配置hadoop集群环境
集群节点初始化:
主机节点(4个节点):
Master01:NN进程(NameNode)
Slave01:DN进程(DataNode)
Slave02:DN进程(DataNode)
Slave03:DN进程(DataNode)
打通网络(配置静态ip地址 、修改主机名、各主机节点ip映射、关闭防火墙和selinux)
配置静态ip地址
[root@localhost ~]# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:0C:29:4C:9B:08
inet addr:192.168.25.130 Bcast:192.168.25.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe4c:9b08/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:71 errors:0 dropped:0 overruns:0 frame:0
TX packets:50 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:8325 (8.1 KiB) TX bytes:6541 (6.3 KiB)
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.25.130
NETMASK=255.255.255.0
GATEWAY=192.168.25.2
DNS1=192.168.25.2
DNS2=8.8.8.8
关闭防火墙、selinux
service iptables stop 关闭防火墙
chkconfig iptables off 关闭开机启动防火墙
setenforce 0 关闭selinux
vi /etc/sysconfig/selinux 修改selinux配置文件关闭自动启动selinux
配置ntp服务(时间同步)
[root@master01 ~]# rpm -qa|grep ntp 查看ntp服务是否安装
[root@master01 ~]# yum install -y ntp 在线安装ntp服务
[root@slave01 ~]# vi /etc/ntp.conf
server 127.127.1.0 # local clock
fudge 192.168.25.130 stratum 0 //stratum 时间层级,0等级最高,从机同步本机此值 必须比0大,即层级比本机低
[root@master01 ~]# service ntpd start 或者 [root@slave01 ~]# /etc/init.d/ntpd start
[root@master01 ~]# ntpstat 查看ntp服务状态 (是否同步)
synchronised to NTP server (193.228.143.14) at stratum 6
time correct to within 960 ms
polling server every 64 s
[root@master01 ~]# ntpq -p 时间同步详情
remote refid st t when poll reach delay offset jitter
===========================================================================
+biisoni.miuku.n 207.224.49.219 2 u 1 64 373 308.701 -25971. 107.269
*ntp5.flashdance 192.36.143.154 2 u 11 64 375 274.055 -25927. 44.216
+ntp2.itcomplian 5.103.128.88 3 u 2 64 357 362.718 -25894. 72.356
LOCAL(0) .LOCL. 5 l 9 64 377 0.000 0.000 0.000
slave01配置
server 192.168.25.130 master01 ip
fudge 192.168.25.131 stratum 10 Slave01 ip
从机手动同步 [root@slave01 ~]# ntpdate master01 (slave01 ntp服务必须关闭)
配置ssh免密登录
只需要master登录到salve各个节点即可,无需反向
[root@master01 ~]# ssh-keygen -t rsa 创建公匙
[root@master01 ~]# ssh-copy-id slave02 拷贝公匙
搭建Hadoop集群
Hadoop运行必须是hadoop用户,不能为其他用户
- 导入并解压压缩包:
[root@master01 install]# tar -zxvf hadoop-2.7.3.tar.gz -C /software/解压到software文件夹
- 更改文件的宿主:
[root@master01 software]# chown -R hadoop:hadoop hadoop-2.7.3/
- su -l hadoop 更改到hadoop用户
