作者|Khuyen Tran
编译|VK
来源|Towards Data Science
动机
Sklearn是一个很好的库,有各种机器学习模型,可以用来训练数据。但是如果你的数据很大,你可能需要很长时间来训练你的数据,特别是当你用不同的超参数来寻找最佳模型时。
有没有一种方法可以使机器学习模型的训练速度比使用Sklearn的速度快150倍?答案就是你可以使用cuML。
下面的图表比较了使用Sklearn的RandomForestClassifier和cuML的RandomForestClassifier训练同一模型所需的时间。

cuML是一套快速的,GPU加速的机器学习算法,设计用于数据科学和分析任务。它的API类似于Sklearn的,这意味着你可以使用训练Sklearn模型的代码来训练cuML的模型。
from cuml.ensemble import RandomForestClassifier
clf = KNeighborsClassifier(n_neighbors=10)
clf.fit(X, y)
在本文中,我将比较使用不同模型的这两个库的性能。我还将演示如何增加显卡,使得速度提高10倍。
安装cuML
要安装cuML,请按照Rapids页面上的说明进行安装。请确保在安装库之前检查先决条件。你可以安装所有软件包,也可以只安装cuML。如果你的计算机空间有限,我建议安装cuDF和cuML。
虽然在很多情况下,不需要安装cuDF来使用cuML,但是cuDF是cuML的一个很好的补充,因为它是一个GPU数据帧。
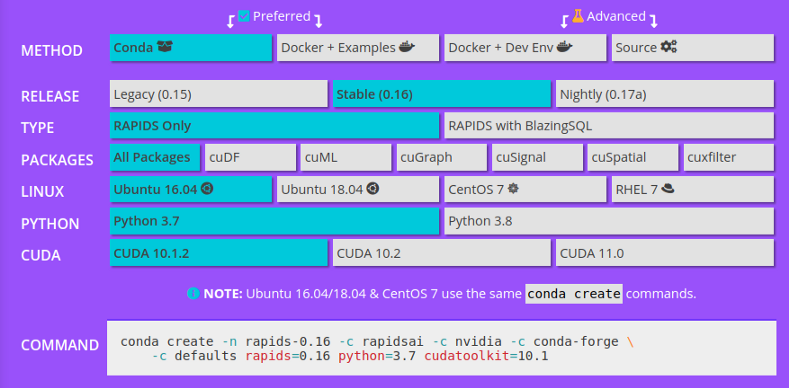
确保选择适合你计算机的选项。
创建数据
因为当有大量数据时,cuML通常比Sklearn更好,因此我们将使用sklearn.datasets.
从sklearn导入数据集
from sklearn import datasets
X, y = datasets.make_classification(n_samples=40000)
将数据类型转换为np.float32因为有些cuML模型要求输入是np.float32.
X = X.astype(np.float32)
y = y.astype(np.float32)
支持向量机
我们将创建用于训练模型的函数。使用此函数将使我们更容易比较不同的模型。
def train_data(model, X=X, y=y):
clf = model
clf.fit(X, y)
我们使用iPython的magic命令%timeit运行每个函数7次,取所有实验的平均值。
from sklearn.svm import SVC
from cuml.svm import SVC as SVC_gpu
clf_svc = SVC(kernel='poly', degree=2, gamma='auto', C=1)
sklearn_time_svc = %timeit -o train_data(clf_svc)
clf_svc = SVC_gpu(kernel='poly', degree=2, gamma='auto', C=1)
cuml_time_svc = %timeit -o train_data(clf_svc)
print(f"""Average time of sklearn's {clf_svc.__class__.__name__}""", sklearn_time_svc.average, 's')
print(f"""Average time of cuml's {clf_svc.__class__.__name__}""", cuml_time_svc.average, 's')
print('Ratio between sklearn and cuml is', sklearn_time_svc.average/cuml_time_svc.average)
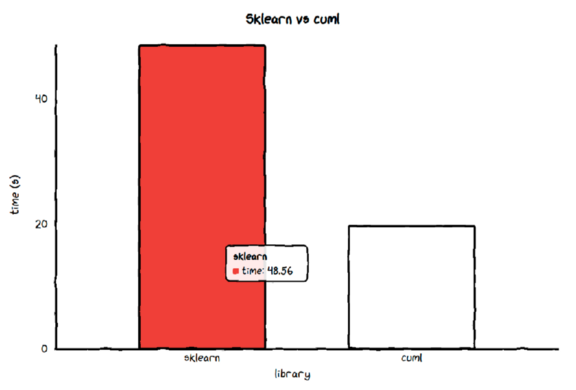
Average time of sklearn's SVC 48.56009825014287 s
Average time of cuml's SVC 19.611496431714304 s
Ratio between sklearn and cuml is 2.476103668030909
cuML的SVC比sklearn的SVC快2.5倍!
让我们通过图片来可视化它。我们创建一个函数来绘制模型的速度。
!pip install cutecharts
import cutecharts.charts as ctc
def plot(sklearn_time, cuml_time):
chart = ctc.Bar('Sklearn vs cuml')
chart.set_options(
labels=['sklearn', 'cuml'],
x_label='library',
y_label='time (s)',
)
chart.add_series('time', data=[round(sklearn_time.average,2), round(cuml_time.average,2)])
return chart
plot(sklearn_time_svc, cuml_time_svc).render_notebook()
更好的显卡
由于cuML的模型在运行大数据时比Sklearn的模型快,因为它们是用GPU训练的,如果我们将GPU的内存增加三倍会发生什么?
在前面的比较中,我使用的是一台搭载geforce2060的Alienware M15笔记本电脑和6.3gb的显卡内存。
现在,我将使用一个带有Quadro RTX 5000的Dell Precision 7740和17 GB的显卡内存来测试GPU内存增加时的速度。
Average time of sklearn's SVC 35.791008955999914 s
Average time of cuml's SVC 1.9953700327142931 s
Ratio between sklearn and cuml is 17.93702840535976
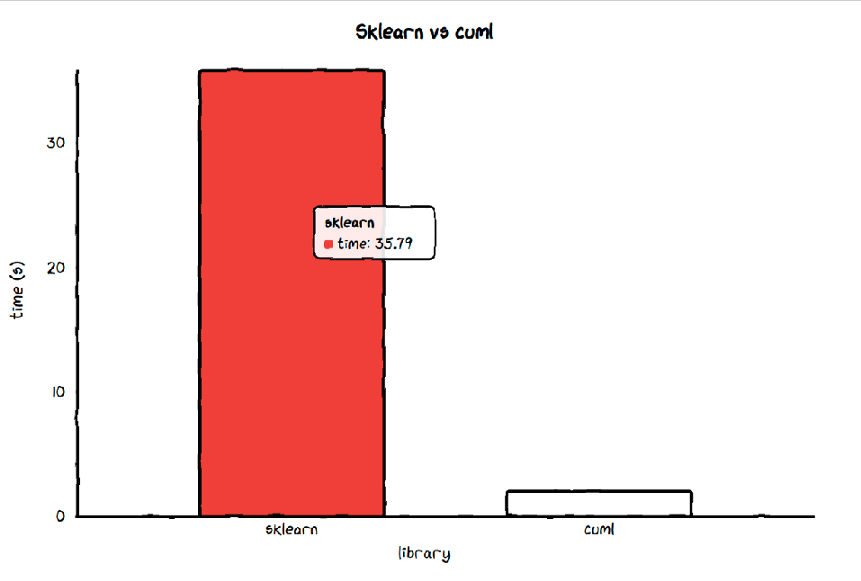
当它在一个显卡内存为17gb的机器上训练时,cuML的支持向量机比Sklearn的支持向量机快18倍!它的速度是笔记本电脑训练速度的10倍,显卡内存为6.3gb。
这就是为什么如果我们使用像cuML这样的GPU加速库。
随机森林分类器
clf_rf = RandomForestClassifier(max_features=1.0,
n_estimators=40)
sklearn_time_rf = %timeit -o train_data(clf_rf)
clf_rf = RandomForestClassifier_gpu(max_features=1.0,
n_estimators=40)
cuml_time_rf = %timeit -o train_data(clf_rf)
print(f"""Average time of sklearn's {clf_rf.__class__.__name__}""", sklearn_time_rf.average, 's')
print(f"""Average time of cuml's {clf_rf.__class__.__name__}""", cuml_time_rf.average, 's')
print('Ratio between sklearn and cuml is', sklearn_time_rf.average/cuml_time_rf.average)
Average time of sklearn's RandomForestClassifier 29.824075075857113 s
Average time of cuml's RandomForestClassifier 0.49404465585715635 s
Ratio between sklearn and cuml is 60.3671646323408
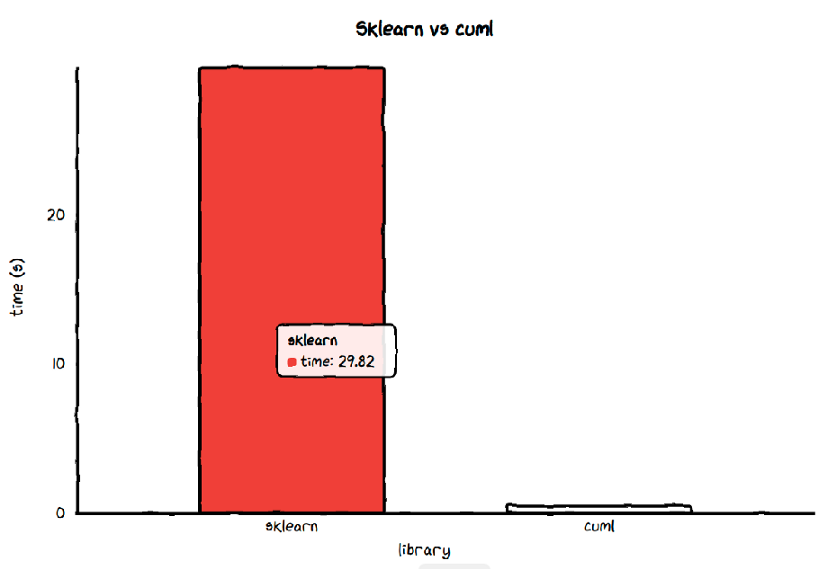
cuML的RandomForestClassifier比Sklearn的RandomForestClassifier快60倍!如果训练Sklearn的RandomForestClassifier需要30秒,那么训练cuML的RandomForestClassifier只需要不到半秒!
