简介
我最近参加了一个开放数据科学家职位的面试。正如你所能想象的,有来自各种背景的候选人——软件工程、学习和开发、金融、市场营销等等。
让我印象深刻的是,这些人已经完成了一系列令人惊叹的项目。他们本身在数据科学方面并没有太多的行业经验,但是他们对学习新概念的热情和好奇心驱使他们去了以前从未涉足过的领域。
一个共同的特点,开源数据科学项目。在过去的几年里,我一直认可开源数据项目的价值。相信我,招聘人员和招聘经理都很欣赏你在接手一个以前没见过的项目时所付出的努力。

该项目可以来自你当前工作的领域,也可以来自你想要学习的领域。
在这里,我在本文中展示了六个这样的开源数据科学项目。。你将发现从计算机视觉到自然语言处理(NLP)等各种项目。

开源计算机视觉项目
对计算机视觉专家的需求每年都在稳步增长。它已经确立了自己作为行业领先领域的地位(这对于任何紧跟最新行业趋势的人来说都是不足为奇的)。作为一名数据科学专业人士,有很多事情要做,有很多东西要学。
这里有三个有用的开源计算机视觉项目,你会喜欢的。
NVIDIA的Few-Shot vid2vid
https://github.com/NVlabs/few-shot-vid2vid
去年我偶然发现了视频到视频(vid2vid)合成的概念,并被它的有效性所震撼。vid2vid本质上是将一个语义输入视频转换为一个超真实的输出视频。从那时起,这个想法已经有了很大的进展。
但是目前这些vid2vid模型有两个主要的限制:
- 他们需要大量的训练数据
- 这些模型很难推广到训练数据之外
英伟达viv2vid框架做了有效的进步。我们可以用它来“生成人体运动姿势,从边缘图合成人物,或者把语义标签地图变成实景照片视频。
这个GitHub库是一个PyTorch实现,它很少使用vid2vid。你可以在这里查看完整的研究论文(它也在NeurIPS 2019上发表):https://arxiv.org/abs/1910.12713
这是一段由开发者分享的视频,展示了几次拍摄的视频:https://youtu.be/8AZBuyEuDqc
轻量的面部检测器
https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这是一个超轻版本的人脸检测模型,一个非常有用的计算机视觉应用。

该面部检测模型的大小仅为1MB!我读了几次后才相信。
该模型是基于libfacedetection架构的边缘计算设备的轻量级面部检测模型。该模型有两个版本:
- Version-slim (slightly faster simplification)
- Version-RFB (with the modified RFB module, higher precision)
Gaussian YOLOv3:一种精确、快速的自动驾驶目标探测器
https://github.com/jwchoi384/Gaussian_YOLOv3
我是自动驾驶汽车的超级粉丝。但是由于各种原因(建筑、公共政策、社区的接受度等),进展缓慢。因此,看到任何框架或算法为这些自动驾驶汽车带来更美好的未来,总是令人振奋的。

目标检测算法是这些自动驾驶车辆的核心——我相信你已经知道了。而高精度、快速的推理速度是保证安全的关键。这些都已经存在了好几年了,那么这个项目有什么不同之处呢?
Gaussian YOLOv3架构提高了系统的检测精度,支持实时操作(一个关键方面)。与传统的YOLOv3相比,Gaussian YOLOv3分别将KITTI和Berkeley deep drive (BDD)数据集的平均精度(mAP)提高了3.09和3.5。
其他开源数据科学项目
这篇文章不仅仅局限于计算机视觉!正如我在引言中提到的,我的目标是覆盖数据科学的所有方面。因此,这里有三个项目,从自然语言处理(NLP)到数据可视化!
Google的T5:Text-to-Text Transfer Transformer
https://github.com/google-research/text-to-text-transfer-transformer
谷歌怎么可能每次都被排除在“最新突破”名单之外呢?他们在机器学习、深度学习和强化学习研究上投入了大量资金,他们的研究结果反映了这一点。我很高兴他们不时地开放他们的项目,我们有很多东西可以向他们学习
T5是Text-to-Text Transfer Transformer的简称,它是由迁移学习的概念驱动的。在这个最新的NLP项目中,T5背后的开发人员引入了一个统一的框架,将每个语言问题转换为文本到文本的格式。