- 为hadoop用户配置ssh免密连接登录(包括对自己的连接)
- 配置hadoop环境
[hadoop@master01 ~]$ su -lc "vi /etc/profile"
修改文件为:
JAVA_HOME=/software/jdk1.7.0_79
HADOOP_HOME=/software/hadoop-2.7.3
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME
[hadoop@master01 ~]$ source /etc/profile 使配置文件生效 source 与 . 等效
修改文件hadoop-env.sh
[hadoop@master01 ~]$ vi /software/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
修改文件中25行:
export JAVA_HOME=/software/jdk1.7.0_79
修改文件 core-site.xml
[hadoop@master01 hadoop]$ vi core-site.xml
修改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/software/hadoop-2.7.3/work</value>
</property>
</configuration>
修改文件hdfs-site.xml
[hadoop@master01 hadoop]$ vi hdfs-site.xml
修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
[hadoop@master01 hadoop]$ mv mapred-site.xml.template mapred-site.xml
修改文件mapred-site.xml
[hadoop@master01 hadoop]$ vi mapred-site.xml
修改为:
<configuration>
<property>
<name>mapreduce.framework.name </name>
<value>yarn</value>
</property>
</configuration>
修改文件yarn-site.xml
[hadoop@master01 hadoop]$ vi yarn-site.xml
修改为:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改文件slaves
[hadoop@master01 hadoop]$ vi slaves
修改为:
slave01
slave02
slave03
- 将配置好的hadoop文件夹拷贝到各个slave
在root用户下执行
[root@master01 ~]# scp -r /software/hadoop-2.7.3 slave01:/software/
[root@master01 ~]# scp -r /software/hadoop-2.7.3 slave02:/software/
[root@master01 ~]# scp -r /software/hadoop-2.7.3 slave03:/software/
拷贝配置好的profile文件到从机
[root@master01 ~]# scp /etc/profile slave01:/etc/
[root@master01 ~]# scp /etc/profile slave02:/etc/
[root@master01 ~]# scp /etc/profile slave03:/etc/
拷贝后的hadoop文件夹宿主为root,需要改变宿主(原因是该文件是从root 用户拷贝而来)
[root@slave01 software]# chown -R hadoop:hadoop hadoop-2.7.3/
拷贝至slave中的profile文件,需要加载配置文件
[root@slave02 software]# . /etc/profile 或者
[root@slave02 software]# source /etc/profile
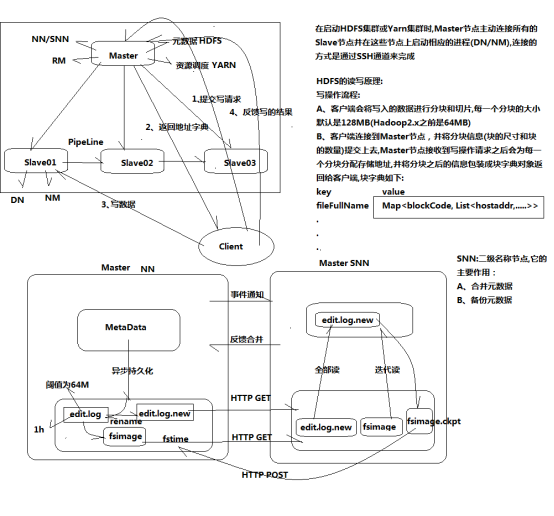
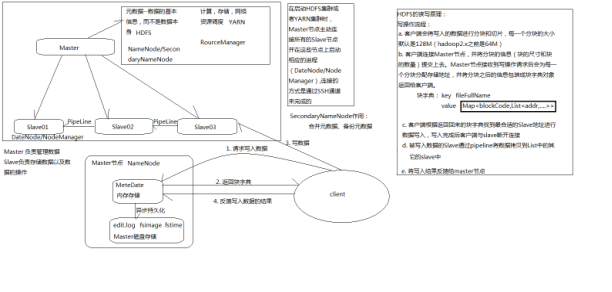
启动HDFS集群并测试 --Hadoop分布式文件系统、存储数据
- 格式化文件系统
[hadoop@master01 ~]$ hdfs namenode -format 只在master中运行
INFO util.ExitUtil: Exiting with status 0 表示格式化成功
- 启动HDSF集群
[hadoop@master01 software]$ start-dfs.sh 启动
Starting namenodes on [master01]
master01: starting namenode, logging to /software/hadoop-2.7.3/logs/hadoop-hadoop-namenode-master01.out
slave03: starting datanode, logging to /software/hadoop-2.7.3/logs/hadoop-hadoop-datanode-slave03.out
slave01: starting datanode, logging to /software/hadoop-2.7.3/logs/hadoop-hadoop-datanode-slave01.out
slave02: starting datanode, logging to /software/hadoop-2.7.3/logs/hadoop-hadoop-datanode-slave02.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /software/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-master01.out
[hadoop@master01 software]$ jps 查看所有java进程
3627 Jps
3518 SecondaryNameNode
3321 NameNode
[hadoop@slave01 ~]$ jps
1875 Jps
1829 DataNode
- 测试HDFS集群
[hadoop@master01 install]$ hdfs dfs -put initNetwork.sh /test 上传文件
[hadoop@master01 hadoop-2.7.3]$ hdfs dfs -mkdir -p /test 创建文件夹
[hadoop@master01 hadoop-2.7.3]$ hdfs dfs -ls /test 查看文件
[hadoop@master01 install]$ hdfs dfs -get /test/initNetwork.sh /software 下载文件
[hadoop@master01 software]$ hdfs dfs -rm -r /test/initNetwork.sh 删除文件
在集群外访问http://192.168.25.130:50070
- 原理:
启动yarn集群 --调用硬件资源、计算数据
- 启动yarn集群
[hadoop@master01 software]$ start-yarn.sh
在集群外访问http://192.168.25.130:8088
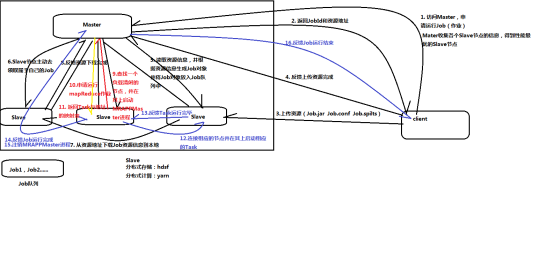
- Yarn集群调度原理
1、client---->master(申请运行job,链接的是RM进程)
2、master---->client(返回jobId和资源地址:提交的jar文件存放地址,配置信 息conf地址,每个副本的spilt分配信息)
3、client---->slave03(根据资源地址链接slave节点,上传资源 --job.jar/job.conf/job.spilt)
4、client---->master(反馈上传资源完成)
5、master---->slave03(读取之前上传的资源信息,根据资源信息生成job对象, 并将job对象放入job队列--master缓存区(job1,job2....))
------资源分配过程
6、slave01--->master(slave主动链接master去领取自己的job,之间用 NodeManage==ResourceManage进程)
7、slave01--->slave03(根据领取的jobId,从资源地址下载job资源信息到本 地(尤其是job.jar))
8、slave01--->master(反馈资源下载完成,所有slave都要反馈)
--------master启动MapReduce进程
9、master在slave中寻找负载清闲的节点(例slave02),并在其上启动 MRAPPMaster进程,同时slave02上会出现MapReduce进程
10、slave02---->master(申请运行MapReduce进程)
---------master从此开始等待跟踪Task的运行过程
11、master---->slave02(返回Task(一个job有多个Task,一个Task就是一个 进程)与地址的映射表--告知哪些节点运行MapTask,哪些运行ReduceTask)
12、slave02--->slave03(链接相应的slave并在其上启动相应的Task)
--------Task进程跑完会将YarnChild进程结束信息反馈给master
13、Task----->master(反馈Task进程(名字叫:YarnChild)运行完毕,所有进 程都要反馈)
-------都反馈完毕
14、slave02--->master(反馈job运行完成)
15、Master----->slave02 (master注销MRAPPMaster进程)
16、master--->client(反馈job运行结束--1、环节出错,job运行失败,2、成 功运行结束)
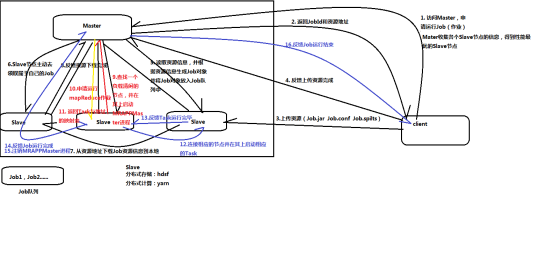
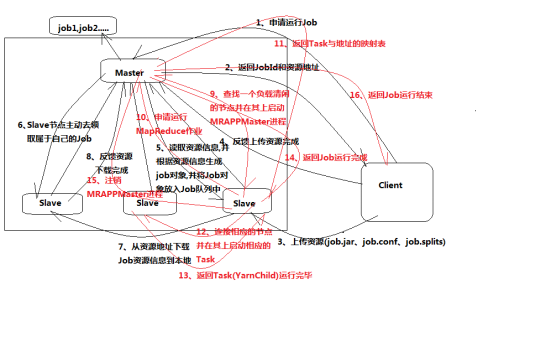
MapReduce原理图: