一个网站的网页经常会更新,作为爬虫方,在网页更新后,则需要我们对这些网页进行重新
爬取,而如何把握恰当的爬取时间呢,若网站更新过慢,则必然会增加爬虫与网站服务器的
压力,而如果更新较快,但是爬虫间隔时间较长,那么爬取的内容版本则会过老,不利于新
内容的爬取。所以要把握好网站更新频率与爬虫访问网站的频率越接近越好。特别是在我们
爬虫资源有限的时候,此时爬虫也需要根据对应策略,让不同的网页具有不同的更新优先级,
优先级高的网页更新,将获得较快的爬取响应。
常见的网页更新策略主要有3种:用户体验策略、历史数据策略、聚类分析策略等,以下对其
进行叙述。
在搜索引擎查询某个关键词的时候,会出现一个排名结果,在排名结果中,通常会有大量的
网页,但是,大部分用户都只会关注排名靠前的网页,所以,在爬虫服务器资源有限的情况
下,爬虫会优先更新排名结果靠前的网页。这种更新策略,我们称之为用户体验策略,那么
在这种策略中,爬虫到底何时去爬取这些排名结果靠前的网页呢?此时,爬取中会保留对应
网页的多个历史版本,并进行对应分析,依据这多个历史版本的内容更新、搜索质量影响、
用户体验等信息,来确定对这些网页的爬取周期。
除此之外,我们还可以使用历史数据策略来确定对网页更新爬取的周期。比如,依据某一个
网页的历史更新数据,通过泊松分布进行建模等手段,预测该网页的下一次更新时间,从而
确定下一次对该网页爬取的时间,即确定更新周期。
以上两种策略,都需要历史数据作为依据。有的时候,若一个网页为新网页,则不会有对应的
历史数据,并且,如果要依据历史数据进行分析,则需要爬虫服务器保存对应网页的历史版本
信息,这无疑给爬虫服务器带来了更多的压力和负担。如果想要解决这些问题,则需要采取新
的更新策略。比较常用的是聚类分析策略。那么什么是聚类分析策略呢?
比如我们去商场,商场中的商品一般都分好类了,方便顾客去选购相应的商品,此时,商品
分类的类别是固定的,是已经拟定好的。但是,假如商品的数量巨大,事先无法对其进行
分类,或者说,根本不知道将会拥有哪些类别的商品,此时,我们应该如何解决将商品归
类的问题呢?
这时候我们可以用聚类的方式解决,依据商品之间的共性进行相应分析,将共性较多的商品
聚为一类,此时,商品聚集成的类的数目是不一定的,但是能保证的是,聚在一起的商品之
间一定有某种共性,即依据“物以类聚”的思想去实现。
同样,在我们的聚类算法中,也会有类似的分析过程。
将聚类分析算法运用在爬虫对网页的更新上,我们可以这样做,如图3-4所示。
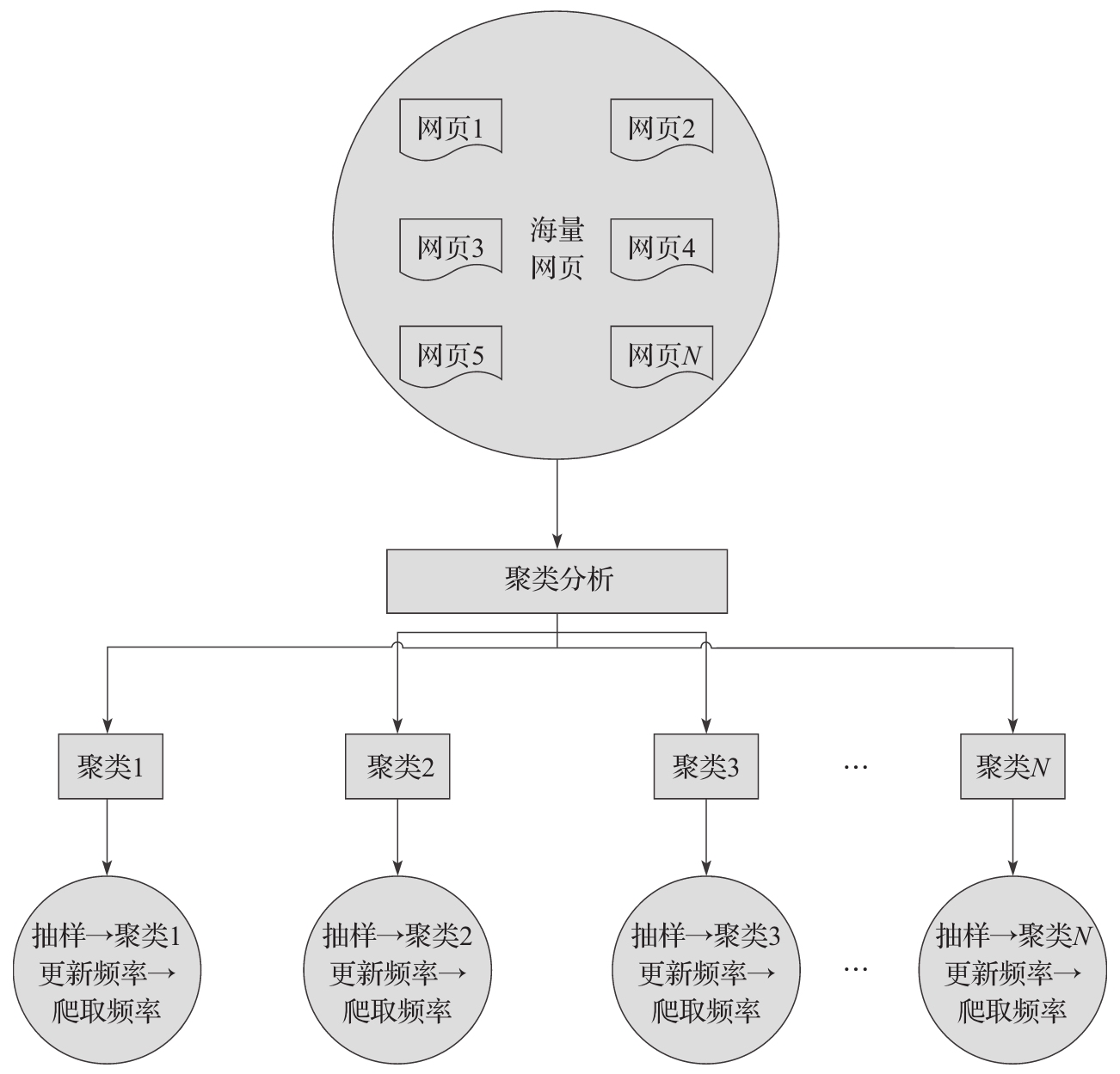
1) 首先,经过大量的研究发现,网页可能具有不同的内容,但是一般来说都具有类似属性
的网页,其更新频率类似。这是聚类分析算法运用在爬虫更新上的一个前提指导思想。
2) 有了1中的指导思想之后,我们可以先对海量的网页进行聚类分析,在聚类之后,会形成
多个类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。
3) 聚类完成后,我们可以对同一个聚类中的网页进行抽样,然后该抽样结果的平均更新值,
从而确定对每个聚类的爬行频率。
以上,就是使用爬虫爬取网页的时候,常见的3种更新策略,我们掌握了其算法思想后,在
后续我们进行爬虫的实际开发的时候,编写出来的爬虫执行效率会更高,并且执行逻辑会
更合理。