更好的显卡
Average time of Sklearn's RandomForestClassifier 24.006061030143037 s
Average time of cuML's RandomForestClassifier 0.15141178591425808 s.
The ratio between Sklearn’s and cuML is 158.54816641379068

在我的戴尔Precision 7740笔记本电脑上训练时,cuML的RandomForestClassifier比Sklearn的RandomForestClassifier快158倍!
最近邻分类器
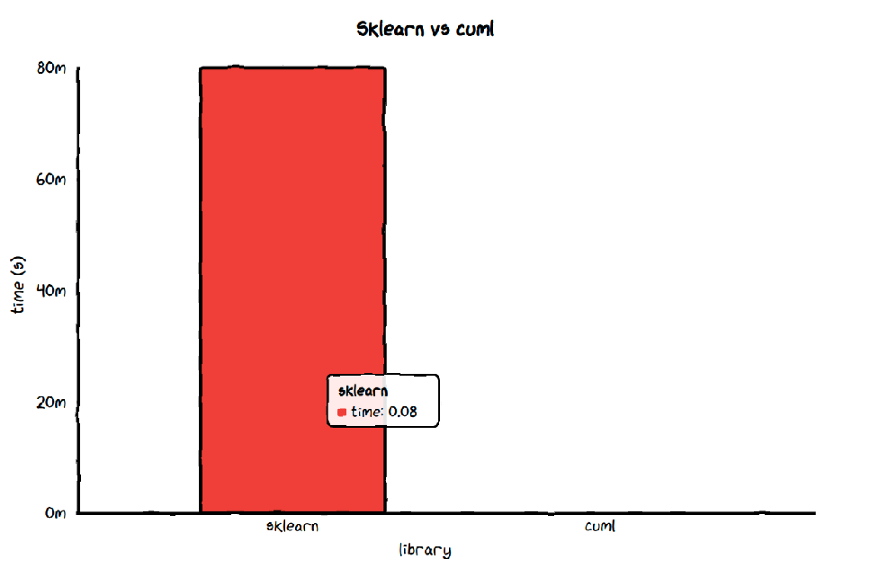
Average time of sklearn's KNeighborsClassifier 0.07836367340000508 s
Average time of cuml's KNeighborsClassifier 0.004251259535714585 s
Ratio between sklearn and cuml is 18.43304854518441

注:y轴上的20m表示20ms。
cuML的KNeighborsClassifier比Sklearn的KNeighborsClassifier快18倍。
更大的显卡内存
Average time of sklearn's KNeighborsClassifier 0.07511190322854547 s
Average time of cuml's KNeighborsClassifier 0.0015137992111426033 s
Ratio between sklearn and cuml is 49.618141346401956
在我的戴尔Precision 7740笔记本电脑上训练时,cuML的KNeighborsClassifier比Sklearn的KNeighborsClassifier快50倍。
总结
你可以在这里找到其他比较的代码。
以下两个表总结了两个库之间不同模型的速度:
- Alienware M15-GeForce 2060和6.3 GB显卡内存
| index | sklearn(s) | cuml(s) | sklearn/cuml |
|---|---|---|---|
| SVC | 50.24 | 23.69 | 2.121 |
| RandomForestClassifier | 29.82 | 0.443 | 67.32 |
| KNeighborsClassifier | 0.078 | 0.004 | 19.5 |
| LinearRegression | 0.005 | 0.006 | 0.8333 |
| Ridge | 0.021 | 0.006 | 3.5 |
| KNeighborsRegressor | 0.076 | 0.002 | 38 |
- Dell Precision 7740-Quadro RTX 5000和17 GB显卡内存
| index | sklearn(s) | cuml(s) | sklearn/cuml |
|---|---|---|---|
| SVC | 35.79 | 1.995 | 17.94 |
| RandomForestClassifier | 24.01 | 0.151 | 159 |
| KNeighborsClassifier | 0.075 | 0.002 | 37.5 |
| LinearRegression | 0.006 | 0.002 | 3 |
| Ridge | 0.005 | 0.002 | 2.5 |
| KNeighborsRegressor | 0.069 | 0.001 | 69 |
相当令人印象深刻,不是吗?
结论
你刚刚了解了在cuML上训练不同的模型与Sklearn相比有多快。如果使用Sklearn训练你的模型需要很长时间,我强烈建议你尝试一下cuML,因为与Sklearn的API相比,代码没有任何变化。
当然,如果库使用GPU来执行像cuML这样的代码,那么你拥有的显卡越好,训练的速度就越快。
有关其他机器学习模型的详细信息,请参阅cuML的文档:https://docs.rapids.ai/api/cuml/stable/
原文链接:https://towardsdatascience.com/train-your-machine-learning-model-150x-faster-with-cuml-69d0768a047a
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/