关键字: requests BeautifulSoup html.parser str.strip() quote() json replace() openpyxl cookies session filter() tkinter selenium schedule gevent scrapy
第0关 认识爬虫
1. 浏览器的工作原理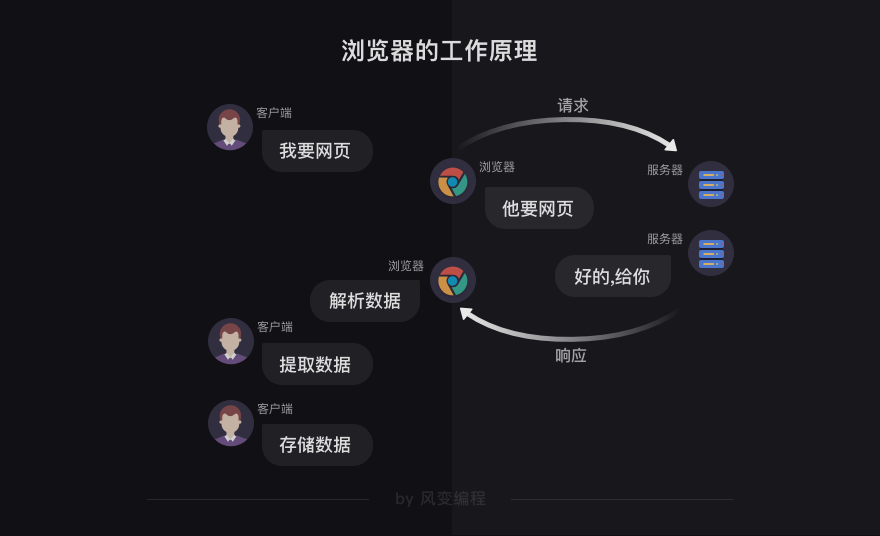
首先,我们在浏览器输入网址(也可以叫URL),然后浏览器向服务器传达了我们想访问某个网页的需求,这个过程就叫做【请求】
紧接着,服务器把你想要的网站数据发送给浏览器,这个过程叫做【响应】
所以浏览器和服务器之间,先请求,后响应,有这么一层关系
当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给你,因为这些数据是用计算机的语言写的,浏览器还要把这些数据翻译成你能看得懂的样子,这是浏览器做的另一项工作【解析数据】
紧接着,我们就可以在拿到的数据中,挑选出对我们有用的数据,这是【提取数据】
最后,我们把这些有用的数据保存好,这是【存储数据】
以上,就是浏览器的工作原理,是人、浏览器、服务器三者之间的交流过程
2. 爬虫的工作原理
爬虫可以帮我们代劳这个过程的其中几步↓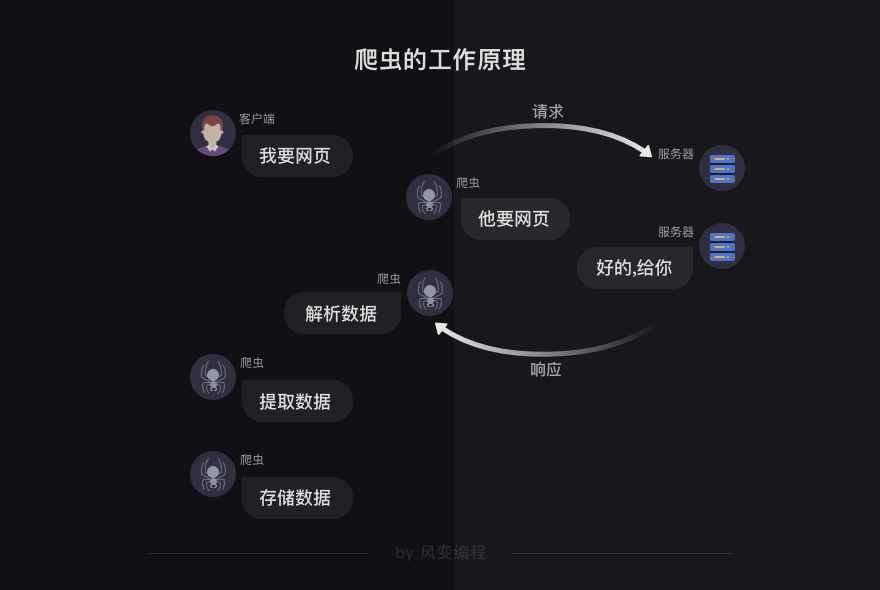
当你决定去某个网页后,首先,爬虫可以模拟浏览器去向服务器发出请求;其次,等服务器响应后,爬虫程序还可以代替浏览器帮我们解析数据;接着,爬虫可以根据我们设定的规则批量提取相关数据,而不需要我们去手动提取;最后,爬虫可以批量地把数据存储到本地
简化上图,就是爬虫的工作原理了↓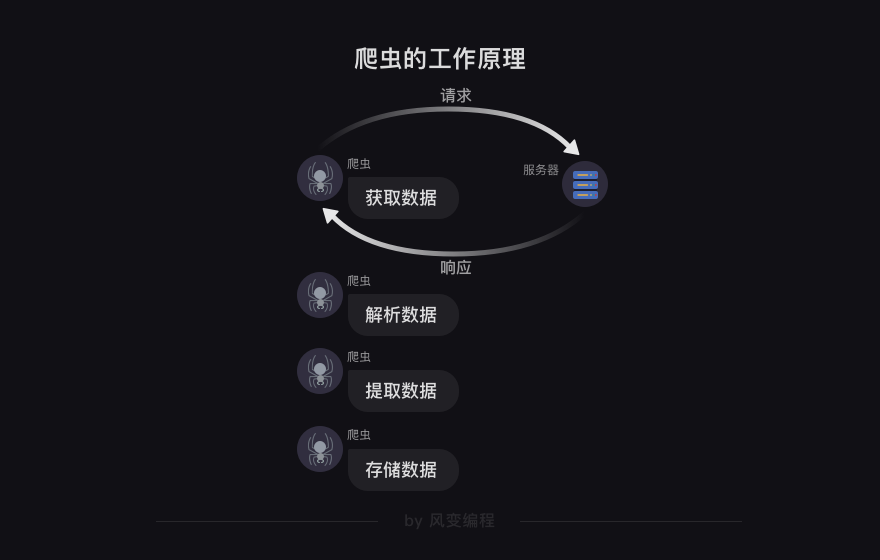
其实,还可以把最开始的【请求——响应】封装为一个步骤——获取数据。由此,我们得出,爬虫的工作分为四步↓
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式
第2步:提取数据。爬虫程序再从中提取出我们需要的数据
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析
3. requests库
Mac安装方法:打开终端软件(terminal),输入pip3 install requests,然后点击enter即可
requests库可以帮我们下载网页源代码、文本、图片,甚至是音频。其实,“下载”本质上是向服务器发送请求并得到响应
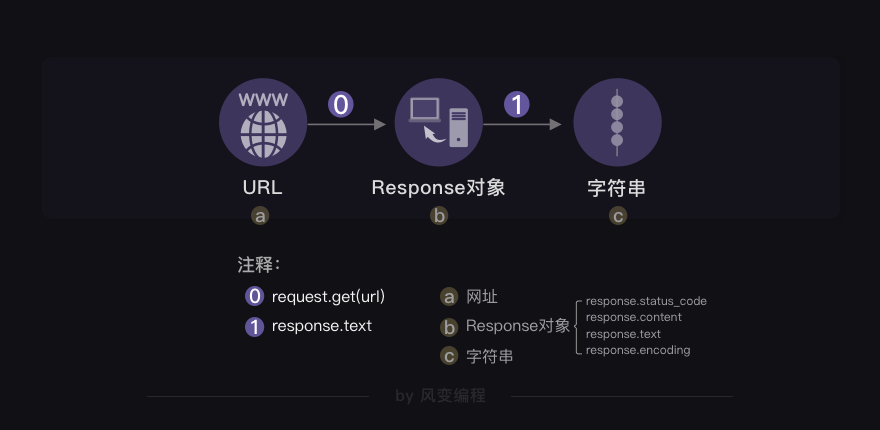
4. requests.get()
import requests # 引入requests库 res = requests.get('URL') # requests.get()方法向服务器发送了一个请求,括号里的参数是你需要的数据所在的网址,然后服务器对请求作出了响应 # 服务器返回的结果是个Response对象,赋值到变量res上
如果用图片展示,那就是这样的↓
5. Response对象的常用属性
import requests res = requests.get('https://www.cnblogs.com/oyster25/p/12334132.html') print(type(res)) # 打印变量res的数据类型 # 》》<class 'requests.models.Response'>
打印结果显示,res是一个对象,属于requests.models.Response类
response.status_code
import requests res = requests.get('https://www.cnblogs.com/oyster25/p/12334132.html') print(res.status_code) # 打印变量res的响应状态码,以检查请求是否成功 # 》》200
status_code用来检查requests请求是否得到了成功的响应,终端结果显示了200,这个数字代表服务器同意了请求,并返回了数据给我们
下面表格供参考不同的状态码代表什么↓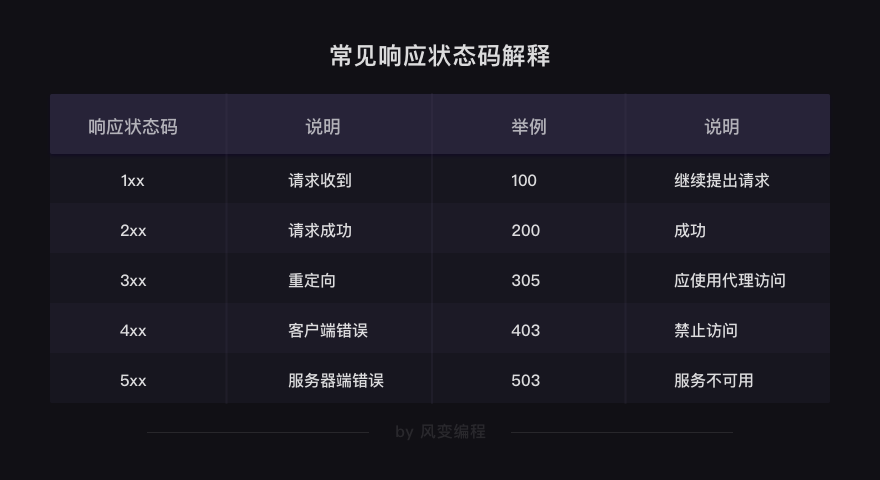

response.content
response.content能把Response对象的内容以二进制数据的形式返回,适用于图片、音频、视频的下载
import requests res = requests.get('https://res.pandateacher.com/2018-12-18-10-43-07.png') # 发出请求,并把返回的结果放在变量res中 pic = res.content # 把Reponse对象的内容以二进制数据的形式返回 photo = open('ppt.jpg', 'wb') # 新建了一个文件ppt.jpg,图片内容需要以二进制wb读写 photo.write(pic) # 获取pic的二进制内容 photo.close() # 关闭文件
response.text
response.text这个属性可以把Response对象的内容以字符串的形式返回,适用于文字、网页源代码的下载
下载《HTTP状态响应码》全部内容↓
import requests res = requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/exercise/HTTP%E5%93%8D%E5%BA%94%E7%8A%B6%E6%80%81%E7%A0%81.md') article = res.text # 把Response对象的内容以字符串的形式返回 with open('HTTP状态响应码.txt', 'w', encoding='utf-8') as f: f.write(article)
response.encoding
response.encoding能定义Response对象的编码,当遇上文本的乱码问题,会考虑用res.encoding把编码定义成和目标数据一致的类型
import requests res = requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md') # 定义Response对象的编码为utf-8 res.encoding = 'utf-8' # 如果写成res.encoding='gbk'就会打印出乱码 novel = res.text print(novel[:800]) # 考虑到整篇文章太长,只输出800字看看就好
6. 爬虫伦理
通常情况下,服务器不太会在意小爬虫,但是,服务器会拒绝频率很高的大型爬虫和恶意爬虫,因为这会给服务器带来极大的压力或伤害
不过,服务器在通常情况下,对搜索引擎是欢迎的态度(谷歌和百度的核心技术之一就是爬虫)。当然,这是有条件的,而这些条件会写在Robots协议
Robots协议是互联网爬虫的一项公认的道德规范,它的全称是“网络爬虫排除标准”(Robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以
如何查看网站的robots协议,在网站的域名后加上/robots.txt就可以了
下面截取了一部分淘宝的robots协议,可以看到淘宝对百度和谷歌这两个爬虫的访问规定,以及对其它爬虫的规定

协议里最常出现的英文是Allow和Disallow,Allow代表可以被访问,Disallow代表禁止被访问。而且有趣的是,淘宝限制了百度对产品页面的爬虫,却允许谷歌访问
所以,当你在百度搜索“淘宝网”时,会看到下图的这两行小字
因为百度很好地遵守了淘宝网的robots.txt协议,自然,你在百度中也查不到淘宝网的具体商品信息了
第1关 HTML基础
HTML(Hyper Text Markup Language)是用来描述网页的一种语言,也叫超文本标记语言
HTML文档就是前端工程师设计网页时使用的语言,浏览器会根据HTML文档的描述,解析出它所描述的网页
1. 查看网页的HTML代码
在网页任意地方点击鼠标右键,然后点击“显示网页源代码”
这样查看的好处是,整个网页的源代码都完整地呈现在面前。坏处是,在大部分情况下,它都会经过压缩,导致结构不够清晰,不太容易懂每行代码的含义。而且,源代码和网页分开在两个页面展示
所以更多时候,会用这样一种方法:在网页的空白处点击右键,然后选择“检查”
接着,会看到一个新的界面——开发者工具栏
上图中标亮的部分就是网页的HTML代码
将鼠标放在HTML源代码上,会发现,左边网页上有一些内容会被标亮。这其实就是这行代码所描述的网页内容,它们一左一右,相互对应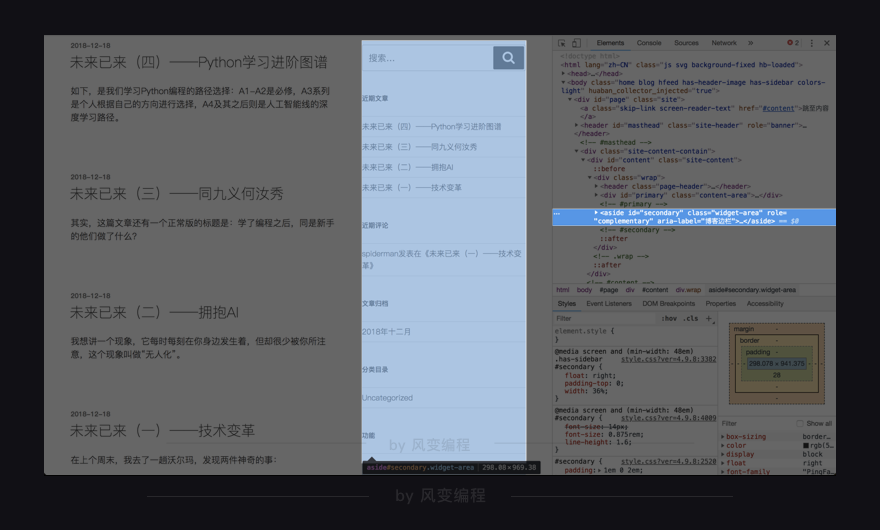
2. HTML的层级
再回到刚才网页,仔细看开发者工具栏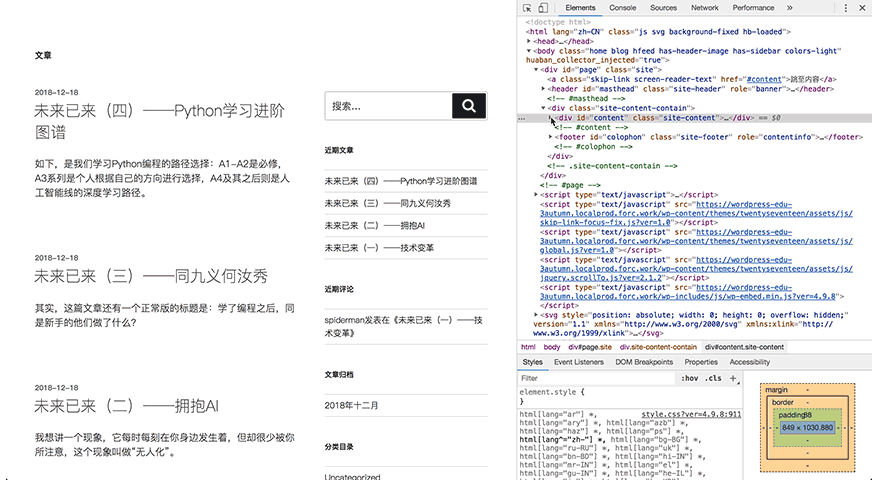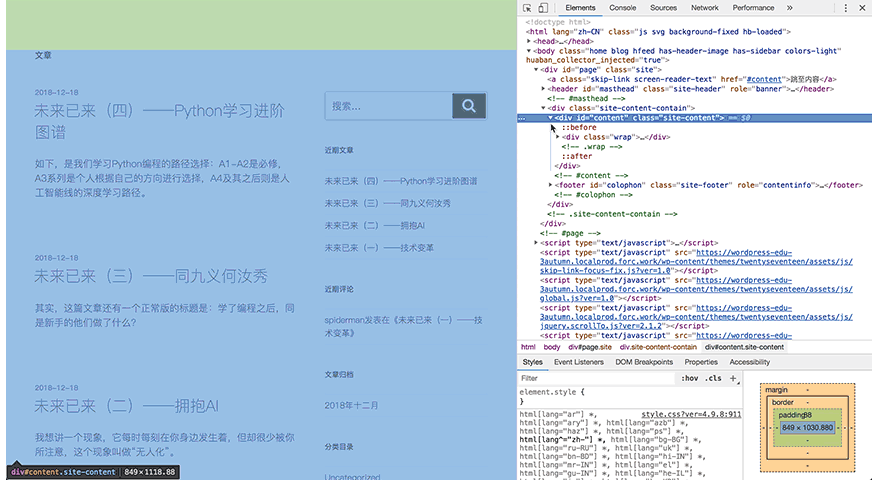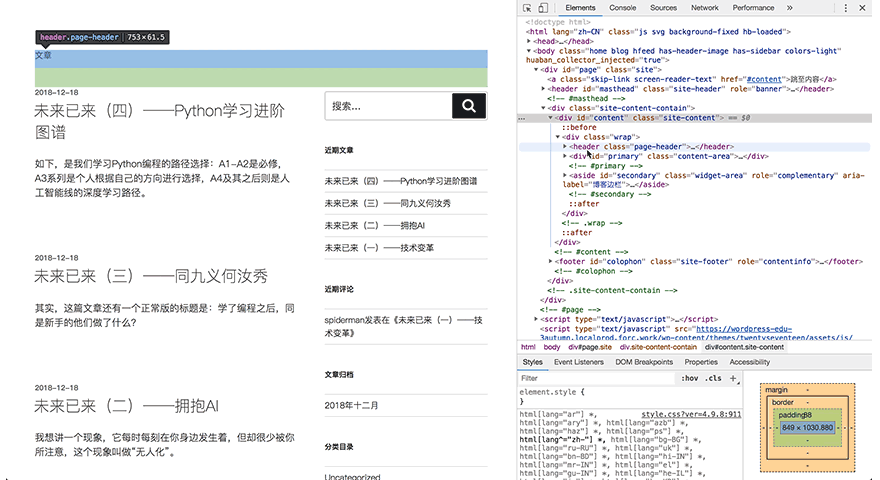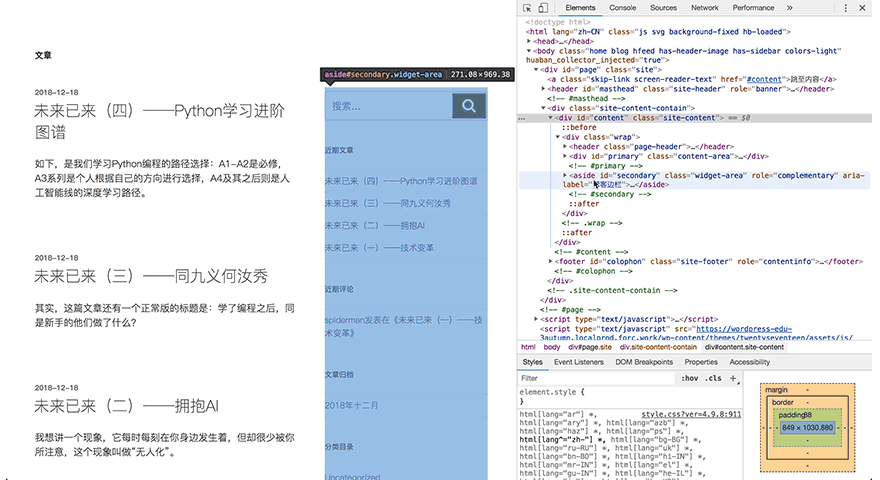
可以看到,HTML源代码中有一些小三角形,每一个三角形都可以展开或合上。尖角向下代表展开,向右代表合上了,这就是HTML的层级关系
3. 标签和元素
夹在尖括号<>中间的字母叫做【标签】
也有标签是形单影只地出现,比如<meta charset="utf-8">(定义网页编码格式为 utf-8)
开始标签+结束标签+中间的所有内容,它们在一起就组成了【元素】
下面的表格列出了几个常见元素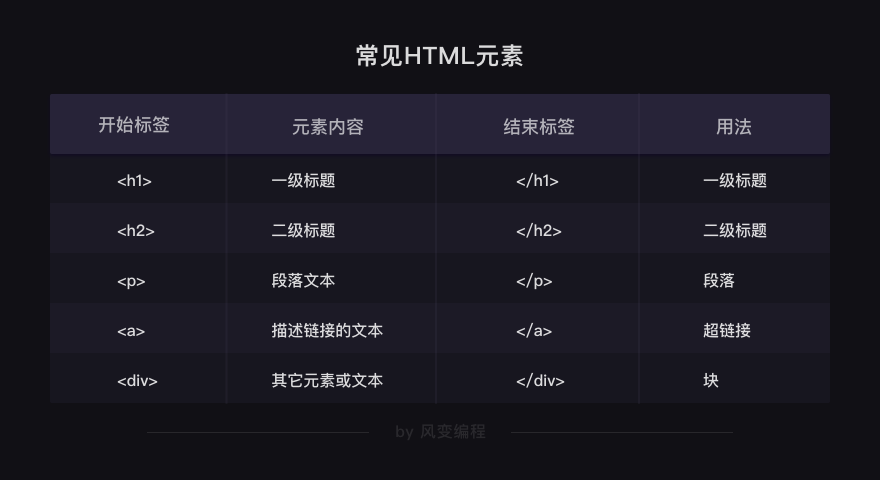
注意一下:HTML标签是可以嵌套标签的,而且可以多层嵌套
4. 网页头和网页体
HTML文档的基本是由【网页头】和【网页体】组成的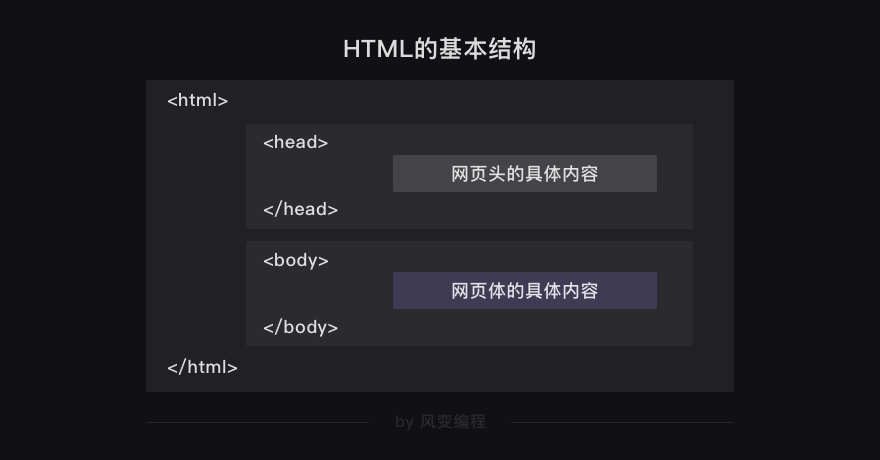
HTML文档的最外层标签一定是<html>,里面嵌套着<head>元素与<body>元素。<head>元素代表了【网页头】,<body>元素代表了【网页体】,这是最基本的网页结构
HTML文档和网页的内容一定是一一对应的。只是,【网页头】的内容不会被直接呈现在浏览器里的网页正文中,而【网页体】的内容是会直接显示在网页正文中的
<head>元素,【网页头】里面一般会有的内容↓
<head> <meta charset="utf-8"> <title>我是网页的名字</title> </head>
<meta charset="utf-8">定义了HTML文档的字符编码<title>元素用来定义网页的标题,这个标题就是显示在浏览器的标签页中的内容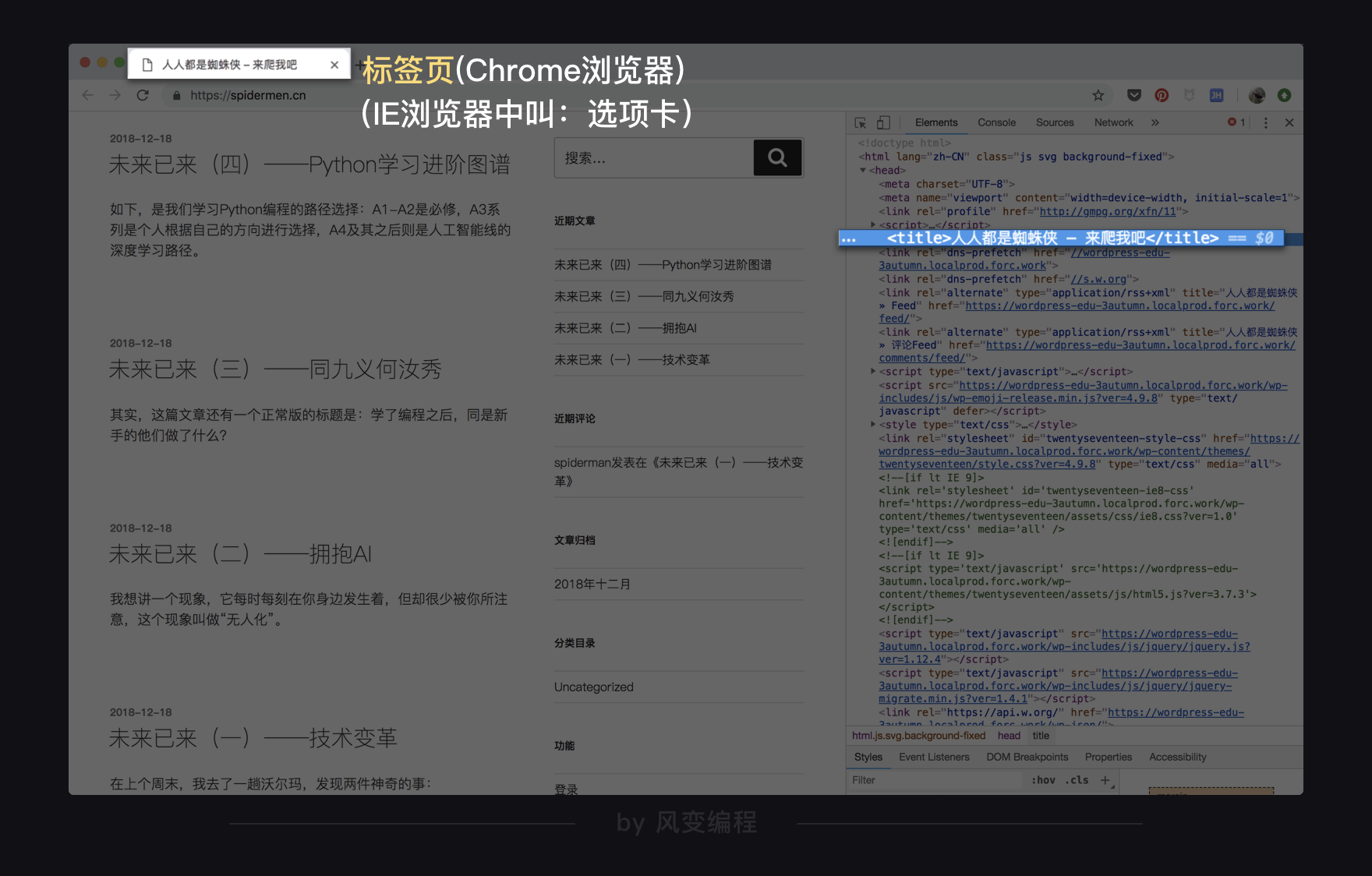
【网页头】中的编码是没办法在网页中直接被看到的,标签页的内容也不属于网页的正文
而<body>元素中,即【网页体】,就是那些能看到的显示在网页中的内容了
<html> <head> <meta charset="utf-8"> <title>豆瓣2019年度电影榜单1.0</title> </head> <body> <h1>豆瓣2019年度电影榜单</h1> <h3>评分最高华语电影</h3> <h2>《少年的你》</h2> <p>根据玖月晞小说改编的电影,由曾国祥执导,周冬雨、易烊千玺领衔主演。该片讲述在高考前夕,被一场校园意外改变命运的两个少年,如何守护彼此成为想成为的成年人的故事</p> </body> </html>

网页体中依次有四个内容:<h1>元素代表一级标题,对应网页中的“豆瓣2019年度电影榜单”;<h3>元素代表三级标题,对应网页中的“评分最高华语电影”;<h2>元素代表二级标题,对应网页中的“《少年的你》”;然后是<p>元素,对应网页中“根据玖月晞小说......的故事”这一整段文本
5. 属性
HTML标签可以通过设置【属性】来为HTML元素描述更多的信息

<html> <head> <meta charset="utf-8"> <title>豆瓣2019年度电影榜单2.0</title> <style> /*以下是.film的具体样式规定*/ .film { float: left; /*控制元素浮动*/ margin: 5px; /*外边距为5像素*/ padding: 15px; /*内边距为15像素*/ width: 350px; /*宽度为350像素*/ height: 240px; /*高度为240像素*/ border: 3px solid #20b2aa; /*边框为3像素*/ } </style> </head> <body> <h1 style="color:#20b2aa;">豆瓣2019年度电影榜单</h1> <h3>评分最高华语电影</h3> <div class="film"> <h2><a href="https://movie.douban.com/subject/30166972/" target="_blank">《少年的你》</a></h2> <p>根据玖月晞小说改编的电影,由曾国祥执导,周冬雨、易烊千玺领衔主演。该片讲述在高考前夕,被一场校园意外改变命运的两个少年,如何守护彼此成为想成为的成年人的故事</p> </div> <div class="film"> <h2><a href="https://movie.douban.com/subject/27119586/" target="_blank">《谁先爱上他的》</a></h2> <p>由徐誉庭、许智彦联合执导,邱泽、谢盈萱、陈如山、黄圣球主演的剧情片。该片讲述了刘三莲为了夺回丈夫宋正远的保险理赔金,与丈夫的同性情人阿杰对抗的故事</p> </div> <div class="film"> <h2><a href="https://movie.douban.com/subject/27191431/" target="_blank">《过春天》</a></h2> <p>由白雪执导,田壮壮监制的剧情电影,由黄尧、孙阳、汤加文、倪虹洁主演。该片讲述了十六岁少女佩佩为完成和闺蜜一起去日本看雪的约定,从而冒险走上水客道路的独特经历</p> </div> </body> </html>

<h1>元素添加了一个style属性,属性中的内容规定了这行文字的颜色。style属性可以用来定义网页文本的样式,比如字体大小、颜色、间距、对齐方式等等
电影名称增加了链接,点击可以打开电影的详情页面。链接一般由<a>标签定义,href属性用于规定指向页面的URL
网页头中多了一个很长的<style>元素,/*控制元素浮动*/是对代码的注释
<style>元素的内容,是一段对网页布局的描述,在大括号内部写的就是一条条的样式规定
其实.对应class,所以.film这段内容对应的是网页体块级元素<div>中的属性class="film"
在HTML中,class属性可以被多次利用,<div class="film"> 在代码中出现了三次,与此对应,网页中也有三个一样的块
网页头的<style>元素中定义了.film的样式,因此,凡是class="film"的元素都会继承它的样式id属性和class属性的用法类似,给元素定义id和class的目的都是为了查找、定位元素,或者为元素设置样式
但id属性用于标识唯一的元素,而class用于标识一系列的元素。id就像是学生的学生证号码,每个人都是唯一的;而学生们可以属于同一个班级,班级就像class
最常用的几个HTML属性↓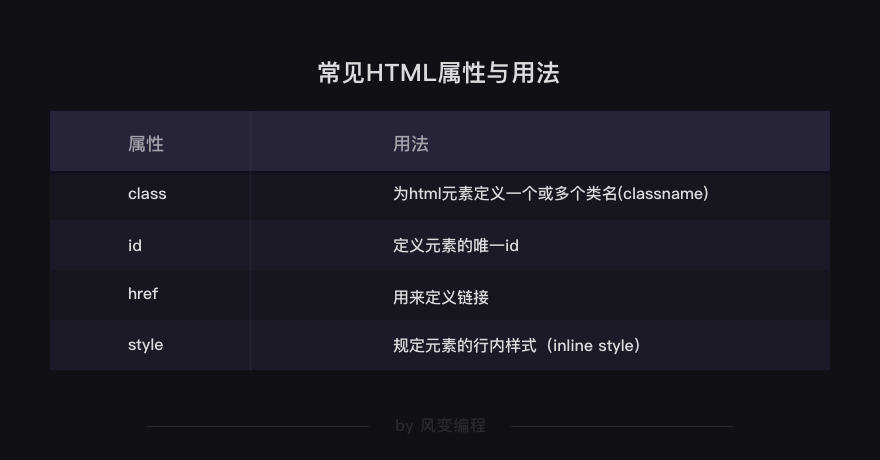
6. 读懂HTML
以【这个书苑不太冷5.0】为例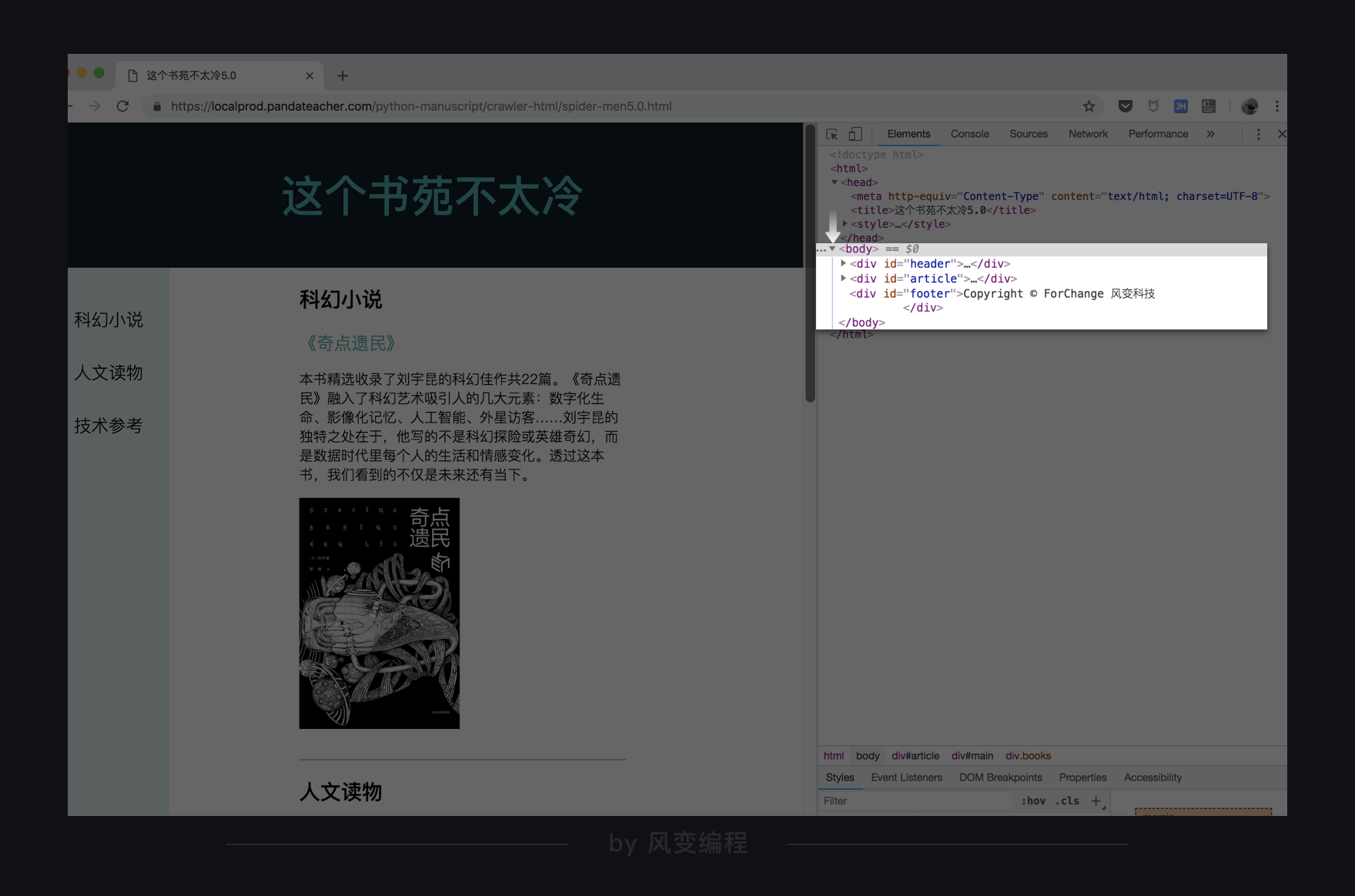
网页体有三大部分,<div id="header">,<div id="article">,和<div id="footer">,对应的是网页布局中的三部分↓
点开HTML的<div id="article">元素
包含了两个<div>元素,<div id="nav">和<div id="main">分别对应着网页中间的左边栏和正文部分
在<div id="main">中,又包含了三个<div>元素,它们都有同样的属性:<class="books">,每个<div>元素分别介绍了一本书的内容
点击导航栏的“科幻小说”、“人文读物”、“技术参考”会分别跳转到正文的对应部分,这是通过超链接和锚点实现的
<div id="article"> <div id="nav"> <a href="#type1" class="catlog">科幻小说</a><br> <a href="#type2" class="catlog">人文读物</a><br> <a href="#type3" class="catlog">技术参考</a><br> </div> <div id="main"> <div class="books">... </div> <div class="books"> <h2><a name="type2">人文读物</a></h2> <a href="https://book.douban.com/subject/26943161/" class="title">《未来简史》</a> <p class="info">未来,人类将面临着三大问题:生物本身就是算法,生命是不断处理数据的过程;意识与智能的分离;拥有大数据积累的外部环境将比我们自己更了解自己。如何看待这三大问题,以及如何采取应对措施,将直接影响着人类未来的发展。</p> <img class="img" src="./spider-men5.0_files/s29287103.jpg"> <br/> <br/> <hr size="1"> </div> <div class="books">... </div> </div> </div>
<div id="nav">中的超链接<a href="#type2">以每个<div class="books">中name属性<a name="type2">为标识,设置了跳转到这个标题的锚点<img>标签添加了书的封面图片
7. 修改网页
打开【这个书苑不太冷5.0】,能看到开发者工具的左上角,有一个图标↓
点击它,然后再把鼠标放在网页中,会发现和点击源代码的情景恰恰相反,当鼠标放在网页上,右边代码区中描述它的代码会被标亮出来
可以在网页的开发者工具这里修改HTML文件,把鼠标点上去,双击,就和修改word文档一样↓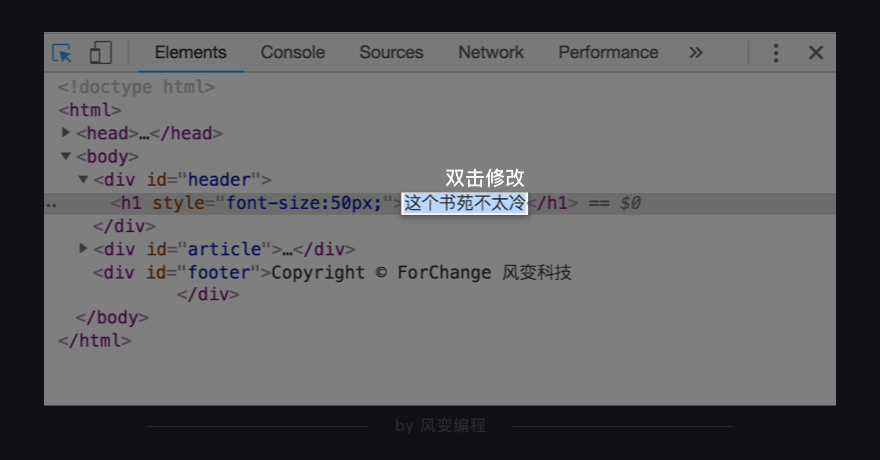
改完之后,按下enter确认,网页就变成了刚才修改后的样子
当然,这样的修改只是在本地的修改,而服务器上的源文件是修改不了的,但可以使用这个方法,在开发者工具这里,调试HTML代码
8. 通过Python将网页下载到本地
import requests with open('spider5.html', 'w', encoding='utf-8') as f: # 将下载的网页源代码写入文件 f.write(requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html').text)
第2关 BeautifulSoup
本关学习目标:使用BeautifulSoup解析和提取网页中的数据
我们平时使用浏览器上网,浏览器会把服务器返回来的HTML源代码翻译为我们能看懂的样子,之后我们才能在网页上做各种操作
而在爬虫中,也要使用能读懂html的工具,才能提取到想要的数据,这就是【解析数据】
【提取数据】是指把需要的数据从众多数据中挑选出来
由于BeautifulSoup不是Python标准库,需要单独安装它,在终端输入pip3 install BeautifulSoup4
1. 解析数据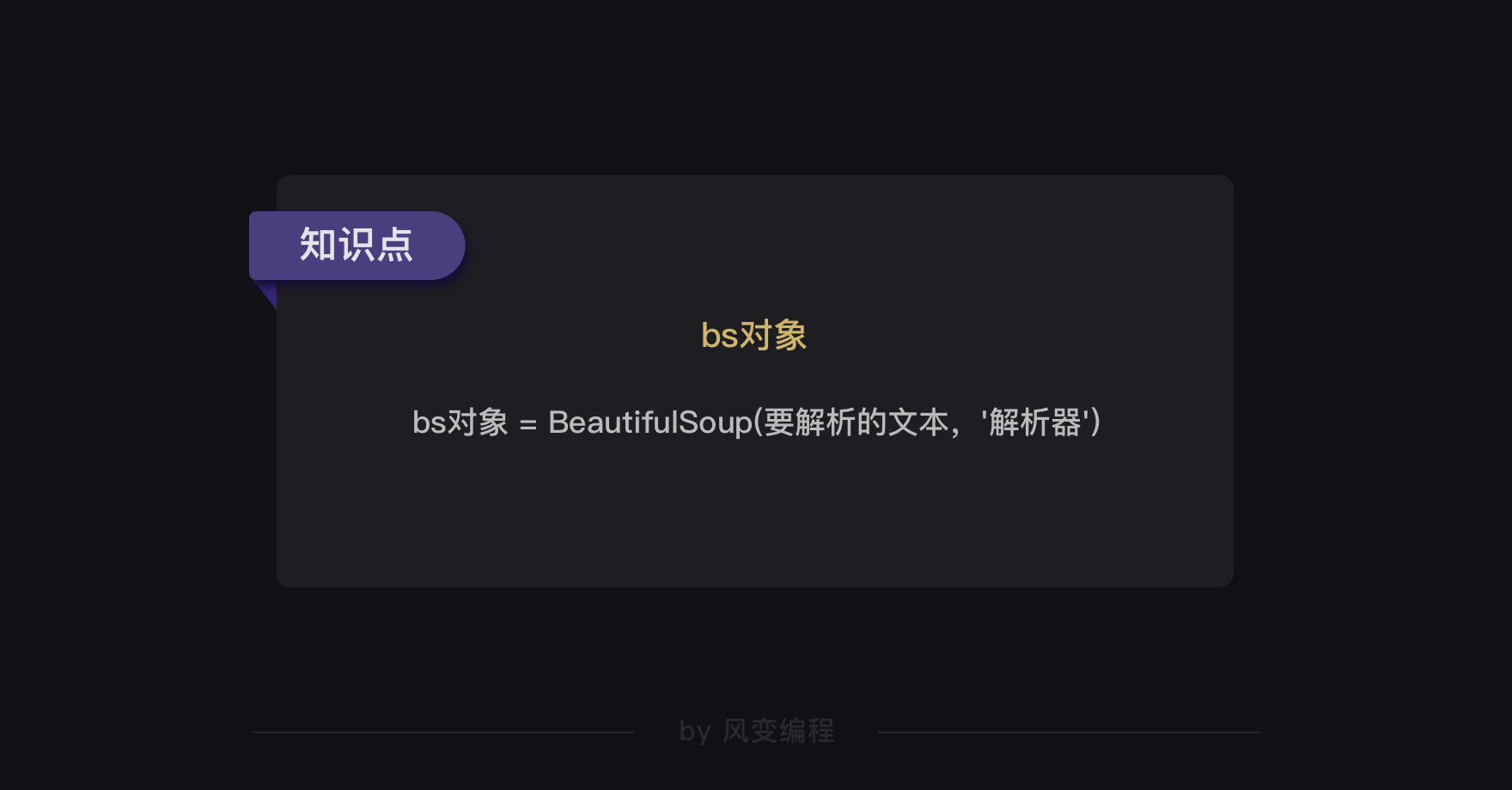
在括号中,要输入两个参数,第0个参数是要被解析的文本,注意了,它必须必须必须是字符串
括号中的第1个参数用来标识解析器,用的是一个Python内置库:html.parser(它不是唯一的解析器,但是比较简单的)
import requests from bs4 import BeautifulSoup # 引入BS库 res = requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') soup = BeautifulSoup(res.text, 'html.parser') # 把网页解析为BeautifulSoup对象 print(type(soup)) # 查看soup的类型 # 》》<class 'bs4.BeautifulSoup'> print(soup) # 打印soup
soup的数据类型是<class 'bs4.BeautifulSoup'>,说明soup是一个BeautifulSoup对象
打印的soup,是所请求网页的完整HTML源代码
虽然response.text和soup打印出的内容表面上看长得一模一样,却有着不同的内心,它们属于不同的类:<class 'str'> 与<class 'bs4.BeautifulSoup'>。前者是字符串,后者是已经被解析过的BeautifulSoup对象。之所以打印出来的是一样的文本,是因为BeautifulSoup对象在直接打印它的时候会调用该对象内的str方法,所以直接打印 bs 对象显示字符串是str的返回结果
现在完成了第1步,使用BeautifulSoup去解析数据↓
from bs4 import BeautifulSoup soup = BeautifulSoup(字符串,'html.parser')
2. 提取数据
find()与find_all()是BeautifulSoup对象的两个方法,它们可以匹配html的标签和属性,把BeautifulSoup对象里符合要求的数据都提取出来
它俩的用法基本是一样的,区别在于,find()只提取首个满足要求的数据,而find_all()提取出的是所有满足要求的数据
示例中括号里的class_,这里有一个下划线,是为了和python语法中的类class区分,避免程序冲突。当然,除了用class属性去匹配,还可以使用其它属性,比如style属性等
括号中的参数:标签和属性可以任选其一,也可以两个一起使用,这取决于要在网页中提取的内容
以这个网页为例(URL: https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html)↓
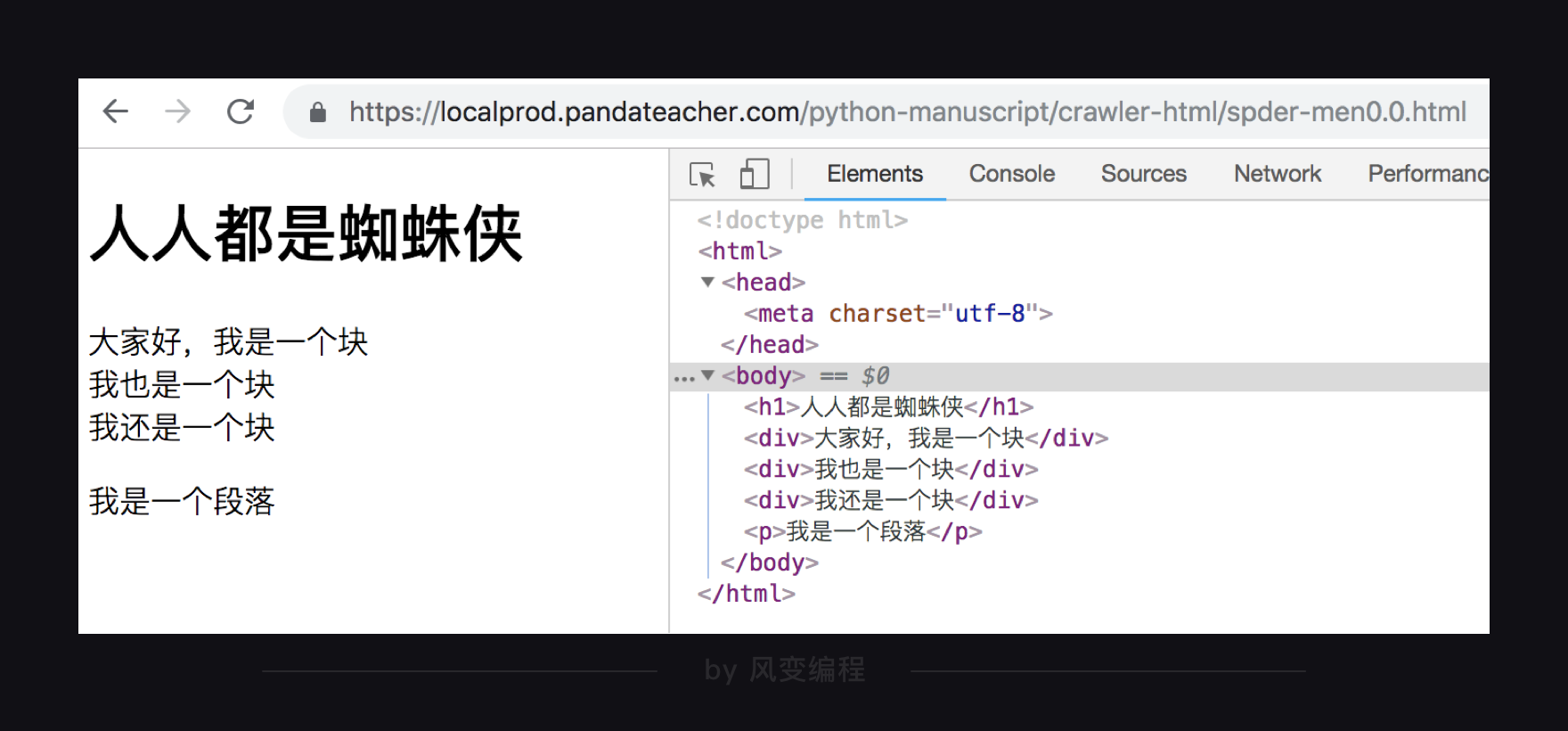
在网页的HTML代码中,有三个<div>元素,用find()可以提取出首个元素,而find_all()可以提取出全部
import requests from bs4 import BeautifulSoup res = requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html') soup = BeautifulSoup(res.text, 'html.parser') item = soup.find('div') # 使用find()方法提取首个<div>元素,并放到变量item里 print(type(item)) # 打印item的数据类型 # 》》<class 'bs4.element.Tag'> print(item) # 打印item # 》》<div>大家好,我是一个块</div> items = soup.find_all('div') # 用find_all()把所有符合要求的数据提取出来,并放在变量items里 print(type(items)) # 打印items的数据类型 # 》》<class 'bs4.element.ResultSet'> print(items) # 打印items # 》》[<div>大家好,我是一个块</div>, <div>我也是一个块</div>, <div>我还是一个块</div>] print(type(items[0])) # 打印items的第一个元素的数据类型 # 》》<class 'bs4.element.Tag'>
item的数据类型显示的是<class 'bs4.element.Tag'>,说明这是一个Tag类对象
items的数据类型显示的是<class 'bs4.element.ResultSet'>,是一个ResultSet类的对象。其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
items[0]的数据类型显示的是<class 'bs4.element.Tag'>,,是Tag对象,这与find()提取出的数据类型是一样的
以爬取【这个书苑不太冷5.0】中的三本书的书名、链接、和书籍介绍为例
import requests # 调用requests库 from bs4 import BeautifulSoup # 调用BeautifulSoup库 # 返回一个response对象,赋值给res res = requests.get( 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') html = res.text # 把res解析为字符串 soup = BeautifulSoup(html, 'html.parser') # 把网页解析为BeautifulSoup对象 items = soup.find_all(class_='books') # 通过匹配属性class='books'提取出想要的数据 for item in items: # 遍历列表items kind = item.find('h2') # 在列表中的每个元素里,匹配标签<h2>提取出数据 title = item.find(class_='title') # 在列表中的每个元素里,匹配属性class_='title'提取出数据 brief = item.find(class_='info') # 在列表中的每个元素里,匹配属性class_='info'提取出数据 print(type(kind), type(title), type(brief)) # 打印提取出的数据类型 print(kind.text, ' ', title.text, ' ', title['href'], ' ', brief.text) # 打印书籍的类型、名字、链接和简介的文字
打印的kind、titile、brief的数据类型,又是<class 'bs4.element.Tag'>,用find()提取出来的数据类型和刚才一样,还是Tag对象
然后用Tag.text提出Tag对象中的文字(Tag.get_text()也可以),用Tag['href']提取出URL
3. 对象的变化过程
从最开始用requests库获取数据,到用BeautifulSoup库来解析数据,再继续用BeautifulSoup库提取数据,不断经历的是操作对象的类型转换↓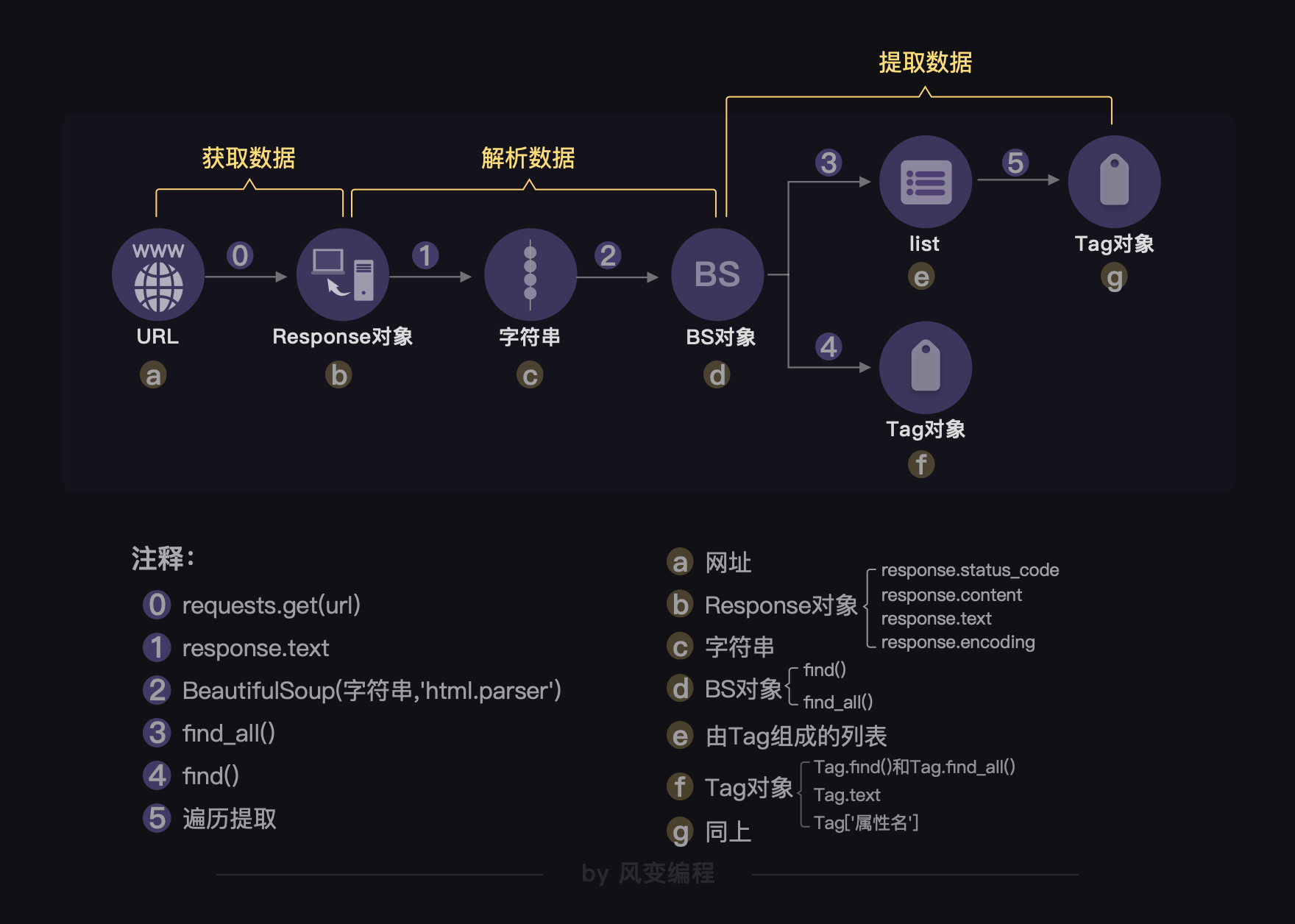
在BeautifulSoup中,不止find()和find_all(),还有select()也可以达到相同目的
在bs的官方文档中,find()与find_all()的方法,其实不止标签和属性两种,还有这些↓
使用str.strip()去除特殊字符串,可以使打印结果整洁很多
第3关 BeautifulSoup实践
text获取到的是该标签内的纯文本信息,即便是在它的子标签内,也能拿得到。但提取属性的值,只能提取该标签本身的
在爬豆瓣的时候遇到status_code为418的情况,解决办法是在request.get()时加个头
安装fake-useragent模块,在终端输入pip3 install fake-useragent
import requests from fake_useragent import UserAgent ua = UserAgent() # 实例化 headers = {'User-Agent': ua.random} # 也可以是ua.ie,ua.chrome,ua.safari等 res = requests.get(url, headers=headers)
from urllib.request import quote, unquote # quote()函数,可以把内容转为标准的url格式,作为网址的一部分打开 print(quote('海边的卡夫卡')) # 》》E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1 # unquote()函数,可以转换回编码前数据 print(unquote('%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1')) # 》》海边的卡夫卡
也可以↓
import urllib.parse a = urllib.parse.quote('海边的卡夫卡') # 转为url编码 print(a) # 》》%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1 b = urllib.parse.unquote('%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1') # 转为编码前数据 print(b) # 》》海边的卡夫卡
第4关 json
目标是从QQ音乐获取周杰伦的歌曲信息,也就是这个页面https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=周杰伦
但requests.get()这个网址获取到的html里面却没有歌曲信息
1. Network
Network的功能是:记录在当前页面上发生的所有请求。由于Network记录的是实时网络请求,现在网页都已经加载完成,所以不会有东西
点击一下刷新,浏览器会重新访问网络,这样就会有记录↓
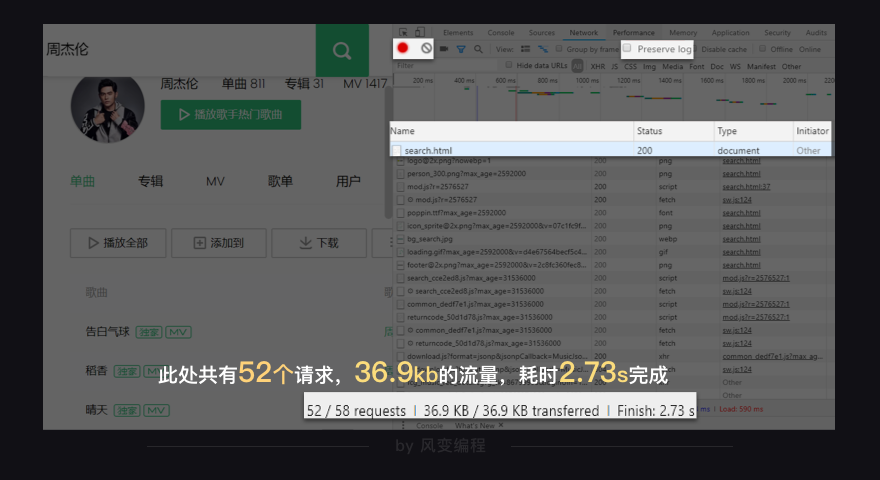
浏览器总是在向服务器,发起各式各样的请求,当这些请求完成,它们会一起组成在Elements中看到的网页源代码
刚才的requests.get()只是模拟了这52个请求中的一个,第0个请求:search.html,查看它的Response↓
它就是刚刚用requests.get()获取到的网页源代码,里面不包含歌曲清单
一般来说,都是这种第0个请求先启动了,其他的请求才会关联启动,一点点地将网页给填充起来
当然,也有一些网页,直接把所有的关键信息都放在第0个请求里,尤其是一些比较老(或比较轻量)的网站,用requests和BeautifulSoup就能解决它们,比如豆瓣
为了成功抓取到歌曲清单,得先找到歌名藏在哪一个请求当中,再用requests库,去模拟这个请求
从上往下,只看圈起来的内容的话,它有四行信息
第0行的左侧,红色的圆钮是启用Network监控(默认高亮打开),灰色圆圈是清空面板上的信息。右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,在爬取一些会发生跳转的网页时,会点亮它
第1行,是对请求进行分类查看。最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门做这个,便不需要了解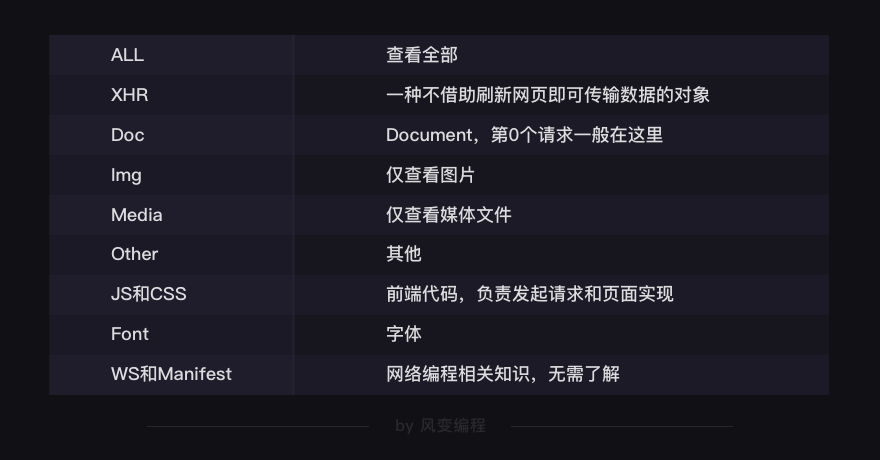
夹在第2行和第1行中间的,是一个时间轴,记录什么时间,有哪些请求。而第2行,就是各个请求
在第3行,是个统计:有多少个请求,一共多大,花了多长时间
2. XHR
在Network中,有一类非常重要的请求叫做XHR(当把鼠标在XHR上悬停,可以看到它的完整表述是XHR and Fetch)
平时使用浏览器上网的时候,经常有这样的情况:浏览器上方,它所访问的网址没变,但是网页里却新加了内容
典型代表:如购物网站,下滑自动加载出更多商品。在线翻译网站,输入中文实时变英文
这个,叫做Ajax技术,应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页,又省流量又省时间
如今,比较新潮的网站都在使用这种技术来实现数据传输。只剩下一些特别老,或是特别轻量的网站,还在用老办法——加载新的内容,必须要跳转一个新网址
这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间传输数据。在这里,XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的
点击XHR按钮,可以看到这个网页里一共有10个XHR或Fetch,想从里面找出带有歌单的那一个,可以从观察名字和大小入手,于是看到了client_search_cp..,它最大,有10.9KB
点击Preview,能在里面发现想要的信息:歌名就藏在里面(只是有点难找,需要一层一层展开:data-song-list-0-name)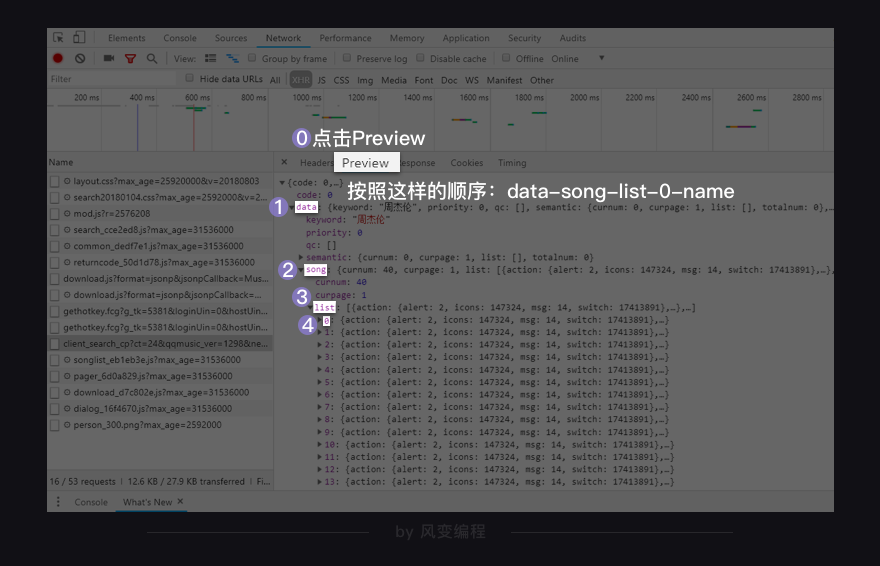
这个XHR是一个字典,键data对应的值也是一个字典;在该字典里,键song对应的值也是一个字典;在该字典里,键list对应的值是一个列表;在该列表里,一共有20个元素;每一个元素都是一个字典;在每个字典里,键name的值,对应的是歌曲名
那如何把这些歌曲名拿到呢?这就需要去看看最左侧的Headers↓
它被分为四个板块,点开第0个General,会看到Requests URL就是应该去访问的链接
3. json
用requests.get()这个链接可以得到response对象,想把response对象转成列表/字典则需要用json
在Python语言当中,json是一种特殊的字符串,这种字符串特殊在它的写法——它是用列表/字典的语法写成的
a = '1,2,3,4' # 这是字符串 b = [1, 2, 3, 4] # 这是列表 c = '[1,2,3,4]' # 这是字符串,但它是用json格式写的字符串
这种特殊的写法决定了,json能够有组织地存储信息
一般来说,这三条占得越多,数据的结构越清晰;占得越少,数据的结构越混沌
html通过标签、属性来实现分层和对应,json则是另一种组织数据的格式,长得和Python中的列表/字典非常相像。它和html一样,常用来做网络数据传输。刚刚在XHR里查看到的列表/字典,严格来说其实它不是列表/字典,它是json
为什么不直接写成列表/字典,非要把它表示成字符串?因为不是所有的编程语言都能读懂Python里的数据类型,但是所有的编程语言,都支持文本(比如在Python中,用字符串这种数据类型来表示文本)这种最朴素的数据类型
如此,json数据才能实现,跨平台,跨语言工作
而json和XHR之间的关系:XHR用于传输数据,它能传输很多种数据,json是被传输的一种数据格式,就是这样而已
Requests中有一个内置的json解码器,帮助处理json数据
import requests # 引用requests库 res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0') # 调用get方法,下载这个字典 json_music = res_music.json() # 使用json()方法,将response对象,转为列表/字典 print(type(json_music)) # 打印json_music的数据类型 # 》》<class 'dict'>
拿到前20个歌曲信息的完整代码↓
import requests # 引用requests库 res_music = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=60997426243444153&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=20&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0') # 调用get方法,下载这个字典 json_music = res_music.json() # 使用json()方法,将response对象,转为列表/字典 list_music = json_music['data']['song']['list'] # 一层一层地取字典,获取歌单列表 for music in list_music: # list_music是一个列表,music是它里面的元素 print(music['name']) # 以name为键,查找歌曲名 print('所属专辑:'+music['album']['name']) # 查找专辑名 print('播放时长:'+str(music['interval'])+'秒') # 查找播放时长 print('播放链接:https://y.qq.com/n/yqq/song/' + music['mid']+'.html ') # 查找播放链接
在Python语言中,实现列表/字典转json,json转列表/字典,需要借助json模块,官方文档地址:https://docs.python.org/3/library/json.html
import json # 引入json模块 a = [1, 2, 3, 4] # 创建一个列表a b = json.dumps(a) # 使用dumps()函数,将列表a转换为json格式的字符串,赋值给b print(b) # 打印b # 》》[1, 2, 3, 4] print(type(b)) # 打印b的数据类型 # 》》<class 'str'> c = json.loads(b) # 使用loads()函数,将json格式的字符串b转为列表,赋值给c print(c) # 打印c # 》》[1, 2, 3, 4] print(type(c)) # 打印c的数据类型 # 》》<class 'list'> # 想输出真正的中文需要指定ensure_ascii=False print(json.dumps(['你', '我', '她'])) # 》》["u4f60", "u6211", "u5979"] print(json.dumps(['你', '我', '她'], ensure_ascii=False)) # 》》["你", "我", "她"]
第5关 带参数请求数据
快速查找XHR的方法:先把Network面板清空,再点击一下点击加载更多,看看有没有多出来的新XHR,多出来的那一个,就应该是要找的了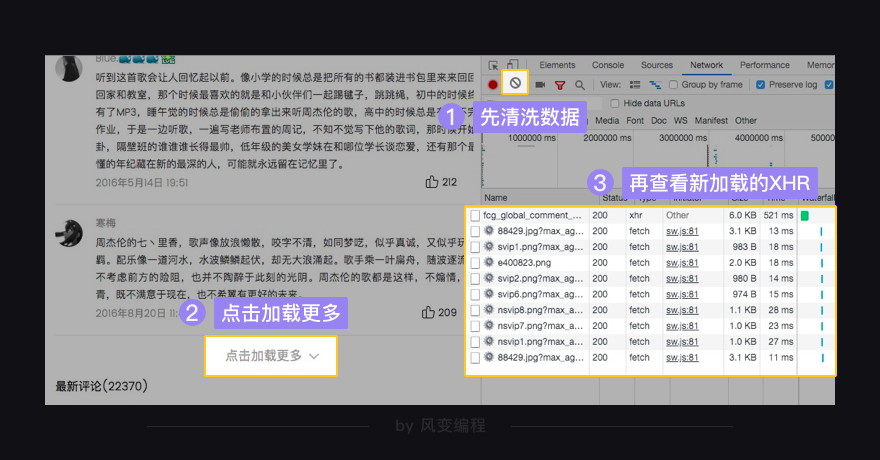
总结一下↓
1. params
上一关只爬取了周杰伦20首歌曲信息,本关目标是爬取更多的歌曲信息,但是qq音乐却显示:查看更多内容,请下载客户端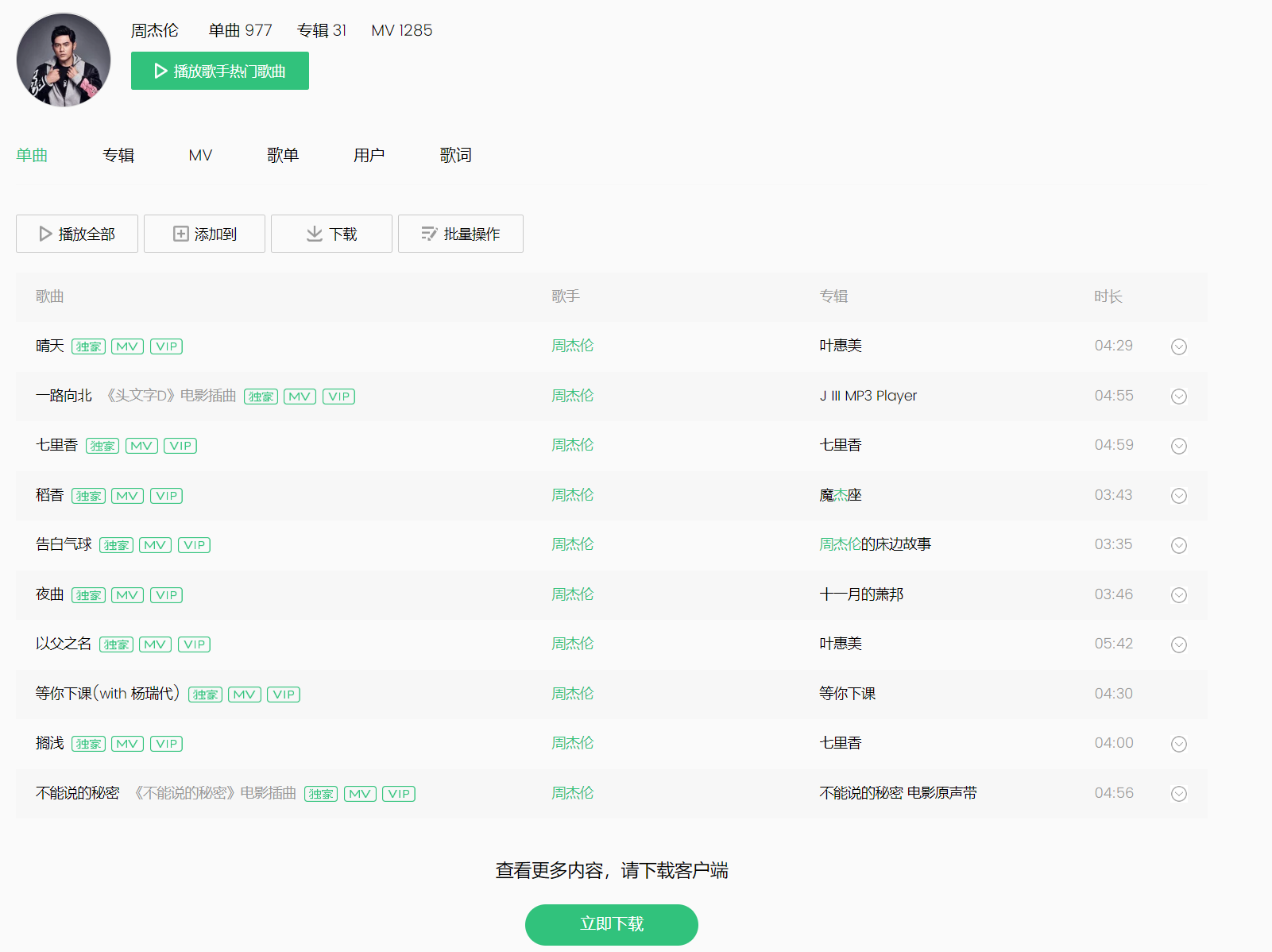
看下这个页面的链接:https://y.qq.com/portal/search.html#page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=周杰伦
这个链接的前半部分是https://y.qq.com/portal/search.html,是所请求的地址,它告诉服务器,我想访问这里;后半部分是page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=周杰伦,是请求所附带的参数,它会告诉服务器想要什么样的数据,这参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接;分隔这两部分的符号是#,#和?的功能是一样的,作用都是分隔,若把链接的#替换成?,访问的效果是一样的(注意:用?分隔的url不一定可以用#代替)
观察一下后半部分的参数page=1&searchid=1&remoteplace=txt.yqq.top&t=song&w=周杰伦,page(中文:页面),searchid(中文:搜索id),remoteplace(中文:远程位置),后面的t和w这俩参数虽然不知道是什么,但根据他们的值(song和周杰伦)可窥得一斑,应该是指类型和关键字
将网页链接中的page=1改成page=2是可以访问到下一页的数据的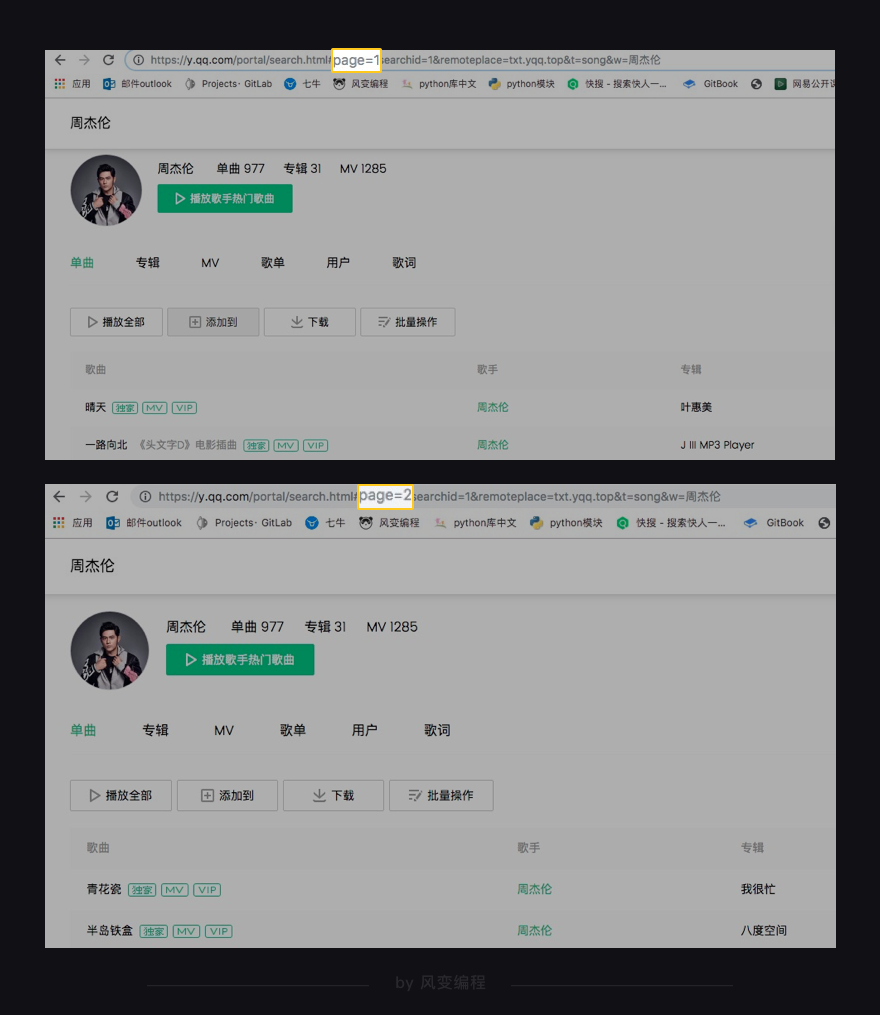
用快速查找XHR的方法,1️⃣先把Network面板清空,2️⃣再修改page值按回车键,3️⃣查看Network多出来的新XHR,也是个client_search_cp..,在这个请求的Preview中能找到歌曲信息
在Headers的General中能看到Request URL,但这样一个长链接阅读体验非常之差,Network面板提供了一个更友好的查看方式
点开Headers的第3个板块Query String Parameters,它里面的内容正是链接请求中所附带的参数,Query String Parameters,它的中文翻译是:查询字符串参数
这个面板用类似字典的形式,呈现了各个参数的键值,阅读体验会好一些
比较网页链接page=1到page=3的XHR的Query String Parameters↓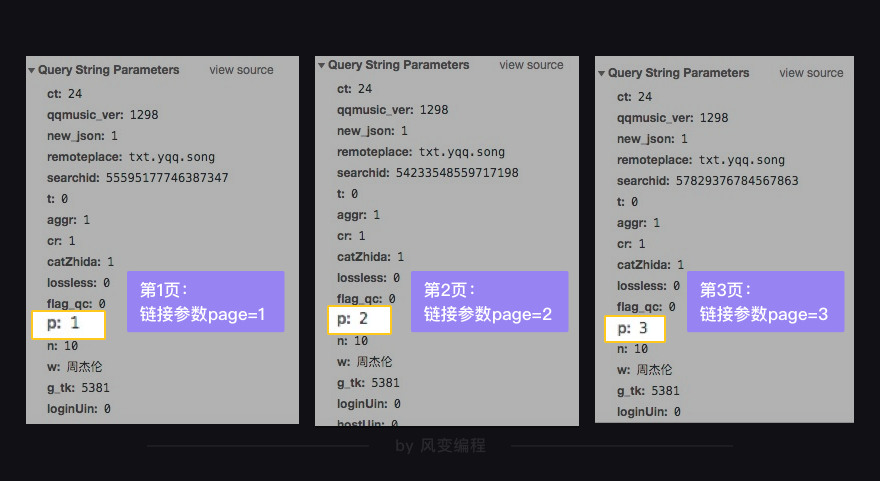
可以看到变化的是这个p参数,第1页XHR的参数p值为1,第2、3页XHR的参数p值则为2和3,说明在这个client_search_cp..的请求中,代表页码的参数是p(page的缩写)
通过循环变更链接中的p参数就可以拿到更多歌曲信息,但这样的代码不够优雅
事实上,requests模块里的requests.get()提供了一个参数叫params,可以用字典的形式,把参数传进去
所以可以把Query String Parameters里的内容,直接复制下来,封装为一个字典,传递给params。只是有一点要特别注意:要给他们打引号,让它们变字符串
import requests # 引用requests模块 url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp' for x in range(5): params = { 'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'sizer.yqq.song_next', 'searchid': '64405487069162918', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': str(x+1), 'n': '20', 'w': '周杰伦', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0' } # 将参数封装为字典 res_music = requests.get(url, params=params) # 调用get方法,下载这个字典 json_music = res_music.json() # 使用json()方法,将response对象,转为列表/字典 list_music = json_music['data']['song']['list'] # 一层一层地取字典,获取歌单列表 for music in list_music: # list_music是一个列表,music是它里面的元素 print(music['name']) # 以name为键,查找歌曲名 print('所属专辑:'+music['album']['name']) # 查找专辑名 print('播放时长:'+str(music['interval'])+'秒') # 查找播放时长 print('播放链接:https://y.qq.com/n/yqq/song/'+music['mid']+'.html ') # 查找播放链接
2. headers
每一个请求,都会有一个Requests Headers,称作请求头,Headers的第2个板块,它里面会有一些关于该请求的基本信息,比如:这个请求是从什么设备什么浏览器上发出?这个请求是从哪个页面跳转而来?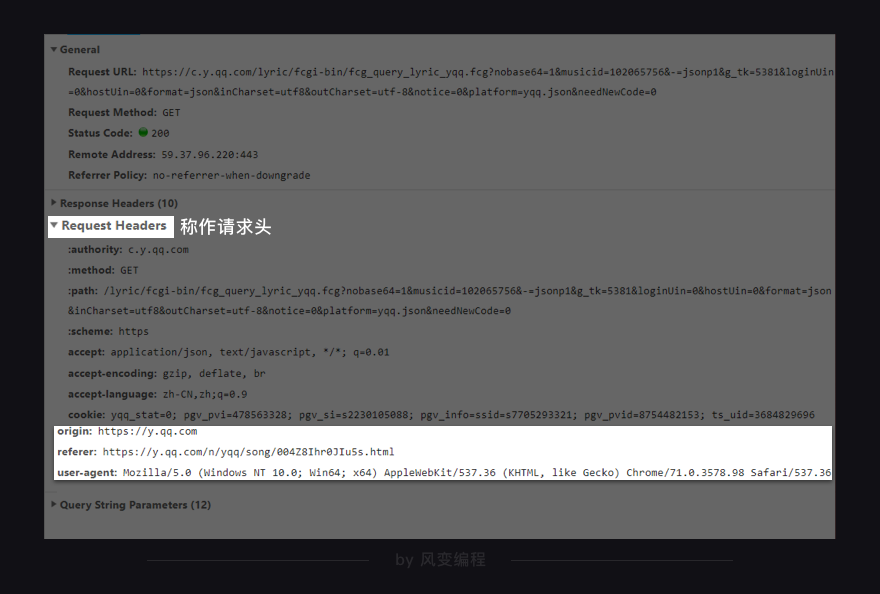
user-agent(中文:用户代理)会记录电脑的信息和浏览器版本origin(中文:源头)和referer(中文:引用来源)则记录了这个请求,最初的起源是来自哪个页面。它们的区别是referer会比origin携带的信息更多些
如果想告知服务器,我们不是爬虫是一个正常的浏览器,就要去修改user-agent。倘若不修改,那么这里的默认值就会是Python,会被浏览器认出来
而对于爬取某些特定信息,也要求注明请求的来源,即origin或referer的内容
requests模块允许修改headers的值,只需要封装一个字典就好了,和写params非常相像
import requests url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp' headers = { 'origin':'https://y.qq.com', # 请求来源,本案例中其实是不需要加这个参数的,只是为了演示 'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html', # 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', # 标记了请求从什么设备,什么浏览器上发出 } # 伪装请求头 params = { 'ct':'24', 'qqmusic_ver': '1298', 'new_json':'1', 'remoteplace':'sizer.yqq.song_next', 'searchid':'64405487069162918', 't':'0', 'aggr':'1', 'cr':'1', 'catZhida':'1', 'lossless':'0', 'flag_qc':'0', 'p':1, 'n':'20', 'w':'周杰伦', 'g_tk':'5381', 'loginUin':'0', 'hostUin':'0', 'format':'json', 'inCharset':'utf8', 'outCharset':'utf-8', 'notice':'0', 'platform':'yqq.json', 'needNewCode':'0' } # 将参数封装为字典 res_music = requests.get(url,headers=headers,params=params) # 发起请求,填入请求头和参数
a = '你\n好\n么\n' b = a.replace('\n', ' ') print(a) # 》》你 好 么 print(b) # 》》你 # 》》好 # 》》么
replace()是字符串对象的一个方法,它的意思是,把第一个参数的字符串用第二个参数的字符串替代
第6关 csv&excel
常用的存储数据的方式有两种——存储成csv格式文件、存储成Excel文件
csv是一种字符串文件的格式,它组织数据的语法就是在字符串之间加分隔符——行与行之间是加换行符,同行字符之间是加逗号分隔
它可以用任意的文本编辑器打开(如记事本),也可以用Excel打开,还可以通过Excel把文件另存为csv格式(因为Excel支持csv格式文件)
file = open('test.csv', 'a+') # 创建test.csv文件,以追加的读写模式 file.write('美国队长,钢铁侠,蜘蛛侠') # 写入test.csv文件 file.close() # 关闭文件
用记事本打开↓
用Excel打开↓ 
用csv格式存储数据,读写比较方便,易于实现,文件也会比Excel文件小,但csv文件缺少Excel文件本身的很多功能,比如不能嵌入图像和图表,不能生成公式
至于Excel文件,就是电子表格,它有专门保存文件的格式,即xls和xlsx(Excel2003版本的文件格式是xls,Excel2007及之后的版本的文件格式就是xlsx)
存储数据的基础知识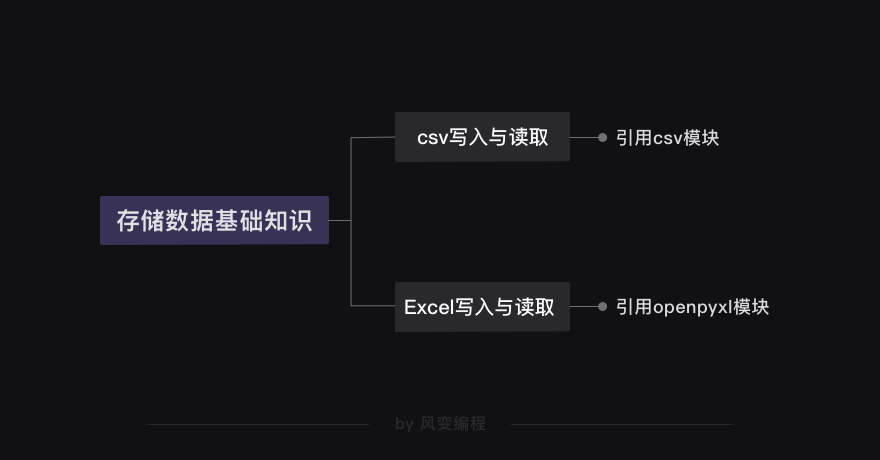
1. 基础知识:csv写入与读取
Python自带了csv模块,所以不需要安装就能引用它
import csv # 引用csv模块。 csv_file = open('demo.csv', 'w', newline='', encoding='utf-8') # 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8' writer = csv.writer(csv_file) # 用csv.writer()函数创建一个writer对象 writer.writerow(['电影', '豆瓣评分']) # 调用writer对象的writerow()方法,可以在csv文件里写入一行文字 “电影”和“豆瓣评分” writer.writerow(['银河护卫队', '8.0']) # 在csv文件里写入一行文字 “银河护卫队”和“8.0” writer.writerow(['复仇者联盟', '8.1']) # 在csv文件里写入一行文字 “复仇者联盟”和“8.1” csv_file.close() # 写入完成后,关闭文件
创建一个新的csv文件,命名为“demo.csv”
“w”就是writer,即文件写入模式,它会以覆盖原内容的形式写入新添加的内容
附上一张文件读写模式表↓
加newline=' '参数的原因是,可以避免csv文件出现两倍的行距(就是能避免表格的行与行之间出现空白行)
加encoding='utf-8',可以避免编码问题导致的报错或乱码
创建完csv文件后,要借助csv.writer()函数来建立一个writer对象
调用writer对象的writerow()方法往csv文件里写入新的内容
提醒:writerow()函数里,需要放入列表参数,所以得把要写入的内容写成列表,就像['电影','豆瓣评分']
最后关闭文件,就完成csv文件的写入了
运行代码后,名为“demo.csv”的文件会被创建,用Excel或记事本打开这个文件↓
csv读取↓
import csv # 导入csv模块 csv_file = open('demo.csv', 'r', newline='', encoding='utf-8') # 用open()打开“demo.csv”文件,'r'是read读取模式,newline=''是避免出现两倍行距。encoding='utf-8'能避免编码问题导致的报错或乱码 reader = csv.reader(csv_file) # 用csv.reader()函数创建一个reader对象 for row in reader: # 用for循环遍历reader对象的每一行 print(row) # 打印row,就能读取出“demo.csv”文件里的内容 csv_file.close() # 读取完成后,关闭文件 # 》》['电影', '豆瓣评分'] # 》》['银河护卫队', '8.0'] # 》》['复仇者联盟', '8.1']

csv模块本身还有很多函数和方法,附上csv模块官方文档链接:https://yiyibooks.cn/xx/python_352/library/csv.html#module-csv
2. 基础知识:Excel写入与读取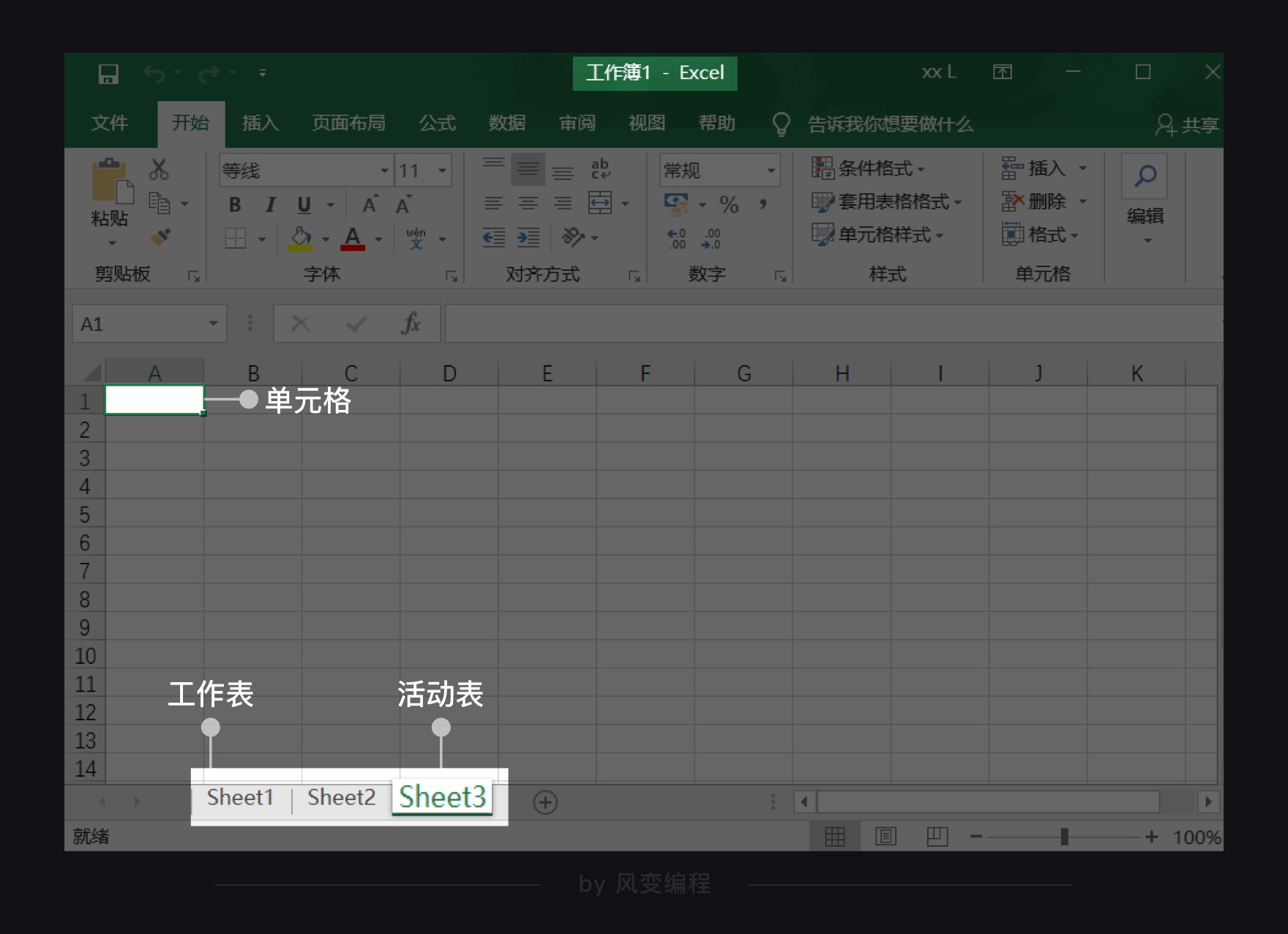
一个Excel文档也称为一个工作薄(workbook),每个工作薄里可以有多个工作表(worksheet),当前打开的工作表又叫活动表
每个工作表里有行和列,特定的行与列相交的方格称为单元格(cell),比如上图第A列和第1行相交的方格可以直接表示为A1单元格
openpyxl模块需要安装,mac电脑在终端输入命令:pip3 install openpyxl
import openpyxl # 引用openpyxl wb = openpyxl.Workbook() # 利用openpyxl.Workbook()函数创建新的workbook(工作薄)对象,就是创建新的空的Excel文件 sheet = wb.active # wb.active就是获取这个工作薄的活动表,通常就是第一个工作表 sheet.title = 'new title' # 可以用.title给工作表重命名。现在第一个工作表的名称就会由原来默认的“sheet1”改为"new title" sheet['A1'] = '漫威宇宙' # 把'漫威宇宙'赋值给第一个工作表的A1单元格,就是往A1的单元格中写入了'漫威宇宙' row = ['灭霸', '敲', '响指'] # 把想写入的一行内容写成列表,赋值给row。 sheet.append(row) # 用sheet.append()就能往表格里添加这一行文字 rows = [['美国队长', '钢铁侠', '蜘蛛侠'], ['是', '漫威', '宇宙', '经典', '人物']] # 把要写入的多行内容写成列表,再放进大列表里,赋值给rows for i in rows: sheet.append(i) # 遍历rows,同时把遍历的内容添加到表格里,这样就实现了多行写入 wb.save('Marvel.xlsx') # 保存新建的Excel文件,并命名为“Marvel.xlsx”

Excel读取↓
import openpyxl # 引用openpyxl wb = openpyxl.load_workbook('Marvel.xlsx') # 调用openpyxl.load_workbook()函数,打开“Marvel.xlsx”文件 sheet = wb['new title'] # 获取“Marvel.xlsx”工作薄中名为“new title”的工作表 sheetname = wb.sheetnames # sheetnames是用来获取工作薄所有工作表的名字的,如果不知道工作薄到底有几个工作表,就可以把工作表的名字都打印出来 print(sheetname) # 》》['new title'] A1_cell = sheet['A1'] A1_value = A1_cell.value # 把“new title”工作表中A1单元格赋值给A1_cell,再利用单元格value属性,就能打印出A1单元格的值 print(A1_value) # 》》漫威宇宙

openpyxl模块的官方文档:https://openpyxl.readthedocs.io/en/stable/
3. 存储周杰伦的歌曲信息
import requests import openpyxl wb = openpyxl.Workbook() # 创建工作薄 sheet = wb.active # 获取工作薄的活动表 sheet.title = 'song' # 工作表重命名 sheet['A1'] = '歌曲名' # 加表头,给A1单元格赋值 sheet['B1'] = '所属专辑' # 加表头,给B1单元格赋值 sheet['C1'] = '播放时长' # 加表头,给C1单元格赋值 sheet['D1'] = '播放链接' # 加表头,给D1单元格赋值 url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp' for x in range(5): params = { 'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'txt.yqq.song', 'searchid': '64405487069162918', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': str(x + 1), 'n': '20', 'w': '周杰伦', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0' } res_music = requests.get(url, params=params) json_music = res_music.json() list_music = json_music['data']['song']['list'] for music in list_music: name = music['name'] # 以name为键,查找歌曲名,把歌曲名赋值给name album = music['album']['name'] # 查找专辑名,把专辑名赋给album time = music['interval'] # 查找播放时长,把时长赋值给time link = 'https://y.qq.com/n/yqq/song/' + str(music['mid']) + '.html ' # 查找播放链接,把链接赋值给link sheet.append([name, album, time, link]) # 把name、album、time和link写成列表,用append函数多行写入Excel print('歌曲名:' + name + ' ' + '所属专辑:' + album + ' ' + '播放时长:' + str(time) + ' ' + '播放链接:' + link) wb.save('Jay.xlsx') # 最后保存并命名这个Excel文件
运行代码,“Jay.xlsx”文件就会被创建,打开这个文件就可以看到存储的数据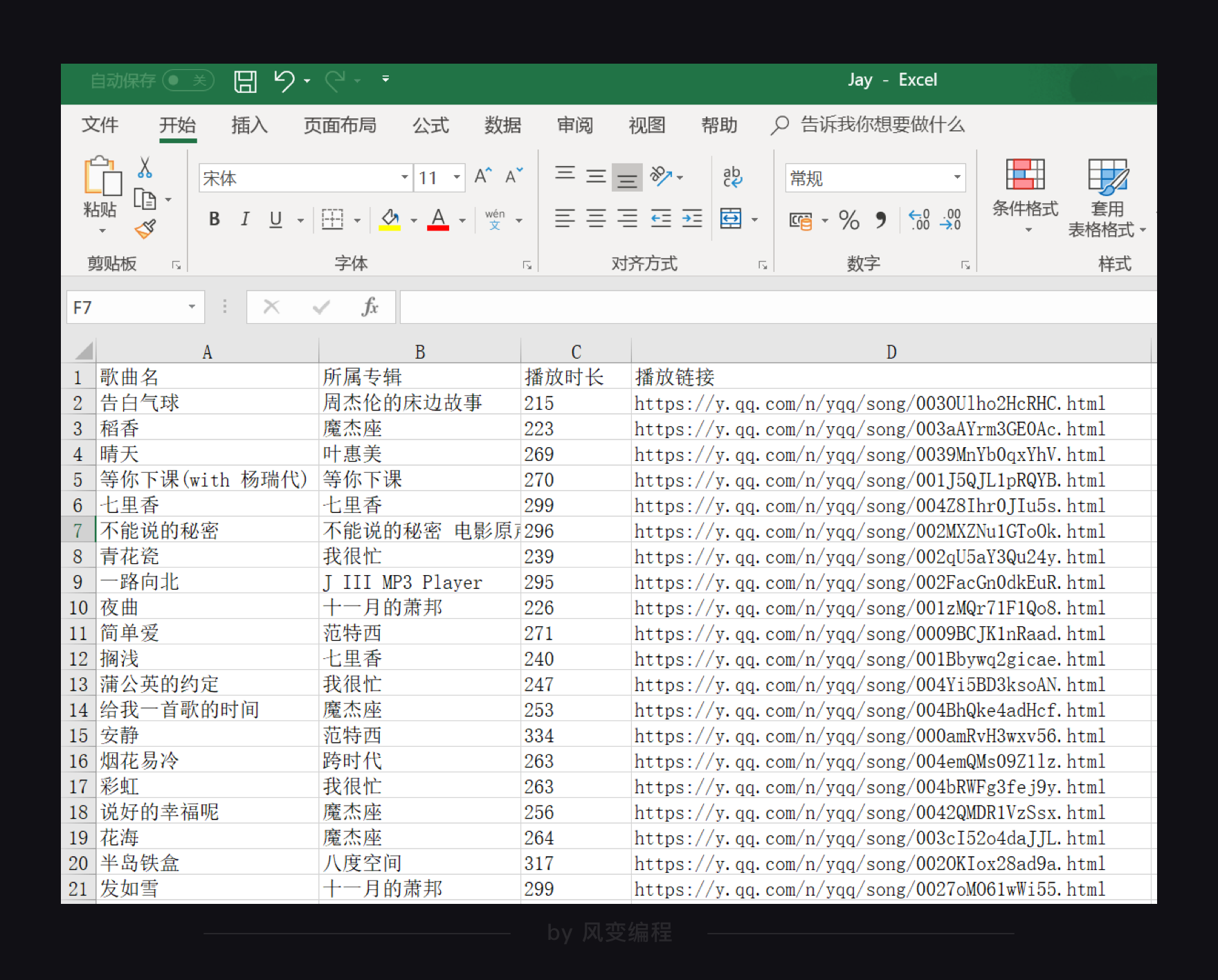
第7关 爬取知乎文章
前面6关所讲的爬虫原理,在本质上,是一个所操作的对象在不断转换的过程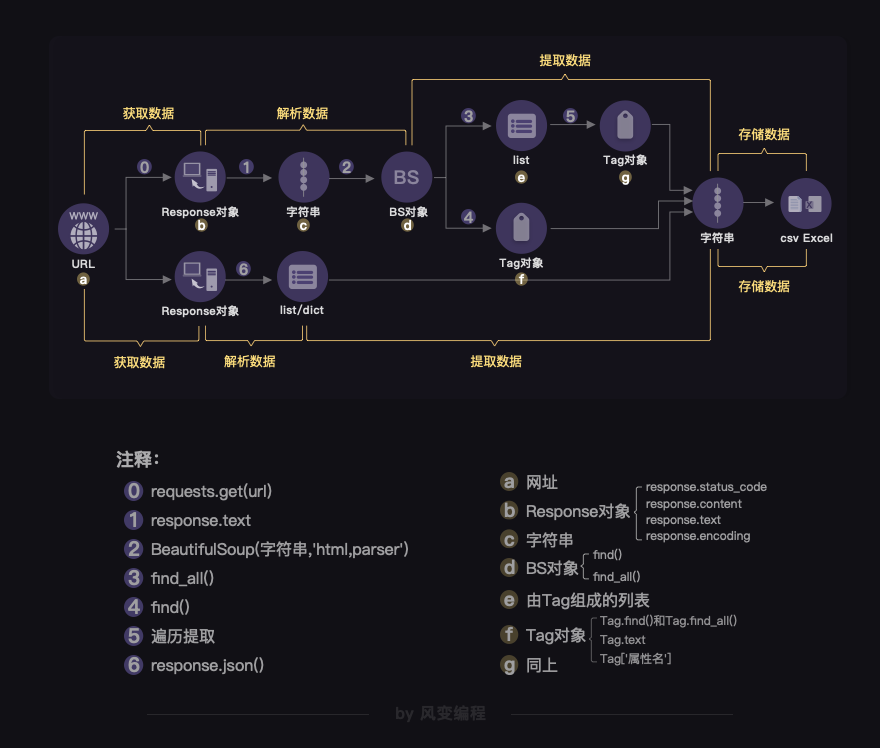
总体上来说,从Response对象开始,就分成了两条路径,一条路径是数据放在HTML里,所以用BeautifulSoup库去解析数据和提取数据;另一条,数据作为Json存储起来,所以用response.json()方法去解析,然后提取、存储数据
本关目标:爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
张佳玮的知乎文章URL:https://www.zhihu.com/people/zhang-jia-wei/posts?page=1
import requests import csv csv_file = open('articles.csv', 'w', newline='', encoding='utf-8') writer = csv.writer(csv_file) writer.writerow(['标题', '链接', '摘要']) offset = 0 while True: url = 'https://www.zhihu.com/api/v4/members/zhang-jia-wei/articles' headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'} params = { 'include': 'data[*].comment_count,suggest_edit,is_normal,thumbnail_extra_info,thumbnail,can_comment,comment_permission,admin_closed_comment,content,voteup_count,created,updated,upvoted_followees,voting,review_info,is_labeled,label_info;data[*].author.badge[?(type=best_answerer)].topics', 'offset': str(offset), 'limit': '20', 'sort_by': 'created' } res = requests.get(url, params=params, headers=headers) resjson = res.json() articles = resjson['data'] for article in articles: title = article['title'] link = article['url'] excerpt = article['excerpt'] writer.writerow([title, link, excerpt]) offset += 20 if offset > 40: break # if resjson['paging']['is_end'] == True: # break csv_file.close()
第8关 cookies
博客登录网址:https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php
账号:spiderman,密码:crawler334566
现在来分析浏览器的登录请求是怎么发送的
先正常操作——填写完账号密码(别点击登录),然后右击打开“检查”工具,点击【network】,勾选【preserve log】(持续显示请求记录,防止请求记录被刷新),再点击登录
1. post请求
展开第0个请求【wp-login.php】,浏览一下【headers】,在【General】键里,可以先只看前两个参数【Request URL】(请求网址)和【Request Method】(请求方式)
这里的请求方式是post,而不是get。其实,post和get都可以带着参数请求,不过get请求的参数会在url上显示出来,但post请求的参数就不会直接显示,而是隐藏起来。像账号密码这种私密的信息,就应该用post的请求,如果用get请求的话,账号密码全部会显示在网址上。可以这么理解,get是明文显示,post是非明文显示
通常,get请求会应用于获取网页数据,比如requests.get()。post请求则应用于向网页提交数据,比如提交表单类型数据(像账号密码就是网页表单的数据)
get和post是两种最常用的请求方式,除此之外,还有其他类型的请求方式,如head、options等,不过一般很少用到
2. cookies及其用法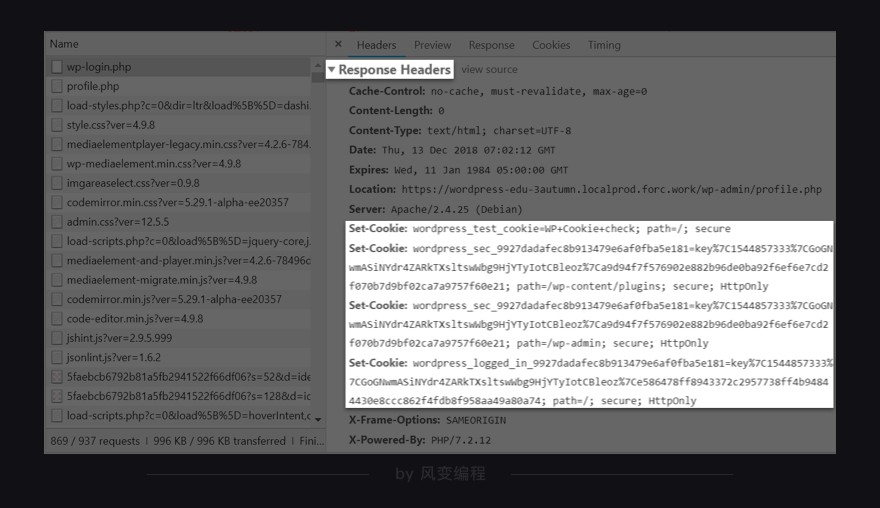
【requests headers】存储的是浏览器的请求信息,【response headers】存储的是服务器的响应信息
在【response headers】里有set cookies的参数,set cookies就是服务器往浏览器写入了cookies
当登录博客账号spiderman,并勾选“记住我”,服务器就会生成一个cookies和spiderman这个账号绑定。接着,它把这个cookies告诉浏览器,让浏览器把cookies存储到本地电脑。当下一次,浏览器带着cookies访问博客,服务器会知道是spiderman,就不需要再重复输入账号密码,即可直接访问
当然,cookies也是有时效性的,过期后就会失效。哪怕勾选了“记住我”,但一段时间过去了,网站还是会提示要重新登录,就是之前的cookies已经失效
继续看【headers】,拉到【form data】,可以看到5个参数↓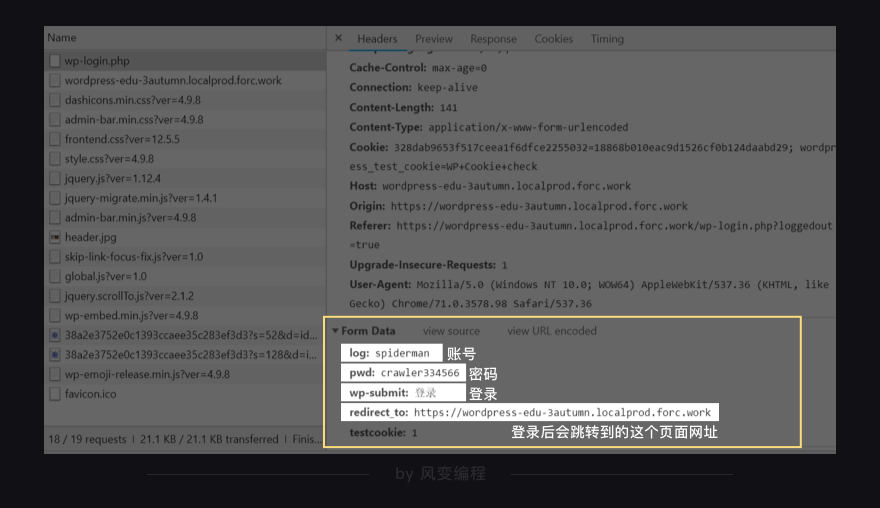
log和pwd显然是账号和密码,wp-submit能知道是登录的按钮,redirect_to后面带的链接是登录后会跳转到的这个页面网址,testcookie不知道是什么
在《未来已来(一)——技术变革》这篇文章下面发表一条评论(不要关闭检查工具,这样才能看到请求的记录)
点开【wp-comments-post.php】,看headers,刚刚发表的评论就藏在这里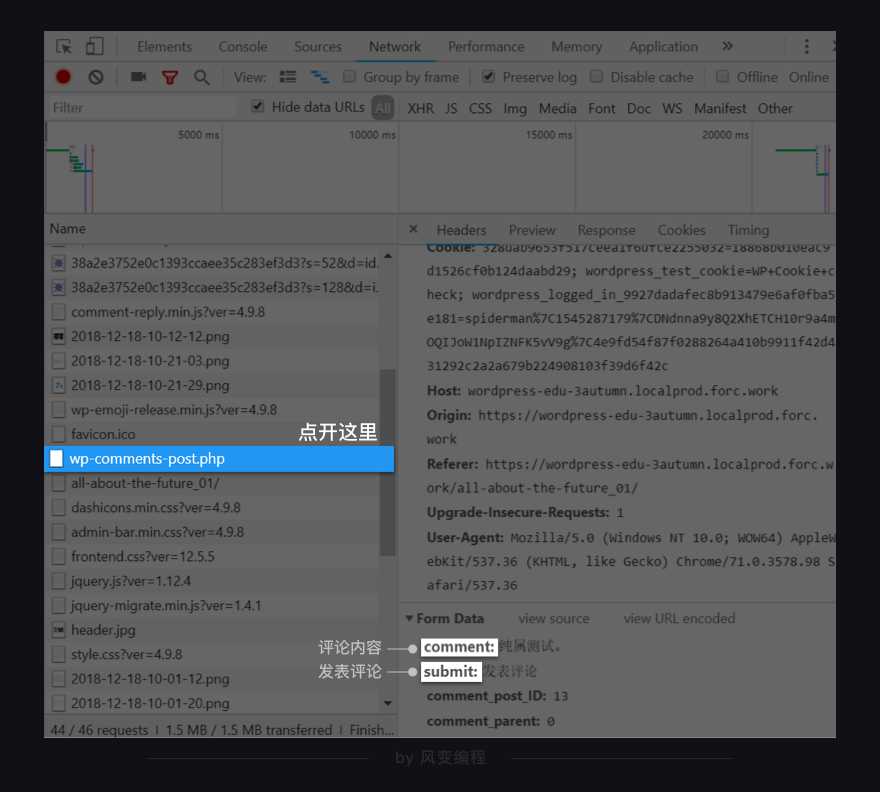
comment是评论内容,submit是发表评论的按钮,还有另外两个和评论有关的参数
想要发表博客评论,首先得登录,其次得提取和调用登录的cookies,然后还需要评论的参数,才能发起评论的请求
import requests # 引入requests url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php' # 把请求登录的网址赋值给url headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } # 加请求头,加请求头是为了模拟浏览器正常的访问,避免被反爬虫 data = { 'log': 'spiderman', # 写入账户 'pwd': 'crawler334566', # 写入密码 'wp-submit': '登录', 'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn', 'testcookie': '1' } # 把有关登录的参数封装成字典,赋值给data login_in = requests.post(url, headers=headers, data=data) # 用requests.post发起请求,放入参数:请求登录的网址、请求头和登录参数,然后赋值给login_in print(login_in) # 打印login_in # 》》<Response [200]> cookies = login_in.cookies # 提取cookies的方法:调用requests对象(login_in)的cookies属性获得登录的cookies,并赋值给变量cookies url_1 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php' # 想要评论的文章网址 data_1 = { 'comment': 'cookies测试', 'submit': '发表评论', 'comment_post_ID': '13', 'comment_parent': '0' } # 把有关评论的参数封装成字典 comment = requests.post(url_1, headers=headers, data=data_1, cookies=cookies) # 用requests.post发起发表评论的请求,放入参数:文章网址、headers、评论参数、cookies参数,赋值给comment # 调用cookies的方法就是在post请求中传入cookies=cookies的参数 print(comment.status_code) # 打印出comment的状态码,若状态码等于200,则证明评论成功 # 》》200
