题干为:有如下字符串:n = "齐天大圣"。
要求:(1)将字符串转换成utf-8的字符编码的字节,再将转换的字节重新转换为utf-8的字符编码的字符串
(2)将字符串转换成utf-8的字符编码的字节,再将转换的字节重新转换为gbk的字符编码的字符串
(1)对于第一个问题,将字符串编码为utf-8编码的字节,然后再转为utf-8,这里可以直接进行encode与decode的操作:

这里我们给n赋值为'齐天大圣',将n的值以utf-8的方式编码得到的结果赋值给n2,而同样以utf-8的方式解码得到的结果仍然是'齐天大圣',也就是说此时的n3与n相等。
(2)但是对于以utf-8方式编码,而又以gbk方式解码,对于很多初学者来说可能会犯下面这样的错误,很多人可能按照字面的意思会这样写:
n = '齐天大圣' n2 = n.encode('utf-8') n3 = n2.decode('gbk') print('编码:%s 解码:%s ' % (n2,n3))
但是,输出的结果却是这样子的:

解码的结果竟然出现了乱码!!!
这里需要着重强调一下,当我们将字符串先以utf-8的编码形式写进计算机的硬盘上时,也就相当于给这个字符串上了一把“锁”,而打开这把“锁”的“钥匙”是在你“上锁”的时候就唯一确定了的。也就是说,当你用utf-8的编码模式encode的时候,decode的话必须以同样的编码方式进行,而上图中我们先以utf-8的模式对字符串“上锁”,而gbk方式不是合适的“钥匙”,当你用这个“不合适的钥匙”解锁的时候,计算机不知道你究竟要decode什么,所以当然会出现乱码。
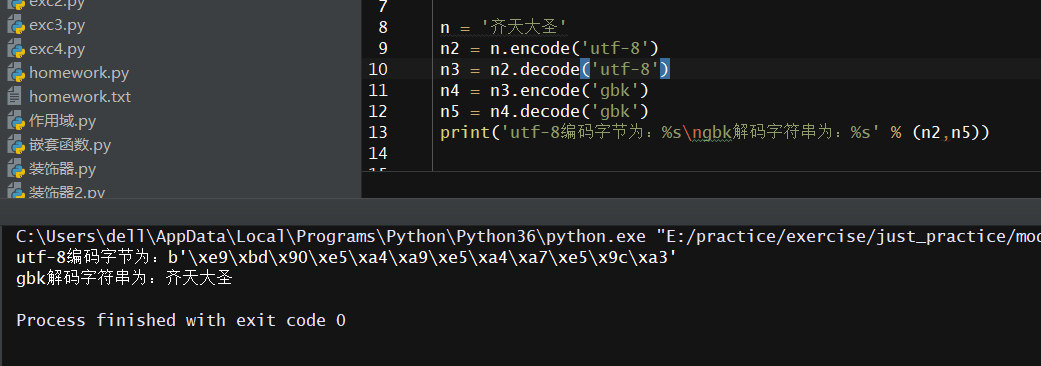
问题(2)正确的解决方式需要我们先将用utf-8模式编码好的字符串以utf-8的模式decode出来,再进行gbk模式的编解码操作:
n = '齐天大圣' n2 = n.encode('utf-8') n3 = n2.decode('utf-8') n4 = n3.encode('gbk') n5 = n4.decode('gbk') print('utf-8编码字节为:%s gbk解码字符串为:%s' % (n2,n5))