作者|Veysel Kocaman
编译|VK
来源|Towards Data Science

自然语言处理(NLP)是许多数据科学系统中必须理解或推理文本的关键组成部分。常见的用例包括文本分类、问答、释义或总结、情感分析、自然语言BI、语言建模和消歧。
NLP在越来越多的人工智能应用中是越来越重要。如果你正在构建聊天机器人、搜索专利数据库、将患者与临床试验相匹配、对客户服务或销售电话进行分级、从财务报告中提取摘要,你必须从文本中提取准确的信息。
文本分类是现代自然语言处理的主要任务之一,它是为句子或文档指定一个合适的类别的任务。类别取决于所选的数据集,并且可以从主题开始。
每一个文本分类问题都遵循相似的步骤,并用不同的算法来解决。更不用说经典和流行的机器学习分类器,如随机森林或Logistic回归,有150多个深度学习框架提出了各种文本分类问题。
文本分类问题中使用了几个基准数据集,可以在nlpprogress.com上跟踪最新的基准。以下是关于这些数据集的基本统计数据。

简单的文本分类应用程序通常遵循以下步骤:
- 文本预处理和清理
- 特征工程(手动从文本创建特征)
- 特征向量化(TfIDF、频数、编码)或嵌入(word2vec、doc2vec、Bert、Elmo、句子嵌入等)
- 用ML和DL算法训练模型。
Spark-NLP中的文本分类
在本文中,我们将使用通用句子嵌入(Universal Sentence Embeddings)在Spark NLP中建立一个文本分类模型。然后我们将与其他ML和DL方法以及文本向量化方法进行比较。
Spark NLP中有几个文本分类选项:
- Spark-NLP中的文本预处理及基于Spark-ML的ML算法
- Spark-NLP和ML算法中的文本预处理和单词嵌入(Glove,Bert,Elmo)
- Spark-NLP和ML算法中的文本预处理和句子嵌入(
Universal Sentence Encoders) - Spark-NLP中的文本预处理和ClassifierDL模块(基于TensorFlow)
正如我们在关于Spark NLP的重要文章中所深入讨论的,在ClassifierDL之前的所有这些文本处理步骤都可以在指定的管道序列中实现,并且每个阶段都是一个转换器或估计器。这些阶段按顺序运行,输入数据帧在通过每个阶段时进行转换。也就是说,数据按顺序通过各个管道。每个阶段的transform()方法更新数据集并将其传递到下一个阶段。借助于管道,我们可以确保训练和测试数据经过相同的特征处理步骤。
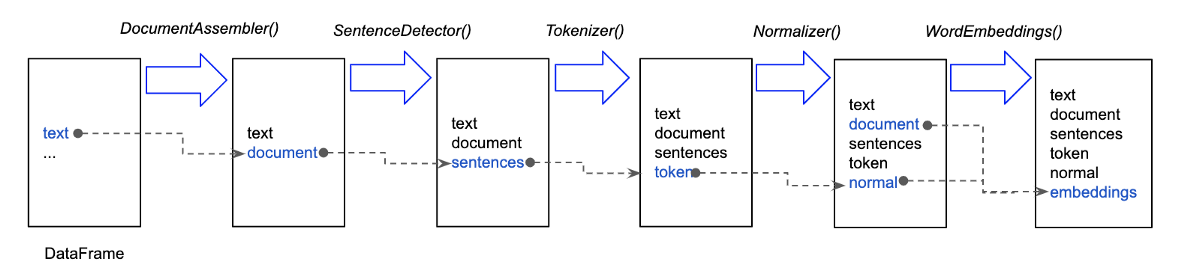
Universal Sentence Encoders
在自然语言处理(NLP)中,在建立任何深度学习模型之前,文本嵌入起着重要的作用。文本嵌入将文本(单词或句子)转换为向量。
基本上,文本嵌入方法在固定长度的向量中对单词和句子进行编码,以极大地改进文本数据的处理。这个想法很简单:出现在相同上下文中的单词往往有相似的含义。
像Word2vec和Glove这样的技术是通过将一个单词转换成向量来实现的。因此,对应的向量“猫”比“鹰”更接近“狗”。但是,当嵌入一个句子时,整个句子的上下文需要被捕获到这个向量中。这就是“Universal Sentence Encoders”的功能了。
Universal Sentence Encoders将文本编码成高维向量,可用于文本分类、语义相似性、聚类和其他自然语言任务。在Tensorflow hub中可以公开使用预训练的Universal Sentence Encoders。它有两种变体,一种是用Transformer编码器训练的,另一种是用深度平均网络(DAN)训练的。
Spark NLP使用Tensorflow hub版本,该版本以一种在Spark环境中运行的方式包装。也就是说,你只需在Spark NLP中插入并播放此嵌入,然后以分布式方式训练模型。
为句子生成嵌入,无需进一步计算,因为我们并不是平均句子中每个单词的单词嵌入来获得句子嵌入。
Spark-NLP中ClassifierDL和USE在文本分类的应用
在本文中,我们将使用AGNews数据集(文本分类任务中的基准数据集之一)在Spark NLP中使用USE和ClassifierDL构建文本分类器,后者是Spark NLP 2.4.4版中添加的最新模块。
ClassifierDL是Spark NLP中第一个多类文本分类器,它使用各种文本嵌入作为文本分类的输入。ClassifierDLAnnotator使用了一个在TensorFlow内部构建的深度学习模型(DNN),它最多支持50个类。
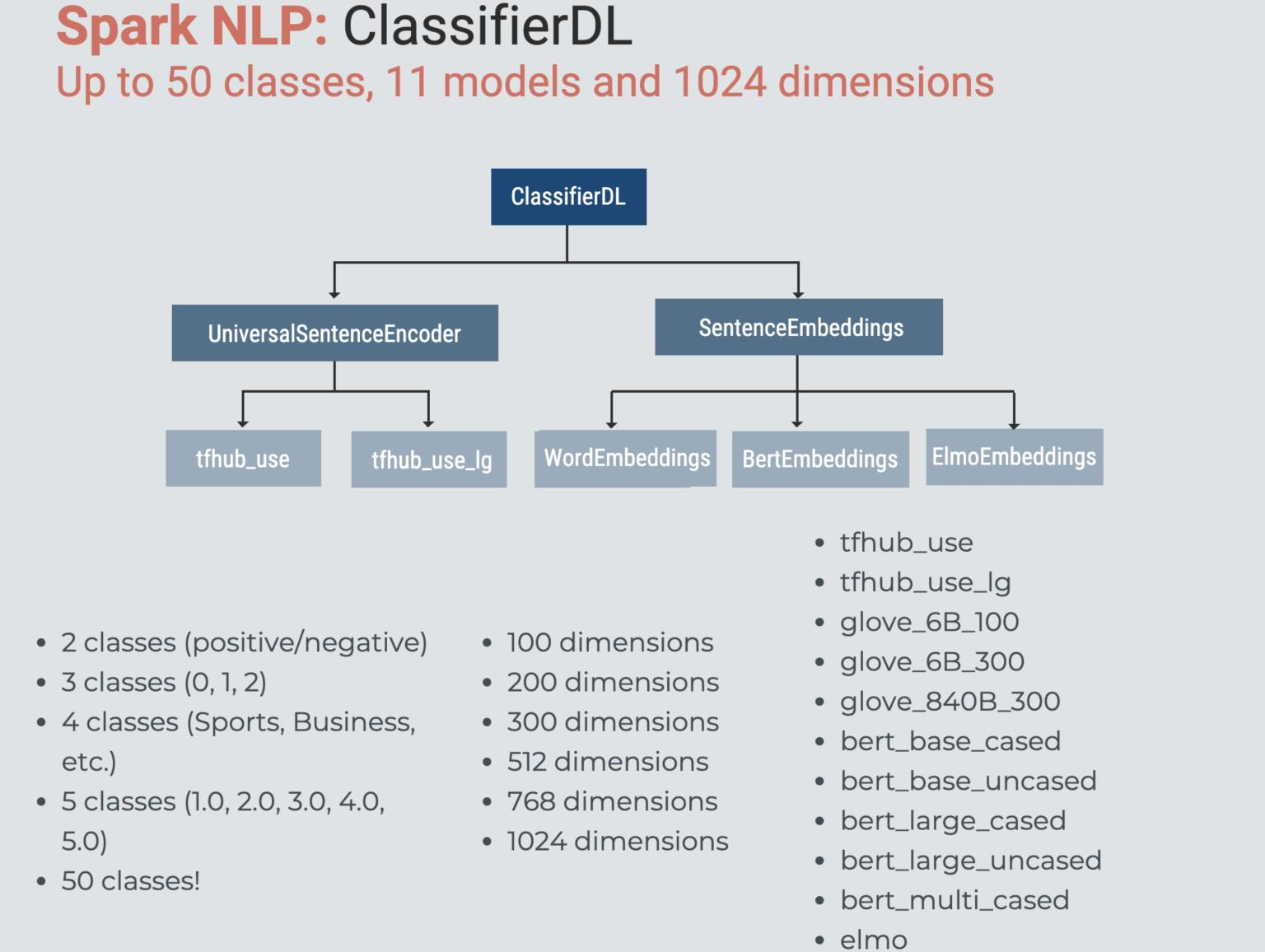
也就是说,你可以用这个classifirdl在Spark NLP中用Bert、Elmo、Glove和Universal Sentence Encoders构建一个文本分类器。
我们开始写代码吧!
