1. 计算机系统分为三层:
应用软件
操作系统
计算机硬件硬件
2.
文本编辑器读一个文件的三个过程:*****
1. 先启动文本编辑器
2. 文件编辑器会将文件内容读入内存
3. 将读入内存的内容显示到屏幕上
Cpython解释器执行一个py文件的三个过程:
1. 先启动python解释器
2. python解释器会将py文件的内容当中普通的文本内容读入内存
3. 开始解释执行刚刚读入内存的代码,识别python语法
3. 字符编码
字符编码指的是字符转换成/编码成数字
编码的过程一定要遵循一个标准,该标准称之为字符编码表
字符------>--编码-------->数字
数字--------解码--------数字
4.编码表的发展史与介绍
计算机最先诞生于美国,所以最先出现的是纯英文字符串的ASCII表
世界各国开始使用计算机,也相继诞生了各种语言的字符编码表
1)ASCII表:
只能识别英文字符,用8bit(8个二进制位)对应一个英文字符
其实7个二进制位就能完全覆盖英文字符,科学家考虑到可能会有新的字符产生,预留了空间 拓展 1)假如1位二进制码代表一个英文字字符 0、1 最多只能代表两个两个英文字符 2)假如2位二进制码代表一个英文字字符 00、01、10、11 那么最多也就代表4个英文字符 ...... ...... 3)假如7位二进制码代表一个字符 000 0000 =a 111 1111 =b 最多可以有b-a+1个字符 由b+1-1=b 可以得出b=1000 0000-1 2**7=128
8bit==1个英文字符
1个英文字符==1Bytes
2)GBK表:
可以识别中文字符、英文字符,同样用8bit对应一个英文字符,对于中文,显然256个字符远不能覆盖汉语字符,它用用16个bit对应一个中文字符
1个英文字符====>1Bytes
1个中文字符====>2Bytes
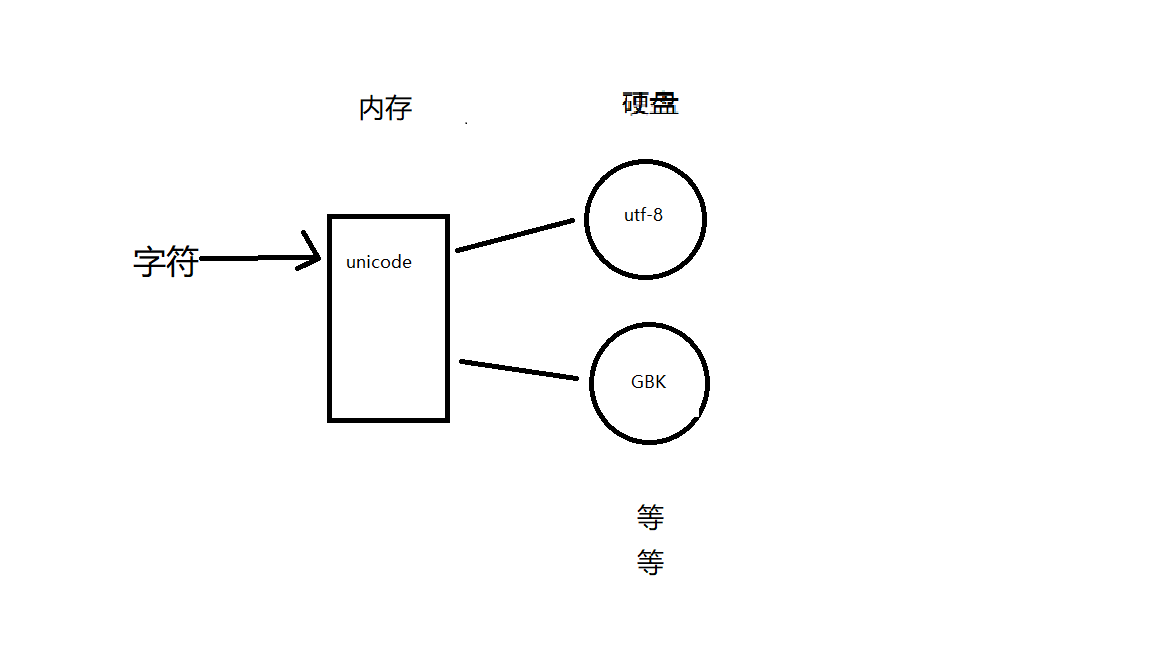
3) unicode: (内存中默认使用该编码)
用2Bytes表示一个字符
1. 可以识别万国字符 (字符与内存)
2. 与各种字符编码的二进制数字都有对应关系(硬盘与内存之间转换)
它的存在为了实现平缓的过度,总有一天,使用各国独自编码表的老版本的软件淘汰后,
会出现内存硬盘中使用的都是utf-8,就像当初只使用ASCII码
4) utf-8全称Unicode Transformation Format:
为了解决unicode从内存往硬盘存储数据效率低的问题
1个英文字符====>1Bytes
1个中文字符====>3Bytes
结论:
1、 编码与解码
字符--------编码--------》数字
字符《--------解码--------数字
unicode二进制========编码========》utf-8二进制
unicode二进制《=======解码=========utf-8二进制
2. 内存中固定使用unicode编码,我们可以改变的是数据由内存刷到硬盘时采用的编码(应该采用utf-8)
unicode的特点:
1. 可以识别万国字符
2. 与各种字符编码的二进制数字都有对应关系
3. 解决乱码问题的核心:
1. 字符当初以什么编码存的,就应该以什么编码去读
2. 保证运行python程序的前两个阶段不乱码的解决方案:添加文件头
在文件首行输入#coding:文件当初存的字符编码


data = b'hello world!' data = str(data,encoding='utf-8') data = bytes(data,encoding='utf-8') 想转换什么类型就用响应的str,或bytes