早上刷空间发现最近好多人过生日诶~
仔细想想,好像4月份的时候也是特别多人过生日【比如我
那么每个人生日的月份有什么分布规律呢。。。突然想写个小程序统计一下
最简单易得的生日数据库大概就是新浪微博了:
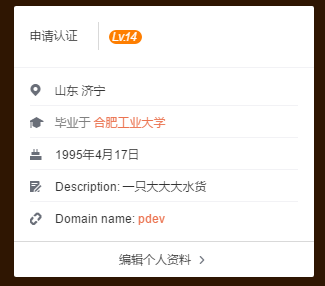
但是电脑版的新浪微博显然是动态网页。。。如果想爬这个应该要解析JS脚本【就像上次爬网易云音乐。。然而并不会解
其实有更高效的方法:爬移动版
移动版因为手机浏览器的限制大多都做了简化,更有利于爬虫
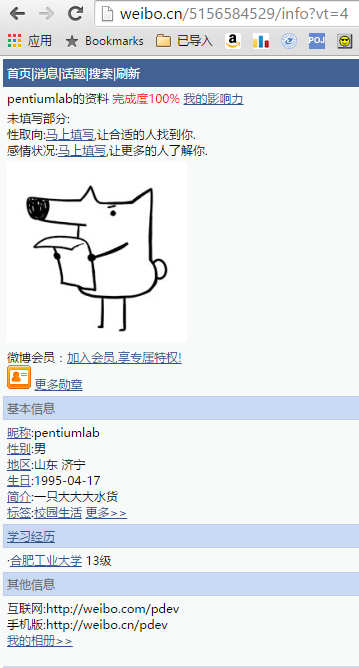
注意上面的网址:http://weibo.cn/5156584529/info
经测试不同的用户仅仅是中间的数字不同,那么只要枚举数字就可以实现爬虫了~
但是移动版微博想查看用户资料是必须要登录的。所以我们要先模拟登录,获取cookie,再访问url,获取用户资料。
许多网站的登录都用到了cookie,大体过程如下:
用户输入用户名密码,浏览器将这些组成一个form(表单)提交给服务器,若服务器判断用户名密码正确则会返回一个cookie,然后浏览器会记录下这个cookie。之后用本地的cookie再访问就不用登录了。
模拟登录:
打开微博移动版主页http://weibo.cn,点击登录,得到登录地址:
http://login.weibo.cn/login/?ns=1&revalid=2&backURL=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=
【这界面真的好丑。。。
输入用户名密码登录,用chrome抓包,查看表单:
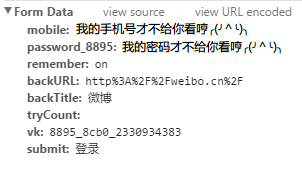
其实我们只需要表单就够了。
用Python中的urllib2,使用表单数据访问登录页,获取cookie,再用cookie访问用户页即可。
但是还要注意一个问题:新浪微博作了反爬虫处理,因此会遇到这个错误:
urllib2.HTTPError: HTTP Error 403: Forbidden
所以还要加上一个头信息headers来冒充浏览器
code:


1 __author__ = 'IBM' 2 import urllib2 3 import urllib 4 import cookielib 5 headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} 6 cookie = cookielib.CookieJar() 7 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) 8 9 #uurl='http://weibo.cn/5156582529/info' 10 wurl='http://login.weibo.cn/login/?backURL=&backTitle=&vt=4&revalid=2&ns=1' 11 12 logindata=urllib.urlencode( 13 { 14 'mobile':'不许偷看我手机号!', 15 'password_8199':'不许偷看我密码!', 16 'remember':'on', 17 'backURL':'http%253A%252F%252Fweibo.cn%252F', 18 'backTitle':'%E5%BE%AE%E5%8D%9A', 19 'tryCount':'', 20 'vk':'8199_4012_2261332562', 21 'submit':'%E7%99%BB%E5%BD%95' 22 } 23 ) 24 25 loginreq=urllib2.Request( 26 url=wurl, 27 data=logindata, 28 headers=headers 29 ) 30 31 loginres=opener.open(loginreq) 32 print loginres.read() 33 34 html=opener.open(urllib2.Request(url='http://weibo.cn/5156584529/info',headers=headers)) 35 dat=html.read() 36 print dat
输出的dat就是用户资料页的HTML。随便想要什么信息都可以去里面找啦~
【但是目前还有个问题没解决:注意表单里红色underline的那两段:
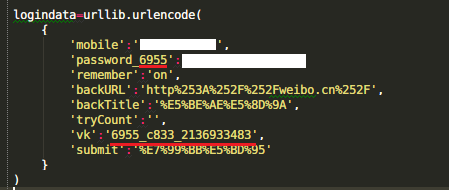
经测试这两个数字每次登录的时候都是不一样的。。而且同一个数字有效期是一定的,也就是说过一会儿这段代码可能就登录不了了。。。
个人猜测这可能是为了反爬虫吧。。。
under construction
Ref:
http://blog.csdn.net/pleasecallmewhy/article/details/9305229
http://www.douban.com/note/131370224/