第一部分,代码分析
第一次作业
第一次作业,说实话,真的就是在面向过程,不明白什么叫做面向对象,虽然有着假期作业的铺垫,对java的语言有着一定的认识,但是总是想先用类似C语言的伪代码写出来过程,然后按照数据方法分成若干块,再建立成若干个类。为了面向对象而写类,为了满足Checkstyle而分成若干个方法,理解很不到位。总而言之做法就是用个hashmap存系数,指数作为索引,合并同类项用contain完成,求导就是新开一个hash表,存储求导之后的<exp,num>,计算方法也很简单,就是一个乘法的计算。
第一次作业的难点在于从输入的字符串读取想要的信息,考查的是正则表达式的基本功。总体来说不太难
第一次作业主要思考的地方在于toStrng,这是影响性能分的关键,换句话说,要考虑到所有可以让你的程序长度缩短的方法,比如负号不能开头,开头+要删除等等,第一次作业基本没啥问题了。
第一次作业类的关系比较简单,没有值得放图的必要。
第二次作业
第二次作业的难点在以下几个方面
(1)如何判断输入字符串的合法性?
我选择的方式不是正难则反,遍历所有反例,相反我认为遍历反例比较困难,我选择了从正面出发,构建出一个能够囊括所有正确表达式的正则表达式。构建的方法基本按照指导书的推导方法。由于第二次作业不需要判断空格导致的wrong format。所以我选择了直接去除所有空格。然后,构建 sunm正则表达式 snum=“([+-]?\d+)”构建三角函数 tri=“(sin|cos)\(x\)(\^" + snum + ")?”之类的表达式。
如图所示,按照最后得到的pp表达式,对输入的poly进行匹配,匹配到了就正常,否则就WF。
(2)怎么进行计算
根据我们的层次化正则表达式,我们每次匹配一个项(item)进来,item的构成是由 factor*factor*factor.....,即(factor(*factor)*)构成
对于我们的item,使用split函数,分成若干个factor进行求导,对于每一个factor求导得到一个字符串,用这个字符串和剩下的factor的字符串用“*”连接,就得到了item求导的一部分,把所有factor都求导拼接之后的结果用“+”起来,就得到一个item的求导式子。所有item求导的式子进行连接,得到了poly的求导字符串。然后进行输出等等。
总的来说,第二次作业,也还是再面向对象边缘徘徊,稍微明白了一点对于类应该怎么处理,怎么划分,但是没有运用到自己地代码里面,整体来说是面向过程换了个写法,还是很不成熟。

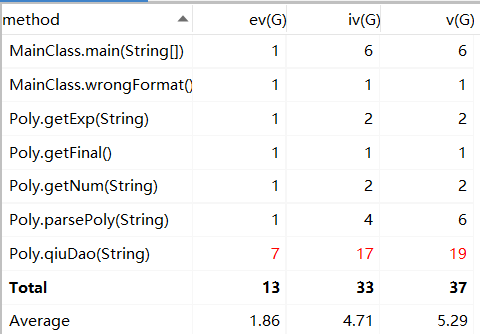
所有复杂都集中在qiuDao()函数里面复杂地判断和生成字符串
第三次作业
第三次作业在第二次地基础之上增加了嵌套项,其中三角函数嵌套项,表达式嵌套在括号里面可以作为因子(factor)
这次的难点就是嵌套的处理,处理完嵌套,换句话说就是知道每个函数嵌套的内容,我们就可以按照第二次作业的方法,用类似的方式,对各个item求导之后的字符串进行连接。
那么问题来了,怎么去分析嵌套?