<Response [200]>,是返回了200的状态码,意味着服务器接收到并响应了登录请求
cookies = login_in.cookies这句是提取cookies的方法,调用requests对象的cookies属性获得登录的cookies
调用cookies的方法是在post请求中传入cookies=cookies的参数就可以了
最后之所以加一行打印状态码的代码,是想运行整个代码后,能立马判断出评论到底有没有成功发表。只要状态码等于200,就说明服务器成功接收并响应了评论请求
登录的cookies其实包含了很多名称和值,真正能帮助发表评论的cookies,只是取了登录cookies中某一小段值而已。所以登录的cookies和评论成功后,在【wp-comments-post.php】里的headers面板中看到的cookies是不一致的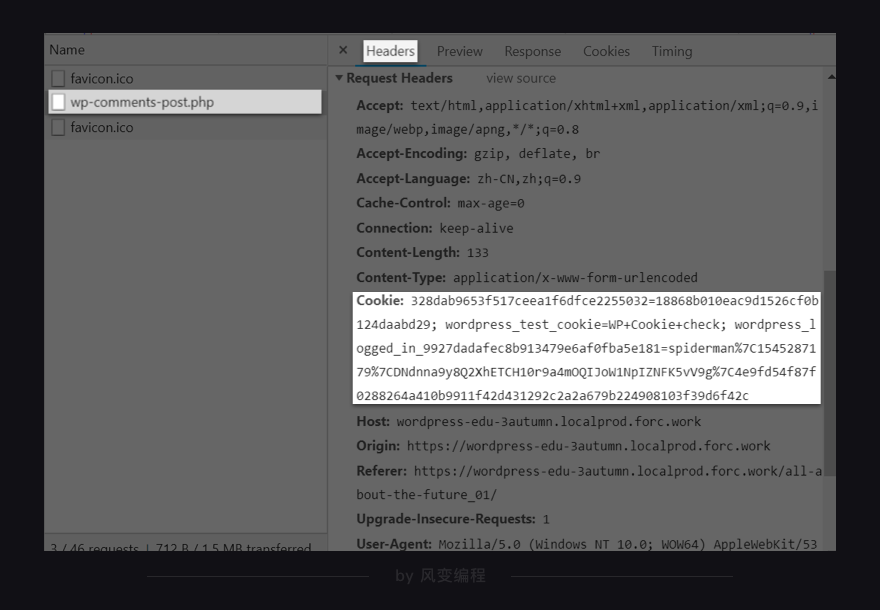
用requests模块发表博客评论的三个重点↓
① post带着参数地请求登录
② 获得登录的cookies
③ 带cookies去请求发表评论
3. session及其用法
所谓的会话,可以理解成用浏览器上网,到关闭浏览器的这一过程。session是会话过程中,服务器用来记录特定用户会话的信息
比如打开浏览器逛购物网页的整个过程中,浏览了哪些商品,在购物车里放了多少件物品,这些记录都会被服务器保存在session中
如果没有session,可能会出现这样搞笑的情况:加购了很多商品在购物车,打算结算时,发现购物车空无一物,因为服务器根本没有记录想买的商品
session和cookies的关系还非常密切——cookies中存储着session的编码信息,session中又存储了cookies的信息
当浏览器第一次访问购物网页时,服务器会返回set cookies的字段给浏览器,而浏览器会把cookies保存到本地
等浏览器第二次访问这个购物网页时,就会带着cookies去请求,而因为cookies里带有会话的编码信息,服务器立马就能辨认出这个用户,同时返回和这个用户相关的特定编码的session
这也是为什么每次重新登录购物网站后,之前在购物车放入的商品并不会消失的原因。因为在登录时,服务器可以通过浏览器携带的cookies,找到保存了购物车信息的session
在requests的高级用法里,有通过创建session来处理cookies的方法。发表博客评论的代码可以写为↓
import requests # 引用requests session = requests.session() # 用requests.session()创建session对象,相当于创建了一个特定的会话,自动保持了cookies url = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } data = { 'log': 'spiderman', 'pwd': 'crawler334566', 'wp-submit': '登录', 'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn', 'testcookie': '1' } session.post(url, headers=headers, data=data) # 在创建的session下用post发起登录请求,放入参数:请求登录的网址、请求头和登录参数 url_1 = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php' # 把想要评论的文章网址赋值给url_1 data_1 = { 'comment': 'session测试', 'submit': '发表评论', 'comment_post_ID': '13', 'comment_parent': '0' } # 把有关评论的参数封装成字典 comment = session.post(url_1, headers=headers, data=data_1) # 在创建的session下用post发起评论请求,放入参数:文章网址,请求头和评论参数,并赋值给comment print(comment) # 打印comment # 》》<Response [200]>
用session模块发表博客评论的三个重点↓
① 创建会话(session)
② 在创建的会话下发起post登录请求
③ 在创建的会话下发起post评论请求
4. 存储cookies
先把登录的cookies打印出来看看↓
import requests session = requests.session() url = 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } data = { 'log': 'spiderman', 'pwd': 'crawler334566', 'wp-submit': '登录', 'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn', 'testcookie': '1' } session.post(url, headers=headers, data=data) print(type(session.cookies)) # 打印cookies的类型,session.cookies就是登录的cookies print(session.cookies) # 打印cookies # 》》<class 'requests.cookies.RequestsCookieJar'> # 》》<RequestsCookieJar[<Cookie 328dab9653f517ceea1f6dfce2255032=7cd1e98da7c519edc41374a980c6c80c for wordpress-edu-3autumn.localprod.oc.forchange.cn/>, <Cookie wordpress_logged_in_dc180e44ec13b4c601eeef962104f0fe=spiderman%7C1586880428%7CA9bYNaShymZmonXtwiZztH9M7umN7yKI79zYRBN4nvR%7C6a43f8d7c2163d940c9c6814ab905d945ee20b4eac985583b18bb1c9a93e32fb for wordpress-edu-3autumn.localprod.oc.forchange.cn/>, <Cookie wordpress_test_cookie=WP+Cookie+check for wordpress-edu-3autumn.localprod.oc.forchange.cn/>, <Cookie wordpress_sec_dc180e44ec13b4c601eeef962104f0fe=spiderman%7C1586880428%7CA9bYNaShymZmonXtwiZztH9M7umN7yKI79zYRBN4nvR%7C7bfb4219b9ff58209108b2186464f4c35df924d732dfbd9769183639bb6152b9 for wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-admin>, <Cookie wordpress_sec_dc180e44ec13b4c601eeef962104f0fe=spiderman%7C1586880428%7CA9bYNaShymZmonXtwiZztH9M7umN7yKI79zYRBN4nvR%7C7bfb4219b9ff58209108b2186464f4c35df924d732dfbd9769183639bb6152b9 for wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-content/plugins>]>
RequestsCookieJar是cookies对象的类,cookies本身的内容有点像一个列表,里面又有点像字典的键与值
想要把cookies存储到txt文件,可是txt文件存储的是字符串,中间需要进行转换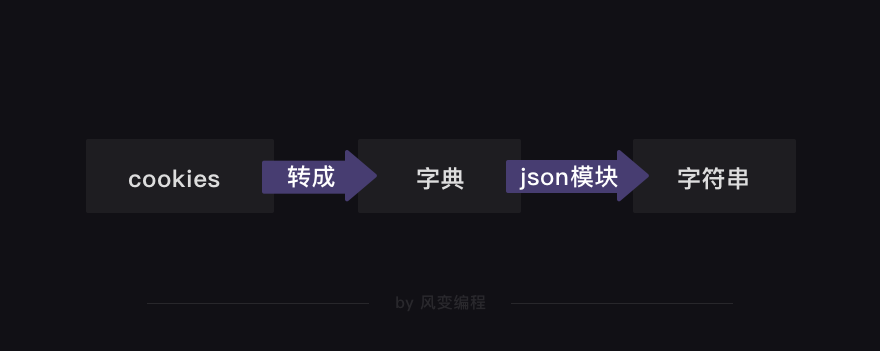
把cookies存储成txt文件的代码如下↓
import requests,json # 引入requests和json模块 session = requests.session() url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } data = { 'log': 'spiderman', 'pwd': 'crawler334566', 'wp-submit': '登录', 'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn', 'testcookie': '1' } session.post(url, headers=headers, data=data) cookies_dict = requests.utils.dict_from_cookiejar(session.cookies) # 把cookies转化成字典 print(cookies_dict) # 打印cookies_dict # 》》{'328dab9653f517ceea1f6dfce2255032': '7cd1e98da7c519edc41374a980c6c80c', 'wordpress_logged_in_dc180e44ec13b4c601eeef962104f0fe': 'spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C3be08285d54b2c7bd527e0491d1e358efcaf6c8b252061e07baeda28bd071332', 'wordpress_test_cookie': 'WP+Cookie+check', 'wordpress_sec_dc180e44ec13b4c601eeef962104f0fe': 'spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C4322ad4a66be7589813f82133ad212bfe4f2d314076b2df91bddb595ea6b0a09'} cookies_str = json.dumps(cookies_dict) # 调用json模块的dumps函数,把cookies从字典再转成字符串 print(cookies_str) # 打印cookies_str # 》》{"328dab9653f517ceea1f6dfce2255032": "7cd1e98da7c519edc41374a980c6c80c", "wordpress_logged_in_dc180e44ec13b4c601eeef962104f0fe": "spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C3be08285d54b2c7bd527e0491d1e358efcaf6c8b252061e07baeda28bd071332", "wordpress_test_cookie": "WP+Cookie+check", "wordpress_sec_dc180e44ec13b4c601eeef962104f0fe": "spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C4322ad4a66be7589813f82133ad212bfe4f2d314076b2df91bddb595ea6b0a09"} f = open('cookies.txt', 'w') # 创建名为cookies.txt的文件,以写入模式写入内容 f.write(cookies_str) # 把已经转成字符串的cookies写入文件 f.close() # 关闭文件
5. 读取cookies
存储cookies时,是把它先转成字典,再转成字符串。读取cookies则刚好相反,要先把字符串转成字典,再把字典转成cookies本来的格式
读取cookies的代码如下↓
import requests,json session = requests.session() cookies_txt = open('cookies.txt', 'r') # 以reader读取模式,打开名为cookies.txt的文件 cookies_dict = json.loads(cookies_txt.read()) # 调用json模块的loads函数,把字符串转成字典 cookies = requests.utils.cookiejar_from_dict(cookies_dict) # 把转成字典的cookies再转成cookies本来的格式 session.cookies = cookies # 获取cookies:就是调用requests对象(session)的cookies属性 print(session.cookies) # 》》<RequestsCookieJar[<Cookie 328dab9653f517ceea1f6dfce2255032=7cd1e98da7c519edc41374a980c6c80c for />, <Cookie wordpress_logged_in_dc180e44ec13b4c601eeef962104f0fe=spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C3be08285d54b2c7bd527e0491d1e358efcaf6c8b252061e07baeda28bd071332 for />, <Cookie wordpress_sec_dc180e44ec13b4c601eeef962104f0fe=spiderman%7C1586885493%7CCCwOuR2nO5BphlCQT4DlfKcDto8abAxD4TH57IUwjso%7C4322ad4a66be7589813f82133ad212bfe4f2d314076b2df91bddb595ea6b0a09 for />, <Cookie wordpress_test_cookie=WP+Cookie+check for />]>
现在可以写成更完整的代码了:如果程序能读取到cookies,就自动登录,发表评论;如果读取不到,就重新输入账号密码登录,再评论;另外,如果cookies过期,也要重新获取新的cookies
import requests,json session = requests.session() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'} def cookies_read(): cookies_txt = open('cookies.txt', 'r') cookies_dict = json.loads(cookies_txt.read()) cookies = requests.utils.cookiejar_from_dict(cookies_dict) return (cookies) def sign_in(): url = ' https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php' data = {'log': 'spiderman', 'pwd': 'crawler334566', 'wp-submit': '登录', 'redirect_to': 'https://wordpress-edu-3autumn.localprod.oc.forchange.cn', 'testcookie': '1'} session.post(url, headers = headers, data = data) cookies_dict=requests.utils.dict_from_cookiejar(session.cookies) cookies_str=json.dumps(cookies_dict) f=open('cookies.txt', 'w') f.write(cookies_str) f.close() def write_message(): url_2='https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-comments-post.php' data_2={ 'comment': '测试测试测试', 'submit': '发表评论', 'comment_post_ID': '13', 'comment_parent': '0' } return (session.post(url_2, headers = headers, data = data_2)) try: session.cookies=cookies_read() except FileNotFoundError: sign_in() num=write_message() if num.status_code == 200: print('成功啦!') else: sign_in() num=write_message()
其实,计算机之所以需要cookies和session,是因为HTTP协议是无状态的协议
何为无状态?就是一旦浏览器和服务器之间的请求和响应完毕后,两者会立马断开连接,也就是恢复成无状态
这样会导致:服务器永远无法辨认,也记不住用户的信息,像一条只有7秒记忆的金鱼。是cookies和session的出现,才破除了web发展史上的这个难题
cookies不仅仅能实现自动登录,因为它本身携带了session的编码信息,网站还能根据cookies,记录用户的浏览足迹,从而知道用户的偏好,只要再加以推荐算法,就可以实现给用户推送定制化的内容
比如,淘宝会根据用户搜索和浏览商品的记录,推送符合偏好的商品,增加用户的购买率。cookies和session在这其中起到的作用,可谓举足轻重
6. filter()函数filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用list()来转换
语法:filter(function, iterable)
filter()接收两个参数,第一个为函数(function-判断函数),第二个为序列(iterable-可迭代对象),序列的每个元素作为参数传递给函数进行判断,然后返回True或False,最后将返回True的元素放到新列表中
# 过滤出网址中的数字 id_filter = filter(str.isdigit, 'https://www.xslou.com/yuedu/22177/') print(type(id_filter)) # 》》<class 'filter'> id_list = list(id_filter) print(id_list) # 》》['2', '2', '1', '7', '7'] book_id = ''.join(id_list) print(book_id) # 》》22177 # 过滤出列表中的所有奇数 def is_odd(n): return n % 2 == 1 tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) newlist = list(tmplist) print(newlist) # 》》[1, 3, 5, 7, 9]
7. 自制翻译小程序
新的知识点tkinter,程序终于有界面了
