Hadoop
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop解决哪些问题?
-
海量数据需要及时分析和处理
-
海量数据需要深入分析和挖掘
-
数据需要长期保存
海量数据存储的问题:
-
磁盘IO称为一种瓶颈,而非CPU资源
-
网络带宽是一种稀缺资源
-
硬件故障成为影响稳定的一大因素
Hadoop 相关技术
Hbase
- Nosql数据库,Key-Value存储
- 最大化利用内存
HDFS
- hadoop distribute file system(分布式文件系统)
- 最大化利用磁盘
MapReduce
- 编程模型,主要用来做数据分析
- 最大化利用CPU
集中式系统
集中式系统用一句话概括就是:一个主机带多个终端。终端没有数据处理能力,仅负责数据的录入和输出。而运算、存储等全部在主机上进行。现在的银行系统,大部分都是这种集中式的系统,此外,在大型企业、科研单位、军队、政府等也有分布。集中式系统,主要流行于上个世纪。
集中式系统的最大的特点就是部署结构非常简单,底层一般采用从IBM、HP等厂商购买到的昂贵的大型主机。因此无需考虑如何对服务进行多节点的部署,也就不用考虑各节点之间的分布式协作问题。但是,由于采用单机部署。很可能带来系统大而复杂、难于维护、发生单点故障(单个点发生故障的时候会波及到整个系统或者网络,从而导致整个系统或者网络的瘫痪)、扩展性差等问题。
分布式系统(distributed system)
一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
一个标准的分布式系统应该具有以下几个主要特征:
- 分布性
分布式系统中的多台计算机之间在空间位置上可以随意分布,系统中的多台计算机之间没有主、从之分,即没有控制整个系统的主机,也没有受控的从机。
- 透明性
系统资源被所有计算机共享。每台计算机的用户不仅可以使用本机的资源,还可以使用本分布式系统中其他计算机的资源(包括CPU、文件、打印机等)。
- 同一性
系统中的若干台计算机可以互相协作来完成一个共同的任务,或者说一个程序可以分布在几台计算机上并行地运行。
- 通信性
系统中任意两台计算机都可以通过通信来交换信息。
分布式数据和存储
大型网站常常需要处理海量数据,单台计算机往往无法提供足够的内存空间,可以对这些数据进行分布式存储。
分布式计算
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。
关系型数据库, MapReduce (大规模数据批量分析)
数据访问效率
磁盘寻址时间提高速度远远小于数据传输速率提高速度(寻址是将磁头移动到特定硬盘位置进行读写操作,这是导致硬盘操作延迟的主要原因,而传输速率取决于硬盘的带宽)。对于超大规模数据(以PB为单位)必须考虑使用其他方式。关系型数据库使用B树结构进行数据的更新查询操作,对于最大到GB的数据量,一般相对数据量较小,效果很好。但是大数据量时,B树使用排序/合并方式重建数据库以更新数据的效率远远低于MapReduce。
数据结构不同
- 结构化数据
(structured data):是具体既定格式的实体化数据,如XML文档或满足特定预定义格式的数据库表。这是RDBMS包括的内容。
半结构化数据
- 半结构化数据
(semi-structured data):比较松散,虽然可能有格式,但是经常被忽略,所以他只能作为对的一般指导。如:一张电子表格,其结构是由单元格组成的网格,但是每个单元格自身可保存任何形式的数据。
非结构化数据
- 非结构化数据
(unstructured data):没有什么特别的内部结构,如纯文本或图像数据。
关系型数据使用的是结构化数据,在数据库阶段按具体类型处理数据。关系型数据的规范性非常重要,保持数据的完整性,一致性。
MapReduce 线性,可伸缩性编程
程序员需要编写 map函数 和 reduce函数。每个函数定义从一个键值对集合到另一个键值对集合的映射。
MapReduce 工作原理
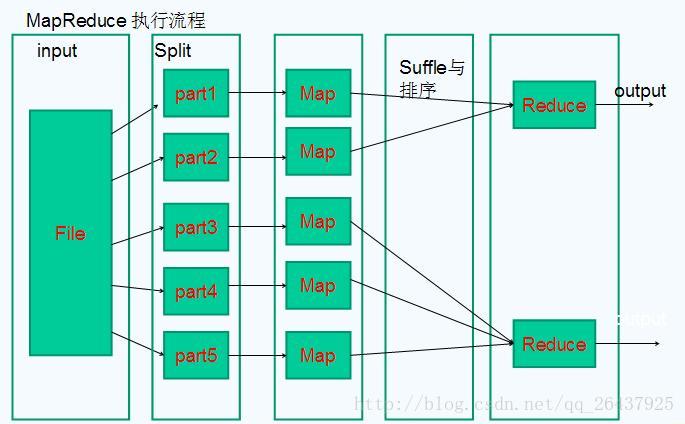


