原文地址:http://www.cnblogs.com/pcxie/p/7750074.html
本文译者水平有限,如发现问题请批评指正
Jerasure 2.0:为方便存储相关应用开发的一个基于C开发的纠删码库
版本2.0
James S.Plank Kevin M.Greenan
技术报告 UT-EECS-14-721
电气工程与计算机科学系
田纳西大学
诺克斯维尔,田纳西大学 37996
http://www.cs.utk.edu/~plank/plank/papers/UT-EECS-14-721.html
源码: http://web.eecs.utk.edu/~plank/plank/www/software.html
本文描述了2.0版本的源码
摘要
本文描述了jerasure2.0,一个基于C的支持存储应用中纠删码的类库。在本文中,我们不仅描述了纠删码技术而且描述了算法,并将其抽象为接口写入源码。因此,本文充当了一个准教程和编程指南。
如果你使用这个类库或者文档
请发送邮件告知我。一个方面是因为本人会被通过本人工作的影响力而评估,另一方面,如果你发现这个类库或者这个文档有用,我会感到很高兴能够编写它。请发送邮件至plank@cs.utk.edu 。
这个类库受到新的BSD许可证保护。在许可证的规定范围内,它是免费被使用和修改的。本文中所有的技术实现都没有申请专利。
找到这个源码http://jerasure.org/jerasure-2.0/
请下载源码从:http://web.eecs.utk.edu/~plank/plank/www/software.html
在你编译之前,你必须先下载,编译和安装GF-Complete。这是可用的资源地址:http://web.eecs.utk.edu/~plank/plank/www/software.html.
所有的类库编译使用autoconf,这意味着你需要在主目录执行以下步骤:
UNIX>./configure
UNIX>make
UNIX>sudo make install
示例程序在Examples这个文件夹。源代码在src文件夹。
Jerasure的发展历程
这是jerasure的第三个主版本。Jerasure的修订历史如下所示:
版本1.0:James S. Plank,2007年九月。
版本1.2:James S. Plank,Scott Simmerman和Catherine D. Schuman,2008年8月。这次修订向源码添加了Blaum-Roth和Liber8tion码,添加了一个示例编码器和解码器,并更改了示例。
版本1.2A:除了它使用new BSD许可证替换了Gnu LGPL,其他与版本1.2相同。该版本是可用的作为一个tar文件在http://web.eecs.utk.edu/~plank/plank/papers/Jerasure-1.2A.tar 。
版本2.0:James S. Plank和Kevin Greenan,2014年一月。这个版本将伽罗华域的后端实现更改为GF-Complete,这使得允许jerasure利用SIMD操作获取超快的编解码速度。所有的示例都被更新,一部分示例被添加用来演示如何调整底层的伽罗华域去探究GF-Complete的未来特点。
目录
1 前言
2 库的模块
3 基于矩阵的编码
4 基于二进制矩阵的编码
4.1 使用schedule代替二进制矩阵
5 MDS最大距离可分码
6 库的第一部分:伽罗华域算法
7 库的第二部分:内核例程
7.1 矩阵/二进制矩阵/Schedule创建例程
7.2 编码例程
7.3 解码例程
7.4 点积例程
7.5 基础矩阵操作
7.6 统计学
7.7 示例程序
8 库的第三部分:经典RS码例程
8.1 范德蒙矩阵
8.2 与针对RID6优化的RS编码相关的程序
8.3 示例程序
9 库的第四部分:CRS码例程
9.1 cauchy.c中的程序
9.2 示例程序
9.3 扩展参数空间用于柯西RAID-6矩阵的优化
10 库的第五部分:最低密度RAID-6编码
10.1 示例程序
11 编码器和解码器的示例
11.1 缓存区大小和包大小的明智选择
12 更改底层的伽罗华域
1 前言
随着存储系统规模和复杂度的增长,纠删码对于存储应用变得越来越重要。本文描述了Jerasure,是一个基于C的支持纠删码应用的类库。Jerasure按照模块化,快速和灵活被设计。我们希望存储应用开发人员能够发现jerasure作为一个方便的工具来为他们的存储系统添加容错能力。
Jerasure支持了纠删码一个horizontal 模式。我们假设我们有k个设备来存储设备。为了这个,我们添加了m个设备来存放原始k个设备中数据计算得到的内容。如果纠删码是一个最大距离可分码(MDS),那么整个存储系统可以容忍m个设备的丢失。
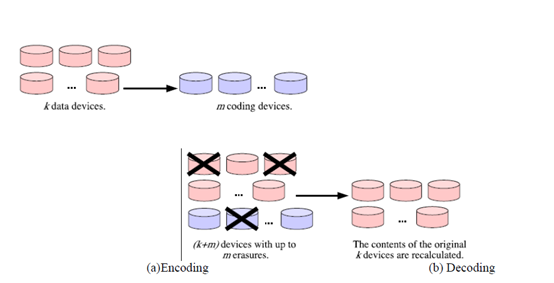
图1:编码操作获取k个数据节点的内容,将其编码后放在m个编码设备上。
解码操作从(k+m)全部的设备上获取一个子集,并通过他们重新计算出放在原始k个设备上的原始数据。
正如图一描述的那样,编码操作获取k个数据设备,并从他们计算出m个编码节点。解码操作通过获取一个有擦除的(k+m)设备的集合,并从其中存活的设备重新计算出原始k个数据节点中的内容。
大多数的码有第三个参数w,称为字长。这个对于一个码的描述将每个设备看作有w位数据。数据设备用D0到Dk-1表示,编码设备用C0到Cm-1表示。每个设备Di或者Cj拥有w位,表示位di,0...diw-1和ci,0...ci,w-1。当然在实际情况当中,每个设备存储了百万字节的数据。为了将一个码的描述与其在实际系统中它的实现相对应,我们做了如下两件事中的一个:
1. 当w∈{8,16,32},我们能够分别认为每w位作为一个字节,短字或者字。考虑到当w=8的情况。我们可以认为每个设备容纳B字节。每个编码设备的第一个字节将会通过每个数据设备的第一个字节编码而来。每个编码设备的第二个字节将会通过每个数据设备的第二个字节编码而来。等等。这是标准RS码的工作方式,当w=16或者w=32时,如何工作也应该是清楚的。
2. 更多其他码的工作是通过定义每个编码位ci,j是由一些其他位的子集的按位异或获得。为了在真实系统中实现这些码。我们假定每个设备是由相等大小的w个包构成。现在每个包被其他别的包的一些子集按位异或计算获得。用这种方式,我们能够充分利用这样的现实:我们可以对整个计算机的字执行异或运算,而不是在位上。
在图二举例说明了这个过程。在这个图中,我们假设k=4,m=2和w=4。假如一种码被定义编码位c1,0是由以下公式生成:c1,0=d0,0⊕d1,1⊕d2,2⊕d3,3.
⊕代表异或操作。图2展示了编码包中c1,0是由数据包中的d0,0,d1,1,d2,2,d3,3计算得到。我们把每个包的大小叫做包长packetize,w个包的大小叫做编码数据块大小coding block size。很明显包长packetize一定是计算机字长的整数倍,编码块大小将是w * packetize的倍数。
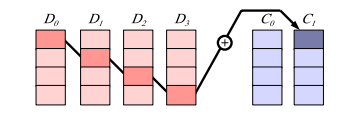
图·2尽管码在系统中被描述只有w位,他们在实现中使用的包是更大的。每个包在实现中对应的描述中的一位。这个图展示了公式c1,0=d0,0⊕d1,1⊕d2,2⊕d3,3的实现。
2 库的模块
这个库被划分为5个模块,每个模块由自己的头文件和C的实现。例如,我们使用一个码,一个只需要其中的三个模块:galois, jerasure and 其他的一个。这些模块如下:
- galois.h/galois.c:这是伽罗华运算的程序,在[Pla07]中描述及实现。
- jerasure.h/jerasure.c:这是内核例程,对大多数纠删码是常见的。他们除了galois,不依赖于其他模块。它们包含了基于矩阵的编解码,基于二进制矩阵的编解码,二进制矩阵到schedules的转换,矩阵和二进制矩阵的求逆。
- reedsol.h/reedsol.c:这些程序是为了创建RS码的分布矩阵[RS60,Pla97, PD05]。它们也包含在[Anv07]中提到的针对RAID-6优化的RS码编码优化。
- cauchy.h/cauchy.c:这些是CRS码运作的程序[BKK +95, PX06],与RS码相比,采用了一个不同的矩阵构造。我们不仅为了RAID-6支持创建最优的柯西分布矩阵,而且支持创建了目前发布的最优的分布矩阵。
- liberation.h/liberation.c:这些是使用最小密度MDS码执行RAID-6编解码的码—RAID-6 Liberation codes [Pla08b], Blaum-Roth codes [BR99]和 RAID-6 Liber8tion code [Pla08a]的程序。这些是基于位矩阵的码,比传统的类RS码及EVENODD码[BBBM95]要好。在某些情况下,它们甚至比目前已知的最优的RAID-6码RDP [CEG+04]更好。
每一个模块会在下面的自己的小节中描述。此外,每个模块都会有使用的示例程序。
3 基于矩阵的编码
给予矩阵的编码技术在[Pla97]被详细地讲解。我们在这里给出了概述。
