CS231n
4.1 Backpropagation
回顾:
两个损失函数:

优化的方法:

如何计算梯度:
- 用有限差分估计
- 直接计算偏导数(解析梯度)

今天,我们要学习如何计算任意复杂度的解析梯度
要用到一个叫做计算图的框架:
每一个节点代表着计算
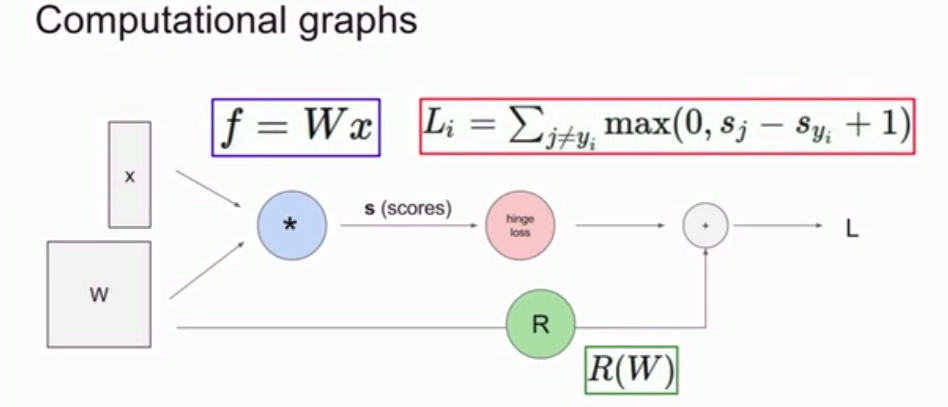
上图是我们讲过的线性分类器
这里使用计算图的好处是:
一旦我们可以用计算图来表示一个函数,那就能用所谓的反向传播技术。递归地使用链式法则,计算图中每一个变量的梯度!
下面来介绍反向传播算法是如何工作的:
举一个实际例子:
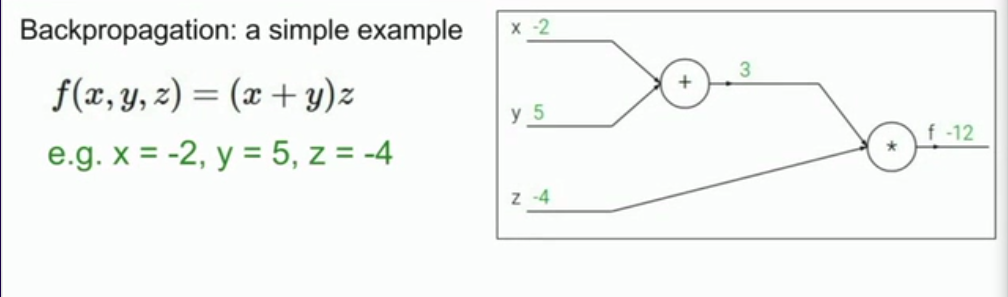
首先我们要用计算图来表示出整个函数
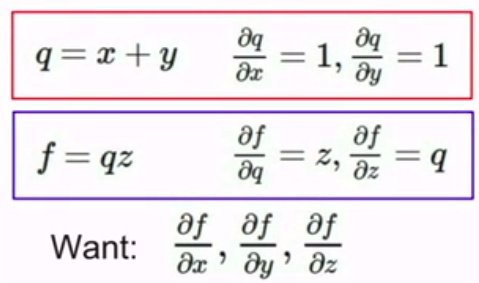
这里用到了中间结点
然后,从后往前算梯度:(如图所示)
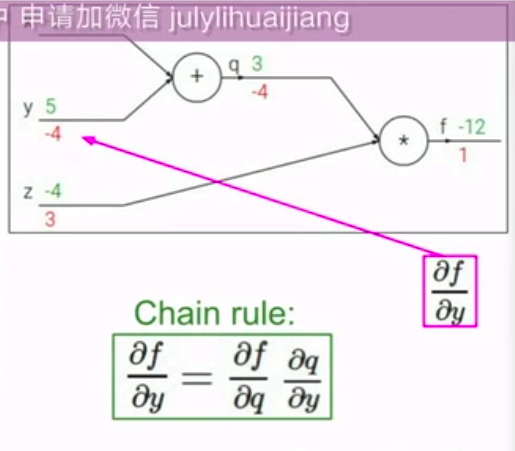
