一、
抽象类InputStream和OutputStream构成了了IO类的基础
因为面向字节流的对象不便于处理Unicode形式储存的信息,所以从抽象类Reader和Writer中继承出专门用于处理Unicode字符的类构成了一个单独的层次结构
这些类拥有的读入和写出操作都是基于两字节的Unicode码元的。
二、
每个子类只需覆盖InputStream中read方法(读入一个字节)或者是OutputStream中write方法(向某个位置写出一个字节)
read和write在执行时都将阻塞,直至字节确实被读入或写出,如果流不能被立即访问则该线程阻塞(可通过available方法判断可用于读入的字节数量来避免阻塞)
API:
java.io.InputStream:
(1)abstract int read():从数据中读入一个字节,并返回该字节,在碰到流的尾时返回-1
(2)int read(byte[] b):读入一个字节数组,返回实际读入的字节数,最多读入b.length个字节,在碰到流的尾时返回-1
(3) int read(byte[] b, int off, int len):读入一个字节数组。这个read方法返回实际读入的字节数,或者在碰到流的结尾时返回-1
参数:b 数据读入的数组
off 第一个读入字节应该被放置的位置在b中的偏移量
len 读入字节的最大数量
(4) long skip(long n):在输入流中跳过n个字节,返回实际跳过的字节数(如果碰到流的结尾,则可能小于n) 。
(5) int available():返回在不阻塞的情况下可用的字节数(阻塞意味着当前线程将失去它对资源的占用) 。
(6) void close():关闭流
(7) void mark(int readlimit):在输入流的当前位置打一个标记(并非所有的流都支持这个特性) 。如果从输入流中已经
读入的字节多于readlimit个,则这个流允许忽略这个标记。
(8)void reset():返回到最后的标记,随后对read的调用将重新读入这些字节。如果当前没有任何标记,
则这个流不被重置。
(9)boolean markSupported():如果这个流支持打标记,则返回true。
java.io.OutputStream:
(1) abstract void write(int n):写出一个字节的数据。
(2) void write(byte[] b)
(3) void write(byte[] b, int off, int len):写出所有字节或者某个范围的字节到数组b中
参数:b 数据写出的数组
off 第一个写出字节在b中的偏移量
len 写出字节的最大数量
(4) void close():清空并关闭输出流。
(5) void flush():清空输出流,也就是将所有缓冲的数据发送到目的地
三、流家族:
(一)字节流家族:

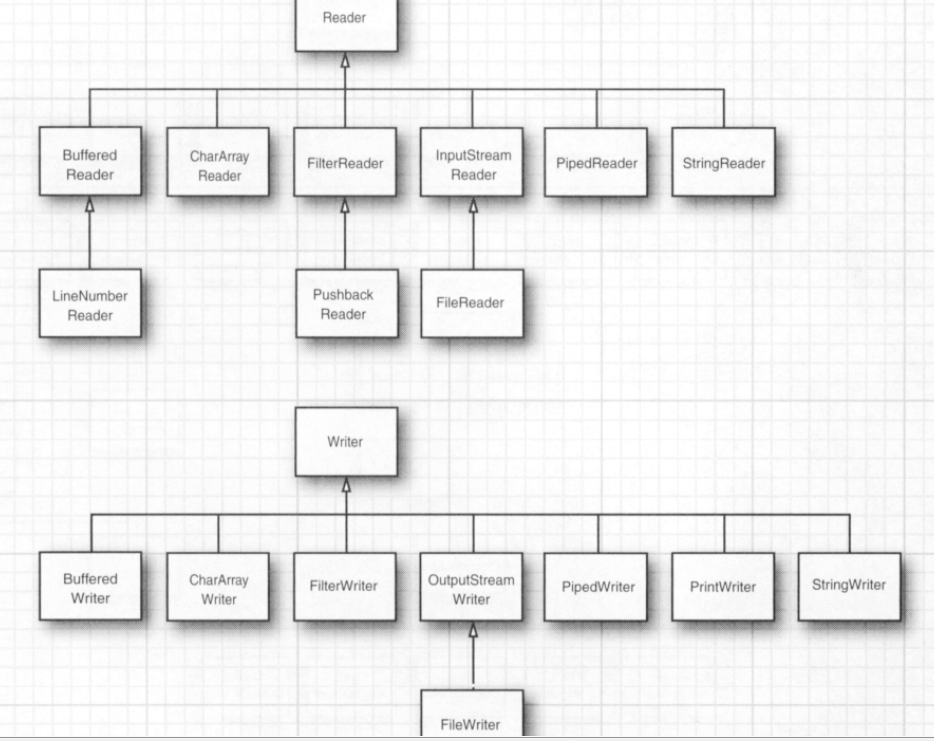
(二)Unicode文本流家族
四、组合流过滤器:
FileInputStream和FileOutputStream只能从文件中读入字节或者字节数组(不能读入数字类型),而DataInputStream只能读入数字类型(不能从文件中获取数据),那么可以组合这两个类从文件中读取数字:
FileInputStream fin = new FileInputStream(“test.txt”);
DataInputStream din = new DataInputStream(fin);
Double s = din.readDouble();
流在默认情况下是不进缓冲区的,那么我们可以这样组合:
DataInputStream din = new DataInputStream(
New BufferedInputStream(
New FileInputStream(“test.txt”)));(之所以把datainputsteam放在最后是为了使用DataInputStream的方法,并且希望它们能够使用带缓冲机制的read方法)