import requests from tkinter import Tk, Text, Button, Label, END def crawl(word): url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'} data = {'i': word, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_REALTIME', 'typoResult': 'false'} res = requests.post(url, data=data, headers=headers) try: result = res.json()['translateResult'][0][0]['tgt'] except: result = "" return result def trans(): content = text.get(0.0, END).strip().replace(" ", " ") result = crawl(content) result_text.configure(state='normal') result_text.delete(0.0, END) result_text.insert(END, result) result_text.configure(state='disabled') def clean(): text.delete(0.0, END) result_text.configure(state='normal') result_text.delete(0.0, END) result_text.configure(state='disabled') root = Tk() # 生成主窗口 root.title('翻译器') # 修改框体的名字,也可在创建时使用className参数来命名 root.geometry('380x500') # 指定主框体大小,geometry(宽度x高度+左上角水平坐标+左上角垂直坐标)(是英文x不是乘号) text = Text(root, bg='gray90') # 生成多行文本框,bg指定了背景色 # 选颜色的链接:http://www.science.smith.edu/dftwiki/index.php/Color_Charts_for_TKinter text.place(x=5, y=5, width=370, height=230) # 布局控件:pack,grid,place,这里使用的是place。x:组件左上角的x坐标,y:组件右上角的y坐标,组件的宽度,heitht:组件的高度 trans_btn = Button(root, text='翻译', command=trans) # 生成“翻译”按钮,调用trans方法 trans_btn.place(x=278, y=238, width=45, height=24) wipe_btn = Button(root, text='清空', command=clean) # 生成“清空”按钮,调用clean方法 wipe_btn.place(x=328, y=238, width=45, height=24) title_label = Label(root, text='翻译结果') # 生成“翻译结果”标题标签˝ title_label.place(x=5, y=238) result_text = Text(root, bg='gray90') # 生成显示结果的多行文本框 result_text.configure(state='disabled') # 为了实现只读效果,将文本框状态设置为disabled result_text.place(x=5, y=265, width=370, height=230) root.mainloop() # 窗口事件主循环
8. 图灵机器人
图灵机器人官网:http://www.tuling123.com/
跟机器人聊天的简易程序代码↓
import requests import json url = 'http://openapi.tuling123.com/openapi/api/v2' # 接口地址 while True: chat = input('我:') data = { "reqType": 0, "perception": { "inputText": { "text": chat } }, "userInfo": { "apiKey": "...", # apiKey是针对接口访问的授权方式。注册登录后创建机器人,会生成apiKey "userId": "xiaomei" # userId:长度需小于32,是用户的唯一标识 } } # perception和userInfo是必须要填写的参数 res = requests.post(url, data=json.dumps(data)) # 请求参数格式为 json result = res.json()['results'][0]['values']['text'] print('图小智:'+result)
第9关 Selenium
selenium是一个强大的Python库,它可以用几行代码,控制浏览器,做出自动打开、输入、点击等操作,就像是有一个真正的用户在操作一样
当你遇到验证码很复杂的网站时,selenium允许让人去手动输入验证码,然后把剩下的操作交给机器
而对于那些交互复杂、加密复杂的网站,selenium问题简化,爬动态网页如爬静态网页一样简单
第1关用html写出的网页,就是静态网页,这类型网页使用beautifulsoup爬取,因为网页源代码中就包含着网页的所有信息,因此,网页地址栏的url就是网页源代码的url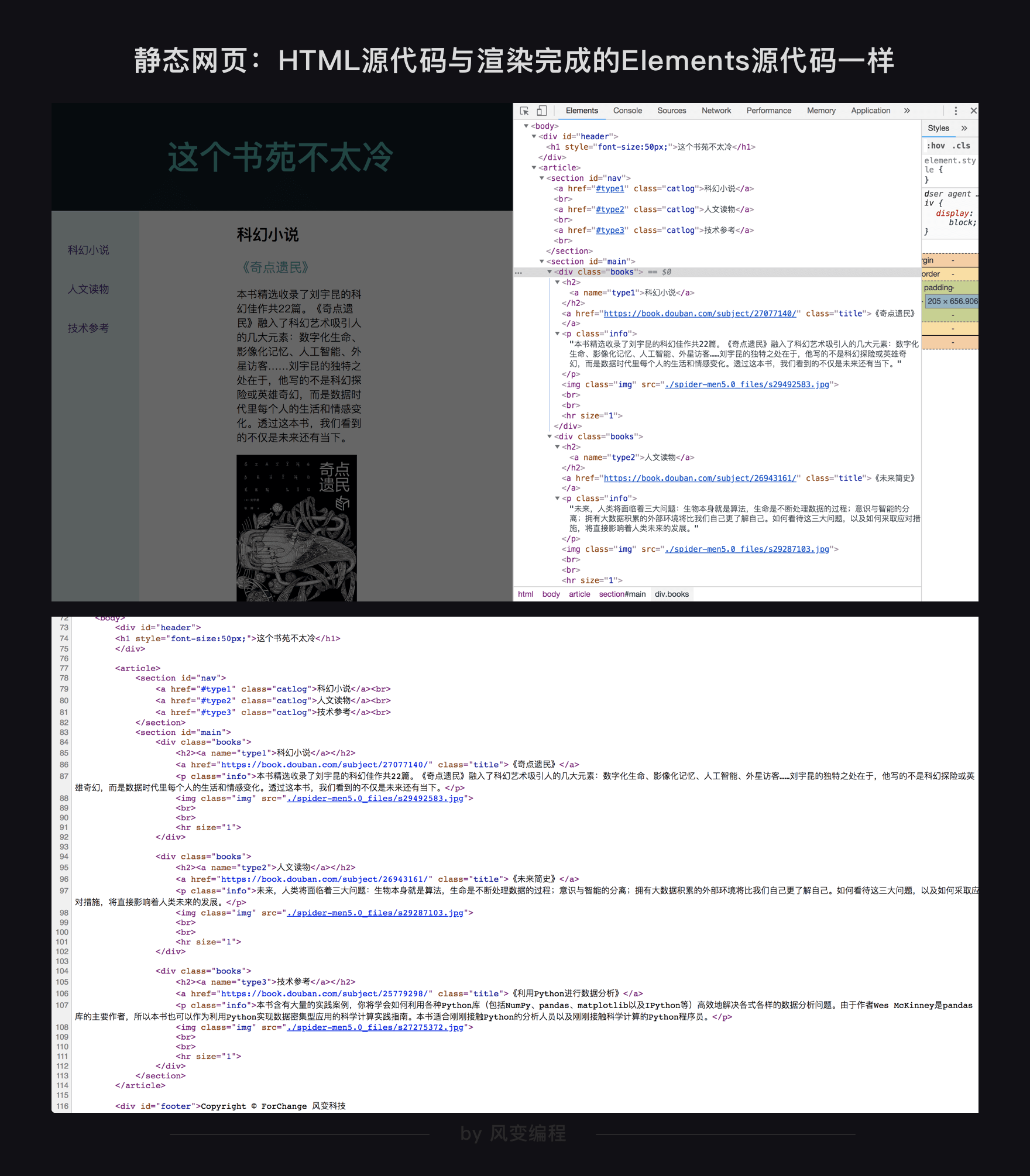
之后接触的更复杂的网页,比如QQ音乐,要爬取的数据不在HTML源代码中,而是在json中,就不能直接使用网址栏的url了,而需要找到json数据的真实url,这就是一种动态网页 
不论数据存在哪里,浏览器总是在向服务器发起各式各样的请求,当这些请求完成后,它们会一起组成开发者工具的Elements中所展示的,渲染完成的网页源代码
在遇到页面交互复杂或是url加密逻辑复杂的情况时,selenium就派上了用场,它可以真实地打开一个浏览器,等待所有数据都加载到Elements中之后,再把这个网页当做静态网页爬取就好了
当然selenium也有美中不足之处,由于要真实地运行本地浏览器,打开浏览器以及等待网渲染完成需要一些时间,selenium的工作不可避免地牺牲了速度和更多资源,不过,至少不会比人慢
1. 安装selenium库和浏览器驱动
selenium需要安装,mac电脑在终端输入命令:pip3 install selenium
selenium的脚本可以控制所有常见浏览器的操作,在使用之前,需要安装浏览器的驱动
推荐使用Chrome浏览器,浏览器安装好后,在终端输入命令:curl -s https://localprod.pandateacher.com/python-manuscript/crawler-html/chromedriver/chromedriver-for-Macos.sh | bash
驱动安装方法也可以见链接:https://localprod.pandateacher.com/python-manuscript/crawler-html/chromedriver/ChromeDriver.html
2. 设置浏览器引擎
# 本地Chrome浏览器设置方法 from selenium import webdriver # 从selenium库中调用webdriver模块 driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
# 本地Chrome浏览器的静默模式设置: from selenium import webdriver # 从selenium库中调用webdriver模块 from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类 chrome_options = Options() # 实例化Option对象 chrome_options.add_argument('--headless') # 把Chrome浏览器设置为静默模式 driver = webdriver.Chrome(options=chrome_options) # 设置引擎为Chrome,在后台默默运行
以上就是浏览器的设置方式:把Chrome浏览器设置为引擎,然后赋值给变量driver,driver是实例化的浏览器
3. 获取、解析与提取数据
本关学习以【你好蜘蛛侠!】这个网站为例
import time # 本地Chrome浏览器设置方法 from selenium import webdriver # 从selenium库中调用webdriver模块 driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器 # 获取数据 driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 通过实例化的浏览器打开网页 time.sleep(2) # 等待2秒,等浏览器加载缓冲数据 # 解析与提取数据 # 解析数据是由driver自动完成的,提取数据是driver的一个方法 label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签中的文字 print(type(label)) # 打印label的数据类型 # 》》<class 'selenium.webdriver.remote.webelement.WebElement'> print(label.text) # 打印label的文本 # 》》(提示:吴枫) print(label) # 打印label # 》》<selenium.webdriver.remote.webelement.WebElement (session="d776d7492e34a61bc565e755ce082388", element="0.30820374741568446-1")> teacher = driver.find_element_by_class_name('teacher') # 根据类名找到元素 print(type(teacher)) # 打印teacher的数据类型 #》》<class 'selenium.webdriver.remote.webelement.WebElement'> print(teacher.get_attribute('type')) # 获取type这个属性的值 #》》text driver.close() # 关闭浏览器驱动,每次调用了webdriver之后,都要在用完它之后加上一行driver.close()用来关闭它
selenium和BeautifulSoup的底层原理一致,但在一些细节和语法上有所出入
selenium所解析提取的,是Elements中的所有数据,而BeautifulSoup所解析的则只是Network中第0个请求的响应
用selenium把网页打开,所有信息就都加载到了Elements那里,之后,就可以把动态网页用静态网页的方法爬取了
selenium有很多查找和提取元素的方法↓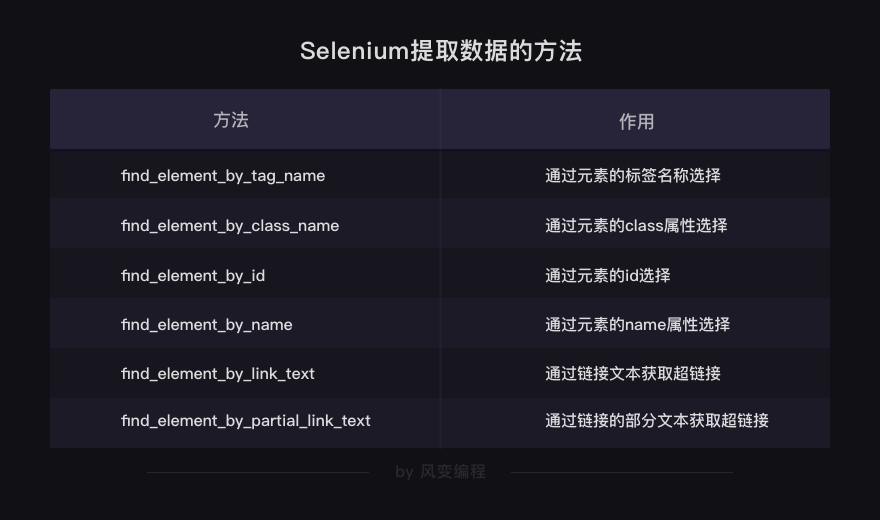
selenium提取出的数据属于WebElement类对象,如果直接打印它,返回的是一串对它的描述
它与BeautifulSoup中的Tag对象类似,也有一个属性.text,可以把提取出的元素用字符串格式显示
有一个方法,也可以通过属性名提取属性的值,这个方法是.get_attribute()
可以总结出selenium解析与提取数据的过程中,操作的对象转换↓
find_element_by_与BeautifulSoup中的find类似,可以提取出网页中第一个符合要求的元素,selenium也同样有与find_all类似的方法,find_elements_by_,可以提取多个元素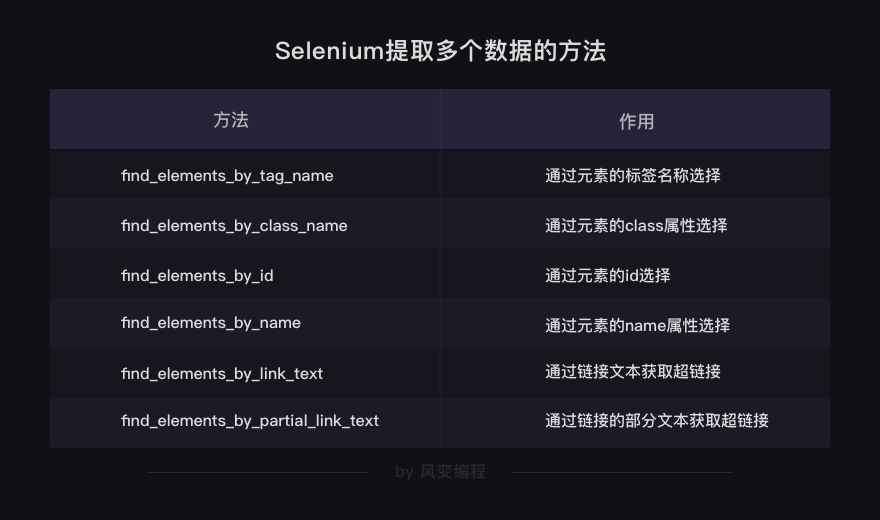
这样提取出的是一个列表,<class 'list'>,而列表的内容就是WebElement对象
除了用selenium解析与提取数据,还有一种解决方案,那就是,使用selenium获取网页,然后交给BeautifulSoup解析和提取
BeautifulSoup需要把字符串格式的网页源代码解析为BeautifulSoup对象,然后再从中提取数据
而selenium刚好可以获取到渲染完整的网页源代码,并且是字符串类型
import time # 本地Chrome浏览器的静默模式设置: from selenium import webdriver # 从selenium库中调用webdriver模块 from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类 chrome_options = Options() # 实例化Option对象 chrome_options.add_argument('--headless') # 把Chrome浏览器设置为静默模式 driver = webdriver.Chrome(options=chrome_options) # 设置引擎为Chrome,在后台默默运行 driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') time.sleep(2) pageSource = driver.page_source # 获取完整渲染的网页源代码 print(type(pageSource)) # 打印pageSource的类型 # 》》<class 'str'> print(pageSource) # 打印pageSource driver.close() # 关闭浏览器
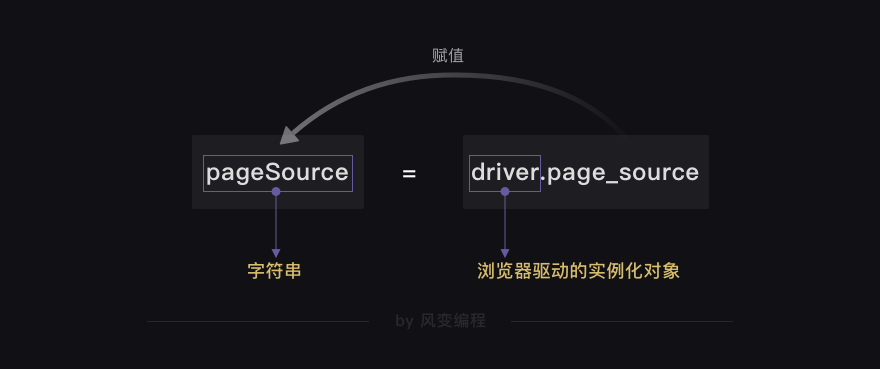
获取到了字符串格式的网页源代码之后,就可以用BeautifulSoup解析和提取数据了
4. 自动操作浏览器
# 本地Chrome浏览器设置方法 from selenium import webdriver # 从selenium库中调用webdriver模块 from bs4 import BeautifulSoup # 导入BeautifulSoup import time # 调用time模块 driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器 driver.get( 'https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面 time.sleep(2) # 暂停两秒,等待浏览器缓冲 teacher = driver.find_element_by_id('teacher') # 找到【请输入你喜欢的老师】下面的输入框位置 teacher.send_keys('蜘蛛侠') # 输入文字 time.sleep(1) teacher.clear() # 清除文字 time.sleep(1) teacher.send_keys('穿着熊') # 再次输入文字 time.sleep(1) assistant = driver.find_element_by_name('assistant') # 找到【请输入你喜欢的助教】下面的输入框位置 assistant.send_keys('都喜欢') # 输入文字 time.sleep(1) button = driver.find_element_by_class_name('sub') # 找到【提交】按钮 button.click() # 点击【提交】按钮 time.sleep(1) bs = BeautifulSoup(driver.page_source, 'html.parser') content_en = bs.find_all('div', class_='content')[0] title_en = content_en.find('h1').text zen_en = content_en.find('p').text content_ch = bs.find_all('div', class_='content')[1] title_ch = content_ch.find('h1').text zen_ch = content_ch.find('p').text driver.close() # 关闭浏览器
在每一次输入和点击之前,都要先定位到对应的位置,查找定位用的方法就是解析与提取数据的方法
selenium的官方文档链接:https://seleniumhq.github.io/selenium/docs/api/py/api.html
还可以参考这个中文文档:https://selenium-python-zh.readthedocs.io/en/latest/
第10关 定时与邮件
1. schedule
通过第三方库schedule实现定时功能
标准库一般意味着最原始最基础的功能,第三方库很多是去调用标准库中封装好了的操作函数。比如schedule,就是用time和datetime来实现的
对于定时功能,time和datetime当然能实现,但操作逻辑会相对复杂,而schedule可以直接解决定时功能,代码比较简单
schedule需要先安装,mac电脑在终端输入:pip3 install schedule
import schedule import time # 引入schedule和time模块 def job(): print("I'm working...") # 定义一个叫job的函数,函数的功能是打印'I'm working...' schedule.every(2).seconds.do(job) # 每2s执行一次job()函数 while True: schedule.run_pending() time.sleep(1) # 检查部署的情况,如果任务准备就绪,就开始执行任务。time.sleep(1)是让程序按秒来检查,如果检查太快,会浪费计算机的资源
执行结果如下图↓
再列一些其他的时间设置↓
import schedule import time def job(): print("I'm working...") schedule.every(10).minutes.do(job) # 部署每10分钟执行一次job()函数的任务 schedule.every().hour.do(job) # 部署每×小时执行一次job()函数的任务 schedule.every().day.at("10:30").do(job) # 部署在每天的10:30执行job()函数的任务 schedule.every().monday.do(job) # 部署每个星期一执行job()函数的任务 schedule.every().wednesday.at("13:15").do(job) # 部署每周三的13:15执行函数的任务 while True: schedule.run_pending() time.sleep(1)
2. 定时发送天气情况
import requests import smtplib import schedule import time from bs4 import BeautifulSoup from email.mime.text import MIMEText from email.header import Header account = input('请输入发件人邮箱:') password = input('请输入邮箱授权码:') receiver = input('请输入收件人邮箱:') def weather_spider(): headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} url = 'http://www.weather.com.cn/weather/101280601.shtml' res = requests.get(url, headers=headers) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') tem1 = soup.find(class_='tem') weather1 = soup.find(class_='wea') tem = tem1.text weather = weather1.text return tem, weather def send_email(tem, weather): mailhost = 'smtp.qq.com' qqmail = smtplib.SMTP() qqmail.connect(mailhost, 25) qqmail.login(account, password) content = tem+weather message = MIMEText(content, 'plain', 'utf-8') subject = '今日天气预报' message['Subject'] = Header(subject, 'utf-8') try: qqmail.sendmail(account, receiver, message.as_string()) print('邮件发送成功') except: print('邮件发送失败') qqmail.quit() def job(): print('开始一次任务') tem, weather = weather_spider() send_email(tem, weather) print('任务完成') schedule.every().day.at("07:30").do(job) while True: schedule.run_pending() time.sleep(1)
保持程序一直运行的状态,和电脑一直开机的状态。因为如果程序结束或者电脑关机了的话,就不会定时爬取天气信息了
真实的开发环境中,程序一般都会挂在远端服务器,因为远端服务器24小时都不会关机,就能保证定时功能的有效性了
关于邮件发送↓
在风变编程笔记(一)-Python基础语法有专门介绍
3. 必做练习【周末吃什么】的代码↓