方法就是层次化分析,遍历字符串,把sin(factor)里面的factor换成@,把(poly)因子里的poly换成#,然后用容器储存替换之后的因子。‘
对于格式检查,就把替换之后的字符串按照第二次的正则表达式改动一下去匹配判断格式,
再把被换成@的factor递归调用,用正则表达式判断是否满足factor正则。
再对被替换成#的poly递归调用,用正则表达式判断是否满足poly正则。
在使用Cal类的String diff()进行计算的时候,对于一个poly拆分出的item中的每一个factor,建立出一个Term项,Term的两个方法返回求导字符串和本身字符串。其中求导方法调用了diff()方法,实现了递归的操作。
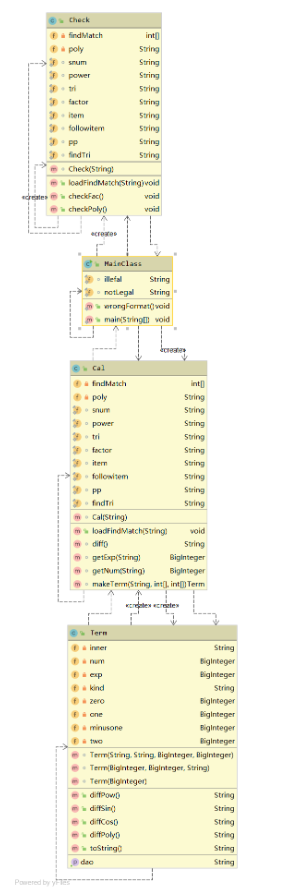
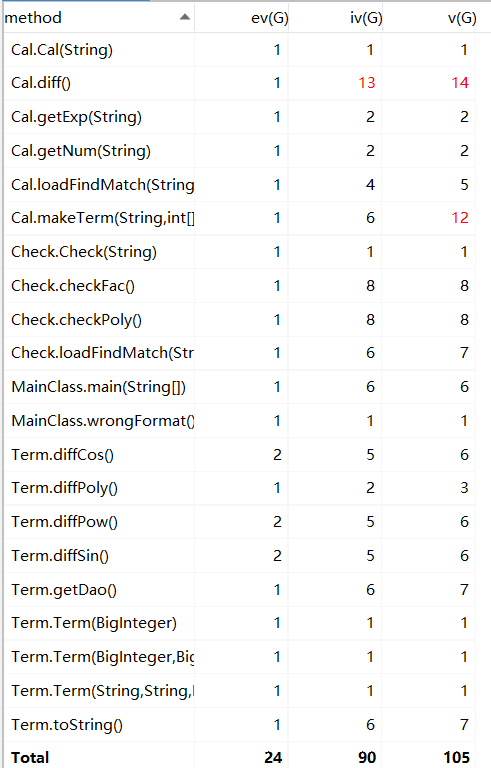
方法主要复杂在diff()里面,因为diff既要替换,还要求导,使得方法比较臃肿,有很大的拆分空间。
除此之外,makeTerm方法,因为没有使用多态继承之类的,使用flag来判断种类,显得十分复杂
第二部分 自己的bug和找别人的bug
(1)自己的bug
第一次作业和第二次作业都没有出现bug。
第三次作业是对static类型变量的使用出现错误导致的,以及忘了加上指数。。
由于太过信任中测,导致本地没有仔细测试,很简单的测试点,出现了很大的问题。三角函数toString的时候忘记加上指数,导致在强测中直接崩溃11个测试点,出现了巨大的bug。
此外,static变量使用不当,导致了很多测试点会runtime error,但是我对re的处理方式是直接WF,导致我本地测试马马虎虎,没有仔细看是否真的WF还是RE出问题了。
这两个问题都是小细节导致的大错误,和整体架构没有关系,这两个本应该本地测试很容易找出来的小问题竟然造成了这么大的影响,真的后悔莫及。
(2)找别人bug
hack别人的时候,使用研读代码找边界问题加少量自动化测评。首先使用常见边缘极限测试寻找别人bug,这些没有结果的话,再去读代码,寻找优化或者计算的潜在问题,对小细节进行攻击。如果还是没有问题,就使用自动化生成少量数据测试。前两次因为强测表现很好,基本没找到别人的bug,第三次同一个房间的人基本都是优化出bug,但是基本都是类似的bug,两个测试点找了8个bug,之后也没什么大的问题
第三部分 重构和改进
我觉得前两次的改动地方基本不大,抽象化的低下以及建立在字符串为基础的运算,没什么特别的变动。
第三次的改动之处我觉得可以把Term类细分,分成sin,cos,constant,power,poly几个类型,都继承自父类Term,重写toString和diff()方法,减少一堆if判断种类。
三次代码的编写过程中,因为抽象层次很低,几乎面向过程,所以没有重构,都是上一次的函数加一些if判断,就可以直接实现功能了。
第四部分 对比感受
太不抽象了,我的感受就是,只有抽象到一定的层次,才可以进行面向对象,走一步看一步的做法注定很难改成面向对象,写的类顶多是一堆方法放一起,类之间的关系混乱不清,看了别人的代码,觉得自己总是急于每一步都能做出一个字符串,最后拼在一起,而不是用一个抽象结构储存各个项,最终用一个统一的toString函数生成结果,导致我的代码可优化性很差,换句话说,牺牲了性能保证了时间的缩短和正确率的提高。
以后思考问题,要适当的抽象,在高一级的层次组织架构,设计代码,减少不必要的麻烦。