声明加载必要的包并启动一个Spark会话。
import sparknlp
spark = sparknlp.start()
# sparknlp.start(gpu=True) >> 在GPU上训练
from sparknlp.base import *
from sparknlp.annotator import *
from pyspark.ml import Pipeline
import pandas as pd
print("Spark NLP version", sparknlp.version())
print("Apache Spark version:", spark.version)
>> Spark NLP version 2.4.5
>> Apache Spark version: 2.4.4
然后我们可以从Github repo下载AGNews数据集(https://github.com/JohnSnowLabs/spark-nlp-workshop/tree/master/tutorials/Certification_Trainings/Public)。
! wget https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp-workshop/master/tutorials/Certification_Trainings/Public/data/news_category_train.csv
! wget https://raw.githubusercontent.com/JohnSnowLabs/spark-nlp-workshop/master/tutorials/Certification_Trainings/Public/data/news_category_test.csv
trainDataset = spark.read
.option("header", True)
.csv("news_category_train.csv")
trainDataset.show(10, truncate=50)
>>
+--------+--------------------------------------------------+
|category| description|
+--------+--------------------------------------------------+
|Business| Short sellers, Wall Street's dwindling band of...|
|Business| Private investment firm Carlyle Group, which h...|
|Business| Soaring crude prices plus worries about the ec...|