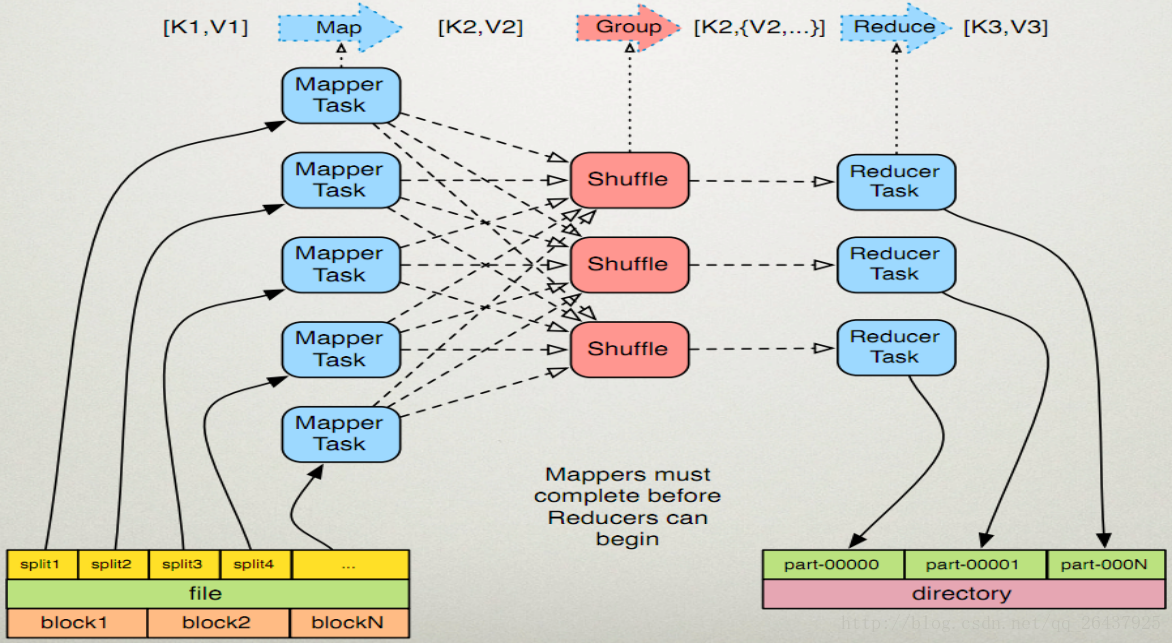
map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
HDFS
HDFS采用master/slave架构 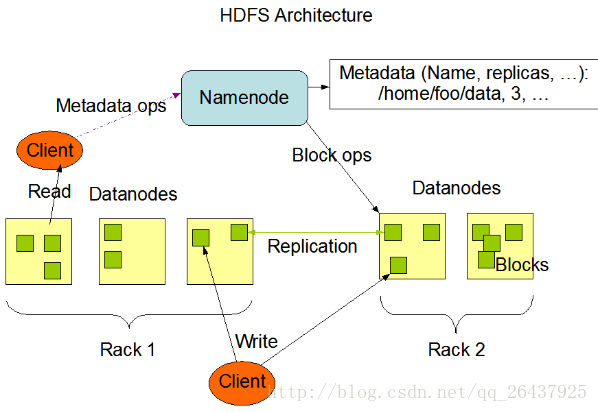

rack
放服务器的支架。
一个Block的副本会保存到两个或两个以上的机架上的服务器中,这样能防灾容错,因为一个机架出现掉电,交换机挂了的概率还是很高的。
数据块
linux中每个磁盘有默认的数据块大小,这是对磁盘操作的最小单位,通常512字节。HDFS同样也有块(Block)的概念,默认64MB/128MB,比磁盘块大得多。与单一的文件系统类似,HDFS上的文件系统也被划分成多个分块(Chunk)作为独立的存储单元。
一个hadoop文件就是由一系列分散在不同的DataNode上的block组成。
HDFS默认的Block为64MB/128MB?
块相对较大,主要是把寻道时间最小化。如果一个块足够大,从硬盘传输数据的时间将远远大于寻找块起始位置的时间。这样使得HDFS的数据块速度和硬盘的传输速度更加接近。
NameNode 元数据节点
NameNode的作用是管理文件目录结构,接受用户的操作请求,是管理数据节点的,是一个jetty服务器。名字节点维护两套数据, 一套是文件目录与数据块之间的关系 , 另一套是数据块与节点之间的关系 。 前一套 数据是 静态的 ,是存放在磁盘上的, 通过fsimage和edits文件来维护 ; 后一套 数据是 动态的 ,不持久放到到磁盘的,每当集群启动的时候,会自动建立这些信息,所以一般都放在内存中。
NameNode保存文件metadata信息,包括:
-
文件owership和permissions
-
文件包含哪些块
-
Block保存在哪个DateNode(由DataNode启动时上报给)
例如一个Metadata
-
file.txt
-
Blk A:
-
DN1,DN5,DN6
-
-
Blk B:
-
DN7,DN1,DN2
-
-
Blk C:
-
DN5,DN8,DN9
NameNode的metadata信息在启动后会加载到内存中
文件包括:
① fsimage (文件系统镜像):元数据镜像文件。存储某一时段NameNode内存元数据信息。
② edits: 操作日志文件。
③ fstime: 保存最近一次checkpoint的时间
NameNode决定是否将文件映射到DataNode的复制块上:多副本,默认三个,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储到不同机架的某个节点上。
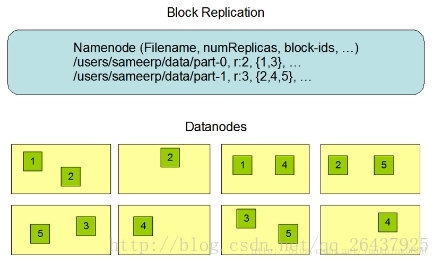

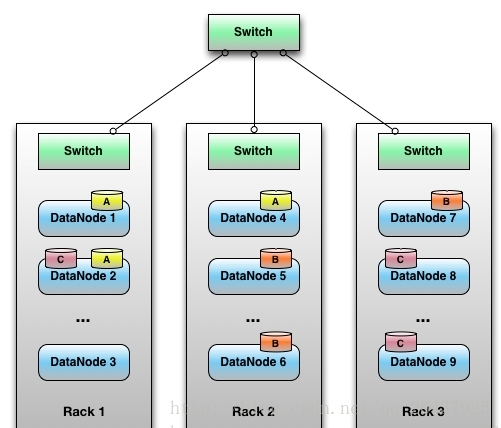

转自:http://www.cnblogs.com/gisorange/p/4328859.html
DataNode
DataNode的作用是HDFS中真正存储数据的。
DataNode的作用:
-
保存Block,每个块对应一个元数据信息文件。这个文件主要描述这个块属于哪个文件,第几个块等信息。
-
启动DataNode线程的时候会向NameNode汇报Block信息
-
通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode 10分钟没有收到DataNode的心跳,认为其已经lost,并将其上的Block复制到其它的DataNode.
假设文件大小是100GB,从字节位置0开始,每64MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是64MB大小。block是hdfs读写数据的基本单位。
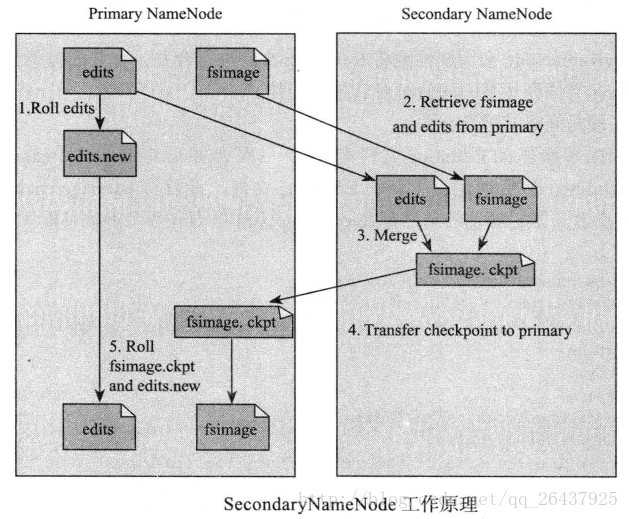
Secondary NameNode(辅助元数据信息)
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大;能减少NameNode启动时间。
它不是NameNode的热备份,可以作为一个冷备份
* 将本地保存的fsimage导入
* 修改cluster的所有DataNode的NameNode地址
* 修改所有client端的NameNode地址
* 或者修改Secondary NameNode IP为 NameNode IP

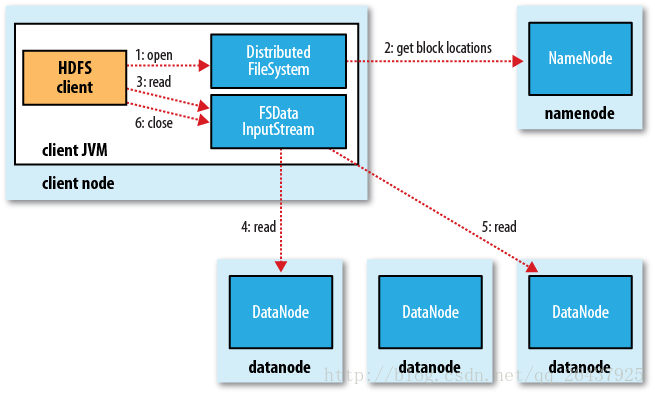
hadoop读取文件

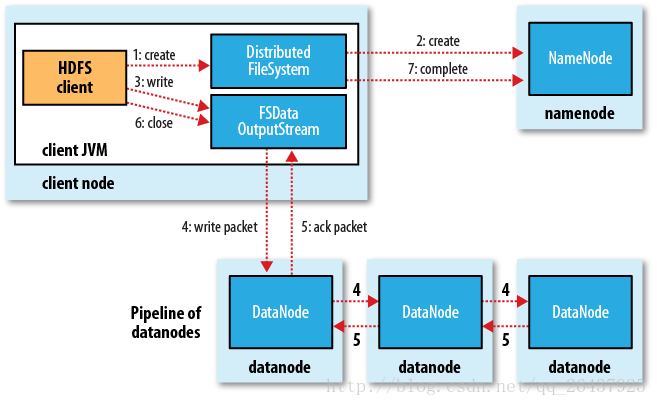
hadoop写文件

Hadoop在创建新文件时是如何选择block的位置的呢,综合来说,要考虑以下因素:带宽(包括写带宽和读带宽)和数据安全性。如果我们把三个备份全部放在一个datanode上,虽然可以避免了写带宽的消耗,但几乎没有提供数据冗余带来的安全性,因为如果这个datanode当机,那么这个文件的所有数据就全部丢失了。另一个极端情况是,如果把三个冗余备份全部放在不同的机架,甚至数据中心里面,虽然这样数据会安全,但写数据会消耗很多的带宽。Hadoop 0.17.0给我们提供了一个默认replica分配策略(Hadoop 1.X以后允许replica策略是可插拔的,也就是你可以自己制定自己需要的replica分配策略)。replica的默认分配策略是把第一个备份放在与客户端相同的datanode上(如果客户端在集群外运行,就随机选取一个datanode来存放第一个replica),第二个replica放在与第一个replica不同机架的一个随机datanode上,第三个replica放在与第二个replica相同机架的随机datanode上。如果replica数大于三,则随后的replica在集群中随机存放,Hadoop会尽量避免过多的replica存放在同一个机架上。
转自:http://www.cnblogs.com/beanmoon/archive/2012/12/17/2821548.html
NameNode 安全模式
在分布式文件系统自动的时候,开始时会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中不允许有上传,修改,删除等写操作,只能读,直到安全模式结束。
1) namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作
2) 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不要SecondaryNameNode)和一个空的日志edits文件
3) NameNode开始监听RPC和HTTP请求
4) 此刻namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。(可以显示目录,显示文件内容等;写,删除,重命名等操作都会失败)
5) 系统中的数据块的位置不是有namenode维护的,而是以块列表的形式存储在datanode中(datanode启动汇报的)
6) 在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息
7)在安全模式下,各个datanode会向namenode发送块列表的最新情况
8) 进入和离开安全模式
查看namenode处于哪个状态
hadoop dfsadmin -sagemode get
进入安全模式(hadoop启动的时候是在安全模式)
hadoop dfsadmin -sagemode enter
离开安全模式
hadoop dfsadmin -sagemode leave
Hadoop中的RPC机制
同其他RPC框架一样,Hadoop RPC分为四个部分:
(1)序列化层:Clent与Server端通信传递的信息采用了Hadoop里提供的序列化类或自定义的Writable类型;
(2)函数调用层:Hadoop RPC通过动态代理以及java反射实现函数调用;
(3)网络传输层:Hadoop RPC采用了基于TCP/IP的socket机制;
(4)服务器端框架层:RPC Server利用java NIO以及采用了事件驱动的I/O模型,提高RPC Server的并发处理能力;

感谢您的关注!可加QQ1群:135430763,QQ2群:454796847,QQ3群:187424846。QQ群进群密码:xttblog,想加微信群的朋友,可以微信搜索:xmtxtt,备注:“xttblog”,添加助理微信拉你进群。备注错误不会同意好友申请。再次感谢您的关注!后续有精彩内容会第一时间发给您!原创文章投稿请发送至532009913@qq.com邮箱。商务合作可添加助理微信进行沟通!