作者|Yuki Takahashi
编译|VK
来源|Towards Datas Science

自在ImageNet上推出AlexNet以来,计算机视觉的深度学习已成功应用于各种应用。相反,NLP在深层神经网络应用方面一直落后。许多声称使用人工智能的应用程序通常使用某种基于规则的算法和传统的机器学习,而不是使用深层神经网络。
2018年,在一些NLP任务中,一种名为BERT的最先进(STOA)模型的表现超过了人类的得分。在这里,我将几个模型应用于情绪分析任务,以了解它们在我所处的金融市场中有多大用处。代码在jupyter notebook中,在git repo中可用:https://github.com/yuki678/financial-phrase-bert
介绍
NLP任务可以大致分为以下几类。
-
文本分类——过滤垃圾邮件,对文档进行分类
-
词序——词翻译,词性标记,命名实体识别
-
文本意义——主题模型,搜索,问答
-
seq2seq——机器翻译、文本摘要、问答
-
对话系统
不同的任务需要不同的方法,在大多数情况下是多种NLP技术的组合。在开发机器人时,后端逻辑通常是基于规则的搜索引擎和排名算法,以形成自然的通信。
这是有充分理由的。语言有语法和词序,可以用基于规则的方法更好地处理,而机器学习方法可以更好地学习单词相似性。向量化技术如word2vec、bag of word帮助模型以数学方式表达文本。最著名的例子是:
King - Man + Woman = Queen
Paris - France + UK = London
第一个例子描述了性别关系,第二个例子描述了首都的概念。然而,在这些方法中,由于在任何文本中同一个词总是由同一个向量表示,因此上下文不能被捕获,这在许多情况下是不正确的。
循环神经网络(RNN)结构利用输入序列的先验信息,处理时间序列数据,在捕捉和记忆上下文方面表现良好。LSTM是一种典型的结构,它由输入门、输出门和遗忘门组成,克服了RNN的梯度问题。有许多基于LSTM的改进模型,例如双向LSTM,不仅可以从前面的单词中捕捉上下文,而且可以从后面捕获上下文。这些方法对于某些特定的任务是有用的,但在实际应用中却不太适用。
2017年,我们看到了一种新的方法来解决这个问题。BERT是Google在2018年推出的一个多编码器堆栈的掩码语言模型,在GLUE、SQuAD和SWAG基准测试中实现了STOA,并有了很大的改进。有很多文章和博客解释了这种架构,比如Jay Alammar的文章:http://jalammar.github.io/illustrated-bert/
我在金融行业工作,在过去的几年里,我很难看到我们在NLP上的机器学习模型在交易系统中的生产应用方面有足够的强劲表现。现在,基于BERT的模型正在变得成熟和易于使用,这要归功于Huggingface的实现和许多预训练的模型已经公开。
我的目标是看看这个NLP的最新开发是否达到了在我的领域中使用的良好水平。在这篇文章中,我比较了不同的模型,这是一个相当简单的任务,即对金融文本的情绪分析,以此作为基线来判断是否值得在真正的解决方案中尝试另一个研发。
此处比较的模型有:
-
基于规则的词典方法
-
基于Tfidf的传统机器学习方法
-
作为一种循环神经网络结构的LSTM
-
BERT(和ALBERT)
输入数据
在情绪分析任务中,我采用以下两种输入来表示行业中的不同语言。
-
财经新闻标题——正式
-
来自Stocktwits的Tweets——非正式
我将为后者写另一篇文章,所以这里关注前者的数据。这是一个包含更正式的金融领域特定语言的文本示例,我使用了Malo等人的FinancialPhraseBank(https://www.researchgate.net/publication/251231107_Good_Debt_or_Bad_Debt_Detecting_Semantic_Orientations_in_Economic_Texts)包括4845篇由16人手写的标题文本,并提供同意等级。我使用了75%的同意等级和3448个文本作为训练数据。
## 输入文本示例
positive "Finnish steel maker Rautaruukki Oyj ( Ruukki ) said on July 7 , 2008 that it won a 9.0 mln euro ( $ 14.1 mln ) contract to supply and install steel superstructures for Partihallsforbindelsen bridge project in Gothenburg , western Sweden."
neutral "In 2008 , the steel industry accounted for 64 percent of the cargo volumes transported , whereas the energy industry accounted for 28 percent and other industries for 8 percent."
negative "The period-end cash and cash equivalents totaled EUR6 .5 m , compared to EUR10 .5 m in the previous year."

请注意,所有数据都属于来源,用户必须遵守其版权和许可条款。
模型
下面是我比较了四款模型的性能。
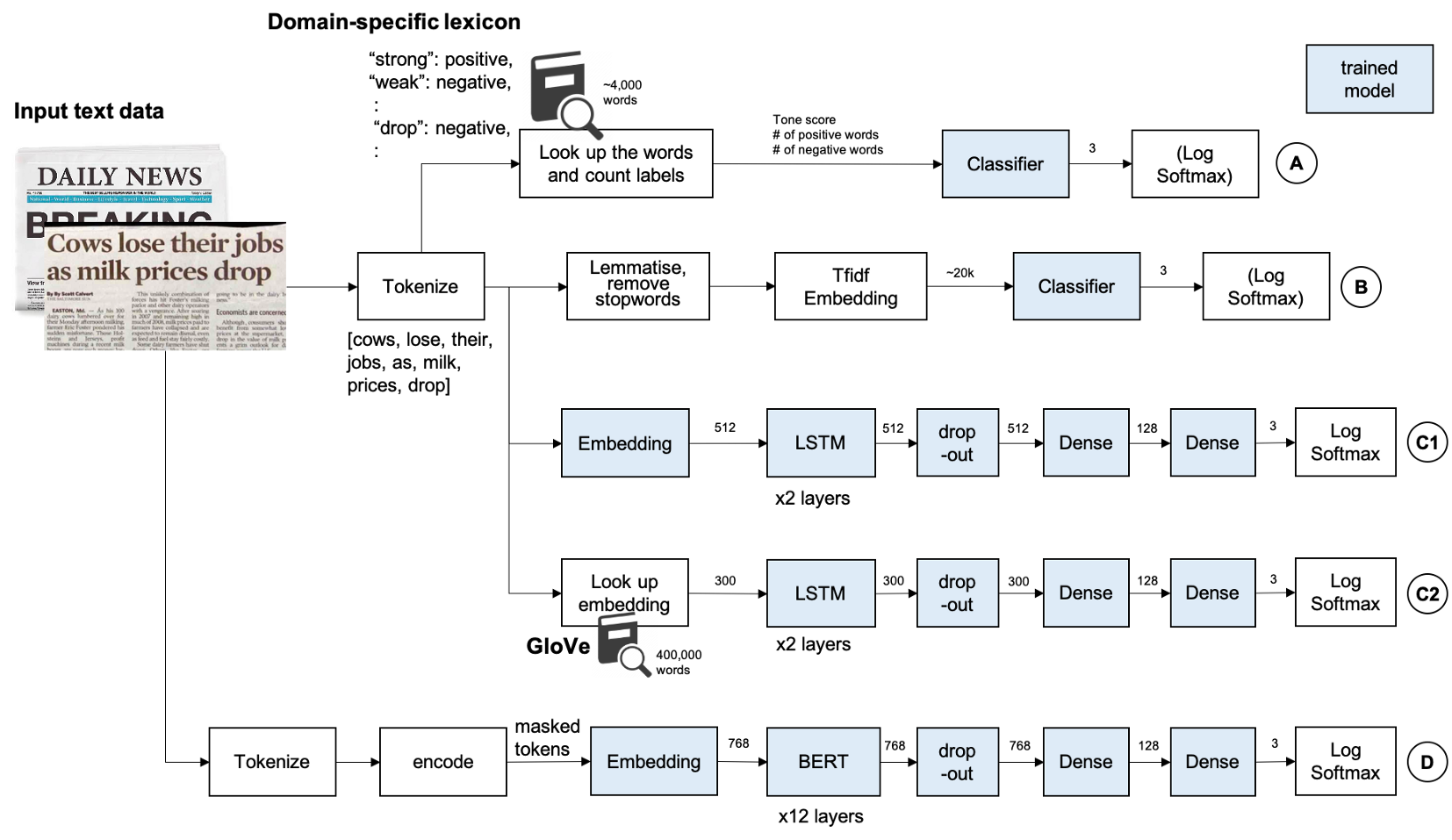
A、 基于词汇的方法
创建特定于领域的词典是一种传统的方法,在某些情况下,如果源代码来自特定的个人或媒体,则这种方法简单而强大。Loughran和McDonald情感词列表。这个列表包含超过4k个单词,这些单词出现在带有情绪标签的财务报表上。注:此数据需要许可证才能用于商业应用。请在使用前检查他们的网站。
## 样本
negative: ABANDON
negative: ABANDONED
constraining: STRICTLY
我用了2355个消极单词和354个积极单词。它包含单词形式,因此不要对输入执行词干分析和词干化。对于这种方法,考虑否定形式是很重要的。比如not,no,don,等等。这些词会把否定词的意思改为肯定的,如果前面三个词中有否定词,这里我简单地把否定词的意思转换成肯定词。
然后,情感得分定义如下。
tone_score = 100 * (pos_count — neg_count) / word_count
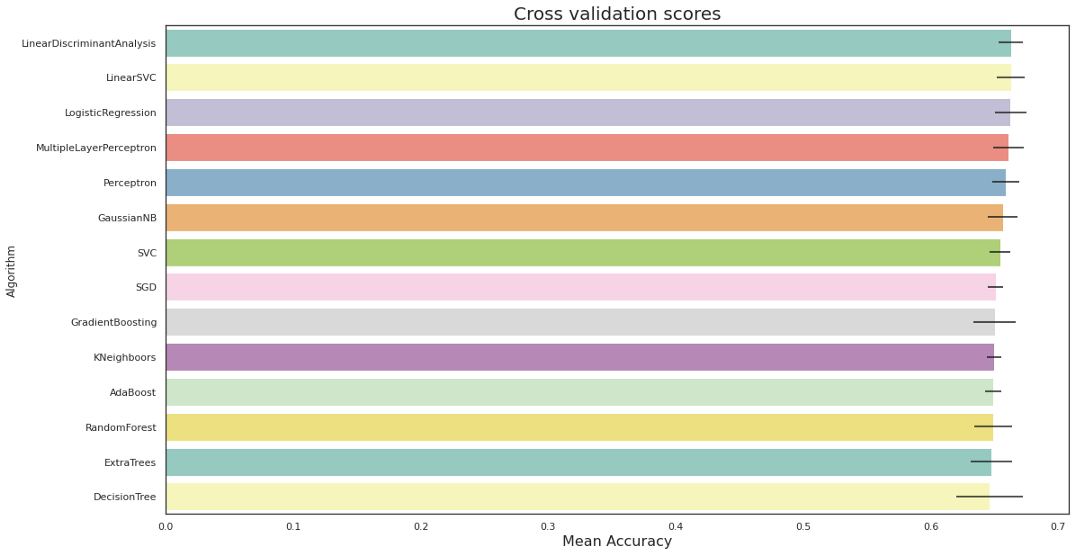
用默认参数训练14个不同的分类器,然后用网格搜索交叉验证法对随机森林进行超参数整定。
classifiers = []
classifiers.append(("SVC", SVC(random_state=random_state)))
classifiers.append(("DecisionTree", DecisionTreeClassifier(random_state=random_state)))
classifiers.append(("AdaBoost", AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state),random_state=random_state,learning_rate=0.1)))
classifiers.append(("RandomForest", RandomForestClassifier(random_state=random_state, n_estimators=100)))
classifiers.append(("ExtraTrees", ExtraTreesClassifier(random_state=random_state)))
classifiers.append(("GradientBoosting", GradientBoostingClassifier(random_state=random_state)))
classifiers.append(("MultipleLayerPerceptron", MLPClassifier(random_state=random_state)))
classifiers.append(("KNeighboors", KNeighborsClassifier(n_neighbors=3)))
classifiers.append(("LogisticRegression", LogisticRegression(random_state = random_state)))
classifiers.append(("LinearDiscriminantAnalysis", LinearDiscriminantAnalysis()))
classifiers.append(("GaussianNB", GaussianNB()))
classifiers.append(("Perceptron", Perceptron()))
classifiers.append(("LinearSVC", LinearSVC()))
classifiers.append(("SGD", SGDClassifier()))
cv_results = []
for classifier in classifiers :
cv_results.append(cross_validate(classifier[1], X_train, y=Y_train, scoring=scoring, cv=kfold, n_jobs=-1))
# 使用随机森林分类器
rf_clf = RandomForestClassifier()
# 执行网格搜索
param_grid = {'n_estimators': np.linspace(1, 60, 10, dtype=int),
'min_samples_split': [1, 3, 5, 10],
'min_samples_leaf': [1, 2, 3, 5],
'max_features': [1, 2, 3],
'max_depth': [None],
'criterion': ['gini'],
'bootstrap': [False]}
model = GridSearchCV(rf_clf, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)
model.fit(X_train, Y_train)
rf_best = model.best_estimator_
B、 基于Tfidf向量的传统机器学习
输入被NLTK word_tokenize()标记化,然后词干化和删除停用词。然后输入到TfidfVectorizer ,通过Logistic回归和随机森林分类器进行分类。
### 逻辑回归
pipeline1 = Pipeline([
('vec', TfidfVectorizer(analyzer='word')),
('clf', LogisticRegression())])
pipeline1.fit(X_train, Y_train)
### 随机森林与网格搜索
pipeline2 = Pipeline([
('vec', TfidfVectorizer(analyzer='word')),
('clf', RandomForestClassifier())])
param_grid = {'clf__n_estimators': [10, 50, 100, 150, 200],
'clf__min_samples_leaf': [1, 2],
'clf__min_samples_split': [4, 6],
'clf__max_features': ['auto']
}
model = GridSearchCV(pipeline2, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)
model.fit(X_train, Y_train)
tfidf_best = model.best_estimator_
C、 LSTM
由于LSTM被设计用来记忆表达上下文的长期记忆,因此使用自定义的tokenizer并且输入是字符而不是单词,所以不需要词干化或输出停用词。输入先到一个嵌入层,然后是两个lstm层。为了避免过拟合,应用dropout,然后是全连接层,最后采用log softmax。
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_size, lstm_size, dense_size, output_size, lstm_layers=2, dropout=0.1):
"""
初始化模型
"""
super().__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.lstm_size = lstm_size
self.dense_size = dense_size
self.output_size = output_size
self.lstm_layers = lstm_layers
self.dropout = dropout
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, lstm_size, lstm_layers, dropout=dropout, batch_first=False)
self.dropout = nn.Dropout(dropout)
if dense_size == 0:
self.fc = nn.Linear(lstm_size, output_size)
else:
self.fc1 = nn.Linear(lstm_size, dense_size)
self.fc2 = nn.Linear(dense_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def init_hidden(self, batch_size):
"""
初始化隐藏状态
"""
weight = next(self.parameters()).data
hidden = (weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_(),
weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_())
return hidden
def forward(self, nn_input_text, hidden_state):
"""
在nn_input上执行模型的前项传播
"""
batch_size = nn_input_text.size(0)
nn_input_text = nn_input_text.long()
embeds = self.embedding(nn_input_text)
lstm_out, hidden_state = self.lstm(embeds, hidden_state)
# 堆叠LSTM输出,应用dropout
lstm_out = lstm_out[-1,:,:]
lstm_out = self.dropout(lstm_out)
# 全连接层
if self.dense_size == 0:
out = self.fc(lstm_out)
else:
dense_out = self.fc1(lstm_out)
out = self.fc2(dense_out)
# Softmax
logps = self.softmax(out)
return logps, hidden_state
作为替代,还尝试了斯坦福大学的GloVe词嵌入,这是一种无监督的学习算法,用于获取单词的向量表示。在这里,用6百万个标识、40万个词汇和300维向量对Wikipedia和Gigawords进行了预训练。在我们的词汇表中,大约90%的单词都是在这个GloVe里找到的,其余的都是随机初始化的。
D、 BERT和ALBERT
我使用了Huggingface中的transformer实现BERT模型。现在他们提供了tokenizer和编码器,可以生成文本id、pad掩码和段id,可以直接在BertModel中使用,我们使用标准训练过程。
与LSTM模型类似,BERT的输出随后被传递到dropout,全连接层,然后应用log softmax。如果没有足够的计算资源预算和足够的数据,从头开始训练模型不是一个选择,所以我使用了预训练的模型并进行了微调。预训练的模型如下所示:
-
BERT:bert-base-uncased
-
ALBERT:albert-base-v2
预训练过的bert的训练过程如下所示。
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
def train_bert(model, tokenizer)
# 移动模型到GUP/CPU设备
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
# 将数据加载到SimpleDataset(自定义数据集类)
train_ds = SimpleDataset(x_train, y_train)
valid_ds = SimpleDataset(x_valid, y_valid)
# 使用DataLoader批量加载数据集中的数据
train_loader = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_ds, batch_size=batch_size, shuffle=False)
# 优化器和学习率衰减
num_total_opt_steps = int(len(train_loader) * num_epochs)
optimizer = AdamW_HF(model.parameters(), lr=learning_rate, correct_bias=False)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_total_opt_steps*warm_up_proportion, num_training_steps=num_total_opt_steps) # PyTorch scheduler
# 训练
model.train()
# Tokenizer 参数
param_tk = {
'return_tensors': "pt",
'padding': 'max_length',
'max_length': max_seq_length,
'add_special_tokens': True,
'truncation': True
}
# 初始化
best_f1 = 0.
early_stop = 0
train_losses = []
valid_losses = []
for epoch in tqdm(range(num_epochs), desc="Epoch"):
# print('================ epoch {} ==============='.format(epoch+1))
train_loss = 0.
for i, batch in enumerate(train_loader):
# 传输到设备
x_train_bt, y_train_bt = batch
x_train_bt = tokenizer(x_train_bt, **param_tk).to(device)
y_train_bt = torch.tensor(y_train_bt, dtype=torch.long).to(device)
# 重设梯度
optimizer.zero_grad()
# 前馈预测
loss, logits = model(**x_train_bt, labels=y_train_bt)
# 反向传播
loss.backward()
# 损失
train_loss += loss.item() / len(train_loader)
# 梯度剪切
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
# 更新权重和学习率
optimizer.step()
scheduler.step()
train_losses.append(train_loss)
# 评估模式
model.eval()
# 初始化
val_loss = 0.
y_valid_pred = np.zeros((len(y_valid), 3))
with torch.no_grad():
for i, batch in enumerate(valid_loader):
# 传输到设备
x_valid_bt, y_valid_bt = batch
x_valid_bt = tokenizer(x_valid_bt, **param_tk).to(device)
y_valid_bt = torch.tensor(y_valid_bt, dtype=torch.long).to(device)
loss, logits = model(**x_valid_bt, labels=y_valid_bt)
val_loss += loss.item() / len(valid_loader)
valid_losses.append(val_loss)
# 计算指标
acc, f1 = metric(y_valid, np.argmax(y_valid_pred, axis=1))
# 如果改进了,保存模型。如果没有,那就提前停止
if best_f1 < f1:
early_stop = 0
best_f1 = f1
else:
early_stop += 1
print('epoch: %d, train loss: %.4f, valid loss: %.4f, acc: %.4f, f1: %.4f, best_f1: %.4f, last lr: %.6f' %
(epoch+1, train_loss, val_loss, acc, f1, best_f1, scheduler.get_last_lr()[0]))
if device == 'cuda:0':
torch.cuda.empty_cache()
# 如果达到耐心数,提前停止
if early_stop >= patience:
break
# 返回训练模式
model.train()
return model
评估
首先,输入数据以8:2分为训练组和测试集。测试集保持不变,直到所有参数都固定下来,并且每个模型只使用一次。由于数据集不用于计算交叉集,因此验证集不用于计算。此外,为了克服数据集不平衡和数据集较小的问题,采用分层K-Fold交叉验证进行超参数整定。

由于输入数据不平衡,因此评估以F1分数为基础,同时也参考了准确性。
def metric(y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='macro')
return acc, f1
scoring = {'Accuracy': 'accuracy', 'F1': 'f1_macro'}
refit = 'F1'
kfold = StratifiedKFold(n_splits=5)
模型A和B使用网格搜索交叉验证,而C和D的深层神经网络模型使用自定义交叉验证。
# 分层KFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=rand_seed)
# 循环
for n_fold, (train_indices, valid_indices) in enumerate(skf.split(y_train, y_train)):
# 模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
# 输入数据
x_train_fold = x_train[train_indices]
y_train_fold = y_train[train_indices]
x_valid_fold = x_train[valid_indices]
y_valid_fold = y_train[valid_indices]
# 训练
train_bert(model, x_train_fold, y_train_fold, x_valid_fold, y_valid_fold)
结果
基于BERT的微调模型在花费了或多或少相似的超参数调整时间之后,明显优于其他模型。
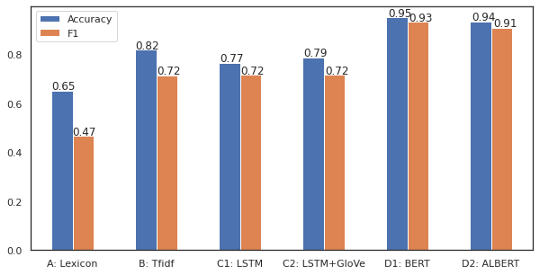
模型A表现不佳,因为输入过于简化为情感得分,情感分数是判断情绪的单一值,而随机森林模型最终将大多数数据标记为中性。简单的线性模型只需对情感评分应用阈值就可以获得更好的效果,但在准确度和f1评分方面仍然很低。

我们没有使用欠采样/过采样或SMOTE等方法来平衡输入数据,因为它可以纠正这个问题,但会偏离存在不平衡的实际情况。如果可以证明为每个要解决的问题建立一个词典的成本是合理的,这个模型的潜在改进是建立一个自定义词典,而不是L-M词典。
模型B比前一个模型好得多,但是它以几乎100%的准确率和f1分数拟合了训练集,但是没有被泛化。我试图降低模型的复杂度以避免过拟合,但最终在验证集中的得分较低。平衡数据可以帮助解决这个问题或收集更多的数据。


模型C产生了与前一个模型相似的结果,但改进不大。事实上,训练数据的数量不足以从零开始训练神经网络,需要训练到多个epoch,这往往会过拟合。预训练的GloVe并不能改善结果。对后一种模型的一个可能的改进是使用类似领域的大量文本(如10K、10Q财务报表)来训练GloVe,而不是使用维基百科中预训练过的模型。
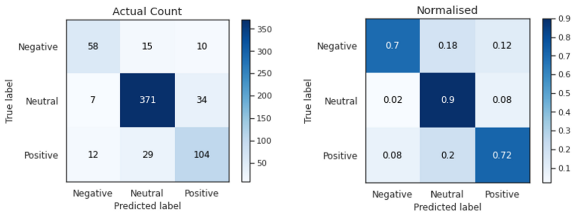
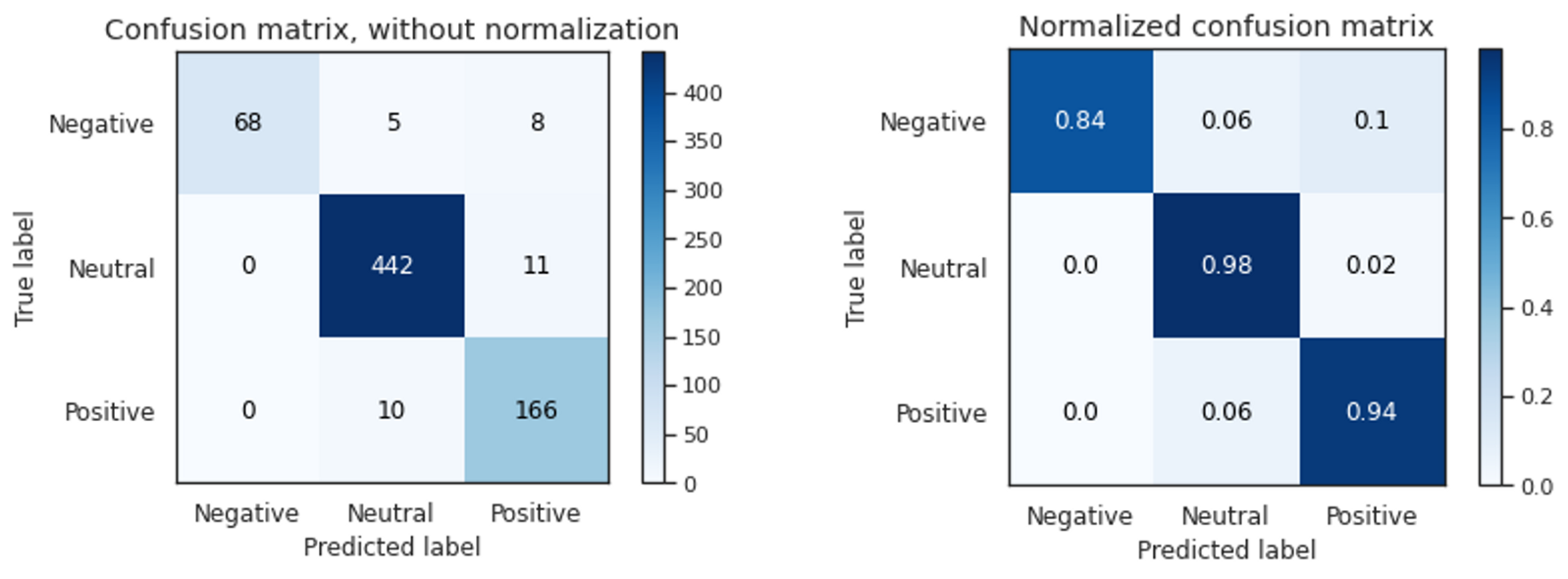
模型D在交叉验证和最终测试中的准确率和f1分数均达到90%以上。它正确地将负面文本分类为84%,而正面文本正确分类为94%,这可能是由于输入的数量,但最好仔细观察以进一步提高性能。这表明,由于迁移学习和语言模型,预训练模型的微调在这个小数据集上表现良好。


结论
这个实验展示了基于BERT的模型在我的领域中应用的潜力,以前的模型没有产生足够的性能。然而,结果不是确定性的,如果调整下超参数,结果可能会有所不同。
值得注意的是,在实际应用中,获取正确的输入数据也相当重要。没有高质量的数据(通常被称为“垃圾输入,垃圾输出”)就不能很好地训练模型。
我下次再谈这些问题。这里使用的所有代码都可以在git repo中找到:https://github.com/yuki678/financial-phrase-bert
原文链接:https://towardsdatascience.com/nlp-in-the-financial-market-sentiment-analysis-9de0dda95dc
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/