|Business| Authorities have halted oil export flows from ...|
|Business| Tearaway world oil prices, toppling records an...|
|Business| Stocks ended slightly higher on Friday but sta...|
|Business| Assets of the nation's retail money market mut...|
|Business| Retail sales bounced back a bit in July, and n...|
|Business|" After earning a PH.D. in Sociology, Danny Baz...|
|Business| Short sellers, Wall Street's dwindling band o...|
+--------+--------------------------------------------------+
only showing top 10 rows
AGNews数据集有4个类:World、Sci/Tech、Sports、Business
from pyspark.sql.functions import col
trainDataset.groupBy("category")
.count()
.orderBy(col("count").desc())
.show()
>>
+--------+-----+
|category|count|
+--------+-----+
| World|30000|
|Sci/Tech|30000|
| Sports|30000|
|Business|30000|
+--------+-----+
testDataset = spark.read
.option("header", True)
.csv("news_category_test.csv")
testDataset.groupBy("category")
.count()
.orderBy(col("count").desc())
.show()
>>
+--------+-----+
|category|count|
+--------+-----+
|Sci/Tech| 1900|
| Sports| 1900|
| World| 1900|
|Business| 1900|
+--------+-----+
现在,我们可以将这个数据提供给Spark NLP DocumentAssembler,它是任何Spark datagram的Spark NLP的入口点。
# 实际内容在description列
document = DocumentAssembler()
.setInputCol("description")
.setOutputCol("document")
#我们可以下载预先训练好的嵌入
use = UniversalSentenceEncoder.pretrained()
.setInputCols(["document"])
.setOutputCol("sentence_embeddings")
# classes/labels/categories 在category列
classsifierdl = ClassifierDLApproach()
.setInputCols(["sentence_embeddings"])
.setOutputCol("class")
.setLabelColumn("category")
.setMaxEpochs(5)
.setEnableOutputLogs(True)
use_clf_pipeline = Pipeline(
stages = [
document,
use,
classsifierdl
])
以上,我们获取数据集,输入,然后从使用中获取句子嵌入,然后在ClassifierDL中进行训练
现在我们开始训练。我们将使用ClassiferDL中的.setMaxEpochs()训练5个epoch。在Colab环境下,这大约需要10分钟才能完成。
use_pipelineModel = use_clf_pipeline.fit(trainDataset)
运行此命令时,Spark NLP会将训练日志写入主目录中的annotator_logs文件夹。下面是得到的日志。
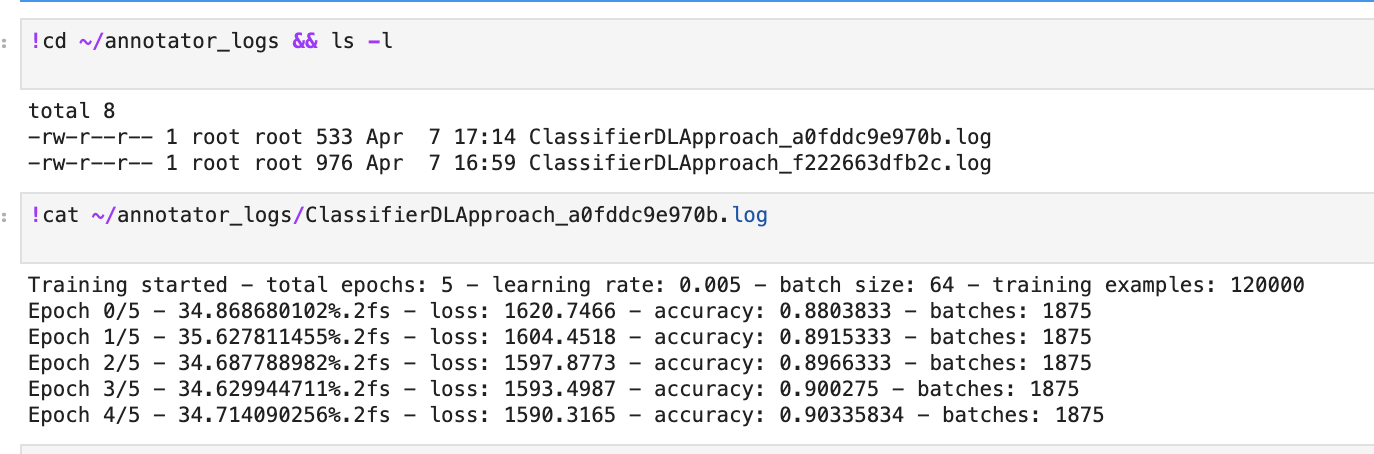
如你所见,我们在不到10分钟的时间内就实现了90%以上的验证精度,而无需进行文本预处理,这通常是任何NLP建模中最耗时、最费力的一步。
现在让我们在最早的时候得到预测。我们将使用上面下载的测试集。

下面是通过sklearn库中的classification_report获得测试结果。
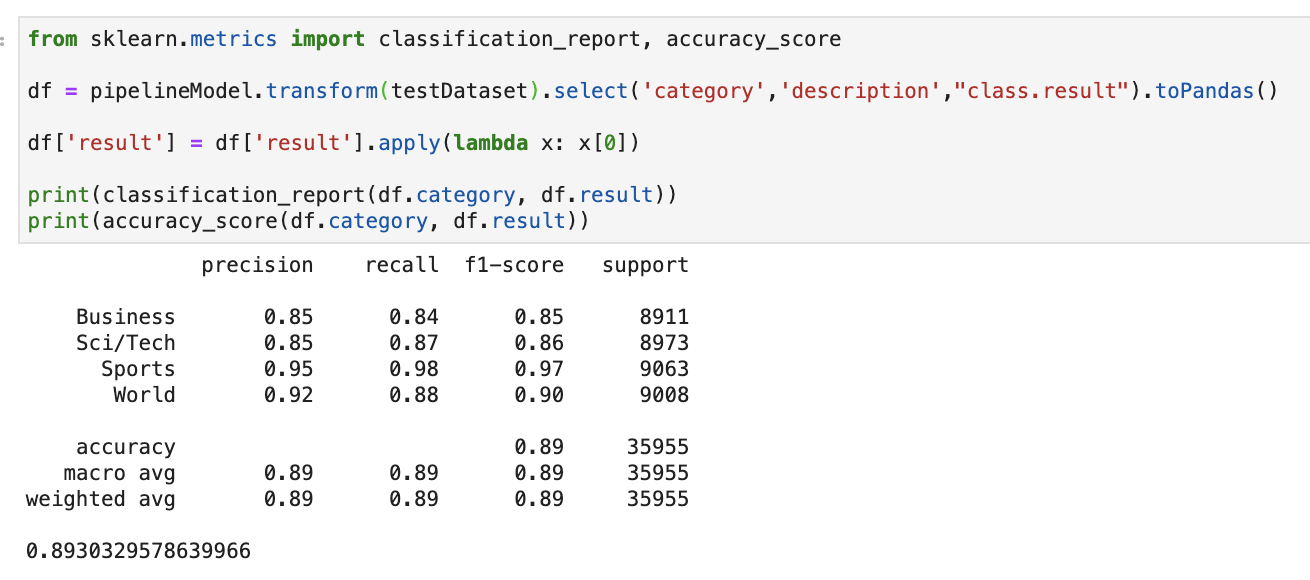
我们达到了89.3%的测试集精度!看起来不错!
基于Bert和globe嵌入的Spark-NLP文本预处理分类
与任何文本分类问题一样,有很多有用的文本预处理技术,包括词干、词干分析、拼写检查和停用词删除,而且除了拼写检查之外,Python中几乎所有的NLP库都有应用这些技术的工具。目前,Spark NLP库是唯一一个具备拼写检查功能的可用NLP库。
让我们在Spark NLP管道中应用这些步骤,然后使用glove嵌入来训练文本分类器。我们将首先应用几个文本预处理步骤(仅通过保留字母顺序进行标准化,删除停用词字和词干化),然后获取每个标记的单词嵌入(标记的词干),然后平均每个句子中的单词嵌入以获得每行的句子嵌入。

