 特征提取:HSV、LAB、LBP;
③ 参数设置:λ1 = 1,λ2 = 1,λ3 = 1,λ4 = 1,
对于 VIPeR,![]()
对于 i-LIDS,![]()
对于 PRID,![]()
对于 ETHZ,![]()
对于 CUHK01,![]()
![]()
![]()
设置聚类的数量为64,图片的patch分割为 8*8,每个子字典的原子数量为 48.
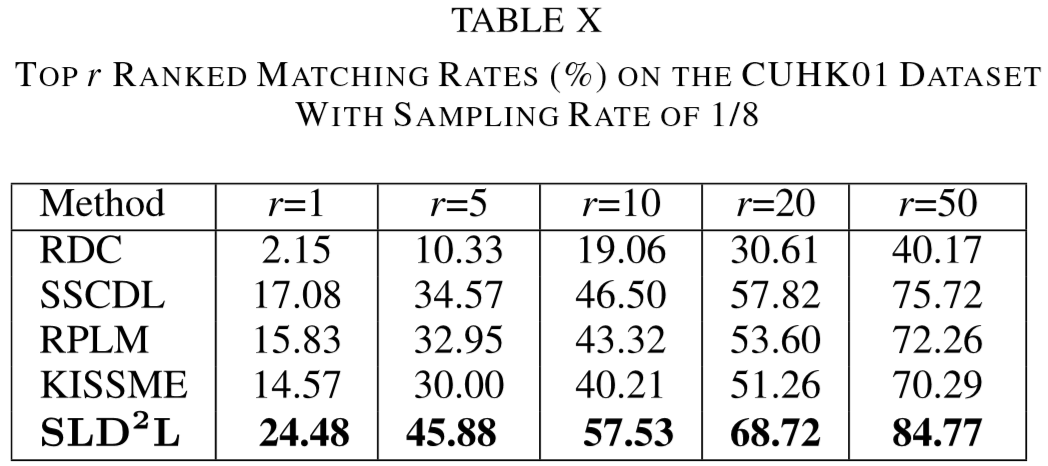
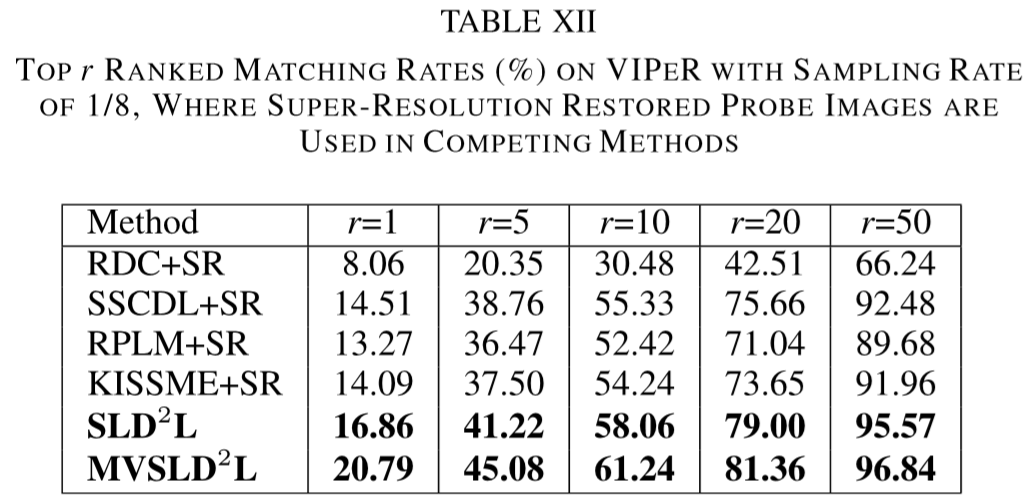
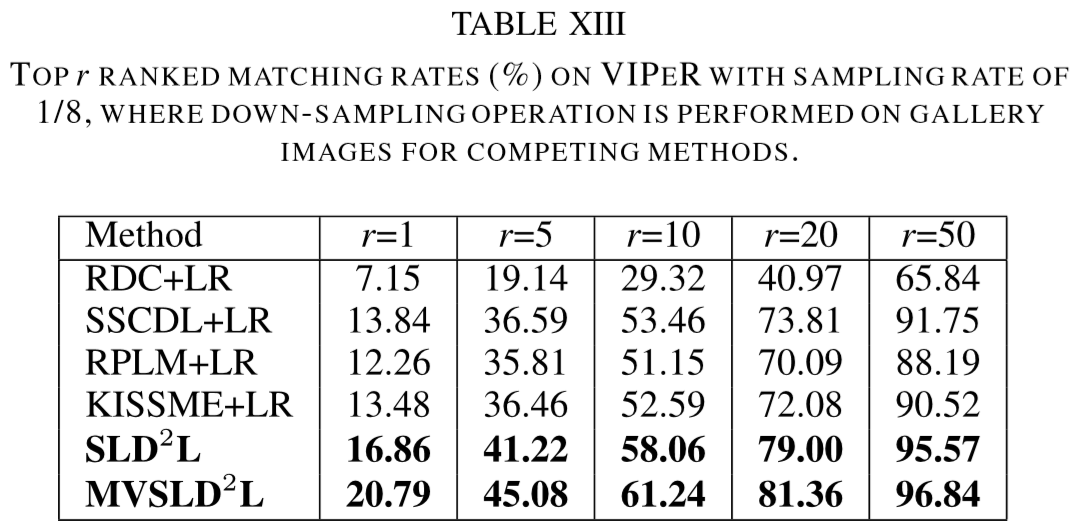
(2)实验结果: