作者|Audhi Aprilliant
编译|VK
来源|Towards Datas Science

概述
对于这个项目,我们在2019年5月28-29日通过爬虫来使用Twitter的原始数据。此外,数据是CSV格式(逗号分隔),可以在这里下载。
它涉及两个主题,一个是包含关键字“Joko Widodo”的Joko Widodo的数据,另一个是带有关键字“Prabowo Subianto”的Prabowo Subianto的数据。其中包括几个变量和信息,以确定用户情绪。实际上,数据有16个变量或属性和1000多个观察值。表1列出了一些变量。
# 导入库
library(ggplot2)
library(lubridate)
# 加载Joko Widodo的数据
data.jokowi.df = read.csv(file = 'data-joko-widodo.csv',
header = TRUE,
sep = ',')
senti.jokowi = read.csv(file = 'sentiment-joko-widodo.csv',
header = TRUE,
sep = ',')
# 加载Prabowo Subianto的数据
data.prabowo.df = read.csv(file = 'data-prabowo-subianto.csv',
header = TRUE,
sep = ',')
senti.prabowo = read.csv(file = 'sentiment-prabowo-subianto.csv',
header = TRUE,
sep = ',')
数据可视化
数据探索旨在从Twitter数据中获取任何信息。应该指出的是,数据已经进行了文本预处理。我们对那些被认为是很有趣的变量进行探索。。
# TWEETS的条形图-JOKO WIDODO
data.jokowi.df$created = ymd_hms(data.jokowi.df$created,
tz = 'Asia/Jakarta')
# 另一种制作“date”和“hour”变量的方法
data.jokowi.df$date = date(data.jokowi.df$created)
data.jokowi.df$hour = hour(data.jokowi.df$created)
# 日期2019-05-29
data.jokowi.date1 = subset(x = data.jokowi.df,
date == '2019-05-29')
data.hour.date1 = data.frame(table(data.jokowi.date1$hour))
colnames(data.hour.date1) = c('Hour','Total.Tweets')
# 创建数据可视化
ggplot(data.hour.date1)+
geom_bar(aes(x = Hour,
y = Total.Tweets,
fill = I('blue')),
stat = 'identity',
alpha = 0.75,
show.legend = FALSE)+
geom_hline(yintercept = mean(data.hour.date1$Total.Tweets),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average:',
ceiling(mean(data.hour.date1$Total.Tweets)),
'Tweets per hour'),
x = 8,
y = mean(data.hour.date1$Total.Tweets)+20),
hjust = 'left',
size = 4)+
labs(title = 'Total Tweets per Hours - Joko Widodo',
subtitle = '28 May 2019',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Time of Day')+
ylab('Total Tweets')+
scale_fill_brewer(palette = 'Dark2')+
theme_bw()
# TWEETS的条形图-PRABOWO SUBIANTO
data.prabowo.df$created = ymd_hms(data.prabowo.df$created,
tz = 'Asia/Jakarta')
# 另一种制作“date”和“hour”变量的方法
data.prabowo.df$date = date(data.prabowo.df$created)
data.prabowo.df$hour = hour(data.prabowo.df$created)
# 日期2019-05-28
data.prabowo.date1 = subset(x = data.prabowo.df,
date == '2019-05-28')
data.hour.date1 = data.frame(table(data.prabowo.date1$hour))
colnames(data.hour.date1) = c('Hour','Total.Tweets')
# 日期 2019-05-29
data.prabowo.date2 = subset(x = data.prabowo.df,
date == '2019-05-29')
data.hour.date2 = data.frame(table(data.prabowo.date2$hour))
colnames(data.hour.date2) = c('Hour','Total.Tweets')
data.hour.date3 = rbind(data.hour.date1,data.hour.date2)
data.hour.date3$Date = c(rep(x = '2019-05-28',
len = nrow(data.hour.date1)),
rep(x = '2019-05-29',
len = nrow(data.hour.date2)))
data.hour.date3$Labels = c(letters,'A','B')
data.hour.date3$Hour = as.character(data.hour.date3$Hour)
data.hour.date3$Hour = as.numeric(data.hour.date3$Hour)
# 数据预处理
for (i in 1:nrow(data.hour.date3)) {
if (i%%2 == 0) {
data.hour.date3[i,'Hour'] = ''
}
if (i%%2 == 1) {
data.hour.date3[i,'Hour'] = data.hour.date3[i,'Hour']
}
}
data.hour.date3$Hour = as.factor(data.hour.date3$Hour)
# 数据可视化
ggplot(data.hour.date3)+
geom_bar(aes(x = Labels,
y = Total.Tweets,
fill = Date),
stat = 'identity',
alpha = 0.75,
show.legend = TRUE)+
geom_hline(yintercept = mean(data.hour.date3$Total.Tweets),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average:',
ceiling(mean(data.hour.date3$Total.Tweets)),
'Tweets per hour'),
x = 5,
y = mean(data.hour.date3$Total.Tweets)+6),
hjust = 'left',
size = 3.8)+
scale_x_discrete(limits = data.hour.date3$Labels,
labels = data.hour.date3$Hour)+
labs(title = 'Total Tweets per Hours - Prabowo Subianto',
subtitle = '28 - 29 May 2019',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Time of Day')+
ylab('Total Tweets')+
ylim(c(0,100))+
theme_bw()+
theme(legend.position = 'bottom',
legend.title = element_blank())+
scale_fill_brewer(palette = 'Dark2')
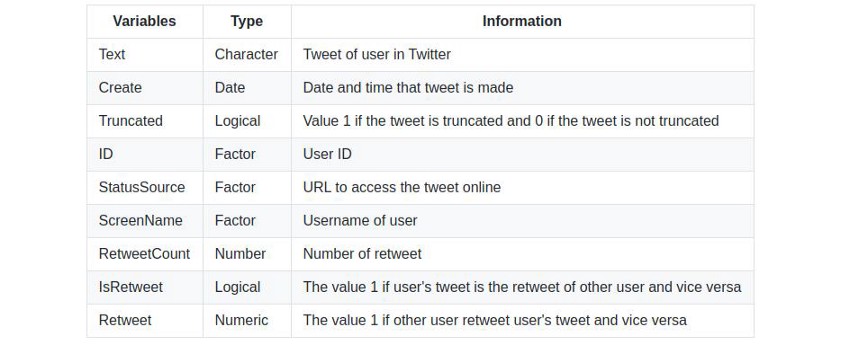
根据图1,我们可以得出结论,通过数据抓取(关键字“Jokow Widodo”和“Prabowo Subianto”)得到的tweet数量并不相似,即使在同一日期。
例如,在图1(左)中,从视觉上看,对于关键字为“Joko Widodo”的推文,仅在2019年5月28日03:00–17:00 WIB期间获得。而在图1(右图)中,我们得出的结论是,在2019年5月28日至29日12:00-23:59 WIB(2019年5月28日)和00:00-15:00 WIB(2019年5月29日)期间获得的关键词为“Prabowo Subianto”的推文。
# 2019-05-28的推特
ggplot(data.hour.date1)+
geom_bar(aes(x = Hour,
y = Total.Tweets,
fill = I('red')),
stat = 'identity',
alpha = 0.75,
show.legend = FALSE)+
geom_hline(yintercept = mean(data.hour.date1$Total.Tweets),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average:',
ceiling(mean(data.hour.date1$Total.Tweets)),
'Tweets per hour'),
x = 6.5,
y = mean(data.hour.date1$Total.Tweets)+5),
hjust = 'left',
size = 4)+
labs(title = 'Total Tweets per Hours - Prabowo Subianto',
subtitle = '28 May 2019',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Time of Day')+
ylab('Total Tweets')+
ylim(c(0,100))+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')
# 2019-05-29的推特
ggplot(data.hour.date2)+
geom_bar(aes(x = Hour,
y = Total.Tweets,
fill = I('red')),
stat = 'identity',
alpha = 0.75,
show.legend = FALSE)+
geom_hline(yintercept = mean(data.hour.date2$Total.Tweets),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average:',
ceiling(mean(data.hour.date2$Total.Tweets)),
'Tweets per hour'),
x = 1,
y = mean(data.hour.date2$Total.Tweets)+6),
hjust = 'left',
size = 4)+
labs(title = 'Total Tweets per Hours - Prabowo Subianto',
subtitle = '29 May 2019',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Time of Day')+
ylab('Total Tweets')+
ylim(c(0,100))+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')
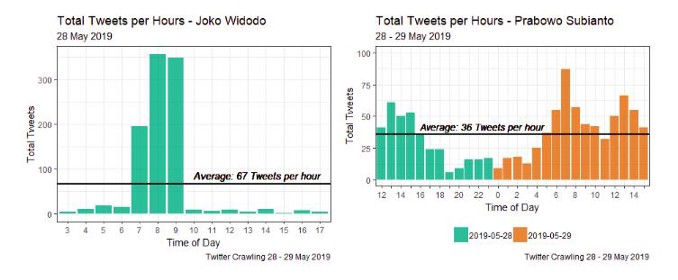
根据图2,我们得到了使用关键字“Joko Widodo”和“Prabowo Subianto”的用户之间的显著差异。关键词为“Joko Widodo”的tweet在某个特定时间(07:00–09:00 WIB)谈论Joko Widodo往往非常激烈,08:00 WIB的tweet数量最多。它有348条推文。然而,在2019年5月28日至29日期间,关键词为“Prabowo Subianto”的推文往往会不断地谈论Prabowo Subianto。2019年5月28日至29日,每小时上传关键词为“Prabowo Subianto”的推文平均为36条。
# JOKO WIDODO
df.score.1 = subset(senti.jokowi,class == c('Negative','Positive'))
colnames(df.score.1) = c('Score','Text','Sentiment')
# Data viz
ggplot(df.score.1)+
geom_density(aes(x = Score,
fill = Sentiment),
alpha = 0.75)+
xlim(c(-11,11))+
labs(title = 'Density Plot of Sentiment Scores',
subtitle = 'Joko Widodo',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Score')+
ylab('Density')+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')+
theme(legend.position = 'bottom',
legend.title = element_blank())
# PRABOWO SUBIANTO
df.score.2 = subset(senti.prabowo,class == c('Negative','Positive'))
colnames(df.score.2) = c('Score','Text','Sentiment')
ggplot(df.score.2)+
geom_density(aes(x = Score,
fill = Sentiment),
alpha = 0.75)+
xlim(c(-11,11))+
labs(title = 'Density Plot of Sentiment Scores',
subtitle = 'Prabowo Subianto',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Density')+
ylab('Score')+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')+
theme(legend.position = 'bottom',
legend.title = element_blank())
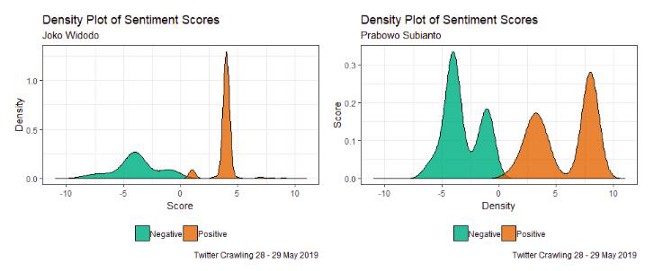
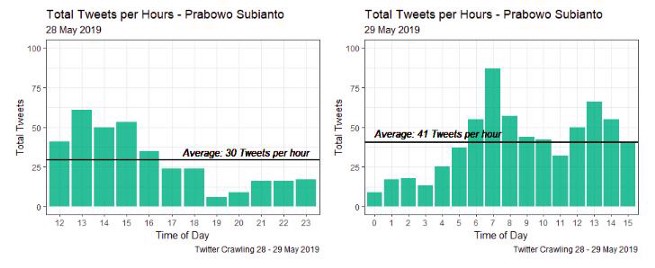
图3是2019年5月28日至29日以“Joko Widodo”和“Prabowo Subianto”为关键词的多条推文的条形图。由图3(左)可以得出,Twitter用户在19:00-23:59 WIB上谈论Prabowo Subianto的频率较低。这是由于印尼人的休息时间造成的。然而,这些带有主题的推文总是在午夜更新,因为有的用户居住在国外,有的用户仍然活跃。然后,用户在04:00 WIB开始活动,在07:00 WIB达到高峰,然后下降,直到12:00 WIB再次上升。
# JOKO WIDODO
df.senti.score.1 = data.frame(table(senti.jokowi$score))
colnames(df.senti.score.1) = c('Score','Freq')
# 数据预处理
df.senti.score.1$Score = as.character(df.senti.score.1$Score)
df.senti.score.1$Score = as.numeric(df.senti.score.1$Score)
Score1 = df.senti.score.1$Score
sign(df.senti.score.1[1,1])
for (i in 1:nrow(df.senti.score.1)) {
sign.row = sign(df.senti.score.1[i,'Score'])
for (j in 1:ncol(df.senti.score.1)) {
df.senti.score.1[i,j] = df.senti.score.1[i,j] * sign.row
}
}
df.senti.score.1$Label = c(letters[1:nrow(df.senti.score.1)])
df.senti.score.1$Sentiment = ifelse(df.senti.score.1$Freq < 0,
'Negative','Positive')
df.senti.score.1$Score1 = Score1
# 数据可视化
ggplot(df.senti.score.1)+
geom_bar(aes(x = Label,
y = Freq,
fill = Sentiment),
stat = 'identity',
show.legend = FALSE)+
# 积极情感
geom_hline(yintercept = mean(abs(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Positive'),'Freq'])),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average Freq:',
ceiling(mean(abs(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Positive'),'Freq'])))),
x = 10,
y = mean(abs(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Positive'),'Freq']))+30),
hjust = 'right',
size = 4)+
# 消极情感
geom_hline(yintercept = mean(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Negative'),'Freq']),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average Freq:',
ceiling(mean(abs(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Negative'),'Freq'])))),
x = 5,
y = mean(df.senti.score.1[which(df.senti.score.1$Sentiment == 'Negative'),'Freq'])-15),
hjust = 'left',
size = 4)+
labs(title = 'Barplot of Sentiments',
subtitle = 'Joko Widodo',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Score')+
scale_x_discrete(limits = df.senti.score.1$Label,
labels = df.senti.score.1$Score1)+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')
# PRABOWO SUBIANTO
df.senti.score.2 = data.frame(table(senti.prabowo$score))
colnames(df.senti.score.2) = c('Score','Freq')
# 数据预处理
df.senti.score.2$Score = as.character(df.senti.score.2$Score)
df.senti.score.2$Score = as.numeric(df.senti.score.2$Score)
Score2 = df.senti.score.2$Score
sign(df.senti.score.2[1,1])
for (i in 1:nrow(df.senti.score.2)) {
sign.row = sign(df.senti.score.2[i,'Score'])
for (j in 1:ncol(df.senti.score.2)) {
df.senti.score.2[i,j] = df.senti.score.2[i,j] * sign.row
}
}
df.senti.score.2$Label = c(letters[1:nrow(df.senti.score.2)])
df.senti.score.2$Sentiment = ifelse(df.senti.score.2$Freq < 0,
'Negative','Positive')
df.senti.score.2$Score1 = Score2
# 数据可视化
ggplot(df.senti.score.2)+
geom_bar(aes(x = Label,
y = Freq,
fill = Sentiment),
stat = 'identity',
show.legend = FALSE)+
# 积极情感
geom_hline(yintercept = mean(abs(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Positive'),'Freq'])),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average Freq:',
ceiling(mean(abs(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Positive'),'Freq'])))),
x = 11,
y = mean(abs(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Positive'),'Freq']))+20),
hjust = 'right',
size = 4)+
# 消极情感
geom_hline(yintercept = mean(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Negative'),'Freq']),
col = I('black'),
size = 1)+
geom_text(aes(fontface = 'italic',
label = paste('Average Freq:',
ceiling(mean(abs(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Negative'),'Freq'])))),
x = 9,
y = mean(df.senti.score.2[which(df.senti.score.2$Sentiment == 'Negative'),'Freq'])-10),
hjust = 'left',
size = 4)+
labs(title = 'Barplot of Sentiments',
subtitle = 'Prabowo Subianto',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlab('Score')+
scale_x_discrete(limits = df.senti.score.2$Label,
labels = df.senti.score.2$Score1)+
theme_bw()+
scale_fill_brewer(palette = 'Dark2')
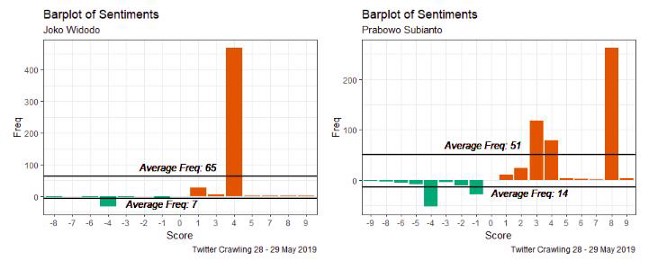
图4是包含关键字“Joko Widodo”和“Prabowo Subianto”的情感得分密度图。tweets的得分是由组成tweets的词根的平均得分得到的。因此,它的分数是针对每个词根给出的,其值介于-10到10之间。如果分数越小,那么微博中的负面情绪就越多,反之亦然。根据图4(左),可以得出结论,包含关键字“Joko Widodo”的推文的负面情绪在-10到-1之间,中间得分为-4。它也适用于积极的情绪(当然,有一个积极的分数)。根据图4(左)中的密度图,我们发现积极情绪的得分具有相当小的方差。因此,我们得出结论,对包含关键词“Joko Widodo”的微博的积极情绪并不是太多样化。
图4(右)显示了包含关键字“Prabowo Subianto”的情感得分密度图。它与图4(左)不同,因为图4(右)上的负面情绪在-8到-1之间。这意味着tweets没有太多负面情绪(tweets有负面情绪,但不够高)。此外,负面情绪得分的分布在4和1之间有两个峰值。然而,积极情绪从1到10不等。与图4(左)相比,图4(右)的积极情绪具有较高的方差,在3和10范围内有两个峰值。这表明,包含关键词“Prabowo Subianto”的微博具有很高的积极情绪。
# JOKO WIDODO
df.senti.3 = as.data.frame(table(senti.jokowi$class))
colnames(df.senti.3) = c('Sentiment','Freq')
# 数据预处理
df.pie.1 = df.senti.3
df.pie.1$Prop = df.pie.1$Freq/sum(df.pie.1$Freq)
df.pie.1 = df.pie.1 %>%
arrange(desc(Sentiment)) %>%
mutate(lab.ypos = cumsum(Prop) - 0.5*Prop)
# 数据可视化
ggplot(df.pie.1,
aes(x = 2,
y = Prop,
fill = Sentiment))+
geom_bar(stat = 'identity',
col = 'white',
alpha = 0.75,
show.legend = TRUE)+
coord_polar(theta = 'y',
start = 0)+
geom_text(aes(y = lab.ypos,
label = Prop),
color = 'white',
fontface = 'italic',
size = 4)+
labs(title = 'Piechart of Sentiments',
subtitle = 'Joko Widodo',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlim(c(0.5,2.5))+
theme_void()+
scale_fill_brewer(palette = 'Dark2')+
theme(legend.title = element_blank(),
legend.position = 'right')
# PRABOWO SUBIANTO
df.senti.4 = as.data.frame(table(senti.prabowo$class))
colnames(df.senti.4) = c('Sentiment','Freq')
# 数据预处理
df.pie.2 = df.senti.4
df.pie.2$Prop = df.pie.2$Freq/sum(df.pie.2$Freq)
df.pie.2 = df.pie.2 %>%
arrange(desc(Sentiment)) %>%
mutate(lab.ypos = cumsum(Prop) - 0.5*Prop)
# 数据可视化
ggplot(df.pie.2,
aes(x = 2,
y = Prop,
fill = Sentiment))+
geom_bar(stat = 'identity',
col = 'white',
alpha = 0.75,
show.legend = TRUE)+
coord_polar(theta = 'y',
start = 0)+
geom_text(aes(y = lab.ypos,
label = Prop),
color = 'white',
fontface = 'italic',
size = 4)+
labs(title = 'Piechart of Sentiments',
subtitle = 'Prabowo Subianto',
caption = 'Twitter Crawling 28 - 29 May 2019')+
xlim(c(0.5,2.5))+
theme_void()+
scale_fill_brewer(palette = 'Dark2')+
theme(legend.title = element_blank(),
legend.position = 'right')
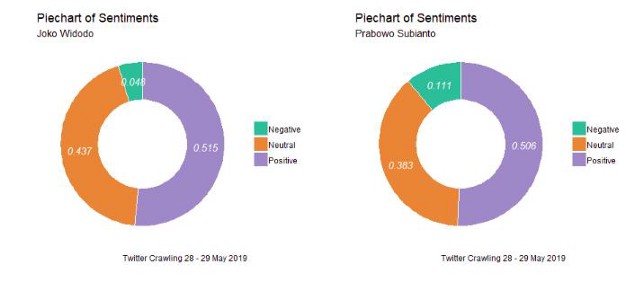
图5是推特的情绪得分汇总,这些微博被分为负面情绪、中性情绪和积极情绪。消极情绪是指得分低于零的情绪,中性是指分数等于零的情绪,积极情绪得分大于零。从图5可以看出,关键字为“Joko Widodo”的微博的负面情绪百分比低于关键字为“Prabowo Subianto”的tweet。有6.3%的差异。研究还发现,与关键词为Prabowo Subianto的微博相比,包含关键词“Joko Widodo”的微博具有更高的中性情绪和积极情绪。通过piechart的研究发现,与关键字为“Prabowo Subianto”的tweet相比,带有关键字“Joko Widodo”的tweet倾向于拥有更高比例的积极情绪。但是通过密度图发现,积极和消极情绪得分的分布表明,与“Joko Widodo”相比,包含关键字“Prabowo Subianto”的微博往往具有更高的情绪得分。它必须进行进一步的分析。

图6显示了用户在2019年5月28-29日经常上传的tweet(关键词“Joko Widodo”和“Prabowo Subianto”)中的术语或单词。通过这个WordCloud可视化,可以找到热门话题,这些话题都是针对关键词进行讨论的。对于包含关键词“Joko Widodo”的tweet,我们发现术语“tuang”、“petisi”、“negara”、“aman”和“nusantara”是前五名,每个tweet出现的次数最多。然而,包含关键词“Joko Widodo”的tweet发现,“Prabowo”、“Subianto”、“kriminalisasi”、“selamat”和“dubai”是每个tweet中出现次数最多的前五个词。这间接地显示了以关键字“Prabowo Subianto”上传的tweet的模式,即:几乎可以肯定的是,每个上传的tweet都直接包含“Prabowo Subianto”的名称,而不是通过提及(@)。这是因为,在文本预处理中,提到(@)已被删除。
可以前往我的GitHub repo查找代码:https://github.com/audhiaprilliant/Indonesia-Public-Election-Twitter-Sentiment-Analysis
参考引用
[1] K. Borau, C. Ullrich, J. Feng, R. Shen. Microblogging for Language Learning: Using Twitter to Train Communicative and Cultural Competence (2009), Advances in Web-Based Learning — ICWL 2009, 8th International Conference, Aachen, Germany, August 19–21, 2009.
原文链接:https://towardsdatascience.com/twitter-data-visualization-fb4f45b63728
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/