作者的警告:我们正在使用的“distribution matrices分布矩阵”是以前的术语。在标准编码理论中,分布矩阵被翻译为生成矩阵(Generator matrix)。在jerasure下个版本的修订中,我们会更新术语使得与经典的编码理论中的术语一致。
假设我们有k个数据字(data word)和m个编码字,每个字由w位组成。我们能够通过图3中的矩阵向量乘积来描述一个基于矩阵编码的系统。图中叫做的分布矩阵是一个(k*m)*k的矩阵。矩阵中的元素属于伽罗华域GF(2w) 。这意味着它们是介于0到2w-1之间的整数,它们的运算是使用伽罗华运算:加是对应着XOR异或运算,乘法的实现多种多样。[Pla07a]中的伽罗华运算类库已经有实现伽罗华域运算实现的函数。

图3:使用一个矩阵向量乘积来描述一个编码系统
图中分布矩阵的前k行是一个k*k的单位矩阵。剩余的m行是叫做编码矩阵,其定义的方式多种多样[Rab89, Pre89, BKK+95, PD05]。分布矩阵乘以一个包含数据字的向量,并产生一个包含数据字和编码字的向量。因此,为了编码,我们需要用数据和编码矩阵进行m次点积运算。
为了解码,我们注意到每个系统中的每个字都对应着分布矩阵的一行。当设备失效,我们从k个没有失效的设备的字对应的分布矩阵中的k行构成解码矩阵。注意到,这个矩阵与原始数据相乘等于我们选择的k个幸存设备中的数据。如果我们对这个矩阵求逆矩阵然后对方程两边乘以这个逆矩阵,那么我们获得了解码方程——这个逆矩阵乘以k个幸存设备的行获得原始数据。
4 基于位矩阵的编码
基于位矩阵编码是在最初CRS码的论文[BKK+95]中提出。为了使用位矩阵进行编解码运算,我们通过w因子对GF(2w)的分布矩阵进行每个方向的扩展。
一个w(k+m)*wk矩阵我们叫做一个位分布矩阵(BDM)。我们将其与一个wk元素向量相乘,该向量是由每个数据设备中的w位组成。其相乘结果是一个w(k+m)元素向量,这个元素向量是由每个数据设备及编码设备的w位组成。这个过程在图4中描述。我们将这些矩阵看作是由w*w的子矩阵(对应图3中的分布矩阵的每个元素)组成的更加容易理解。
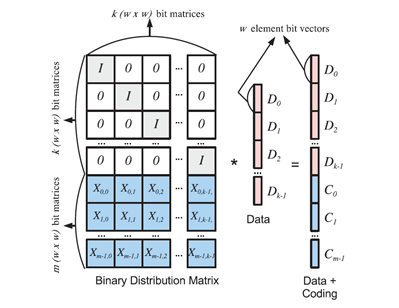
图4:描述一个带有位矩阵向量乘积的编码系统
与GF(2w)中的矩阵向量乘积一样,结果的每一行都对应着BDM的一行,计算过程是BDM的该行和数据位的点积。因为所有的元素都是位,我们可以通过对位分布矩阵行中为1对应的每个数据位进行XOF异或运算来完成点积运算。换句话说,计算点积我们只使用异或运算而不使用加法和乘法。此外,这个点积的性能与行中1的个数相关。因此,找到含有很少1的矩阵是有必要的。
除了每个设备对应矩阵的w行而不是一行,位矩阵的解码与GF(2w)域上的矩阵解码过程是相同的。还需要注意的是描述中的一个位对应着实现中的一个包。
虽然传统的位矩阵的构造是使用一个GF(2w)的标准分布矩阵,但是可以构造与伽罗华域运算无关的位矩阵,还是仍然要考虑编解码性能。
4.1 使用schedule代替位矩阵
考虑基于位矩阵的编码的操作。我们在图5中给了一个k=3,w=5的例子,我们计算出编码设备的内容。最直接的编码方法是为了编码设备的每五位去计算五次点积, 我们能够通过遍历五行中的每一行,在矩阵中为1对应的地方做异或运算。
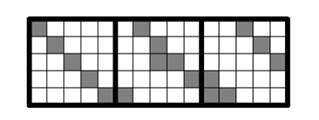
图5:一个k=3,w=5位矩阵的超行的例子
因为这个矩阵是稀疏的,所以预先计算编码操作是比每次编码去遍历矩阵更加有效。我们代表编码的数据结构是一个schedule,它是一个五元组:<op,sd,sb,dd,db>,op是一个操作码:0代表复制,1代表XOR异或,sd是源设备的id,sb是源设备的位,最后的两个dd,db是目标设备和位。按照惯例,我们使用0到k+m-1的整数来定义设备。当i<k定义数据设备Di,当i小于等于k定义编码设备Ci-k。
一个使用图5中位矩阵进行编码的schedule如图6所示。

图6:图5中的位矩阵的位矩阵运算schedule。(a)展示了这个schedule,(b)展示了对应schedule每一行的点积方程式。
正如[HDRT05, Pla08]提出,一种可以推导出在点积中使用位矩阵编解码的schedule 的表达式,因此可以使用更少的XOR运算来计算位矩阵向量积而不是通过简单的遍历位矩阵。即使是在BDM的最后w行中有超过kw的1的情况下,RPD编码采用这种方式获取最佳性能[CEG+04]。我们把这样的调度称为智能调度,并且通过简单地遍历矩阵哑调度进行调度。
未完待续。。。好难翻译,有要一起的朋友可以一起翻译