概览
- 知识图谱是数据科学中最有趣的概念之一
- 了解如何使用Wikipedia页面上的文本构建知识图谱
- 我们将动手使用Python流行的spaCy库构建我们的知识图谱
介绍
梅西(Lionel Messi)无需介绍,甚至不喜欢足球的人都听说过,最伟大的球员之一为这项运动增光添彩。这是他的维基百科页面:

那里有很多信息!我们有文本,大量的超链接,甚至还有音频剪辑。在一个页面上有很多相关且可能有用的信息。
但是,有一个小问题。这不是要馈送到我们的计算机的理想数据源。无论如何都不是当前形式。
我们能否找到一种方法使该文本数据对计算机可读?从本质上讲,我们可以将这些文本数据转换为机器可以使用的内容,也可以由我们轻松地解释吗?
我们可以!我们可以借助知识图谱(KG)来做到这一点,KG是数据科学中最引人入胜的概念之一。知识图谱的巨大潜力和应用使我震惊,并且我相信你也会如此。
在本文中,你将了解什么是知识图谱,它们为何有用,然后我们将基于从Wikipedia提取的数据构建自己的知识图谱,从而深入研究代码。
什么是知识图谱?
让我们先确定一件事情,在本文中,我们会经常看到图一词。当我说图时,我们并不是指条形图,饼图和折线图。在这里,我们谈论的是相互联系的实体,这些实体可以是人员,位置,组织,甚至是事件。

我们可以将图定义为一组节点和边。看下图:
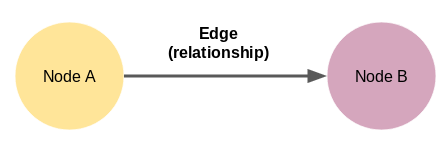
这里的节点A和节点B是两个不同的实体。这些节点由代表两个节点之间关系的边连接。现在,这是我们可以构建的最小知识图谱–也称为三元图。知识图谱有各种形状和大小。例如,截至2019年10月,Wikidata的知识图谱具有59,910,568个节点。
如何在图中表示知识?
在开始构建知识图谱之前,了解信息或知识如何嵌入这些图非常重要。
让我用一个例子来解释一下。如果节点A = Putin ,节点B = Russia,则边缘很可能是“president of”:

节点或实体也可以具有多个关系。普京不仅是俄罗斯总统,还曾在苏联安全机构克格勃苏联安全局(KGB)工作。但是,我们如何将有关普京的新信息纳入上面的知识图谱中?
实际上非常简单。只需为新实体KGB添加一个节点即可:

新关系不仅可以从知识图谱中的第一个节点出现,还可以从知识图谱中的任何节点出现,如下所示:

俄罗斯是亚太经济合作组织(APEC)的成员。
识别实体及其之间的关系对我们来说不是一件困难的任务。但是,手动构建知识图谱是不可扩展的。没有人会浏览成千上万的文档并提取所有实体及其之间的关系!
这就是为什么机器更适合执行此任务的原因,因为浏览甚至成百上千的文档对于他们来说都是很简单的事。但是,还有另一个挑战就是机器不懂自然语言。这是自然语言处理(NLP)进入图的地方。
要从文本构建知识图谱,重要的是使我们的机器能够理解自然语言。这可以通过使用NLP技术来完成,例如句子分段,依存关系分析,词性标记和实体识别。让我们更详细地讨论这些。
句子分割
构建知识图谱的第一步是将文本文档或文章拆分为句子。然后,我们将仅列出那些恰好具有1个主语和1个宾语的句子。让我们看下面的示例文本:
“Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking. The 22-year-old recently won the ATP Challenger tournament. He made his Grand Slam debut against Federer in the 2019 US Open. Nagal won the first set.”
让我们将以上段落拆分为句子:
- Indian tennis player Sumit Nagal moved up six places from 135 to a career-best 129 in the latest men’s singles ranking
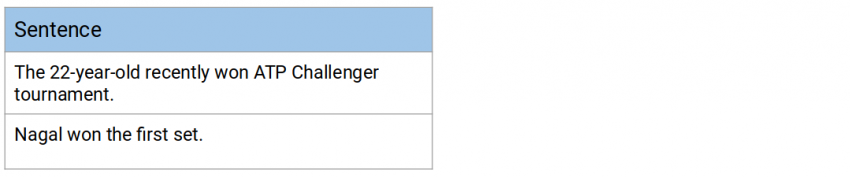
- The 22-year-old recently won the ATP Challenger tournament
- He made his Grand Slam debut against Federer in the 2019 US Open
- Nagal won the first set
在这四个句子中,我们将选择第二个和第四个句子,因为它们每个包含1个主语和1个宾语。在第二句中,主语为“22-year-old”,宾语为“ATP Challenger tournament”。在第四句中,主语是“Nagal”,“first set”是宾语:

挑战在于使你的机器理解文本,尤其是在多词主语和宾语的情况下。例如,提取以上两个句子中的对象有点棘手。你能想到解决此问题的任何方法吗?
###实体提取
从句子中提取单个单词实体并不是一项艰巨的任务。我们可以借助词性(POS)标签轻松地做到这一点。名词和专有名词将是我们的实体。
但是,当一个实体跨越多个单词时,仅靠POS标签是不够的。我们需要解析句子的依存关系树。
你可以在以下文章中阅读有关依赖项解析的更多信息1。
让我们获取所选择的一句句子的依赖项标签。我将使用流行的spaCy库执行此任务:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("The 22-year-old recently won ATP Challenger tournament.")
for tok in doc:
print(tok.text, "...", tok.dep_)
Output:
The … det
22-year … amod
– … punct
old … nsubj
recently … advmod
won … ROOT
ATP … compound
Challenger … compound
tournament … dobj
. … punct
根据依赖性分析器,此句子中的主语(nsubj)为“old”。那不是想要的实体。我们想提取“22-year-old”。
“22-year”的依赖项标签是amod,这意味着它是“old”的修饰语。因此,我们应该定义一个规则来提取这些实体。
规则可以是这样的:提取主语/宾语及其修饰符,还提取它们之间的标点符号。
但是,然后看看句子中的宾语(dobj)。这只是“tournament”,而不是“ATP Challenger tournament”。在这里,我们没有修饰词,但有复合词。
复合词是那些共同构成一个具有不同含义的新术语的词。因此,我们可以将上述规则更新为-提取主语/宾语及其修饰词,复合词,并提取它们之间的标点符号。
简而言之,我们将使用依赖性解析来提取实体。
提取关系
实体提取是完成工作的一半。要构建知识图谱,我们需要边缘将节点(实体)彼此连接。这些边缘是一对节点之间的关系。
让我们回到上一节中的示例。我们选择了几个句子来构建知识图谱:
你能猜出这两个句子中主语和宾语之间的关系吗?
两个句子具有相同的关系“won”。让我们看看如何提取这些关系。我们将再次使用依赖项解析:
doc = nlp("Nagal won the first set.")
for tok in doc:
print(tok.text, "...", tok.dep_)
Output:
Nagal … nsubj
won … ROOT
the … det
first … amod
set … dobj
. … punct
要提取该关系,我们必须找到句子的根(也是句子的动词)。因此,从该句子中提取的关系将是“won”。最后,来自这两个句子的知识图谱将如下所示:

根据文本数据构建知识图谱
是时候开始编写一些代码了!
我们将使用一组与Wikipedia文章相关的电影和电影中的文本从头开始构建知识图谱。我已经从500多个Wikipedia文章中提取了大约4,300个句子。这些句子中的每个句子都恰好包含两个实体-一个主语和一个宾语。你可以从这里2下载这些句子。
我建议对此实现使用Google Colab,以加快计算时间。
导入库
import re
import pandas as pd
import bs4
import requests
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
from spacy.matcher import Matcher
from spacy.tokens import Span
import networkx as nx
import matplotlib.pyplot as plt
from tqdm import tqdm
pd.set_option('display.max_colwidth', 200)
%matplotlib inline
读取数据
读取包含Wikipedia句子的CSV文件:
# 读取wikipedia句子
candidate_sentences = pd.read_csv("wiki_sentences_v2.csv")
candidate_sentences.shape
Output:
(4318, 1)
让我们检查一些示例句子:
candidate_sentences['sentence'].sample(5)
Output:

让我们检查其中一个句子的主语和宾语。理想情况下,句子中应该有一个主语和一个宾语:
doc = nlp("the drawdown process is governed by astm standard d823")
for tok in doc:
print(tok.text, "...", tok.dep_)
Output:

结果不错!只有一个主语和宾语。你可以类似的方式检查其他句子。
实体对提取
这些节点将成为Wikipedia句子中存在的实体。边是将这些实体彼此连接的关系。我们将以无监督的方式提取这些元素,即,我们将使用句子的语法。
主要思想是通过句子,并在遇到主语和宾语时提取它们。但是,存在一些挑战–一个实体可以跨越多个单词,例如“red wine”,并且依赖解析器仅将单个单词标记为主语或宾语。
因此,我在下面创建了一个函数来从句子中提取主语和宾语(实体),同时也克服了上述挑战。为了方便起见,我将代码分为多个块:
def get_entities(sent):
## chunk 1
ent1 = ""
ent2 = ""
prv_tok_dep = "" # 句子中先前标记的依赖项标签
prv_tok_text = "" # 句子中的前一个标记
prefix = ""
modifier = ""
#############################################################
for tok in nlp(sent):
## chunk 2
# 如果标记是标点符号,则继续下一个标记
if tok.dep_ != "punct":
# 检查:标记是否为compound
if tok.dep_ == "compound":
prefix = tok.text
# 如果前一个单词也是'compound',然后将当前单词添加到其中
if prv_tok_dep == "compound":
prefix = prv_tok_text " " tok.text
# 检查:标记是否为修饰符
if tok.dep_.endswith("mod") == True:
modifier = tok.text
# 如果前一个单词也是'compound',然后将当前单词添加到其中
if prv_tok_dep == "compound":
modifier = prv_tok_text " " tok.text
## chunk 3
if tok.dep_.find("subj") == True:
ent1 = modifier " " prefix " " tok.text
prefix = ""
modifier = ""
prv_tok_dep = ""
prv_tok_text = ""
## chunk 4
if tok.dep_.find("obj") == True:
ent2 = modifier " " prefix " " tok.text
## chunk 5
# 更新变量
prv_tok_dep = tok.dep_
prv_tok_text = tok.text
#############################################################
return [ent1.strip(), ent2.strip()]
让我解释一下上面函数中的代码块:
chunk1:
我在此块中定义了一些空变量。prv_tok_dep和prv_tok_text将分别保存句子中前一个单词和上一个单词本身的依赖项标签。prefix和modifier将保存与主语或宾语关联的文本。
chunk 2:
接下来,我们将遍历句子中的标记。我们将首先检查标记是否为标点符号。如果是,那么我们将忽略它并继续下一个标记。如果标记是复合词的一部分(dependency tag = “compound”)=“ compound”),我们将其保留在prefix变量中。复合词是由多个词组成的组合,这些词链接在一起形成具有新含义的词(例如,“Football Stadium”, “animal lover”)。
当我们遇到句子中的一个主语或宾语时,我们将在其前面加上这个prefix。修饰词来也会做同样的操作,例如 “nice shirt”, “big house”等。
chunk 3:
在这里,如果标记是主语,那么它将被捕获作为第一个实体存储在ent1变量中,prefix, modifier, prv_tok_dep, 和 prv_tok_text等变量将被重置。
chunk 4:
在这里,如果标记是宾语,那么它将被捕获作为第二个实体存储在ent2变量中。prefix, modifier, prv_tok_dep, 和 prv_tok_text等变量将再次被重置。
chunk 5:
一旦捕获了句子中的主语和宾语,我们将更新先前的标记及其依赖项标签。
让我们在一个句子上测试此函数:
get_entities("the film had 200 patents")
Output:
[‘film’, ‘200 patents’]
目前都在在按计划进行中。在以上句子中,‘film’ 是主语,“ 200 patents”是宾语。现在,我们可以使用此函数为数据中的所有句子提取这些实体对:
Output:

如你所见,这些实体对中有一些代词,例如 ‘we’, ‘it’, ‘she’等。我们希望使用专有名词或名词。也许我们可以进一步改进get_entities()函数以过滤代词。目前,让我们保持现状,继续进行关系提取部分。
关系/谓词提取
这将是本文的一个非常有趣的方面。我们的假设是谓词实际上是句子中的主要动词。
例如,在句子“Sixty Hollywood musicals were released in 1929”中,动词是“released in” ,这就是我们将要用作该句子所产生的三元组的谓词。下面的函数能够从句子中捕获此类谓语。在这里,我使用过spaCy基于规则的匹配:
def get_relation(sent):
doc = nlp(sent)
# Matcher类对象
matcher = Matcher(nlp.vocab)
#定义模式
pattern = [{'DEP':'ROOT'},
{'DEP':'prep','OP':"?"},
{'DEP':'agent','OP':"?"},
{'POS':'ADJ','OP':"?"}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
k = len(matches) - 1
span = doc[matches[k][1]:matches[k][2]]
return(span.text)
函数中定义的模式试图在句子中找到根词或主要动词。识别出根后,该模式将检查是否紧跟着介词(“prep”)或代理词。如果是,则将其添加到ROOT词中。
让我向你展示一下此功能:
get_relation("John completed the task")
Output:
completed
同样,让我们从所有Wikipedia句子中获取关系:
relations = [get_relation(i) for i in tqdm(candidate_sentences['sentence'])]
让我们看一下我们刚刚提取的最常见的关系或谓词:
pd.Series(relations).value_counts()[:50]
Output:

事实证明,最常见的关系是“A is B” 和 “A was B”。一些示例是 “composed by”, “released in”, “produced”, “written by”等等。
建立知识图谱
最后,我们将从提取的实体(主语-宾语对)和谓词(实体之间的关系)创建知识图谱。
让我们创建一个实体和谓词的dataframe:
# 抽取主语
source = [i[0] for i in entity_pairs]
# 抽取宾语
target = [i[1] for i in entity_pairs]
kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})
接下来,我们将使用networkx库从此dataframe创建网络。节点将代表实体,节点之间的边或连接将代表节点之间的关系。
这将是有向图。换句话说,任何连接的节点对之间的关系不是双向的,它只是从一个节点到另一个节点。例如,“John eats pasta”:
# 从一个dataframe中创建一个有向图
G=nx.from_pandas_edgelist(kg_df, "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
绘制这个网络:
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
Output:

好吧,这并不是我们所希望的(尽管看起来仍然很美!)。
事实证明,我们已经创建了一个具有所有关系的图形。很难想象具有许多关系或谓词的图。
因此,建议仅使用一些重要的关系来可视化图形。我每次只建立一种关系。让我们从“composed by”的关系开始:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="composed by"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5) # k调节节点之间的距离
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
Output:

那是一张更清晰的图表。这里的箭头指向作曲家。例如著名音乐作曲家拉A.R. Rahman在上图中与“soundtrack score”, “film score”, and “music” 相关联。
让我们看看更多的关系。
由于写作在任何电影中都扮演着重要的角色,因此我想形象化“written by”关系的图表:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="written by"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
Output:

太棒了!该知识图谱为我们提供了一些非凡的信息。Javed Akhtar,Krishna Chaitanya和Jaideep Sahni等人都是著名的歌词家,这张图很好地体现了这种关系。
我们来看看另一个重要谓词的知识图谱,即“released in”:
G=nx.from_pandas_edgelist(kg_df[kg_df['edge']=="released in"], "source", "target",
edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
pos = nx.spring_layout(G, k = 0.5)
nx.draw(G, with_labels=True, node_color='skyblue', node_size=1500, edge_cmap=plt.cm.Blues, pos = pos)
plt.show()
Output:

在此图中,我可以看到很多有趣的信息。例如,看一下这种关系- “several action horror movies released in the 1980s” 和 “pk released on 4844 screens”。这些都是事实,它向我们表明,我们可以从文本中挖掘这些事实。太神奇了!
结语
在本文中,我们学习了如何以三元组的形式从给定文本中提取信息并从中构建知识图谱。
但是,我们限制自己使用仅包含2个实体的句子。即便如此,我们仍然能够构建内容丰富的知识图谱。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/