import requests,schedule,time,smtplib,json from bs4 import BeautifulSoup from email.mime.text import MIMEText from email.header import Header url = 'http://www.xiachufang.com/explore/' headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} from_addr = 'xxx@qq.com' password = 'xxx' to_addr = 'xxx@sina.com' smtp_server = 'smtp.qq.com' def job(): res_foods = requests.get(url, headers=headers) bs_foods = BeautifulSoup(res_foods.text, 'html.parser') list_foods = bs_foods.find_all('div', class_='info pure-u') list_all = [] for i in range(len(list_foods)): tag_a = list_foods[i].find('a') name = tag_a.text[17:-13] URL = 'http://www.xiachufang.com'+tag_a['href'] tag_p = list_foods[i].find('p', class_='ing ellipsis') ingredients = tag_p.text[1:-1] list_all.append([name, URL, ingredients]) msg = MIMEText(json.dumps(list_all, ensure_ascii=False), 'plain', 'utf-8') msg['From'] = Header(from_addr) msg['To'] = Header(to_addr) msg['Subject'] = Header('本周最受欢迎菜谱', 'utf-8') server = smtplib.SMTP_SSL(smtp_server) server.connect(smtp_server, 465) server.login(from_addr, password) try: server.sendmail(from_addr, to_addr, msg.as_string()) print('恭喜,发送成功') except: print('发送失败,请重试') server.quit() schedule.every().friday.do(job) while True: schedule.run_pending() time.sleep(1)
第11关 协程
一个任务未完成时,就可以执行其他多个任务,彼此不受影响,叫异步
同步就是一个任务结束才能启动下一个
显然,异步执行任务会比同步更加节省时间,因为它能减少不必要的等待。如果需要对时间做优化,异步是一个很值得考虑的方案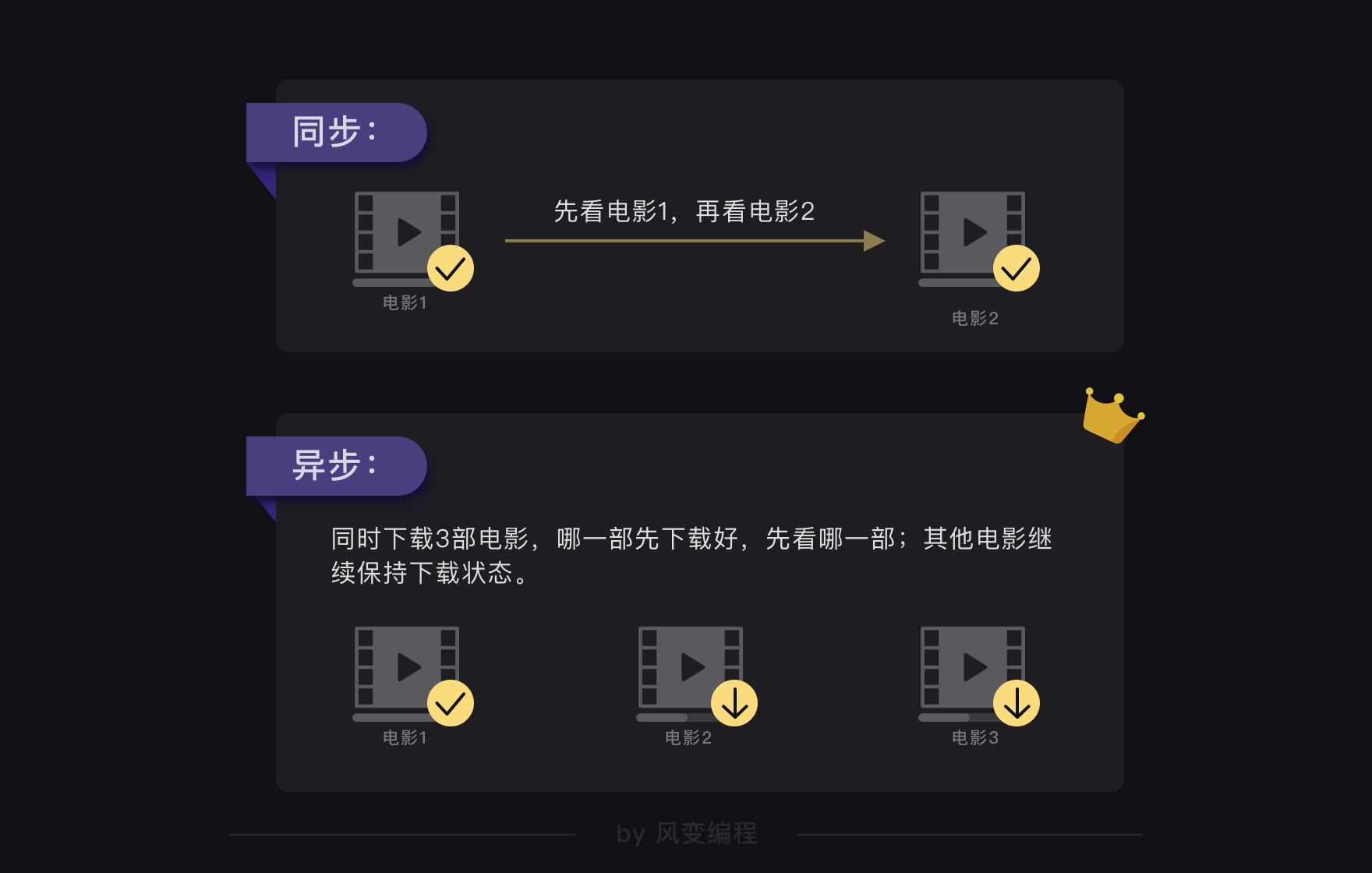
同步与异步是计算机里的概念,如果把这个概念迁移到网络爬虫的场景中,那前面讲的爬虫方式都是同步的
爬虫每发起一个请求,都要等服务器返回响应后,才会执行下一步。而很多时候,由于网络不稳定,加上服务器自身也需要响应的时间,导致爬虫会浪费大量时间在等待上。这也是爬取大量数据时,爬虫的速度会比较慢的原因
那是不是可以采取异步的爬虫方式,让多个爬虫在执行任务时保持相对独立,彼此不受干扰,这样不就可以免去等待时间?显然这样爬虫的效率和速度都会提高
一点点计算机的历史小知识:每台计算机都靠着CPU(中央处理器)干活。在过去,单核CPU的计算机在处理多任务时,会出现一个问题:每个任务都要抢占CPU,执行完了一个任务才开启下一个任务。CPU毕竟只有一个,这会让计算机处理的效率很低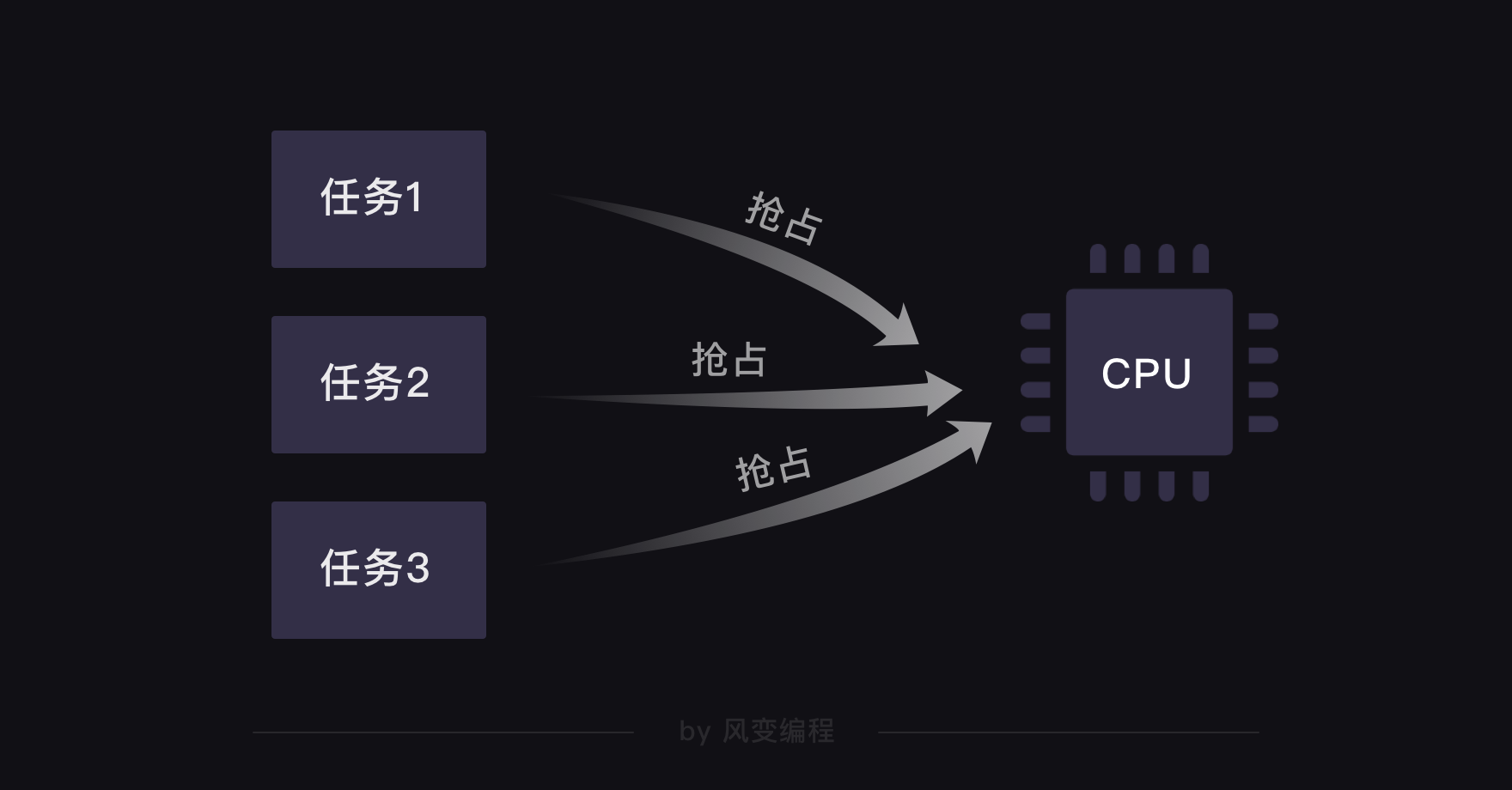
为了解决这样的问题,一种非抢占式的异步技术被创造了出来,这种方式叫多协程
多协程,是一种非抢占式的异步方式。使用多协程的话,就能让多个爬取任务用异步的方式交替执行
它的原理是:一个任务在执行过程中,如果遇到等待,就先去执行其他的任务,当等待结束,再回来继续之前的那个任务。在计算机的世界,这种任务来回切换得非常快速,看上去就像多个任务在被同时执行一样
所以,要实现异步的爬虫方式的话,需要用到多协程。在它的帮助下,能实现前面提到的“让多个爬虫干活”
1. gevent库
先用同步的爬虫方式爬取百度、新浪、搜狐、腾讯、网易、爱奇艺、天猫、凤凰这个8个网站,看下用了多长时间↓
import requests import time # 导入requests和time start = time.time() # 记录程序开始时间 url_list = ['https://www.baidu.com/', 'https://www.sina.com.cn/', 'http://www.sohu.com/', 'https://www.qq.com/', 'https://www.163.com/', 'http://www.iqiyi.com/', 'https://www.tmall.com/', 'http://www.ifeng.com/'] # 把8个网站封装成列表 for url in url_list: # 遍历url_list r = requests.get(url) # 用requests.get()函数爬取网站 print(url, r.status_code) # 打印网址和抓取请求的状态码 end = time.time() # 记录程序结束时间 print(end-start) # end-start是结束时间减去开始时间,就是最终所花时间 # 最后,把时间打印出来 # 》》https://www.baidu.com/ 200 # 》》https://www.sina.com.cn/ 200 # 》》http://www.sohu.com/ 200 # 》》https://www.qq.com/ 200 # 》》https://www.163.com/ 200 # 》》http://www.iqiyi.com/ 200 # 》》https://www.tmall.com/ 200 # 》》http://www.ifeng.com/ 200 # 》》0.5697987079620361
同步的爬虫方式,是依次爬取网站,并等待服务器响应(状态码为200表示正常响应)后,才爬取下一个网站。比如第一个先爬取了百度的网址,等服务器响应后,再去爬取新浪的网址,以此类推,直至全部爬取完毕。再看看用多协程gevent库需要先安装,mac电脑在终端输入:pip3 install gevent
from gevent import monkey # 从gevent库里导入monkey模块 monkey.patch_all() # monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步 import gevent,time,requests # 导入gevent、time、requests start = time.time() # 记录程序开始时间 url_list = ['https://www.baidu.com/', 'https://www.sina.com.cn/', 'http://www.sohu.com/', 'https://www.qq.com/', 'https://www.163.com/', 'http://www.iqiyi.com/', 'https://www.tmall.com/', 'http://www.ifeng.com/'] # 把8个网站封装成列表。 def crawler(url): # 定义一个crawler()函数 r = requests.get(url) # 用requests.get()函数爬取网站 print(url, time.time()-start, r.status_code) # 打印网址、请求运行时间、状态码 tasks_list = [] # 创建空的任务列表 for url in url_list: # 遍历url_list task = gevent.spawn(crawler, url) # 用gevent.spawn()函数创建任务 tasks_list.append(task) # 往任务列表添加任务 gevent.joinall(tasks_list) # 执行任务列表里的所有任务,就是让爬虫开始爬取网站 end = time.time() # 记录程序结束时间 print(end-start) # 打印程序最终所需时间 # 》》http://www.ifeng.com/ 0.08891010284423828 200 # 》》https://www.baidu.com/ 0.1046142578125 200 # 》》https://www.sina.com.cn/ 0.12417197227478027 200 # 》》https://www.163.com/ 0.12881922721862793 200 # 》》https://www.qq.com/ 0.1435079574584961 200 # 》》http://www.sohu.com/ 0.1657421588897705 200 # 》》https://www.tmall.com/ 0.18058228492736816 200 # 》》http://www.iqiyi.com/ 0.18367409706115723 200 # 》》0.18380022048950195
程序运行后,打印出了网址、每个请求运行的时间、状态码和爬取8个网站最终所用时间
通过每个请求运行的时间能知道:爬虫用了异步的方式抓取了8个网站,因为每个请求完成的时间并不是按着顺序来的。比如这次运行最先爬取到的网站是凤凰,接着是百度,并不是百度和新浪
且每个请求完成时间之间的间隔都非常短,可以看作这些请求几乎是“同时”发起的
通过对比同步和异步爬取最终所花的时间,用多协程异步的爬取方式,确实比同步的爬虫方式速度更快
其实,案例爬取的数据量还比较小,不能直接体现出更大的速度差异。如果爬的是大量的数据,运用多协程会有更显著的速度优势
下面具体解释一下多协程的代码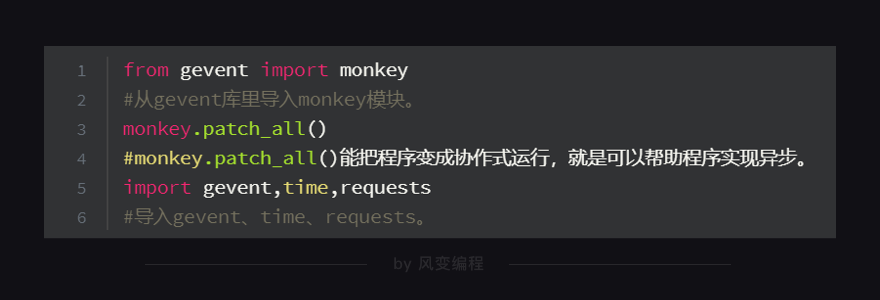
第1、3行代码:从gevent库里导入了monkey模块,这个模块能将程序转换成可异步的程序。monkey.patch_all(),它的作用其实就像电脑有时会弹出“是否要用补丁修补漏洞或更新”一样。它能给程序打上补丁,让程序变成是异步模式,而不是同步模式。它也叫“猴子补丁”
要在导入其他库和模块前,先把monkey模块导入进来,并运行monkey.patch_all()。这样,才能先给程序打上补丁。也可以理解成这是一个规范的写法
第5行代码:导入了gevent库来实现多协程,导入了time模块来记录爬取所需时间,导入了requests模块实现爬取8个网站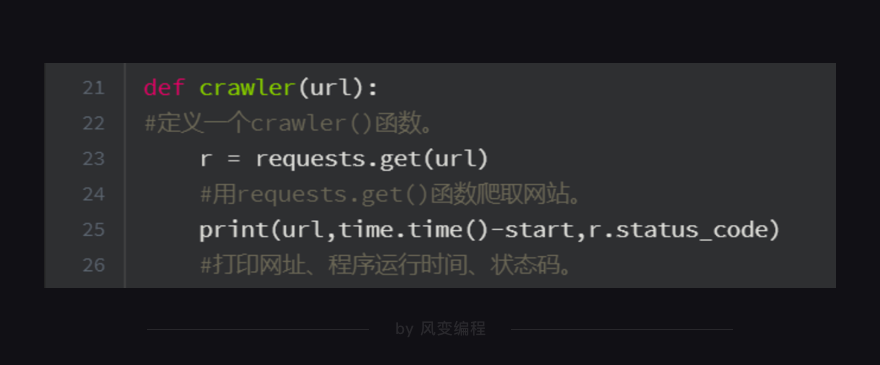
第21、23、25行代码:定义了一个crawler函数,只要调用这个函数,它就会执行【用requests.get()爬取网站】和【打印网址、请求运行时间、状态码】这两个任务
第33行代码:因为gevent只能处理gevent的任务对象,不能直接调用普通函数,所以需要借助gevent.spawn()来创建任务对象
这里需要注意一点:gevent.spawn()的参数需为要调用的函数名及该函数的参数。比如,gevent.spawn(crawler,url)就是创建一个执行crawler函数的任务,参数为crawler函数名和它自身的参数url
第35行代码:用append函数把任务添加到tasks_list的任务列表里
第37行代码:调用gevent库里的gevent.joinall()方法,能启动执行所有的任务。gevent.joinall(tasks_list)就是执行tasks_list这个任务列表里的所有任务,开始爬取
总结一下用gevent实现多协程爬取的重点↓
如果要爬的不是8个网站,而是1000个网站,可以怎么做?
用gevent.spawn()创建1000个爬取任务,再用gevent.joinall()执行这1000个任务
这种方法会有问题:执行1000个任务,就是一下子发起1000次请求,这样子的恶意请求,会拖垮网站的服务器
既然直接创建1000个任务的方式不可取,那创建5个任务,每个任务爬取200个网站
这么做也是会有问题的:就算用gevent.spawn()创建了5个分别执行爬取200个网站的任务,这5个任务之间是异步执行的,但是每个任务(爬取200个网站)内部是同步的。这意味着如果有一个任务在执行的过程中,它要爬取的一个网站一直在等待响应,哪怕其他任务都完成了200个网站的爬取,它也还是不能完成200个网站的爬取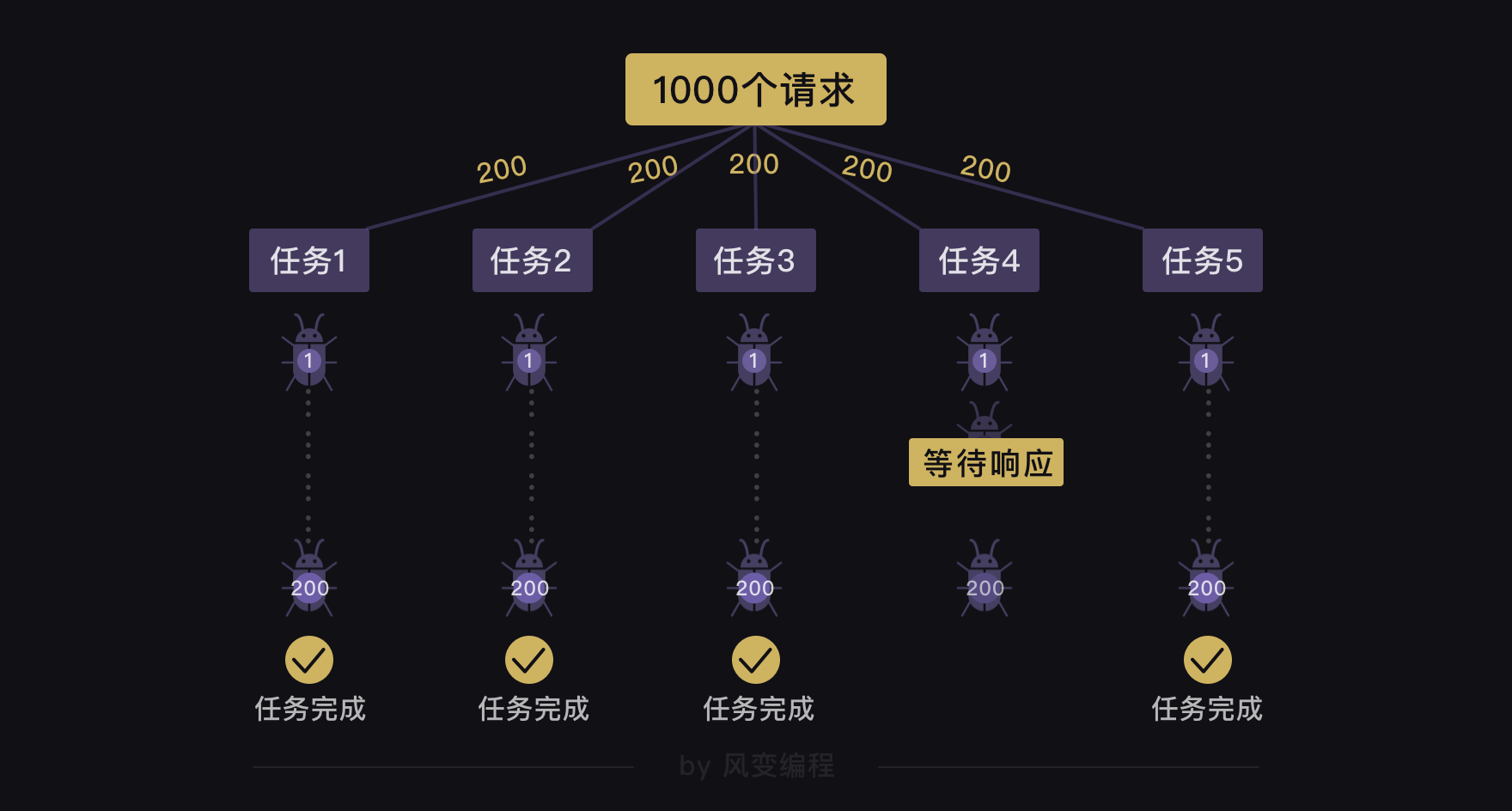
银行是怎么在一天内办理1000个客户的业务的,银行会开设办理业务的多个窗口,让客户取号排队,由银行的叫号系统分配客户到不同的窗口去办理业务
在gevent库中,也有一个模块可以实现这种功能——queue模块
2. queue模块
当用多协程来爬虫,需要创建大量任务时,可以借助queue模块queue翻译成中文是队列的意思。可以用queue模块来存储任务,让任务都变成一条整齐的队列,就像银行窗口的排号做法。因为queue其实是一种有序的数据结构,可以用来存取数据
这样,协程就可以从队列里把任务提取出来执行,直到队列空了,任务也就处理完了。就像银行窗口的工作人员会根据排号系统里的排号,处理客人的业务,如果已经没有新的排号,就意味着客户的业务都已办理完毕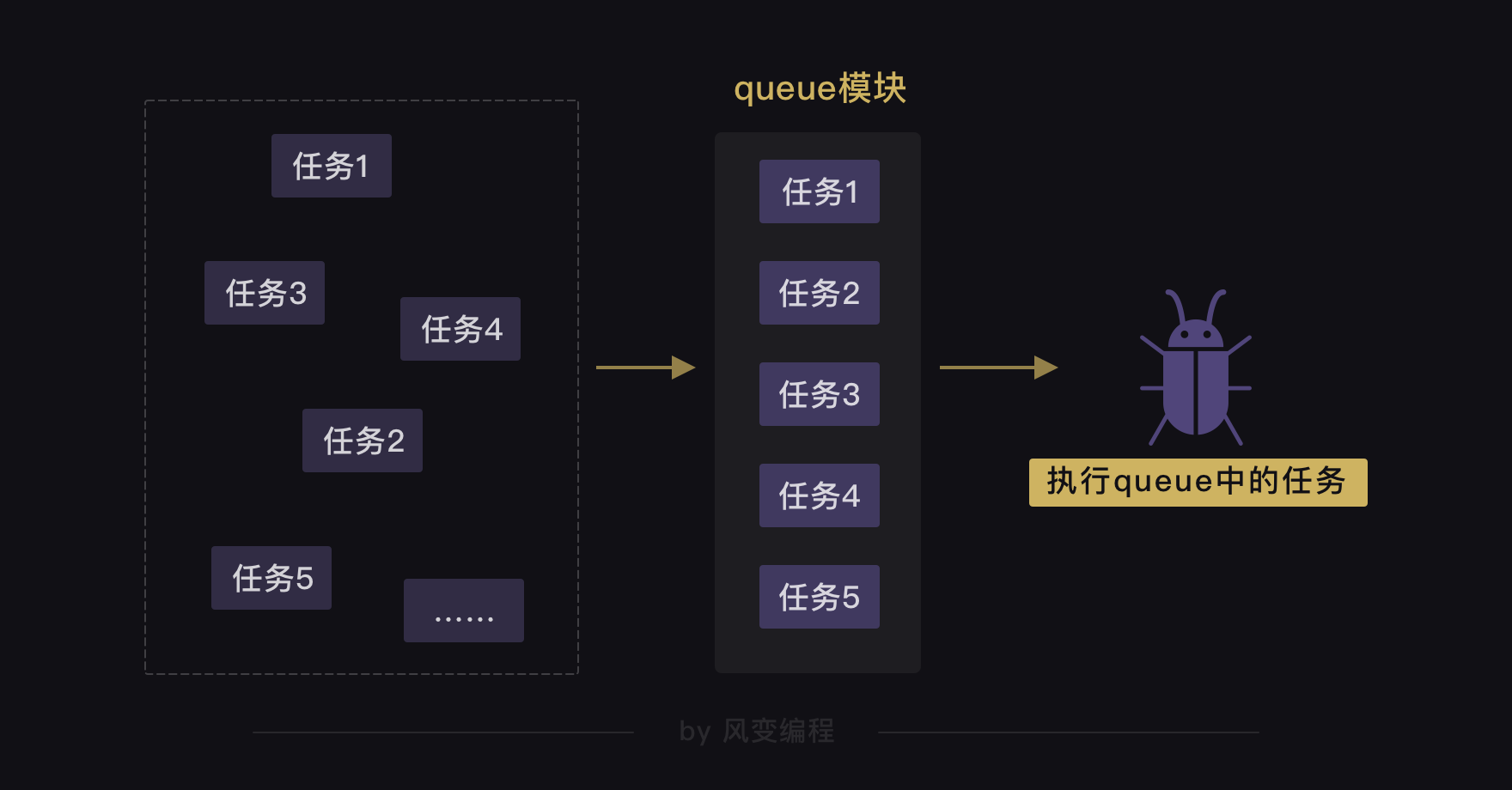
依旧是爬取刚才的8个网站
from gevent import monkey monkey.patch_all() import gevent,time,requests from gevent.queue import Queue # 从gevent库的queue模块导入Queue类 start = time.time() url_list = ['https://www.baidu.com/', 'https://www.sina.com.cn/', 'http://www.sohu.com/', 'https://www.qq.com/', 'https://www.163.com/', 'http://www.iqiyi.com/', 'https://www.tmall.com/', 'http://www.ifeng.com/'] work = Queue() # 创建队列对象,并赋值给work for url in url_list: work.put_nowait(url) # 用put_nowait()函数可以把网址都放进队列里 def crawler(): while not work.empty(): # 当队列不是空的时候,就执行下面的程序 url = work.get_nowait() # 用get_nowait()函数可以把队列里的网址都取出 r = requests.get(url) # 用requests.get()函数抓取网址 print(url, work.qsize(), r.status_code) # 打印网址、队列长度、抓取请求的状态码 tasks_list = [] for x in range(2): # 相当于创建了2个爬虫 task = gevent.spawn(crawler) # 用gevent.spawn()函数创建执行crawler()函数的任务 tasks_list.append(task) gevent.joinall(tasks_list) end = time.time() print(end-start) # 》》https://www.baidu.com/ 6 200 # 》》https://www.sina.com.cn/ 5 200 # 》》http://www.sohu.com/ 4 200 # 》》https://www.163.com/ 3 200 # 》》https://www.qq.com/ 2 200 # 》》http://www.iqiyi.com/ 1 200 # 》》http://www.ifeng.com/ 0 200 # 》》https://www.tmall.com/ 0 200 # 》》0.3898591995239258
运行程序后,打印的网址后面的数字指的是队列里还剩的任务数,比如第一个网址后面的数字6,就是此时队列里还剩6个抓取其他网址的任务
用Queue()创建的对象,相当于创建了一个不限任何存储数量的空队列。如果往Queue()中传入参数,比如Queue(10),则表示这个队列只能存储10个任务
创建了Queue对象后,就能调用这个对象的put_nowait()方法,把每个网址都存储进刚刚建立好的空队列里
work.put_nowait(url)这行代码就是把遍历的8个网站,都存储进队列里empty()方法,是用来判断队列是不是空了的;get_nowait()方法,是用来从队列里提取数据的;qsize()方法,是用来判断队列里还剩多少数量的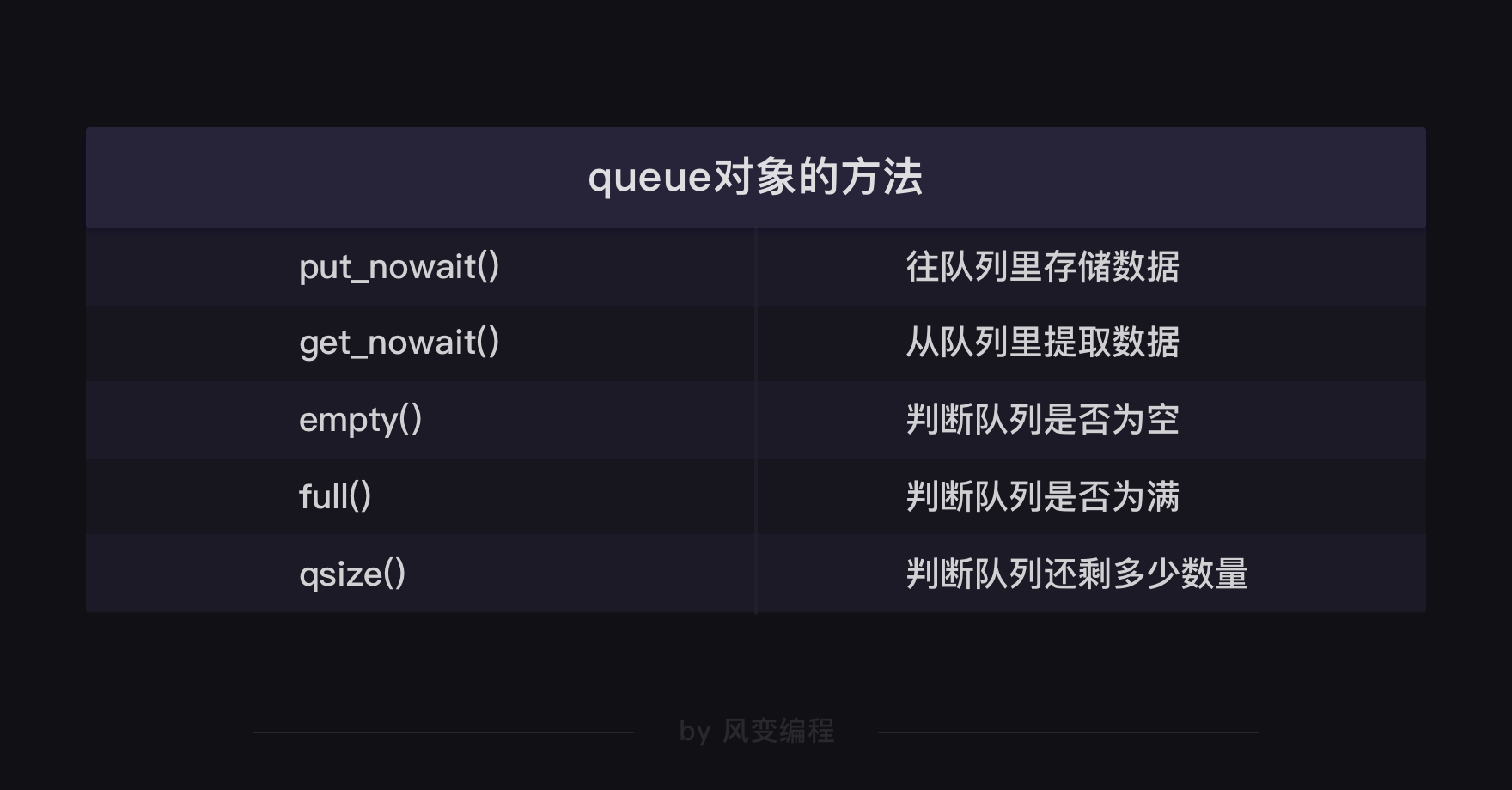
queue模块的重点内容就是队列怎么创建、数据怎么存储进队列,以及怎么从队列里提取出的数据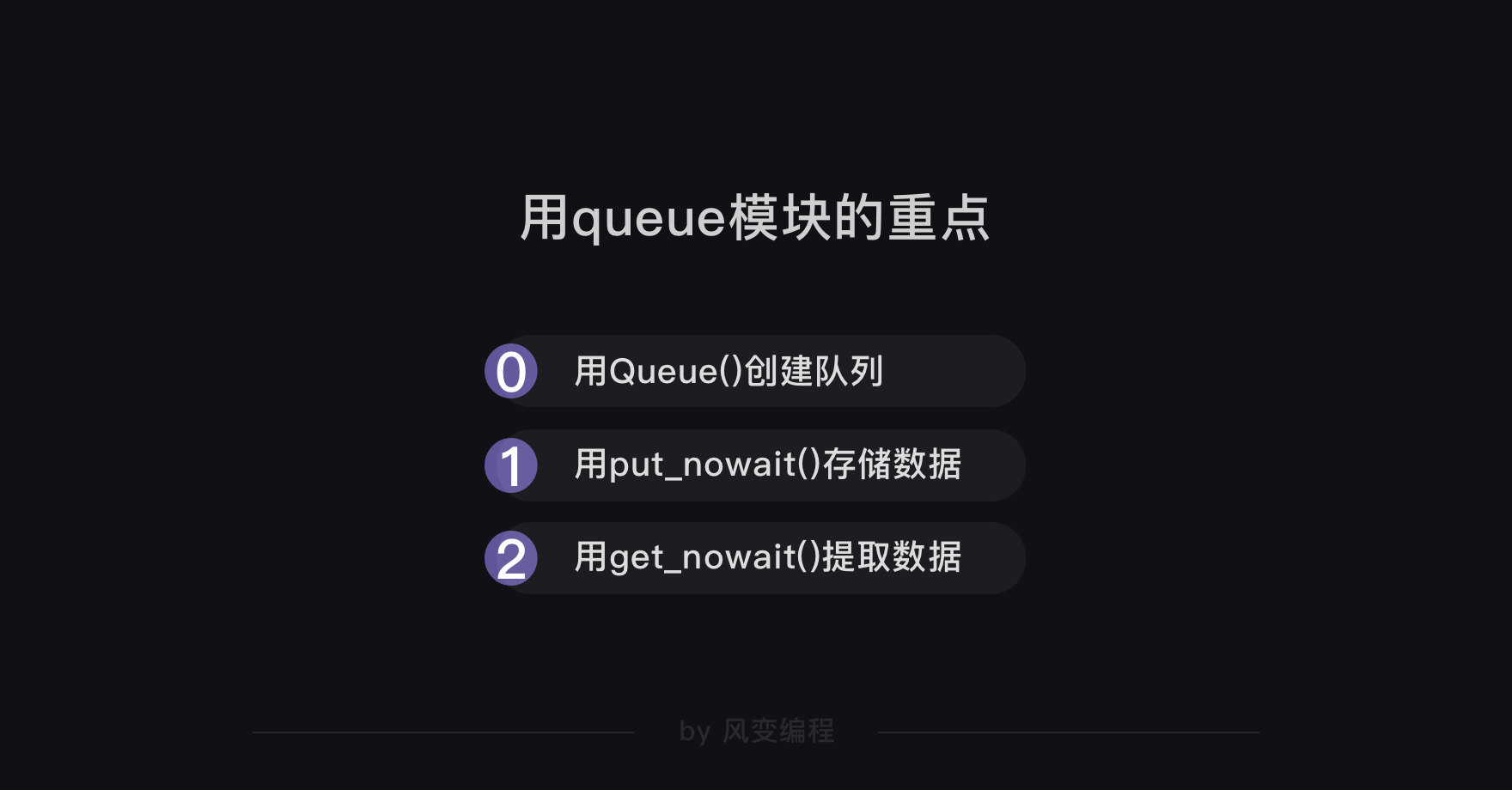
然后创建了两只可以异步爬取的爬虫。它们会从队列里取走网址,执行爬取任务。一旦一个网址被一只爬虫取走,另一只爬虫就取不到了,另一只爬虫就会取走下一个网址。直至所有网址都被取走,队列为空时,爬虫就停止工作
继续说计算机历史小知识:在后来,CPU从单核终于进化到了多核,每个核都能够独立运作。计算机开始能够真正意义上同时执行多个任务(术语叫并行执行),而不是在多个任务之间来回切换(术语叫并发执行)
比如现在打开浏览器看着网页的同时,可以打开音乐播放器听歌,还可以打开Excel。对于多核CPU而言,这些任务就都是同时运行的
时至今日,电脑一般都会是多核CPU。多协程,其实只占用了CPU的一个核运行,没有充分利用到其他核。利用CPU的多个核同时执行任务的技术,把它叫做“多进程”
所以,真正大型的爬虫程序不会单单只靠多协程来提升爬取速度的。比如,百度搜索引擎,可以说是超大型的爬虫程序,它除了靠多协程,一定还会靠多进程,甚至是分布式爬虫
第12关 协程实践
项目:用多协程爬取薄荷网的食物热量
任何完成项目的过程,都是由以下三步构成的↓
1. 明确目标
用多协程爬取薄荷网11个常见食物分类里的食物信息(包含食物名、热量、食物详情页面链接)
2. 分析过程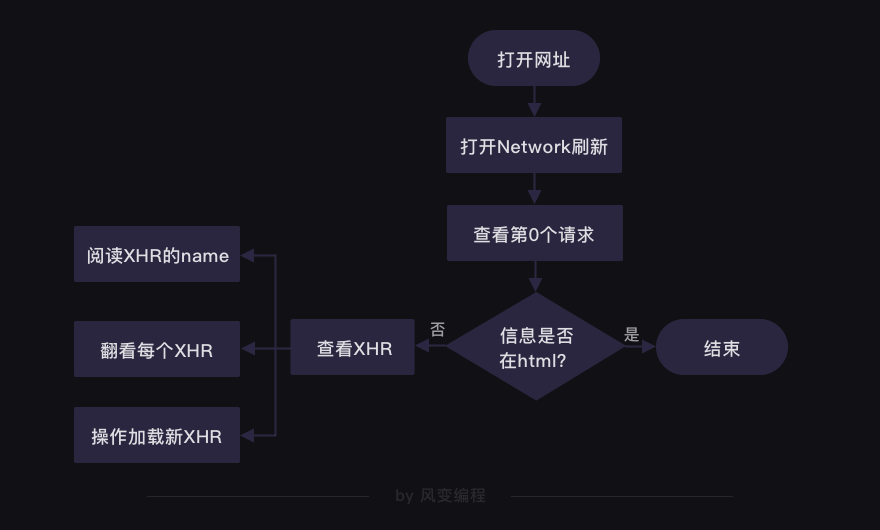
按照上图方法,得知想要的数据直接存在HTML里
再看第0个请求的Headers,可以发现薄荷网的网页请求方式是get
经过分析可以得出薄荷网每个食物类别的每一页食物记录的网址规律↓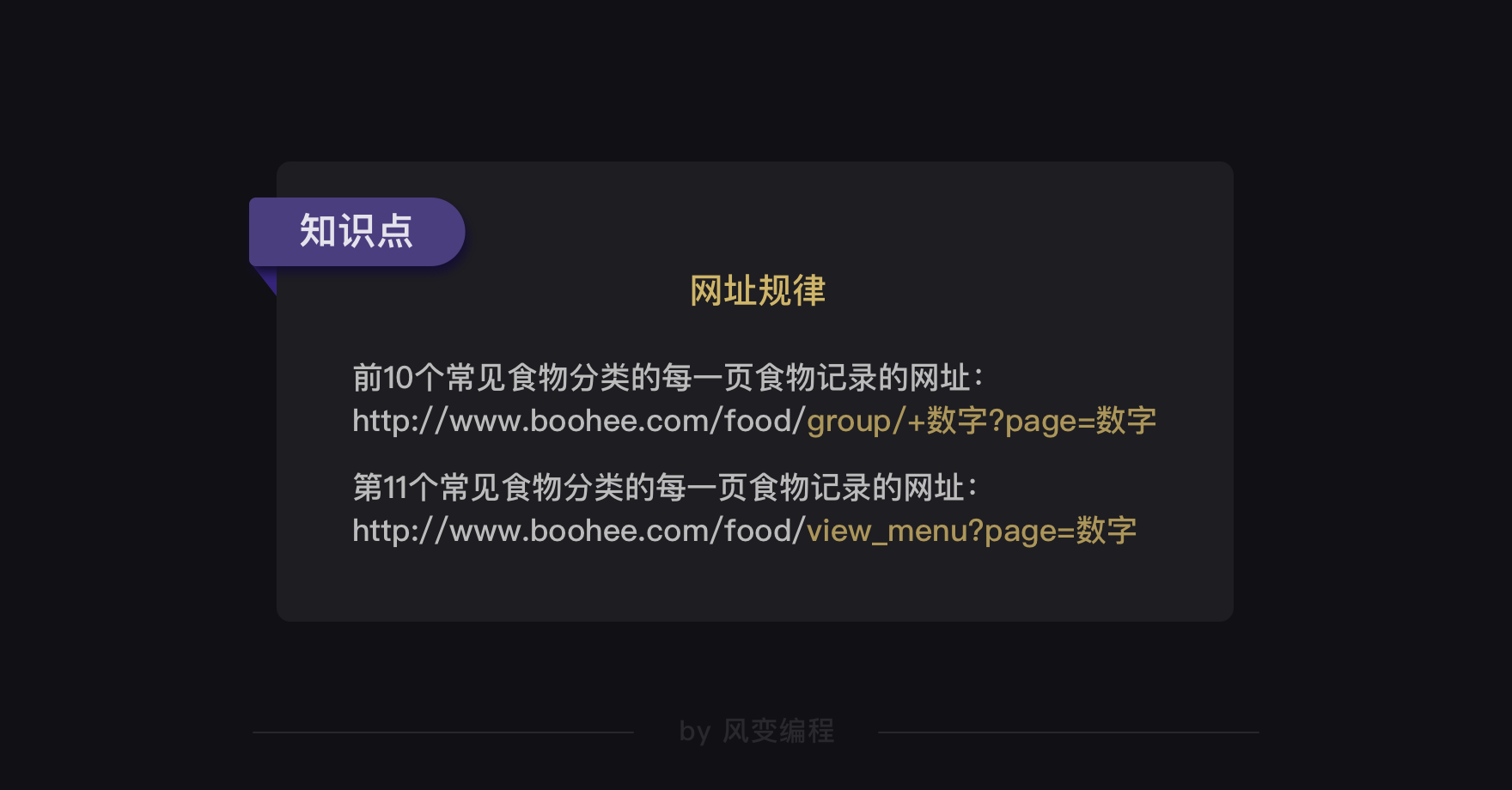
然后在<li class="item clearfix">元素下,找到了食物的信息,包括食物详情的链接、食物名和热量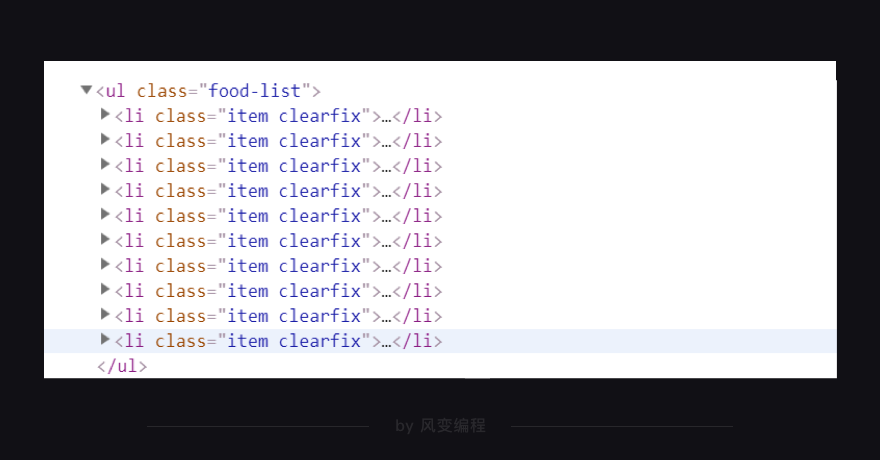
总结一下分析得出的思路↓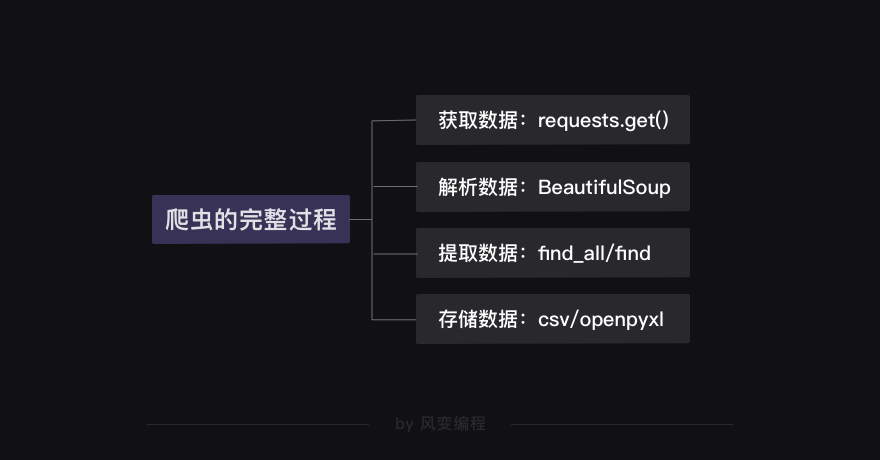
3. 代码实现
这里仅展示前3个常见食物分类的前3页和第11个常见食物分类的前3页的食物信息
# 导入所需的库和模块 from gevent import monkey monkey.patch_all() # 让程序变成异步模式 import gevent,requests, bs4, csv from gevent.queue import Queue work = Queue() # 创建队列对象,并赋值给work # 前3个常见食物分类的前3页的食物记录的网址 url_1 = 'http://www.boohee.com/food/group/{type}?page={page}' for x in range(1, 4): for y in range(1, 4): real_url = url_1.format(type=x, page=y) work.put_nowait(real_url) # 通过两个for循环,能设置分类的数字和页数的数字 # 然后,把构造好的网址用put_nowait方法添加进队列里 # 第11个常见食物分类的前3页的食物记录的网址 url_2 = 'http://www.boohee.com/food/view_menu?page={page}' for x in range(1, 4): real_url = url_2.format(page=x) work.put_nowait(real_url) # 通过for循环,能设置第11个常见食物分类的食物的页数 # 然后,把构造好的网址用put_nowait方法添加进队列里 def crawler(): # 定义crawler函数 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36' } # 添加请求头 while not work.empty(): # 当队列不是空的时候,就执行下面的程序 url = work.get_nowait() # 用get_nowait()方法从队列里把刚刚放入的网址提取出来 res = requests.get(url, headers=headers) # 用requests.get获取网页源代码 bs_res = bs4.BeautifulSoup(res.text, 'html.parser') # 用BeautifulSoup解析网页源代码 foods = bs_res.find_all('li', class_='item clearfix') # 用find_all提取出<li class="item clearfix">标签的内容 for food in foods: # 遍历foods food_name = food.find_all('a')[1]['title'] # 用find_all在<li class="item clearfix">标签下,提取出第2个<a>元素title属性的值,也就是食物名称 food_url = 'http://www.boohee.com' + food.find_all('a')[1]['href'] # 用find_all在<li class="item clearfix">元素下,提取出第2个<a>元素href属性的值,跟'http://www.boohee.com'组合在一起,就是食物详情页的链接 food_calorie = food.find('p').text # 用find在<li class="item clearfix">标签下,提取<p>元素,再用text方法留下纯文本,也提取出了食物的热量 writer.writerow([food_name, food_calorie, food_url]) # 借助writerow()函数,把提取到的数据:食物名称、食物热量、食物详情链接,写入csv文件 print(food_name) # 打印食物的名称 csv_file = open('boohee.csv', 'w', newline='') # 调用open()函数打开csv文件,传入参数:文件名“boohee.csv”、写入模式“w”、newline='' writer = csv.writer(csv_file) # 用csv.writer()函数创建一个writer对象 writer.writerow(['食物', '热量', '链接']) # 借助writerow()函数往csv文件里写入文字:食物、热量、链接 tasks_list = [] # 创建空的任务列表 for x in range(5): # 相当于创建了5个爬虫 task = gevent.spawn(crawler) # 用gevent.spawn()函数创建执行crawler()函数的任务 tasks_list.append(task) # 往任务列表添加任务 gevent.joinall(tasks_list) # 用gevent.joinall方法,启动协程,执行任务列表里的所有任务,让爬虫开始爬取网站
第13关 Scrapy框架