该框架在总结、问题回答、文本分类等任务的各种基准测试上取得了最新的结果。在这个GitHub存储库中,他们已经开源了数据集、预先训练的模型和T5背后的代码。
正如谷歌的人所说,“T5可以作为未来模型开发的库,它提供了有用的模块来向量和微调(参数量巨大)文本到文本混合任务的模型。”
历史上最大的中国知识图谱
https://github.com/ownthink/KnowledgeGraphData
最近我读了很多关于图的文章。它们是如何工作的,一个图的不同组成部分是什么,知识如何在图中流动,这个概念如何应用到数据科学中,等等。我相信你们现在正在问这些问题。
图论的某些分支可以应用于数据科学,如知识树和知识图。

从这个意义上说,这个项目是一个庞然大物。它是历史上最大的中文知识地图,超过1.4亿个节点!数据集以(实体,属性,值),(实体,关系,实体)的形式组织。数据为.csv格式。这是一个出色的开源项目,可以展示你的图方面的技能。
RoughViz – JavaScript中的出色数据可视化库
https://github.com/jwilber/roughViz
我是数据可视化的忠实拥护者 -这不是秘密。因此,我总是抓住机会在这些文章中加入一个数据可视化库或项目。
RoughViz就是这样一个JavaScript库,用于生成手绘草图或可视化。它基于D3v5、roughjs和handy。
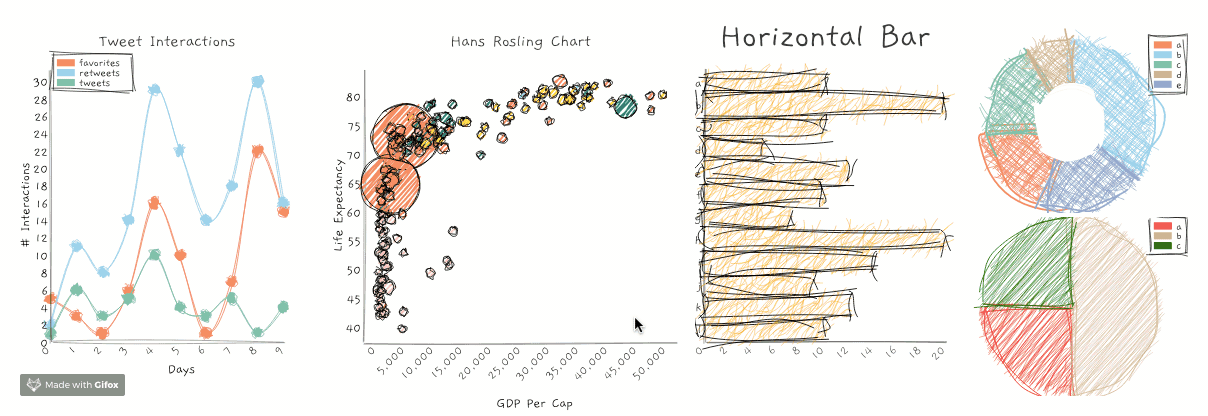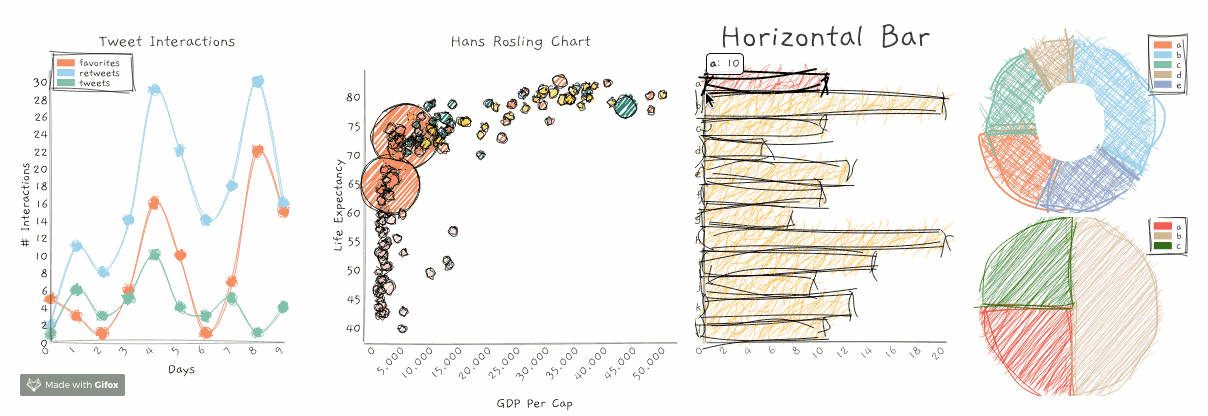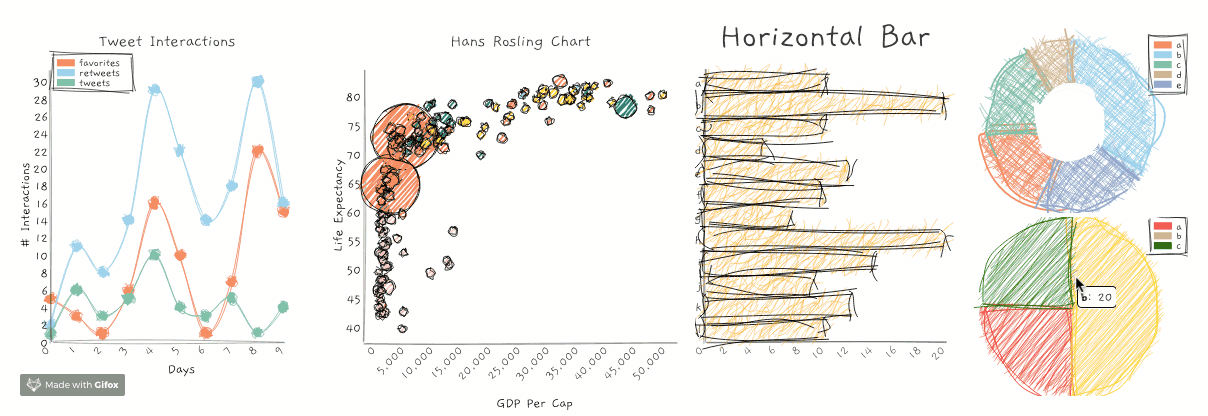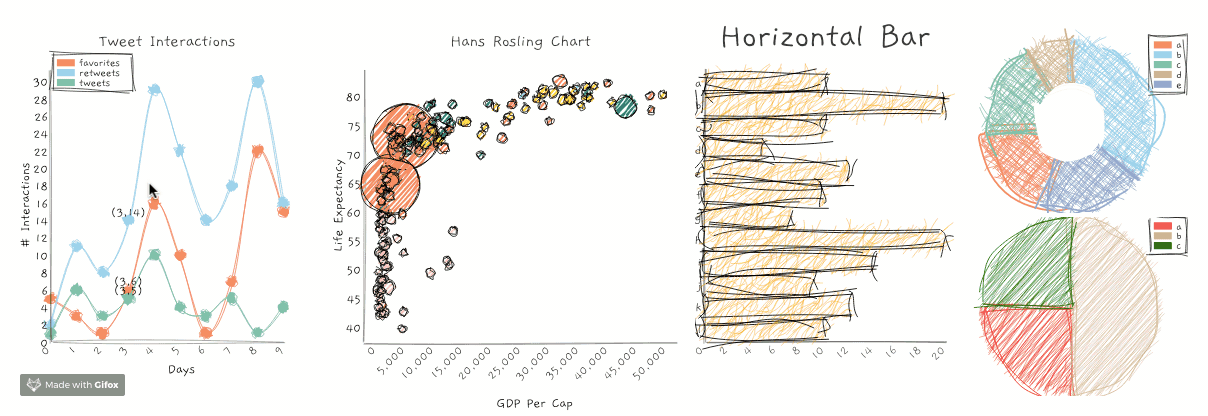
你可以使用以下命令在你的计算机上安装roughViz:
npm install rough-viz
这个GitHub存储库包含关于如何使用roughViz的详细示例和代码。以下是你可以生成的不同图表:
- 条形图
- 水平栏
- 圆环图
- 折线图
- 饼状图
- 散点图
结尾
我很喜欢整理这篇文章。在这个过程中,我遇到了一些非常有趣的数据科学项目、库和框架。这实际上是一种很好的方式来跟上这个领域的最新发展。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/