关于Spark NLP中的所有这些文本预处理工具以及更多内容,你可以在这个Colab笔记本中找到详细的说明和代码示例(https://github.com/JohnSnowLabs/spark-nlp-workshop/blob/master/tutorials/Certification_Trainings/Public/2.Text_Preprocessing_with_SparkNLP_Annotators_Transformers.ipynb)。
那我们就可以训练了。
clf_pipelineModel = clf_pipeline.fit(trainDataset)
得到测试结果。
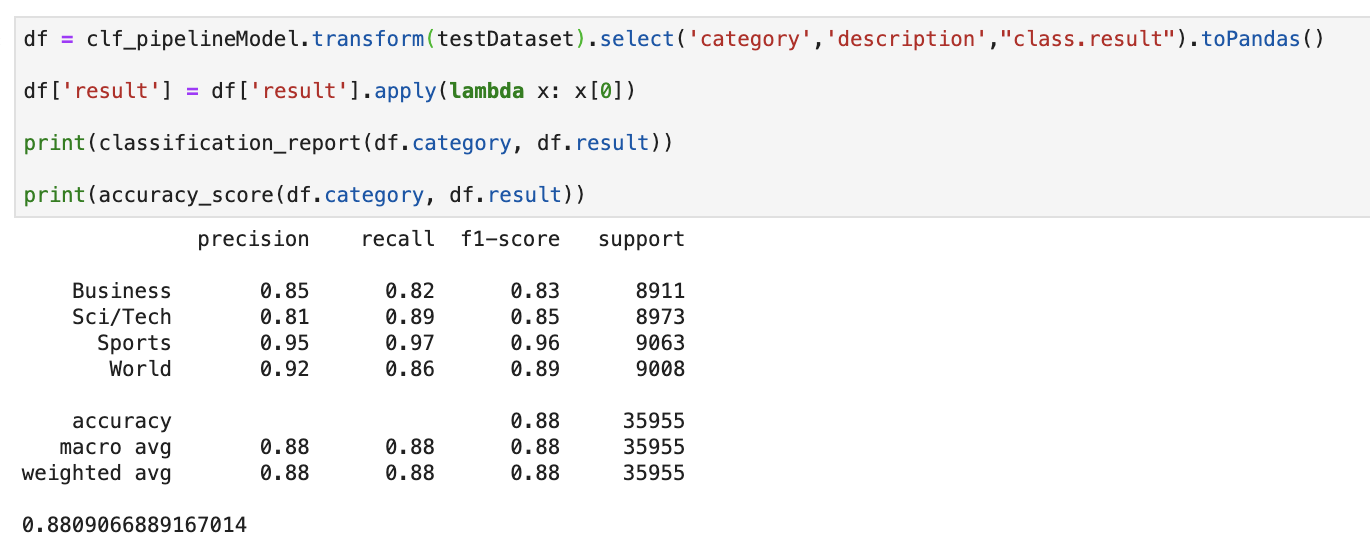
现在我们有88%的测试集精度!即使在所有这些文本清理步骤之后,我们仍然无法击败Universal Sentence Embeddings+ClassifierDL,这主要是因为USE相对于数据清理后的版本,它在原始文本上执行得更好。
为了训练与BERT相同的分类器,我们可以在上面构建的同一管道中用BERT_embedding替换glove_embeddings。
word_embeddings = BertEmbeddings
.pretrained('bert_base_cased', 'en')
.setInputCols(["document",'lemma'])
.setOutputCol("embeddings")
.setPoolingLayer(-2) # default 0
我们也可以使用Elmo嵌入。
word_embeddings = ElmoEmbeddings
.pretrained('elmo', 'en')
.setInputCols(["document",'lemma'])
.setOutputCol("embeddings")
使用LightPipeline进行快速推理
正如我们在前面的一篇文章中深入讨论的,LightPipelines是Spark NLP特有的管道,相当于Spark ML管道,但其目的是处理少量的数据。它们在处理小数据集、调试结果或从服务一次性请求的API运行训练或预测时非常有用。
Spark NLP LightPipelines是Spark ML管道转换成在单独的机器上,变成多线程的任务,对于较小的数据量(较小的是相对的,但5万个句子大致最大值)来说,速度快了10倍以上。要使用它们,我们只需插入一个经过训练的管道,我们甚至不需要将输入文本转换为DataFrame,就可以将其输入到一个管道中,该管道首先接受DataFrame作为输入。当需要从经过训练的ML模型中获得几行文本的预测时,这个功能将非常有用。
LightPipelines很容易创建,而且可以避免处理Spark数据集。它们的速度也非常快,当只在驱动节点上工作时,它们执行并行计算。让我们看看它是如何适用于我们上面描述的案例的:
