![]()
推荐下我自己创建的Python学习交流群923414804,这是Python学习交流的地方,不管你是小白还是大牛,小编都欢迎,不定期分享干货,包括我整理的一份适合零基础学习Python的资料和入门教程。
笔者是头条的深度使用者,经常用头条完成“看片”大业。若不信的话可以试试在头条搜索街拍,返回的都是一道道靓丽的风景线。
想把图片存下来,该怎么办呢?我们可以用Python爬虫啊。
1、工具
Python3.5,Sublime Text,Windows 7
2、分析(第三步有完整代码)
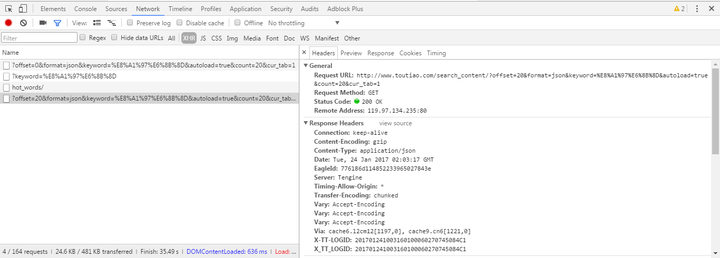
可以看到搜索结果默认返回了 20 篇文章,当页面滚动到底部时头条通过 ajax 加载更多文章,浏览器按下 F12 打开调试工具(我的是 Chrome),点击 Network 选项,尝试加载更多的文章,可以看到相关的 http 请求:
![]()
此次返回Request URL:
http://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1
来试试返回了什么
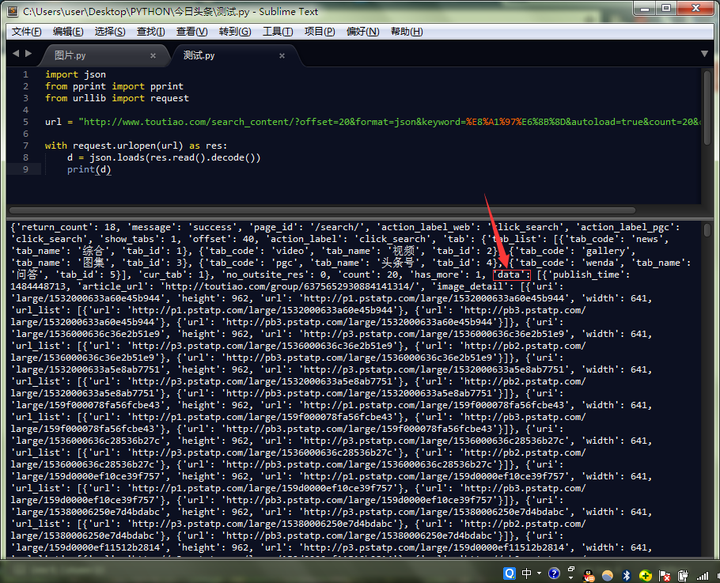
import json
from urllib import request
url = "http://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1"
with request.urlopen(url) as res:
d = json.loads(res.read().decode())
print(d)
![]()
发现我们需要的东西在'data'里,打开一篇文章,来试试如何下载单篇图片。
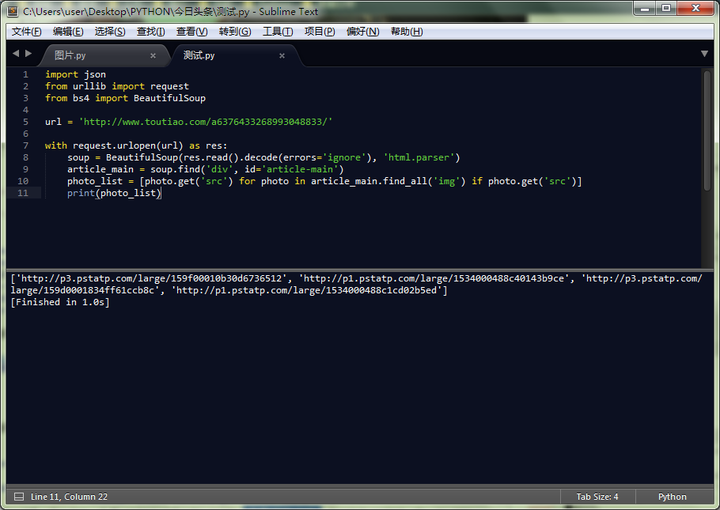
import json
from urllib import request
url = 'http://www.toutiao.com/a6314996711535444226/#p=1'
with request.urlopen(url) as res:
soup = BeautifulSoup(res.read().decode(errors='ignore'), 'html.parser')
article_main = soup.find('div', id='article-main')
photo_list = [photo.get('src') for photo in article_main.find_all('img') if photo.get('src')]
print(photo_list)
![]()
输出
['http://p3.pstatp.com/large/159f00010b30d6736512', 'http://p1.pstatp.com/large/1534000488c40143b9ce', 'http://p3.pstatp.com/large/159d0001834ff61ccb8c', 'http://p1.pstatp.com/large/1534000488c1cd02b5ed']
首先用BeautifulSoup解析网页,通过 find 方法找到 article-main 对应的 div 块,在该 div 块下继续使用 find_all 方法搜寻全部的 img 标签,并提取其 src 属性对应的值,于是我们便获得了该文章下全部图片的 URL 列表。
接下来就是保存图片。
photo_url = "http://p3.pstatp.com/large/159f00010b30d6736512"
photo_name = photo_url.rsplit('/', 1)[-1] + '.jpg'
with request.urlopen(photo_url) as res, open(photo_name, 'wb') as f:
f.write(res.read())
基本步骤就是这么多了,整理下爬取流程:
- 指定查询参数,向 http://www.toutiao.com/search_content/ 提交我们的查询请求。
- 从返回的数据(JSON 格式)中解析出全部文章的 URL,分别向这些文章发送请求。
- 从返回的数据(HTML 格式)提取出文章的标题和全部图片链接。
- 再分别向这些图片链接发送请求,将返回的图片输入保存到本地(E:jiepai)。
- 修改查询参数,以使服务器返回新的文章数据,继续第一步。
3、完整代码
import re
import json
import time
import random
from pathlib import Path
from urllib import parse
from urllib import error
from urllib import request
from datetime import datetime
from http.client import IncompleteRead
from socket import timeout as socket_timeout
from bs4 import BeautifulSoup
def _get_timestamp():
"""
向 http://www.toutiao.com/search_content/ 发送的请求的参数包含一个时间戳,
该函数获取当前时间戳,并格式化成头条接收的格式。格式为 datetime.today() 返回
的值去掉小数点后取第一位到倒数第三位的数字。
"""
row_timestamp = str(datetime.timestamp(datetime.today()))
return row_timestamp.replace('.', '')[:-3]
def _create_dir(name):
"""
根据传入的目录名创建一个目录,这里用到了 python3.4 引入的 pathlib 库。
"""
directory = Path(name)
if not directory.exists():
directory.mkdir()
return directory
def _get_query_string(data):
"""
将查询参数编码为 url,例如:
data = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': 20,
'_': 1480675595492
}
则返回的值为:
?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=1480675595492"
"""
return parse.urlencode(data)
def get_article_urls(req, timeout=10):
with request.urlopen(req, timeout=timeout) as res:
d = json.loads(res.read().decode()).get('data')
if d is None:
print("数据全部请求完毕...")
return
urls = [article.get('article_url') for article in d if article.get('article_url')]
return urls
def get_photo_urls(req, timeout=10):
with request.urlopen(req, timeout=timeout) as res:
# 这里 decode 默认为 utf-8 编码,但返回的内容中含有部分非 utf-8 的内容,会导致解码失败
# 所以我们使用 ignore 忽略这部分内容
soup = BeautifulSoup(res.read().decode(errors='ignore'), 'html.parser')
article_main = soup.find('div', id='article-main')
if not article_main:
print("无法定位到文章主体...")
return
heading = article_main.h1.string
if '街拍' not in heading:
print("这不是街拍的文章!!!")
return
img_list = [img.get('src') for img in article_main.find_all('img') if img.get('src')]
return heading, img_list
def save_photo(photo_url, save_dir, timeout=10):
photo_name = photo_url.rsplit('/', 1)[-1] + '.jpg'
# 这是 pathlib 的特殊操作,其作用是将 save_dir 和 photo_name 拼成一个完整的路径。例如:
# save_dir = 'E:jiepai'
# photo_name = '11125841455748.jpg'
# 则 save_path = 'E:jiepai11125841455748.jpg'
save_path = save_dir / photo_name
with request.urlopen(photo_url, timeout=timeout) as res, save_path.open('wb') as f:
f.write(res.read())
print('已下载图片:{dir_name}/{photo_name},请求的 URL 为:{url}'
.format(dir_name=dir_name, photo_name=photo_name, url=a_url))
if __name__ == '__main__':
ongoing = True
offset = 0 # 请求的偏移量,每次累加 20
root_dir = _create_dir('E:jiepai') # 保存图片的根目录
request_headers = {
'Referer': 'http://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'
}
while ongoing:
timestamp = _get_timestamp()
query_data = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': 20, # 每次返回 20 篇文章
'_': timestamp
}
query_url = 'http://www.toutiao.com/search_content/' + '?' + _get_query_string(query_data)
article_req = request.Request(query_url, headers=request_headers)
article_urls = get_article_urls(article_req)
# 如果不再返回数据,说明全部数据已经请求完毕,跳出循环
if article_urls is None:
break
# 开始向每篇文章发送请求
for a_url in article_urls:
# 请求文章时可能返回两个异常,一个是连接超时 socket_timeout,
# 另一个是 HTTPError,例如页面不存在
# 连接超时我们便休息一下,HTTPError 便直接跳过。
try:
photo_req = request.Request(a_url, headers=request_headers)
photo_urls = get_photo_urls(photo_req)
# 文章中没有图片?跳到下一篇文章
if photo_urls is None:
continue
article_heading, photo_urls = photo_urls
# 这里使用文章的标题作为保存这篇文章全部图片的目录。
# 过滤掉了标题中在 windows 下无法作为目录名的特殊字符。
dir_name = re.sub(r'[\/:*?"<>|]', '', article_heading)
download_dir = _create_dir(root_dir / dir_name)
# 开始下载文章中的图片
for p_url in photo_urls:
# 由于图片数据以分段形式返回,在接收数据时可能抛出 IncompleteRead 异常
try:
save_photo(p_url, save_dir=download_dir)
except IncompleteRead as e:
print(e)
continue
except socket_timeout:
print("连接超时了,休息一下...")
time.sleep(random.randint(15, 25))
continue
except error.HTTPError:
continue
# 一次请求处理完毕,将偏移量加 20,继续获取新的 20 篇文章。
offset += 20
同理,只需修改代码,就可以下载想要的关键词,自己动手,想啥有啥。
![]()