其中,因为用到了中间项,所以使用链式法则!
注:为什么在这里不直接算出来?因为这个例子很简单,在其他很复杂的例子后,很难直接算。
一旦表达是十分复杂,你绝不会想用微积分来算出来。
但如果你用这种方法,就可以把复杂的表达式分解成一些计算结点。然后就可以用基础运算就可以算出你想要的梯度值而不需要算出整个表达式。
现在,我们来分解看看反向传播到底在做什么:
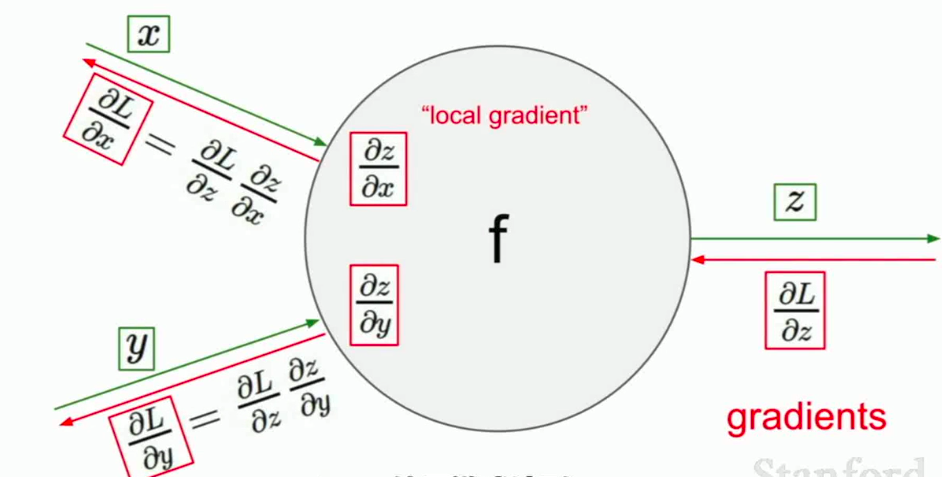
主要工作就是:
在每一个节点上计算我们所需要的本地梯度,local gradient, 然后跟踪这个梯度。在反向传播的过程中,我们接受从上游传回来的这个梯度值,我们直接用这个梯度值乘以本地梯度,然后得到我们想要传回连接点的值。我们不考虑除了直接相连的结点之外的任务东西。
接下来我们来看一个更复杂的例子:
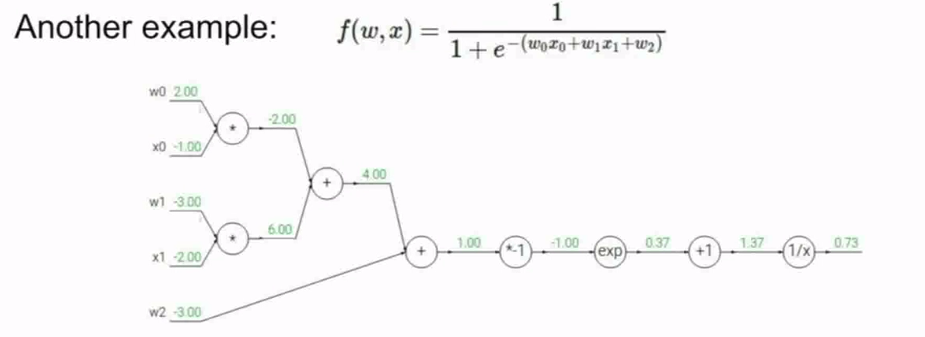
然后按照惯例,执行反向传播算法:

逐步前进:
用上游梯度值乘以本地梯度值
其中几个步骤:


我们额外来看看分支节点:
在这里我们要算2个分支!!!!

注明:当我们遇到加法运算的节点的时候,加法运算对每个输入的梯度,正好是 1
所以在这里,本地梯度是 1 乘以 反向梯度 0.2
得到总的梯度是0.2
继续移动,接近终点 了!

在这里对w0, 上游梯度是0.2 乘以 x的值(也就是本地梯度) —— -1
我们可以用相同的方法算出x0
这里,就已经完成了反向梯度计算了:
那么,为什么这样做会使计算更简单?
答:在这里可以看出,我们处理过的本地梯度的表达式要先写出来,我们要做的就是填充每一个值,然后使用链式法则,从后往前乘以这些值得到对所有变量的梯度。
值得提醒的一点是:我们可以将原表达式化为最简单的步骤,也可以化为稍微复杂点的步骤,反正殊途同归。
例如下图的蓝色方框可以合成为一个节点

在这里的sigmoid函数,以后我们也会经常用到
所以,你可以聚合你想要的任意节点,去组成一些在某种程度上稍微复杂的节点
但这都取决于你的判断,如何更简单地用计算图表达和计算??
我们再重新审视一下到底会发生什么以及总结一下步骤
以及我们还有一个wired的函数,max函数 |
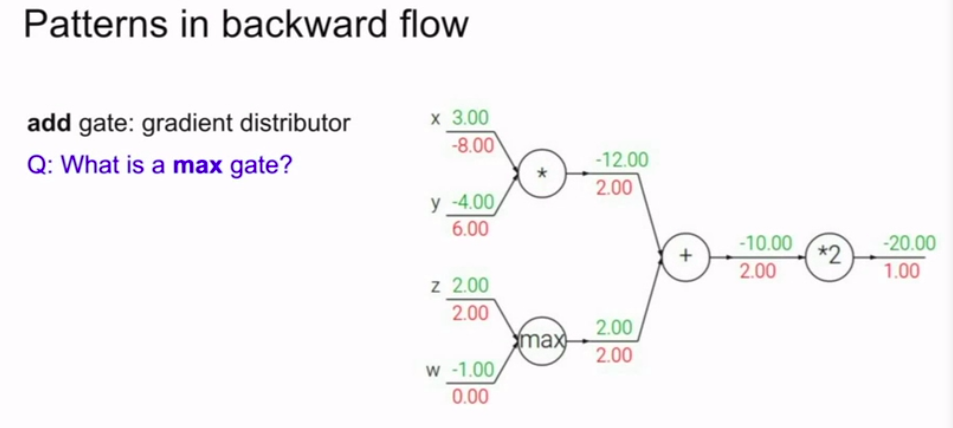
max门就是传递最大的。
而它的本地梯度一个是1,一个是0!可以认为它是一个路由器
mul门(乘法门)就是求导带入,然后可以发现是一个梯度转换器!
add门。如图

这次我们学到的就是计算任意复杂函数的梯度
额,不过以上所讲的都是一维的例子,下面我们来讲当变量是高维向量的情况
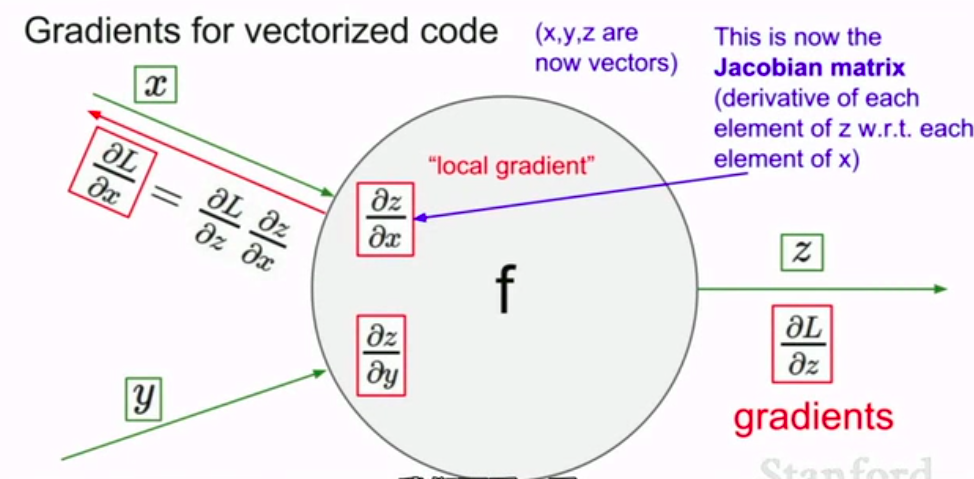
现在假设我们有x,y,z三个变量。三个向量而不再是标量。计算流程还是一样的,唯一的区别就是我们刚才的梯度变成 了Jacobian矩阵。雅可比矩阵
现在是一个包含了每个变量中各个元素导数的矩阵
比如z在每个x元素方向上的梯度。
so,看一个例子:

问题来了,雅克比矩阵中要几行几列呢?
雅克比矩阵中每一行都是偏导数。矩阵中的每个元素是输出向量的每个元素,对输入向量每个元素分别求偏导的结果。
答案是4096*4096。这是一个非常大的矩阵。
但是,这个雅克比矩阵有特点,就是
这个矩阵是一个对角矩阵。
所以我们并不需要全部矩阵写出来,我们只需要求出输入向量关于x的偏导。然后把结果作为梯度填进去。
下面看一个例子:

首先如上图所示,把前向传播计算出来,
然后,着手反向传播的计算:
(frac{part f}{part q_i} = 2q_i)
(
abla_qf = 2q)
所以,向量的梯度总是与原向量保持相同的大小
每个梯度的元素代表着这个特定元素对最终函数影响的大小。
现在我们倒退一步:
W的梯度是什么?
再次运用相同的概念,链式规则:我们希望计算关于w的q的本地梯度。
在元素级别,如果我们这么做,观察一下影响。
推导公式:
(frac {part q_k}{part W_{i,j}} = 1_{k=i}x_j)
最后我们可以写成向量形式:
(
abla_Wf = 2q * x^T)
always check 记住一个重要的事情
检查变量梯度的向量大小,应该和变量向量大小一致
这在实际应用中是非常有用的完整性检查。
因为每一个梯度元素量化了元素对最终结果所造成的影响
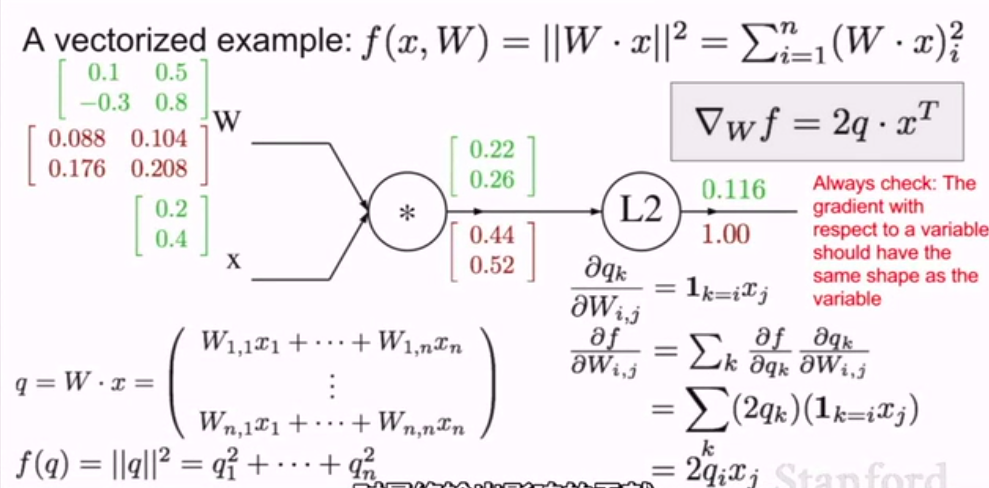
所以,最终公式是:
( abla_xf = 2W^T * q)
下面是前向传播和反向传播的伪代码:

这是门的代码:
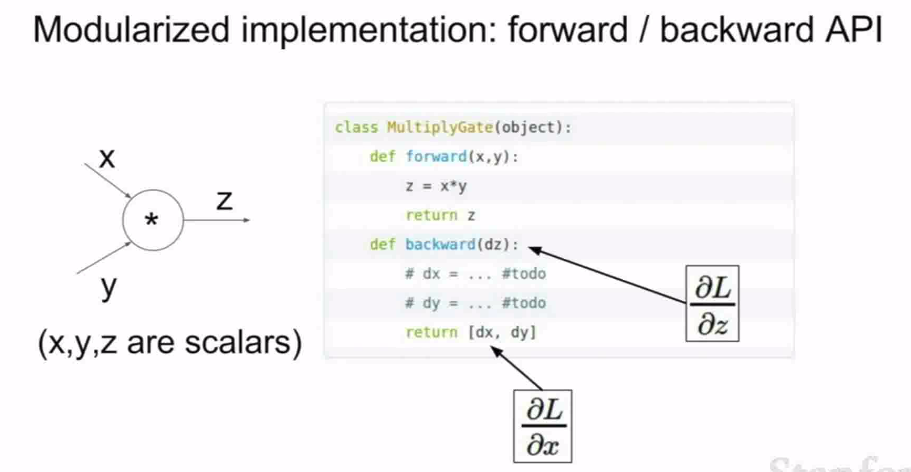
这是前向和反向传播的代码:

这体现了一种模块化设计
在作业当中,我们也需要用模块化表达

总结:
- 神经网络通常非常大,所以用一点点写出梯度下降是非常不现实的
- 反向传播算法——通常要根据计算图来实现,用递归计算。
- 要仔细设计自己所需要的计算图的结构等等。要设计好前向传播和反向传播的API接口
- 对于前向传播:计算出运算的结果并储存好需要的数据是很重要的,对于梯度下降来说
- 对于反向传播:应用链式法则来计算梯度的损失函数是很重要的。记得使用上游梯度和本地梯度