之前写的爬虫,要导入和操作不同的模块,比如requests模块、gevent库、csv模块等。而在Scrapy里,不需要这么做,因为很多爬虫需要涉及的功能,比如麻烦的异步,在Scrapy框架都自动实现了
之前编写爬虫的方式,相当于在一个个地在拼零件,拼成一辆能跑的车。而Scrapy框架则是已经造好的、现成的车,只要踩下它的油门,它就能跑起来。这样便节省了开发项目的时间
1. Scrapy的结构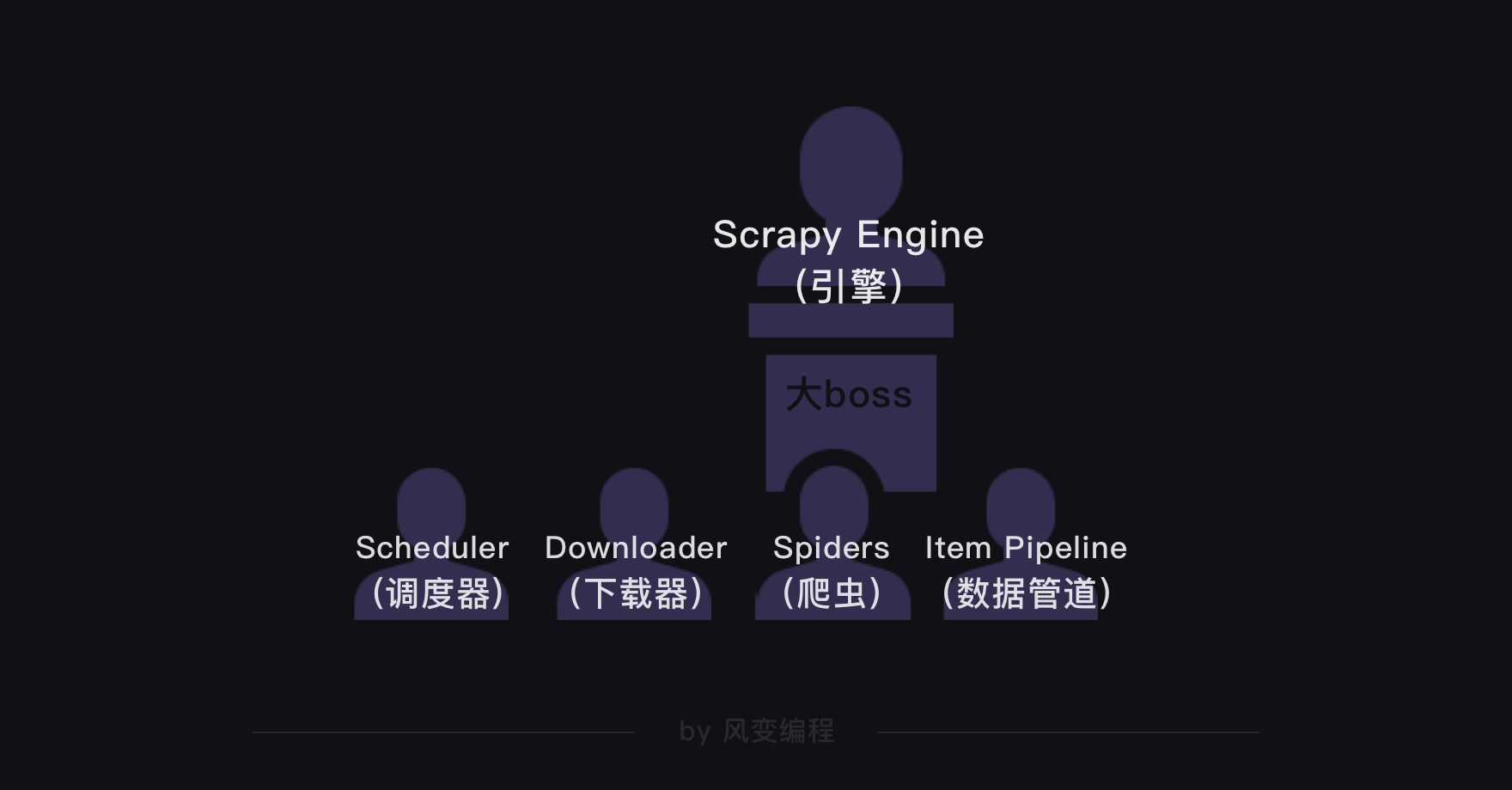
上面的这张图是Scrapy的整个结构。可以把整个Scrapy框架看成是一家爬虫公司。最中心位置的Scrapy Engine(引擎)就是这家爬虫公司的大boss,负责统筹公司的4大部门,每个部门都只听从它的命令,并只向它汇报工作Scheduler(调度器)部门主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)Downloader(下载器)部门则是负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程【获取数据】这一步Spiders(爬虫)部门是公司的核心业务部门,主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程【解析数据】和【提取数据】这两步Item Pipeline(数据管道)部门则是公司的数据部门,只负责存储和处理Spiders部门提取到的有用数据。这个对应的是爬虫流程【存储数据】这一步Downloader Middlewares(下载中间件)的工作相当于下载器部门的秘书,比如会提前对引擎大boss发送的诸多requests做出处理Spider Middlewares(爬虫中间件)的工作则相当于爬虫部门的秘书,比如会提前接收并处理引擎大boss发送来的response,过滤掉一些重复无用的东西
2. Scrapy的工作原理
Scrapy框架的工作原理——引擎是中心,其他组成部分由引擎调度
在Scrapy里,整个爬虫程序的流程都不需要我们去操心,且Scrapy中的程序全部都是异步模式,所有的请求或返回的响应都由引擎自动分配去处理
哪怕有某个请求出现异常,程序也会做异常处理,跳过报错的请求,继续往下运行程序
在一定程度上,Scrapy可以说是非常让人省心的一套爬虫框架
3. Scrapy的用法-创建项目
Scrapy需要安装,mac电脑在终端输入命令:pip3 install scrapy
记录一下安装过程↓
Collecting scrapy Downloading Scrapy-2.0.1-py2.py3-none-any.whl (242 kB) |████████████████████████████████| 242 kB 341 kB/s Collecting zope.interface>=4.1.3 Downloading zope.interface-5.0.2-cp38-cp38-macosx_10_9_x86_64.whl (184 kB) |████████████████████████████████| 184 kB 875 kB/s Collecting lxml>=3.5.0 Downloading lxml-4.5.0-cp38-cp38-macosx_10_9_x86_64.whl (4.6 MB) |████████████████████████████████| 4.6 MB 626 kB/s Collecting parsel>=1.5.0 Downloading parsel-1.5.2-py2.py3-none-any.whl (12 kB) Collecting pyOpenSSL>=16.2.0 Downloading pyOpenSSL-19.1.0-py2.py3-none-any.whl (53 kB) |████████████████████████████████| 53 kB 4.8 MB/s Collecting cssselect>=0.9.1 Downloading cssselect-1.1.0-py2.py3-none-any.whl (16 kB) Collecting protego>=0.1.15 Downloading Protego-0.1.16.tar.gz (3.2 MB) |████████████████████████████████| 3.2 MB 520 kB/s Collecting Twisted>=17.9.0 Downloading Twisted-20.3.0.tar.bz2 (3.1 MB) |████████████████████████████████| 3.1 MB 626 kB/s Collecting queuelib>=1.4.2 Downloading queuelib-1.5.0-py2.py3-none-any.whl (13 kB) Collecting service-identity>=16.0.0 Downloading service_identity-18.1.0-py2.py3-none-any.whl (11 kB) Collecting PyDispatcher>=2.0.5 Downloading PyDispatcher-2.0.5.tar.gz (34 kB) Collecting w3lib>=1.17.0 Downloading w3lib-1.21.0-py2.py3-none-any.whl (20 kB) Collecting cryptography>=2.0 Downloading cryptography-2.9-cp35-abi3-macosx_10_9_intel.whl (1.7 MB) |████████████████████████████████| 1.7 MB 615 kB/s Requirement already satisfied: setuptools in /Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages (from zope.interface>=4.1.3->scrapy) (41.2.0) Collecting six>=1.5.2 Downloading six-1.14.0-py2.py3-none-any.whl (10 kB) Collecting constantly>=15.1 Downloading constantly-15.1.0-py2.py3-none-any.whl (7.9 kB) Collecting incremental>=16.10.1 Downloading incremental-17.5.0-py2.py3-none-any.whl (16 kB) Collecting Automat>=0.3.0 Downloading Automat-20.2.0-py2.py3-none-any.whl (31 kB) Collecting hyperlink>=17.1.1 Downloading hyperlink-19.0.0-py2.py3-none-any.whl (38 kB) Collecting PyHamcrest!=1.10.0,>=1.9.0 Downloading PyHamcrest-2.0.2-py3-none-any.whl (52 kB) |████████████████████████████████| 52 kB 1.9 MB/s Collecting attrs>=19.2.0 Downloading attrs-19.3.0-py2.py3-none-any.whl (39 kB) Collecting pyasn1-modules Downloading pyasn1_modules-0.2.8-py2.py3-none-any.whl (155 kB) |████████████████████████████████| 155 kB 506 kB/s Collecting pyasn1 Downloading pyasn1-0.4.8-py2.py3-none-any.whl (77 kB) |████████████████████████████████| 77 kB 778 kB/s Collecting cffi!=1.11.3,>=1.8 Downloading cffi-1.14.0-cp38-cp38-macosx_10_9_x86_64.whl (175 kB) |████████████████████████████████| 175 kB 972 kB/s Requirement already satisfied: idna>=2.5 in /Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages (from hyperlink>=17.1.1->Twisted>=17.9.0->scrapy) (2.8) Collecting pycparser Downloading pycparser-2.20-py2.py3-none-any.whl (112 kB) |████████████████████████████████| 112 kB 496 kB/s Installing collected packages: zope.interface, lxml, six, w3lib, cssselect, parsel, pycparser, cffi, cryptography, pyOpenSSL, protego, constantly, incremental, attrs, Automat, hyperlink, PyHamcrest, Twisted, queuelib, pyasn1, pyasn1-modules, service-identity, PyDispatcher, scrapy Running setup.py install for protego ... done Running setup.py install for Twisted ... done Running setup.py install for PyDispatcher ... done Successfully installed Automat-20.2.0 PyDispatcher-2.0.5 PyHamcrest-2.0.2 Twisted-20.3.0 attrs-19.3.0 cffi-1.14.0 constantly-15.1.0 cryptography-2.9 cssselect-1.1.0 hyperlink-19.0.0 incremental-17.5.0 lxml-4.5.0 parsel-1.5.2 protego-0.1.16 pyOpenSSL-19.1.0 pyasn1-0.4.8 pyasn1-modules-0.2.8 pycparser-2.20 queuelib-1.5.0 scrapy-2.0.1 service-identity-18.1.0 six-1.14.0 w3lib-1.21.0 zope.interface-5.0.2
下面通过Scrapy框架来爬取豆瓣Top250图书前三页书籍的信息,也就是爬取前75本书籍的信息(包含书名、出版信息和书籍评分)
豆瓣Top250图书的链接:https://book.douban.com/top250
首先在终端进入到想要保存项目的目录,输入一行创建Scrapy项目的命令:scrapy startproject douban,douban就是Scrapy项目的名字。按下enter键,一个Scrapy项目就创建成功了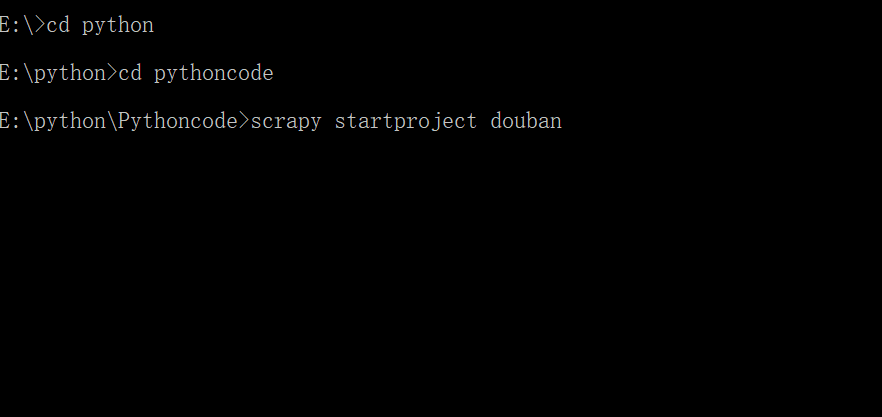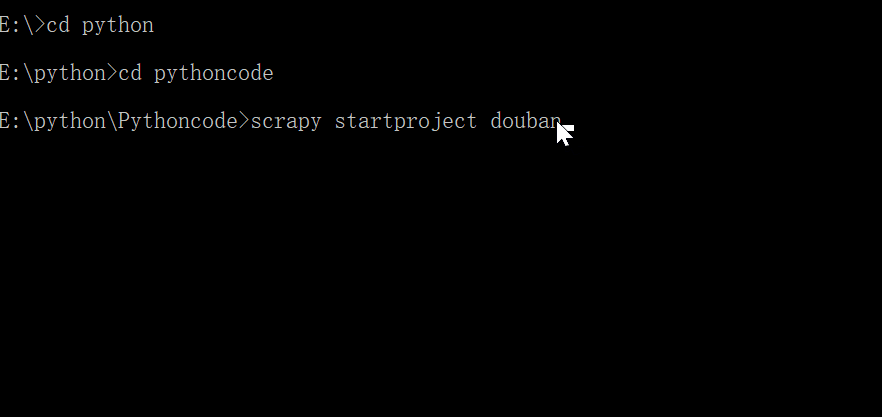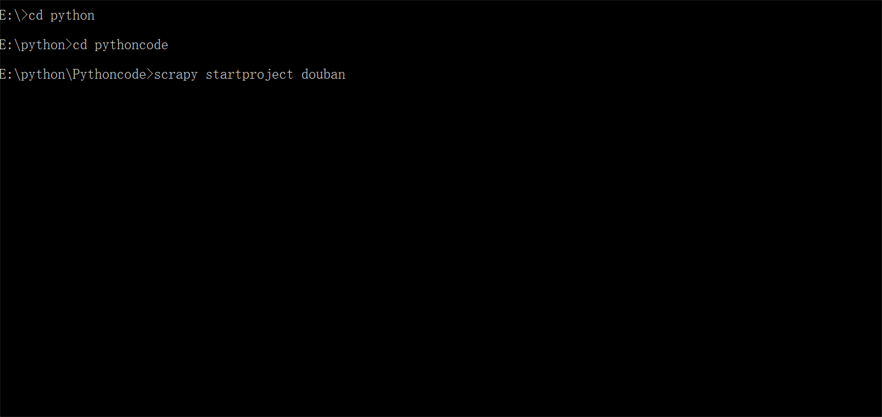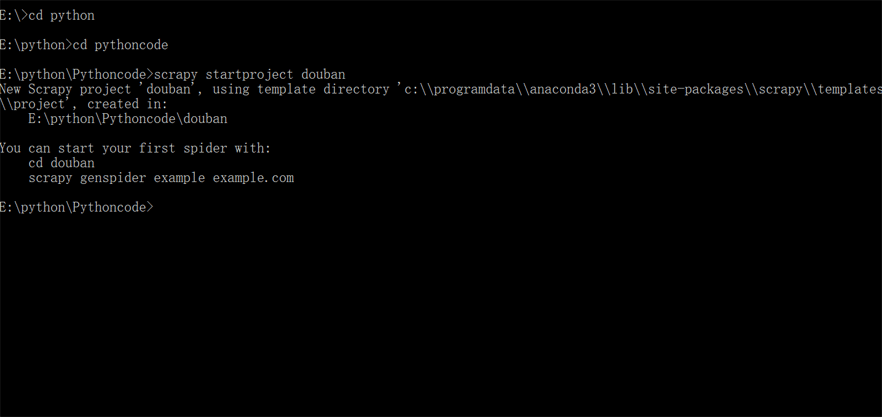
整个scrapy项目的结构,如下图所示↓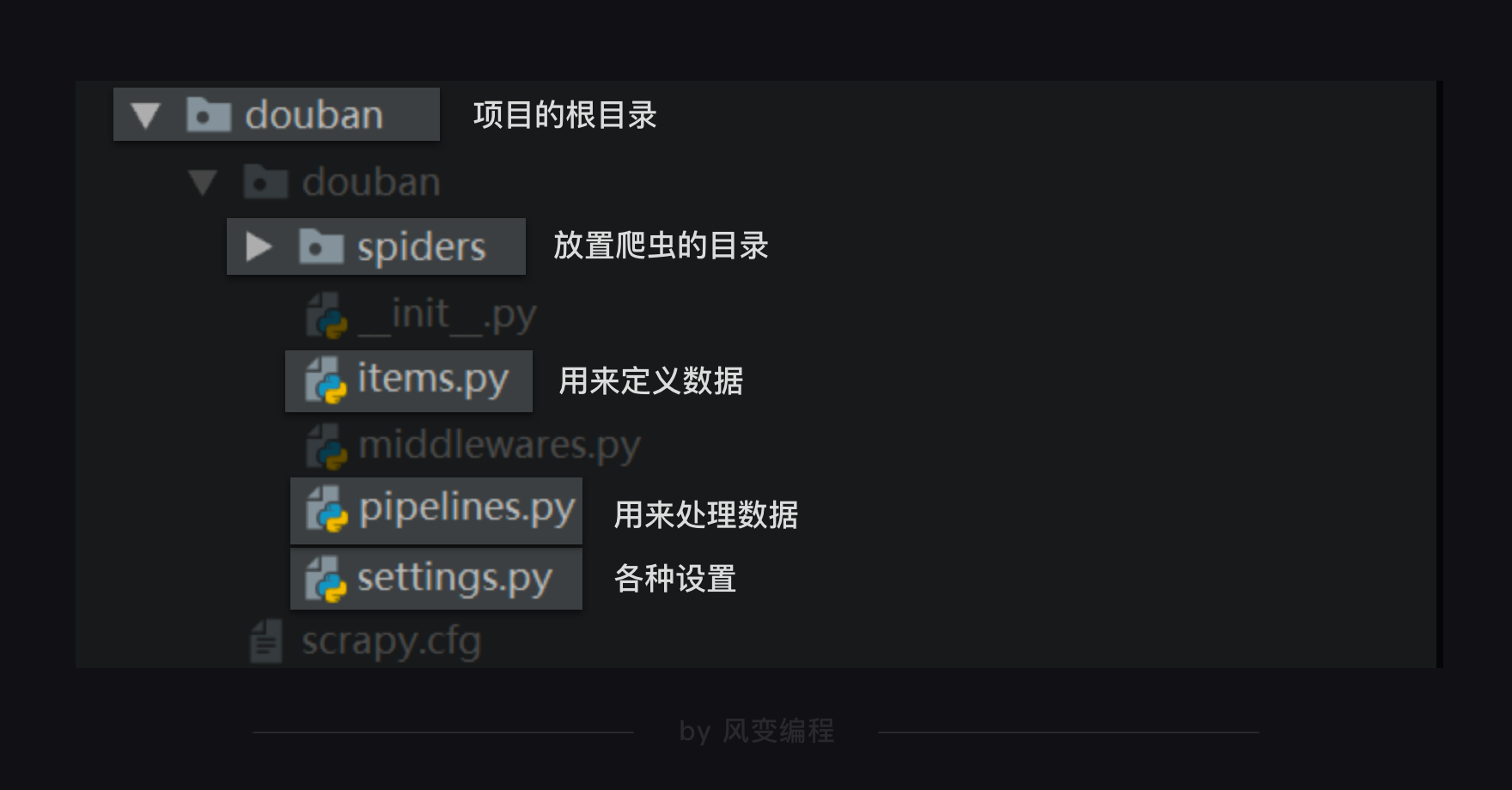
Scrapy项目里每个文件都有特定的功能,比如settings.py是scrapy里的各种设置,items.py是用来定义数据的,pipelines.py是用来处理数据的,它们对应的就是Scrapy的结构中的Item Pipeline(数据管道)
4. Scrapy的用法-编辑爬虫
可以在spiders这个文件夹里创建爬虫文件,这个文件命名为top250。后面的大部分代码都需要在这个top250.py文件里编写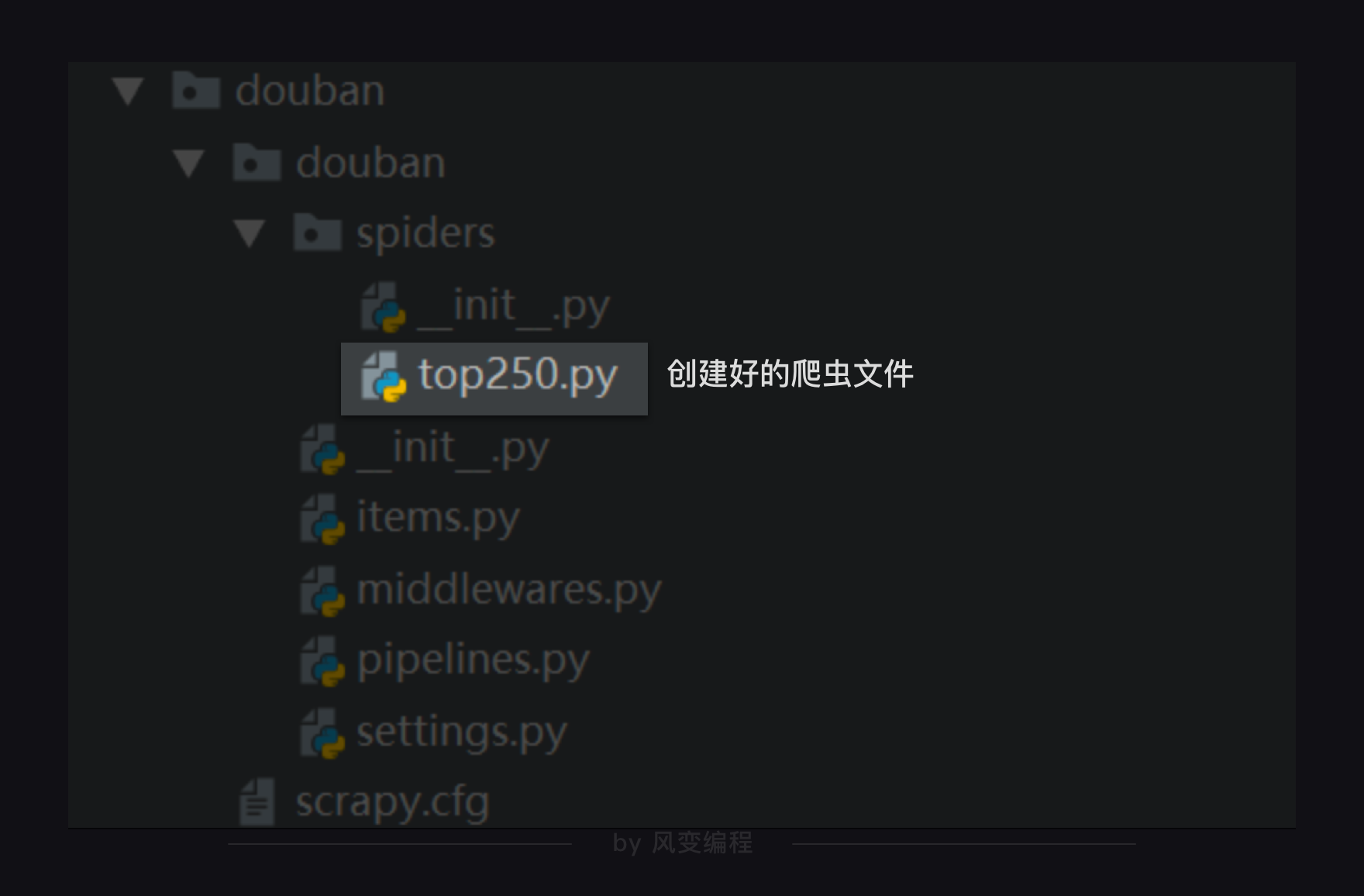
先在top250.py文件里导入需要的模块
import scrapy import bs4
导入scrapy是待会要用创建类的方式写这个爬虫,所创建的类将直接继承scrapy中的scrapy.Spider类。这样,有许多好用属性和方法,就能够直接使用
在Scrapy中,每个爬虫的代码结构基本都如下所示↓
class DoubanSpider(scrapy.Spider): name = 'douban' allowed_domains = ['book.douban.com'] start_urls = ['https://book.douban.com/top250?start=0'] def parse(self, response): print(response.text)
定义一个爬虫类DoubanSpider,继承自scrapy.Spider类name是定义爬虫的名字,这个名字是爬虫的唯一标识。name='douban'意思是定义爬虫的名字为douban。等会启动爬虫的时候,要用到这个名字allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。如果网址的域名不在这个列表里,就会被过滤掉
当在爬取大量数据时,经常是从一个URL开始爬取,然后关联爬取更多的网页。比如,假设这个爬虫目标不是爬书籍信息,而是要爬豆瓣图书top250的书评,就会先爬取书单,再找到每本书的URL,再进入每本书的详情页面去抓取评论,allowed_domains就限制了这种关联爬取的URL一定在book.douban.com这个域名之下,不会跳转到某个奇怪的广告页面start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。在此,allowed_domains的设定对start_urls里的网址不会有影响parse是Scrapy里默认处理response的一个方法,中文是解析
把豆瓣Top250图书前3页网址塞进start_urls的列表里,完善后的代码如下↓
class DoubanSpider(scrapy.Spider): name = 'douban' allowed_domains = ['book.douban.com'] start_urls = [] for x in range(3): url = 'https://book.douban.com/top250?start=' + str(x * 25) start_urls.append(url)
接下来,只要再借助parse方法处理response,借助BeautifulSoup来取出想要的书籍信息的数据,代码即可完成
按照过去的知识,可能会把代码写成这个模样↓
import scrapy import bs4 from ..items import DoubanItem class DoubanSpider(scrapy.Spider): # 定义一个爬虫类DoubanSpider。 name = 'douban' # 定义爬虫的名字为douban。 allowed_domains = ['book.douban.com'] # 定义爬虫爬取网址的域名。 start_urls = [] # 定义起始网址。 for x in range(3): url = 'https://book.douban.com/top250?start=' + str(x * 25) start_urls.append(url) # 把豆瓣Top250图书的前3页网址添加进start_urls。 def parse(self, response): # parse是默认处理response的方法。 bs = bs4.BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析response。 datas = bs.find_all('tr', class_="item") # 用find_all提取<tr class="item">元素,这个元素里含有书籍信息。 for data in datas: # 遍历data。 title = data.find_all('a')[1]['title'] # 提取出书名。 publish = data.find('p', class_='pl').text # 提取出出版信息。 score = data.find('span', class_='rating_nums').text # 提取出评分。 print([title, publish, score]) # 打印上述信息。
按照过去,会把书名、出版信息、评分,分别赋值,然后统一做处理——或是打印,或是存储。但在scrapy这里,事情却有所不同
spiders(如top250.py)只干spiders应该做的事。对数据的后续处理,另有人负责
5. Scrapy的用法-定义数据
在scrapy中会专门定义一个用于记录数据的类
当每一次,要记录数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。会实例化一个对象,利用这个对象来记录数据
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理
定义这个类的py文件,正是items.py
要爬取的数据是书名、出版信息和评分,来看看如何在items.py里定义这些数据。代码如下↓
import scrapy # 导入scrapy class DoubanItem(scrapy.Item): # 定义一个类DoubanItem,它继承自scrapy.Item title = scrapy.Field() # 定义书名的数据属性 publish = scrapy.Field() # 定义出版信息的数据属性 score = scrapy.Field() # 定义评分的数据属性
导入了scrapy,目的是,等会所创建的类将直接继承scrapy中的scrapy.Item类。这样,有许多好用属性和方法,就能够直接使用。比如到后面,引擎能将item类的对象发给Item Pipeline(数据管道)处理
然后定义了一个DoubanItem类,它继承自scrapy.Item类
之后的代码是定义了书名、出版信息和评分三种数据。scrapy.Field()这句代码实现的是,让数据能以类似字典的形式记录。举例看下↓
import scrapy # 导入scrapy class DoubanItem(scrapy.Item): # 定义一个类DoubanItem,它继承自scrapy.Item title = scrapy.Field() # 定义书名的数据属性 publish = scrapy.Field() # 定义出版信息的数据属性 score = scrapy.Field() # 定义评分的数据属性 book = DoubanItem() # 实例化一个DoubanItem对象 book['title'] = '海边的卡夫卡' book['publish'] = '[日] 村上春树 / 林少华 / 上海译文出版社 / 2003' book['score'] = '8.1' print(book) print(type(book)) # 》》{'publish': '[日] 村上春树 / 林少华 / 上海译文出版社 / 2003', # 》》'score': '8.1', # 》》'title': '海边的卡夫卡'} # 》》<class '__main__.DoubanItem'>
会看到打印出来的结果的确和字典非常相像,但它却并不是dict,它的数据类型是DoubanItem,属于“自定义的Python字典”。可以利用类似上述代码的样式,去重新写top250.py
import scrapy import bs4 from ..items import DoubanItem # 需要引用DoubanItem,它在items里面。因为是items在top250.py的上一级目录,所以要用..items,这是一个固定用法 class DoubanSpider(scrapy.Spider): # 定义一个爬虫类DoubanSpider name = 'douban' # 定义爬虫的名字为douban allowed_domains = ['book.douban.com'] # 定义爬虫爬取网址的域名 start_urls = [] # 定义起始网址 for x in range(3): url = 'https://book.douban.com/top250?start=' + str(x * 25) start_urls.append(url) # 把豆瓣Top250图书的前3页网址添加进start_urls def parse(self, response): # parse是默认处理response的方法 bs = bs4.BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析response datas = bs.find_all('tr', class_="item") # 用find_all提取<tr class="item">元素,这个元素里含有书籍信息 for data in datas: # 遍历data item = DoubanItem() # 实例化DoubanItem这个类 item['title'] = data.find_all('a')[1]['title'] # 提取出书名,并把这个数据放回DoubanItem类的title属性里 item['publish'] = data.find('p', class_='pl').text # 提取出出版信息,并把这个数据放回DoubanItem类的publish里 item['score'] = data.find('span', class_='rating_nums').text # 提取出评分,并把这个数据放回DoubanItem类的score属性里 print(item['title']) # 打印书名 yield item # yield item是把获得的item传递给引擎
当每一次,要记录数据的时候,会实例化一个item对象,利用这个对象来记录数据
每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句
yield语句可以简单理解为:它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息
程序运行的过程:爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器(Scheduler),让调度器把这些requests对象排序处理。然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理
5. Scrapy的用法-设置
运行时可能还是会报错,原因在于Scrapy里的默认设置没被修改。比如需要修改请求头,点击settings.py文件,能在里面找到如下的默认设置代码↓
# Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True
把USER_AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头
又因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以还得修改Scrapy中的默认设置
把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False
5. Scrapy的用法-运行
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),然后输入命令行:scrapy crawl douban(douban 就是爬虫的名字)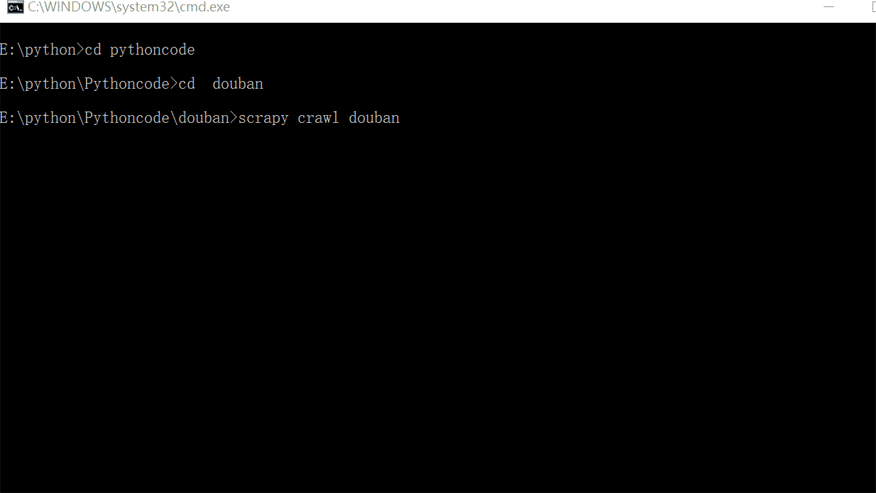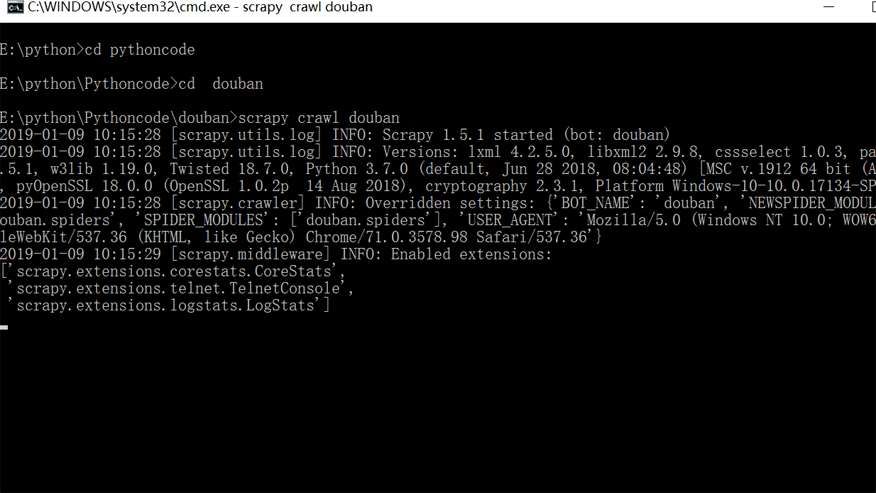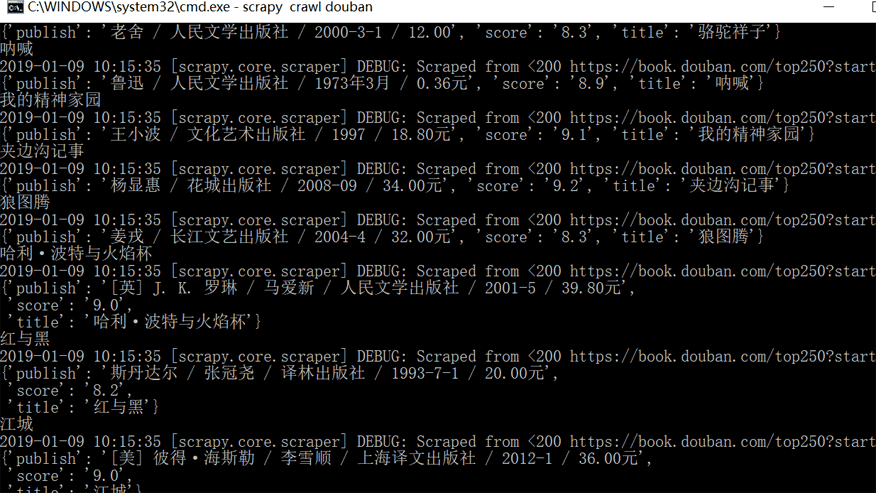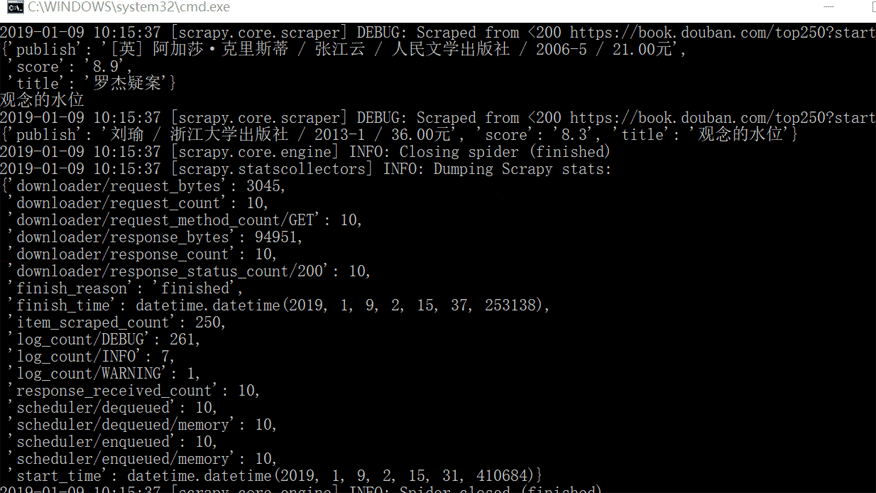
另一种运行方式需要在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)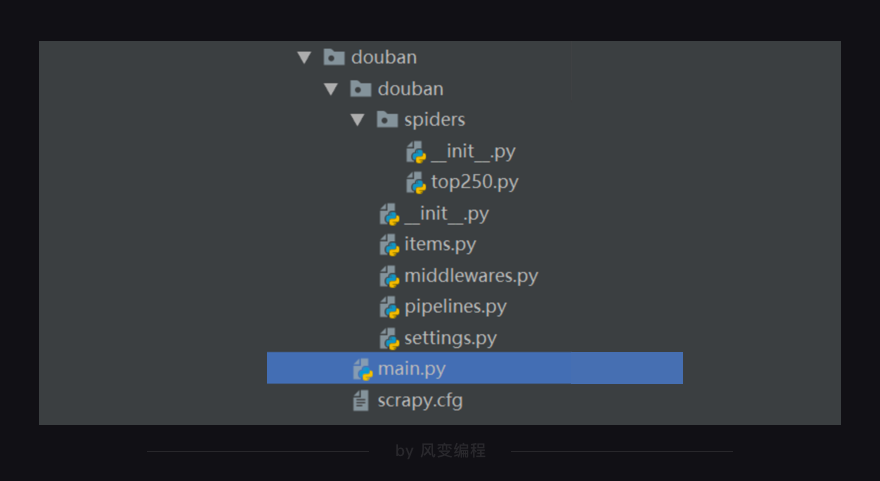
只需要在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动
from scrapy import cmdline # 导入cmdline模块,可以实现控制终端命令行 cmdline.execute(['scrapy', 'crawl', 'douban']) # 用execute()方法,输入运行scrapy的命令
在Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,就能操控终端
在cmdline模块中,有一个execute方法能执行终端的命令行,不过这个方法需要传入列表的参数。想输入运行Scrapy的代码scrapy crawl douban,就需要写成['scrapy','crawl','douban']这样
这个项目先写了爬虫,再定义数据。但是,在实际项目实战中,常常顺序却是相反的——先定义数据,再写爬虫。所以,流程图应如下↓
第14关 Scrapy实操
1. 明确目标
爬取职友集本月最佳人气企业榜10家公司的招聘信息,包括公司名称、职位名称、工作地点和招聘要求。链接:https://www.jobui.com/rank/company/
2. 分析过程
经“检查”,公司和后面的招聘信息均在html里
通过<ul class="textList flsty cfix">里面的<a>标签中的href属性可以通往公司的详情页面
到公司详情页面,点击“招聘”页签,可以总结出公司招聘信息的网址规律↓
公司名称可以在<a class="company-banner-name">的文本中找到
在<div class="c-job-list">下可以找到各个职位信息
通过<a>元素里的<h3>元素的文本取到职位名称
通过第1个<span>标签的title属性取到工作地点
通过第2个<span>标签的title属性取到职位要求
3. 代码实现-创建Scrapy项目
在终端跳转到想要保存项目的目录,输入创建Scrapy项目的命令:scrapy startproject jobui(jobui是职友集网站的英文名,在这里可以把它作为Scrapy项目的名字)
4. 代码实现-定义item(数据)
import scrapy class JobuiItem(scrapy.Item): # 定义了一个继承自scrapy.Item的JobuiItem类 company = scrapy.Field() # 定义公司名称的数据属性 position = scrapy.Field() # 定义职位名称的数据属性 address = scrapy.Field() # 定义工作地点的数据属性 detail = scrapy.Field() # 定义招聘要求的数据属性
5. 创建和编写spiders文件
在spiders文件夹下创建爬虫文件,命名为jobui_ jobs.py
在Scrapy里,获取网页源代码这件事儿,会由引擎分配给下载器去做,不需要自己处理。之所以要构造新的requests对象,是为了告诉引擎,新的请求需要传入什么参数,这样才能让引擎拿到的是正确requests对象,交给下载器处理
构造了新的requests对象,就得定义与之匹配的用来处理response的新方法。这样才能提取出想要的招聘信息的数据
# 导入模块 import scrapy import bs4 from ..items import JobuiItem class JobuiSpider(scrapy.Spider): # 定义一个爬虫类JobuiSpider name = 'jobui' # 定义爬虫的名字为jobui allowed_domains = ['www.jobui.com'] # 定义允许爬虫爬取网址的域名——职友集网站的域名 start_urls = ['https://www.jobui.com/rank/company/'] # 定义起始网址——职友集企业排行榜的网址 # 提取公司id标识和构造公司招聘信息的网址 def parse(self, response): # parse是默认处理response的方法 bs = bs4.BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析response(企业排行榜的网页源代码) ul_list = bs.find_all('ul', class_="textList flsty cfix") # 用find_all提取<ul class_="textList flsty cfix">标签 for ul in ul_list: # 遍历ul_list a_list = ul.find_all('a') # 用find_all提取出<ul class_="textList flsty cfix">元素里的所有<a>元素 for a in a_list: # 再遍历a_list company_id = a['href'] # 提取出所有<a>元素的href属性的值,也就是公司id标识 url = 'https://www.jobui.com{id}jobs'.format(id=company_id) # 构造出公司招聘信息的网址链接 yield scrapy.Request(url, callback=self.parse_job) # 用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parse_job方法 # 解析和提取公司招聘信息的数据 def parse_job(self, response): # 定义新的处理response的方法parse_job(方法的名字可以自己起) bs = bs4.BeautifulSoup(response.text, 'html.parser') # 用BeautifulSoup解析response(公司招聘信息的网页源代码) company = bs.find('a',class_='company-banner-name').text # 用find方法提取出公司名称 datas = bs.find_all('div', class_="c-job-list") # 用find_all提取<div class_="c-job-list">标签,里面含有招聘信息的数据 for data in datas: # 遍历datas item = JobuiItem() # 实例化JobuiItem这个类 item['company'] = company # 把公司名称放回JobuiItem类的company属性里 item['position'] = data.find('a').find('h3').text # 提取出职位名称,并把这个数据放回JobuiItem类的position属性里 item['address'] = data.find_all('span')[0]['title'] # 提取出工作地点,并把这个数据放回JobuiItem类的address属性里 item['detail'] = data.find_all('span')[1]['title'] # 提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里 yield item # 用yield语句把item传递给引擎
scrapy.Request是构造requests对象的类;url是我们往requests对象里传入的每家公司招聘信息网址的参数;callback的中文意思是回调,self.parse_job是新定义的parse_job方法,往requests对象里传入callback=self.parse_job这个参数后,引擎就能知道response要前往的下一站,是parse_job()方法;yield语句就是用来把这个构造好的requests对象传递给引擎
6. 存储文件
在Scrapy里,把数据存储成csv文件和Excel文件,也有分别对应的方法
存储成csv文件的方法,只需在settings.py文件里,添加如下的代码↓
FEED_URI = './storage/data/%(name)s.csv' FEED_FORMAT = 'CSV' FEED_EXPORT_ENCODING = 'utf-8'
FEED_URI是导出文件的路径。'./storage/data/%(name)s.csv',就是把存储的文件放到与scrapy.cfg文件同级的storage文件夹的data子文件夹里FEED_FORMAT 是导出数据格式,写CSV就能得到CSV格式FEED_EXPORT_ENCODING 是导出文件编码,utf-8是用在mac电脑上的编码格式,写ansi是一种在windows上的编码格式
存储成Excel文件的方法,需要先在settings.py里设置启用ITEM_PIPELINES,设置方法只要取消ITEM_PIPELINES的注释(删掉#)
# 取消`ITEM_PIPELINES`的注释后: # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'jobui.pipelines.JobuiPipeline': 300, }
接着,就可以去编辑pipelines.py文件。存储Excel文件,依旧是用openpyxl模块来实现
import openpyxl class JobuiPipeline(object): # 定义一个JobuiPipeline类,负责处理item def __init__(self): # 初始化函数 当类实例化时这个方法会自启动 self.wb = openpyxl.Workbook() # 创建工作薄 self.ws = self.wb.active # 定位活动表 self.ws.append(['公司', '职位', '地址', '招聘信息']) # 用append函数往表格添加表头 def process_item(self, item, spider): # process_item是默认的处理item的方法,就像parse是默认处理response的方法 line = [item['company'], item['position'], item['address'], item['detail']] # 把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line self.ws.append(line) # 用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格 return item # 将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度 def close_spider(self, spider): # close_spider是当爬虫结束运行时,这个方法就会执行 self.wb.save('./jobui.xlsx') # 保存文件 self.wb.close() # 关闭文件
7. 修改设置
修改Scrapy中settings.py文件里的默认设置:添加请求头,以及把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False
还有一处默认设置需要修改,需要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,要把下载延迟的时间改成0.5秒
# Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 0.5
修改完设置,已经可以运行代码
第15关 复习与反爬虫
1. 爬虫进阶路线指引
· 解析与提取
当说要学习解析和提取,是指学习解析库。除了BeautifulSoup解析、Selenium的自带解析库之外,还会有:xpath/lxml等。它们可能语法有所不同,但底层原理都一致,能很轻松上手,然后在一些合适的场景去用它们
正则表达式(re模块)功能强大,它能让自己设定一套复杂的规则,然后把目标文本里符合条件的相关内容给找出来
· 存储
说到存储,目前已经掌握的知识是csv和excel。它们并不是非常高难度的模块,可以翻阅它们的官方文档了解更多的用法。这样,对于平时的自动化办公也会有所帮助
但是当数据量变得十分巨大(这在爬虫界并不是什么新鲜事),同时数据与数据之间的关系,应难以用一张简单的二维平面表格来承载。那么,需要数据库的帮助
推荐从MySQL和MongoDB这两个库开始学起,它们一个是关系型数据库的典型代表,一个是非关系型数据库的典型代表
设计两份表格,一张存储用户们的账户信息(昵称,头像等),一张则存储用户们的学习记录,两个表格之间,通过唯一的用户id来进行关联,这样的就是关系型数据库。没有这种特征的,自然就是非关系型数据库
学习数据库,需要接触另一种语言:SQL
· 数据分析与可视化
徒有海量的数据的意义非常有限。数据,要被分析过才能创造出更深远的价值。这里边的技能,叫做数据分析。将数据分析的结论,直观、有力地传递出来,是可视化
这并不是很简单的技能,学习数据分析,要比爬虫还要花费更多的时间。推荐的模块与库:Pandas/Matplotlib/Numpy/Scikit-Learn/Scipy
· 更多的爬虫
当有太多的数据要爬取,就要开始关心爬虫的速度。已经学习过一个可以让多个爬虫一起工作的工具——协程
严格来说这并不是同时工作,而是电脑在多个任务之间快速地来回切换,看上去就仿佛是爬虫们同时工作
所以这种工作方式对速度的优化有瓶颈。那么,如果还想有所突破还可以怎么做?
协程在本质上只用到CPU的一个核。而多进程(multiprocessing库)爬虫允许使用CPU的多个核,所以可以使用多进程,或者是多进程与多协程结合的方式进一步优化爬虫
理论上来说,只要CPU允许,开多少个进程,就能让爬虫速度提高多少倍
那要是CPU不允许呢?一台普通的电脑,也就8核,但想突破8个进程,应该怎么办?
答,分布式爬虫。分布式爬虫,就是让多个设备,去跑同一个项目
创建一个共享的队列,队列里塞满了待执行的爬虫任务,让多个设备从这个共享队列当中,去获取任务,并完成执行。这就是分布式爬虫
如此,就不再有限制爬虫的瓶颈——多加设备就行。在企业内,面对大量爬虫任务,他们也是使用分布式的方式来进行爬虫作业
实现分布式爬虫,需要下一个组块的内容——框架
· 更强大的爬虫——框架
目前,已经简单地学过Scrapy框架的基本原理和用法。而一些更深入的用法:使用Scrapy模拟登录、存储数据库、使用HTTP代理、分布式爬虫……这些还不曾涉及
不过这些知识大数都能轻松上手,因为它们的底层逻辑都已掌握,剩下的不过是一些语法问题罢了
推荐先去更深入地学习、了解Scrapy框架,然后再了解一些其他的优秀框架,如:PySpider
2. 反爬虫应对策略汇总
几乎所有的技术人员对反爬虫都有一个共识:所谓的反爬虫,从不是将爬虫完全杜绝;而是想办法将爬虫的访问量限制在一个可接纳的范围,不要让它过于肆无忌惮
原因很简单:爬虫代码写到最后,已经和真人访问网络毫无区别。服务器的那一端完全无法判断是人还是爬虫。如果想要完全禁止爬虫,正常用户也会无法访问。所以只能想办法进行限制,而非禁止
有的网站会限制请求头,即Request Headers。那就去填写user-agent声明自己的身份,有时还要去填写origin和referer声明请求的来源
有的网站会限制登录,不登录就不给访问。那就用cookies和session去模拟登录
有的网站会做一些复杂的交互,比如设置“验证码”来阻拦登录。这就比较难做,解决方案一般有二:用Selenium去手动输入验证码;用一些图像处理的库自动识别验证码(tesserocr/pytesserart/pillow)
有的网站会做IP限制,如果一个IP地址爬取网站频次太高,那么服务器就会暂时封掉来自这个IP地址的请求。解决方案有二:使用time.sleep()来对爬虫的速度进行限制;建立IP代理池(可以在网络上搜索可用的IP代理),一个IP不能用了就换一个用。大致语法是这样↓
import requests url = 'https://…' proxies = {'http': 'http://…'} # ip地址 response = requests.get(url, proxies=proxies)
写爬虫最重要的是什么?确认目标-分析过程-先面向过程一行行实现代码-代码封装。最重要的是确认目标,最难的是分析过程,写代码不过是水到渠成的事