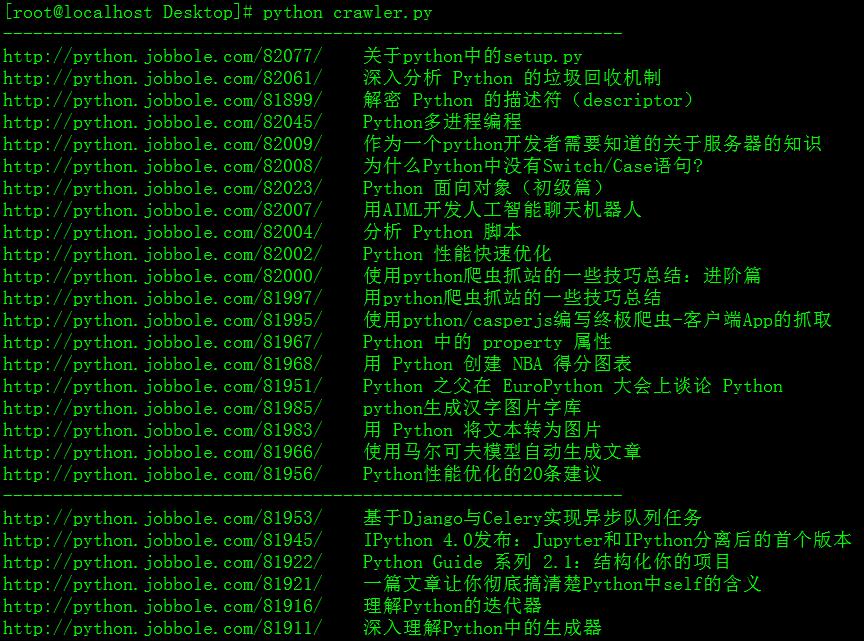
因为要学习python,所以看到一些网站有很多文章。
如:http://python.jobbole.com/all-posts/
目标:
将某个网站脚本编程-》python模块这个分类下所有的文章标题和网址提取(就相当于一个目录索引了)
在目录中找东西总好过一页页点击网页上的下一页吧。
为什么用python来实现呢,因为实在太简单易用了。在不考虑效率的情况下是大大方便了我等小白
我感觉我用爬虫得几个原因:
自从百度的site、intitle、inurl等这类搜索命令失效之后搜索关键内容的灵活度降低了,找不到想要的内容
技术博客里面有很多文章分类,可是一个分类下的文章遗憾的就是没有目录,难道要一页一页地打开网页查找么
不过不试不知道,一个简单的爬虫也牵扯了挺多东西的,总结一下
1、正则表达式,为了一行代码,把正则表达式的东西又加深学习了一遍了,无分组捕获、命名捕获、零宽断言、贪婪模式等等以前没有听过的东东。具体自己去了解吧!
2、urllib的使用,简单的使用也会有问题,看错误如下
IOError: ('http protocol error', 0, 'got a bad status line', None)
http://blog.csdn.net/yueguanghaidao/article/details/11994229 中有解释是因为http://www.website.com/需要在域名后加"/",不然会报"IOError: ('http protocol error', 0, 'got a bad status line', None)”。我第一次抓取的网页有这个错误,加了“/”访问网页直接返回404。我换成urllib2就有错误“httplib.BadStatusLine”
后来发现IOERROR是因为那个坑爹的网页本来就有问题,前一刻访问好好的,程序没写完就变成了足彩网站了。我可以理解为网站管理员休假了么。
3、中文编码问题,成功抓取了可是显示了一片看不明白的东东。看了下encode(),decode()毫无头绪,我怎么知道用什么来解码啊
>>> print fi
['python chardetxc4xa3xbfxe9xc5xd0xb6xcfxd7xd6xb7xfbxb1xe0xc2xeb'
引用一段:出自http://www.linuxidc.com/Linux/2014-11/109853.htm
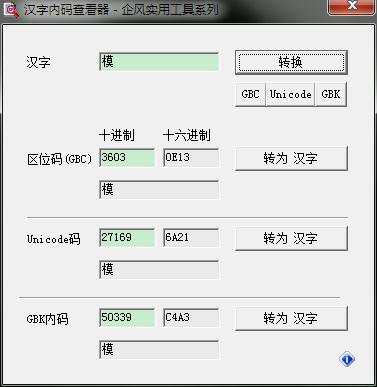
可以发现C4A3的编码是GBK,哈哈,别介意我作弊,然后成功解码。
#coding=utf-8 import urllib2 import re import time pattern_site_title=re.compile(r'(?<=<a class="archive-title" target="_blank" href=")(.*)(?="stitle="(.*)">)') for page in range(1,10): url='http://python.jobbole.com/all-posts/page/%d/'%page try: url_open=urllib2.urlopen(url) except: exit() print "urlopen error!" result=pattern_site_title.findall(url_open.read()) print "--------------------------------------------------------------" for i in range(0,len(result)): print "%s %s"%result[i] time.sleep(3) url_open.close()
正则表达式是个值得研究的地方,怎样才能匹配到自己需要的内容。简单的几行程序,实现了需要的功能。有更多的需要还可以在这基础上扩展。噢~~python真是个好东西