一、工作原理剖析
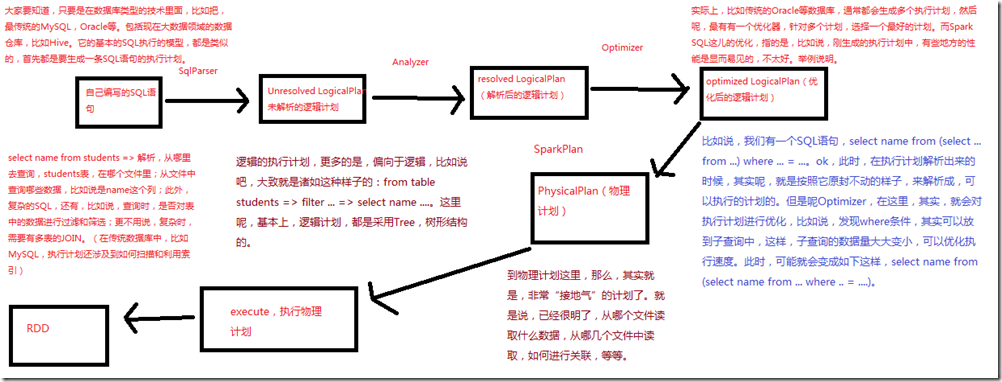
二、性能优化
1、设置Shuffle过程中的并行度:spark.sql.shuffle.partitions(SQLContext.setConf()) 2、在Hive数据仓库建设过程中,合理设置数据类型,比如能设置为INT的,就不要设置为BIGINT。减少数据类型导致的不必要的内存开销。 3、编写SQL时,尽量给出明确的列名,比如select name from students。不要写select *的方式。 4、并行处理查询结果:对于Spark SQL查询的结果,如果数据量比较大,比如超过1000条,那么就不要一次性collect()到Driver再处理。 使用foreach()算子,并行处理查询结果。 5、缓存表:对于一条SQL语句中可能多次使用到的表,可以对其进行缓存,使用SQLContext.cacheTable(tableName),或者DataFrame.cache()即可。 Spark SQL会用内存列存储的格式进行表的缓存。然后Spark SQL就可以仅仅扫描需要使用的列,并且自动优化压缩,来最小化内存使用和GC开销。 SQLContext.uncacheTable(tableName)可以将表从缓存中移除。用SQLContext.setConf(),设置spark.sql.inMemoryColumnarStorage.batchSize参数(默认10000),可以配置列存储的单位。 6、广播join表:spark.sql.autoBroadcastJoinThreshold,默认10485760 (10 MB)。在内存够用的情况下,可以增加其大小,概参数设置了一个表在join的时候, 最大在多大以内,可以被广播出去优化性能。 7、钨丝计划:spark.sql.tungsten.enabled,默认是true,自动管理内存。 最有效的,其实就是第四点、缓存表和广播join表,也是非常不错的!
三、hive on spark
Hive On Spark背景知识:
sparkSQL与hive on saprk:
Hive是目前大数据领域,事实上的SQL标准。其底层默认是基于MapReduce实现的,但是由于MapReduce速度实在比较慢,因此这两年,陆续出来了新的SQL查询引擎。
包括Spark SQL,Hive On Tez,Hive On Spark等。
Spark SQL与Hive On Spark是不一样的。Spark SQL是Spark自己研发出来的针对各种数据源,包括Hive、JSON、Parquet、JDBC、RDD等都可以执行查询的,
一套基于Spark计算引擎的查询引擎。因此它是Spark的一个项目,只不过提供了针对Hive执行查询的工功能而已。适合在一些使用Spark技术栈的大数据应用类系统中使用。
而Hive On Spark,是Hive的一个项目,它是指,不通过MapReduce作为唯一的查询引擎,而是将Spark作为底层的查询引擎。Hive On Spark,只适用于Hive。
在可预见的未来,很有可能Hive默认的底层引擎就从MapReduce切换为Spark了。适合于将原有的Hive数据仓库以及数据统计分析替换为Spark引擎,作为全公司通用的大数据统计分析引擎。
首先看一下Hive的基本工作原理:
Hive QL语句 =>
语法分析 => AST =>
生成逻辑执行计划 => Operator Tree =>
优化逻辑执行计划 => Optimized Operator Tree =>
生成物理执行计划 => Task Tree =>
优化物理执行计划 => Optimized Task Tree =>
执行优化后的Optimized Task Tree
Hive On Spark的计算原理有如下几个要点:
1、将Hive表作为Spark RDD来进行操作:这个是没有疑问的
2、使用Hive原语
对于一些针对RDD的操作,比如groupByKey、sortByKey等。不使用Spark的transformation操作和原语。如果那样做的话,那么就需要重新实现一套Hive的原语,
而且如果Hive增加了新功能,那么又要实现新的Spark原语。因此选择将Hive的原语包装为针对RDD的操作即可。
3、新的物理执行计划生成机制
使用SparkCompiler将逻辑执行计划,即Operator Tree,转换为Task Tree。提交Spark Task给Spark进行执行。SparkTask包装了DAG,DAG包装为SparkWork。
SparkTask根据SparkWork表示的DAG计算。
4、SparkContext生命周期
Hive On Spark会为每个用户的会话,比如执行一次SQL语句,创建一个SparkContext。但是Spark不允许在一个JVM内创建多个SparkContext。
因此,需要在单独的JVM中启动每个会话的SparkContext,然后通过RPC与远程JVM中的SparkContext进行通信。
5、本地和远程运行模式
Hive On Spark提供两种运行模式,本地和远程。如果将Spark Master设置为local,比如set spark.master=local,那么就是本地模式,
SparkContext与客户端运行在一个JVM中。否则,如果将Spark Master设置为Master的地址,那么就是远程模式,SparkContext会在远程的JVM中启动。
远程模式下,每个用户Session都会创建一个SparkClient,SparkClient启动RemoteDriver,RemoteDriver负责创建SparkContext。
Hive On Spark做了一些优化:
1、Map Join
Spark SQL默认对join是支持使用broadcast机制将小表广播到各个节点上,以进行join的。但是问题是,这会给Driver和Worker带来很大的内存开销。
因为广播的数据要一直保留在Driver内存中。所以目前采取的是,类似乎MapReduce的Distributed Cache机制,即提高HDFS replica factor的复制因子,
以让数据在每个计算节点上都有一个备份,从而可以在本地进行数据读取。
2、Cache Table
对于某些需要对一张表执行多次操作的场景,Hive On Spark内部做了优化,即将要多次操作的表cache到内存中,以便于提升性能。但是这里要注意,
并不是对所有的情况都会自动进行cache。所以说,Hive On Spark还有很多不完善的地方。
hive on spark环境搭建
1、安装包apache-hive-1.2.1-bin.tar.gz 2、在/usr/local目录下解压缩 3、进入conf目录,mv hive-default.xml.template hive-site.xml,修改hive-site.xml <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://spark1:3306/hive_metadata_2?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse2</value> </property> 4、在conf目录下 mv hive-env.sh.template hive-env.sh vi ./bin/hive-config.sh export JAVA_HOME=/usr/java/latest export HIVE_HOME=/usr/local/apache-hive-1.2.1-bin export HADOOP_HOME=/usr/local/hadoop 5、cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/local/apache-hive-1.2.1-bin/lib 6、MySQL create database if not exists hive_metadata_2; grant all privileges on hive_metadata_2.* to 'hive'@'%' identified by 'hive'; grant all privileges on hive_metadata_2.* to 'hive'@'localhost' identified by 'hive'; grant all privileges on hive_metadata_2.* to 'hive'@'spark1' identified by 'hive'; flush privileges; 7、启动hive cli,./hive,报错,Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D 创建文件夹:/home/grid/apache-hive-1.2.1-bin /iotmp 将hive-site.xml中所有的${system:java.io.tmpdir}改为上面的目录,这里建议用WinSCP将hive-site.xml拷贝到windows上来,用notepad++这种工具,来进行文本替换,比较方便。 8、启动hive cli,./hive,继续报错,Found class jline.Terminal, but interface was expected cp /usr/local/apache-hive-1.2.1-bin/lib/jline-2.12.jar /usr/local/hadoop/share/hadoop/yarn/lib 将hadoop原来的老的jline-0.9.94.jar,改名或者删除 9、启动hive cli,/usr/local/apache-hive-1.2.1-bin/bin/hive,成功启动 使用: create table students(name string, age int); load data local inpath '/usr/local/spark-study/resources/students.txt' into table students; // 使用Hive On Spark非常简单 // 只要用set hive.execution.engine命令设置Hive的执行引擎为spark即可 // 默认是mr set hive.execution.engine=spark; // 这里,是完全可以将其设置为Spark Master的URL地址的 set spark.master=spark://192.168.1.107:7077 select * from students;