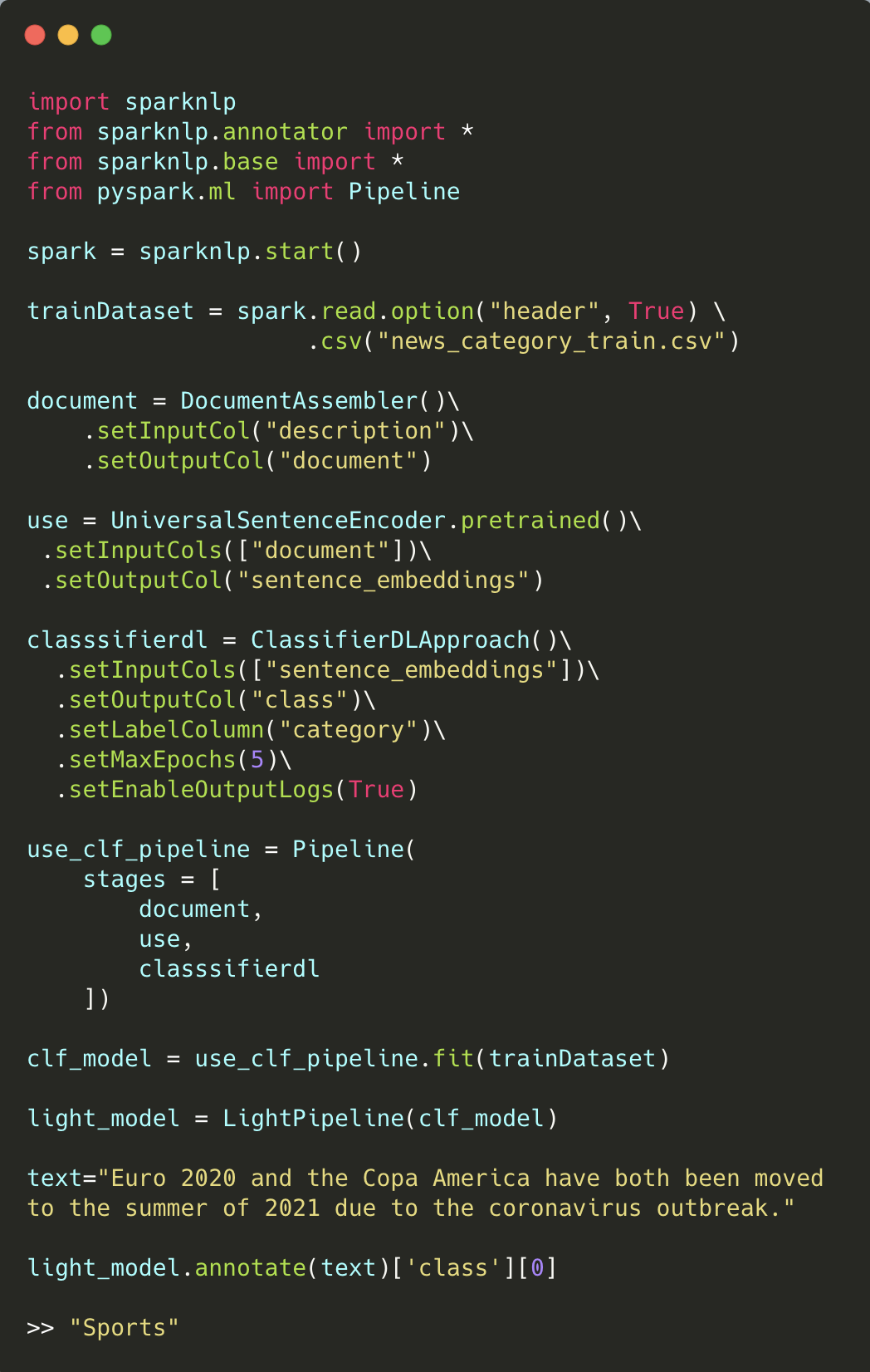
light_model = LightPipeline(clf_pipelineModel)
text="Euro 2020 and the Copa America have both been moved to the summer of 2021 due to the coronavirus outbreak."
light_model.annotate(text)['class'][0]
>> "Sports"
你还可以将这个经过训练的模型保存到磁盘中,然后稍后在另一个Spark管道中与ClassifierDLModel.load()一起使用。

结论
本文在Spark-NLP中利用词嵌入和Universal Sentence Encoders,训练了一个多类文本分类模型,在不到10min的训练时间内获得了较好的模型精度。整个代码都可以在这个Github repo中找到(Colab兼容,https://github.com/JohnSnowLabs/spark-nlp-workshop/blob/master/tutorials/Certification_Trainings/Public/5.Text_Classification_with_ClassifierDL.ipynb)。我们还准备了另一个Notebook,几乎涵盖了Spark NLP和Spark ML中所有可能的文本分类组合(CV、TfIdf、Glove、Bert、Elmo、USE、LR、RF、ClassifierDL、DocClassifier):https://github.com/JohnSnowLabs/spark-nlp-workshop/blob/master/tutorials/Certification_Trainings/Public/5.1_Text_classification_examples_in_SparkML_SparkNLP.ipynb。
我们还开始为公共和企业(医疗)版本提供在线Spark NLP训练。这里是所有公共Colab Notebook的链接(https://github.com/JohnSnowLabs/spark-nlp-workshop/tree/master/tutorials/Certification_Trainings/Public)
John Snow实验室将组织虚拟Spark NLP训练,以下是下一次训练的链接:
https://events.johnsnowlabs.com/online-training-spark-nlp
以上代码截图
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/