概述
- 在PyTorch中构建自己的卷积神经网络(CNN)的实践教程
- 我们将研究一个图像分类问题——CNN的一个经典和广泛使用的应用
- 我们将以实用的格式介绍深度学习概念
介绍
我被神经网络的力量和能力所吸引。在机器学习和深度学习领域,几乎每一次突破都以神经网络模型为核心。
这在计算机视觉领域尤为普遍。无论是简单的图像分类还是更高级的东西(如对象检测),神经网络开辟了处理图像数据的可能性。简而言之,对于像我这样的数据科学家来说,这是一座金矿!

当我们使用深度学习来解决一个图像分类问题时,简单的神经网络总是一个好的起点。但是,它们确实有局限性,而且模型的性能在达到一定程度后无法得到改善。
这就是卷积神经网络(CNNs)改变了竞争环境的地方。它们在计算机视觉应用中无处不在。老实说,我觉得每一个计算机视觉爱好者都应该可以很快学会这个概念。
我将向你介绍使用流行的PyTorch框架进行深度学习的新概念。在本文中,我们将了解卷积神经网络是如何工作的,以及它如何帮助我们改进模型的性能。我们还将研究在PyTorch中CNNs的实现。
目录
- 简要介绍PyTorch、张量和NumPy
- 为什么选择卷积神经网络(CNNs)?
- 识别服装问题
- 使用PyTorch实现CNNs
简要介绍PyTorch、张量和NumPy
让我们快速回顾一下第一篇文章中涉及的内容。我们讨论了PyTorch和张量的基础知识,还讨论了PyTorch与NumPy的相似之处。
PyTorch是一个基于python的库,提供了以下功能:
- 用于创建可序列化和可优化模型的TorchScript
- 以分布式训练进行并行化计算
- 动态计算图,等等

PyTorch中的张量类似于NumPy的n维数组,也可以与gpu一起使用。在这些张量上执行操作几乎与在NumPy数组上执行操作类似。这使得PyTorch非常易于使用和学习。
在本系列的第1部分中,我们构建了一个简单的神经网络来解决一个案例研究。使用我们的简单模型,我们在测试集中获得了大约65%的基准准确度。现在,我们将尝试使用卷积神经网络来提高这个准确度。
为什么选择卷积神经网络(CNNs)?
在我们进入实现部分之前,让我们快速地看看为什么我们首先需要CNNs,以及它们是如何工作的。
我们可以将卷积神经网络(CNNs)看作是帮助从图像中提取特征的特征提取器。
在一个简单的神经网络中,我们把一个三维图像转换成一维图像,对吧?让我们看一个例子来理解这一点:

你能认出上面的图像吗?这似乎说不通。现在,让我们看看下面的图片:

我们现在可以很容易地说,这是一只狗。如果我告诉你这两个图像是一样的呢?相信我,他们是一样的!唯一的区别是第一个图像是一维的,而第二个图像是相同图像的二维表示
空间定位
人工神经网络也会丢失图像的空间方向。让我们再举个例子来理解一下:

你能分辨出这两幅图像的区别吗?至少我不能。由于这是一个一维的表示,因此很难确定它们之间的区别。现在,让我们看看这些图像的二维表示:

在这里,图像某些定位已经改变,但我们无法通过查看一维表示来识别它。
这就是人工神经网络的问题——它们失去了空间定位。
大量参数
神经网络的另一个问题是参数太多。假设我们的图像大小是28283 -所以这里的参数是2352。如果我们有一个大小为2242243的图像呢?这里的参数数量为150,528。
这些参数只会随着隐藏层的增加而增加。因此,使用人工神经网络的两个主要缺点是:
- 丢失图像的空间方向
- 参数的数量急剧增加
那么我们如何处理这个问题呢?如何在保持空间方向的同时减少可学习参数?
这就是卷积神经网络真正有用的地方。CNNs有助于从图像中提取特征,这可能有助于对图像中的目标进行分类。它首先从图像中提取低维特征(如边缘),然后提取一些高维特征(如形状)。
我们使用滤波器从图像中提取特征,并使用池技术来减少可学习参数的数量。
在本文中,我们不会深入讨论这些主题的细节。如果你希望了解滤波器如何帮助提取特征和池的工作方式,我强烈建议你从头开始学习卷积神经网络的全面教程。
理解问题陈述:识别服装
理论部分已经铺垫完了,开始写代码吧。我们将讨论与第一篇文章相同的问题陈述。这是因为我们可以直接将我们的CNN模型的性能与我们在那里建立的简单神经网络进行比较。
你可以从这里下载“识别”Apparels问题的数据集。
https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-apparels/?utm_source=blog&utm_medium=building-image-classification-models-cnn-pytorch
让我快速总结一下问题陈述。我们的任务是通过观察各种服装形象来识别服装的类型。我们总共有10个类可以对服装的图像进行分类:
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
数据集共包含70,000张图像。其中60000张属于训练集,其余10000张属于测试集。所有的图像都是大小(28*28)的灰度图像。数据集包含两个文件夹,—一个用于训练集,另一个用于测试集。每个文件夹中都有一个.csv文件,该文件具有图像的id和相应的标签;
准备好开始了吗?我们将首先导入所需的库:
# 导入库
import pandas as pd
import numpy as np
# 读取与展示图片
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib inline
# 创建验证集
from sklearn.model_selection import train_test_split
# 评估模型
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# Pytorch的相关库
import torch
from torch.autograd import Variable
from torch.nn import Linear, ReLU, CrossEntropyLoss, Sequential, Conv2d, MaxPool2d, Module, Softmax, BatchNorm2d, Dropout
from torch.optim import Adam, SGD
加载数据集
现在,让我们加载数据集,包括训练,测试样本:
# 加载数据集
train = pd.read_csv('train_LbELtWX/train.csv')
test = pd.read_csv('test_ScVgIM0/test.csv')
sample_submission = pd.read_csv('sample_submission_I5njJSF.csv')
train.head()

- 该训练文件包含每个图像的id及其对应的标签
- 另一方面,测试文件只有id,我们必须预测它们对应的标签
- 样例提交文件将告诉我们预测的格式
我们将一个接一个地读取所有图像,并将它们堆叠成一个数组。我们还将图像的像素值除以255,使图像的像素值在[0,1]范围内。这一步有助于优化模型的性能。
让我们来加载图像:
# 加载训练图像
train_img = []
for img_name in tqdm(train['id']):
# 定义图像路径
image_path = 'train_LbELtWX/train/' str(img_name) '.png'
# 读取图片
img = imread(image_path, as_gray=True)
# 归一化像素值
img /= 255.0
# 转换为浮点数
img = img.astype('float32')
# 添加到列表
train_img.append(img)
# 转换为numpy数组
train_x = np.array(train_img)
# 定义目标
train_y = train['label'].values
train_x.shape

如你所见,我们在训练集中有60,000张大小(28,28)的图像。由于图像是灰度格式的,我们只有一个单一通道,因此形状为(28,28)。
现在让我们研究数据和可视化一些图像:
# 可视化图片
i = 0
plt.figure(figsize=(10,10))
plt.subplot(221), plt.imshow(train_x[i], cmap='gray')
plt.subplot(222), plt.imshow(train_x[i 25], cmap='gray')
plt.subplot(223), plt.imshow(train_x[i 50], cmap='gray')
plt.subplot(224), plt.imshow(train_x[i 75], cmap='gray')

以下是来自数据集的一些示例。我鼓励你去探索更多,想象其他的图像。接下来,我们将把图像分成训练集和验证集。
创建验证集并对图像进行预处理
# 创建验证集
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
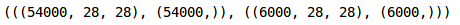
我们在验证集中保留了10%的数据,在训练集中保留了10%的数据。接下来将图片和目标转换成torch格式:
# 转换为torch张量
train_x = train_x.reshape(54000, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# 转换为torch张量
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# 训练集形状
train_x.shape, train_y.shape
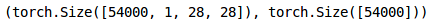
同样,我们将转换验证图像:
# 转换为torch张量
val_x = val_x.reshape(6000, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# 转换为torch张量
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
# 验证集形状
val_x.shape, val_y.shape

我们的数据现在已经准备好了。最后,是时候创建我们的CNN模型了!
使用PyTorch实现CNNs
我们将使用一个非常简单的CNN架构,只有两个卷积层来提取图像的特征。然后,我们将使用一个完全连接的Dense层将这些特征分类到各自的类别中。
让我们定义一下架构:
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义2D卷积层
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# 定义另一个2D卷积层
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
self.linear_layers = Sequential(
Linear(4 * 7 * 7, 10)
)
# 前项传播
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
现在我们调用这个模型,定义优化器和模型的损失函数:
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.07)
# 定义loss函数
criterion = CrossEntropyLoss()
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)

这是模型的架构。我们有两个卷积层和一个线性层。接下来,我们将定义一个函数来训练模型:
def train(epoch):
model.train()
tr_loss = 0
# 获取训练集
x_train, y_train = Variable(train_x), Variable(train_y)
# 获取验证集
x_val, y_val = Variable(val_x), Variable(val_y)
# 转换为GPU格式
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# 清除梯度
optimizer.zero_grad()
# 预测训练与验证集
output_train = model(x_train)
output_val = model(x_val)
# 计算训练集与验证集损失
loss_train = criterion(output_train, y_train)
loss_val = criterion(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# 更新权重
loss_train.backward()
optimizer.step()
tr_loss = loss_train.item()
if epoch%2 == 0:
# 输出验证集loss
print('Epoch : ',epoch 1, ' ', 'loss :', loss_val)
最后,我们将对模型进行25个epoch的训练,并存储训练和验证损失:
# 定义轮数
n_epochs = 25
# 空列表存储训练集损失
train_losses = []
# 空列表存储验证集损失
val_losses = []
# 训练模型
for epoch in range(n_epochs):
train(epoch)

可以看出,随着epoch的增加,验证损失逐渐减小。让我们通过绘图来可视化训练和验证的损失:
# 画出loss曲线
plt.plot(train_losses, label='Training loss')
plt.plot(val_losses, label='Validation loss')
plt.legend()
plt.show()

啊,我喜欢想象的力量。我们可以清楚地看到,训练和验证损失是同步的。这是一个好迹象,因为模型在验证集上进行了很好的泛化。
让我们在训练和验证集上检查模型的准确性:
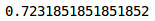
# 训练集预测
with torch.no_grad():
output = model(train_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
# 训练集精度
accuracy_score(train_y, predictions)

训练集的准确率约为72%,相当不错。让我们检查验证集的准确性:
# 验证集预测
with torch.no_grad():
output = model(val_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
# 验证集精度
accuracy_score(val_y, predictions)
正如我们看到的损失,准确度也是同步的-我们在验证集得到了72%的准确度。
为测试集生成预测
最后是时候为测试集生成预测了。我们将加载测试集中的所有图像,执行与训练集相同的预处理步骤,最后生成预测。
所以,让我们开始加载测试图像:
# 载入测试图
test_img = []
for img_name in tqdm(test['id']):
# 定义图片路径
image_path = 'test_ScVgIM0/test/' str(img_name) '.png'
# 读取图片
img = imread(image_path, as_gray=True)
# 归一化像素
img /= 255.0
# 转换为浮点数
img = img.astype('float32')
# 添加到列表
test_img.append(img)
# 转换为numpy数组
test_x = np.array(test_img)
test_x.shape

现在,我们将对这些图像进行预处理步骤,类似于我们之前对训练图像所做的:
# 转换为torch格式
test_x = test_x.reshape(10000, 1, 28, 28)
test_x = torch.from_numpy(test_x)
test_x.shape

最后,我们将生成对测试集的预测:
# 生成测试集预测
with torch.no_grad():
output = model(test_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
用预测替换样本提交文件中的标签,最后保存文件并提交到排行榜:
# 用预测替换
sample_submission['label'] = predictions
sample_submission.head()
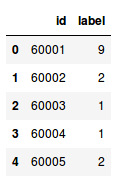
# 保存文件
sample_submission.to_csv('submission.csv', index=False)
你将在当前目录中看到一个名为submission.csv的文件。你只需要把它上传到问题页面的解决方案检查器上,它就会生成分数。链接:https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-apparels/?utm_source=blog&utm_medium=building-image-classification-models-cnn-pytorch
我们的CNN模型在测试集上给出了大约71%的准确率,这与我们在上一篇文章中使用简单的神经网络得到的65%的准确率相比是一个很大的进步。
结尾
在这篇文章中,我们研究了CNNs是如何从图像中提取特征的。他们帮助我们将之前的神经网络模型的准确率从65%提高到71%,这是一个重大的进步。
你可以尝试使用CNN模型的超参数,并尝试进一步提高准确性。要调优的超参数可以是卷积层的数量、每个卷积层的滤波器数量、epoch的数量、全连接层的数量、每个全连接层的隐藏单元的数量等。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/