原文链接:http://www.one2know.cn/keras7/
Autoencoder 自编码
- 压缩与解压
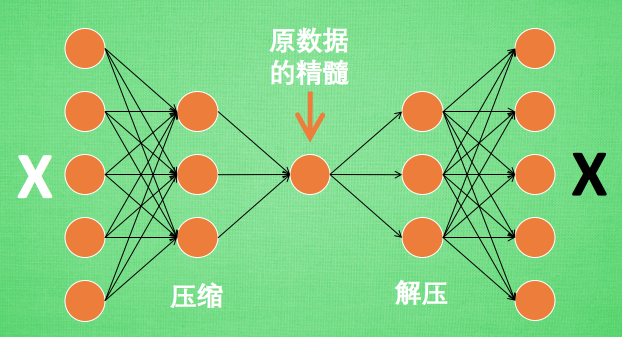
原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了. 所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分 - Encoder 编码器
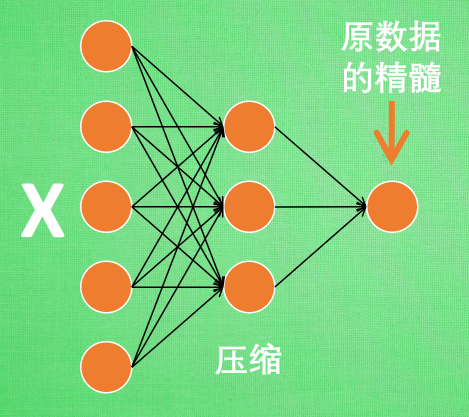
编码器能得到原数据的精髓, 然后我们只需要再创建一个小的神经网络学习这个精髓的数据,不仅减少了神经网络的负担, 而且同样能达到很好的效果
自编码能从原数据中总结出每种类型数据的特征, 如果把这些特征类型都放在一张二维的图片上, 每种类型都已经被很好的用原数据的精髓区分开来. 如果你了解 PCA 主成分分析, 再提取主要特征时, 自编码和它一样,甚至超越了 PCA. 换句话说, 自编码 可以像 PCA 一样 给特征属性降维 - Decoder 解码器
将精髓信息解压成原始信息 - 实例
把 datasets.mnist 数据的 28×28=784 维的数据,压缩成 2 维的数据,然后在一个二维空间中可视化出分类的效果
import numpy as np
np.random.seed(1)
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Dense, Input
import matplotlib.pyplot as plt
# 获取数据 非监督学习 不用y
(x_train, _), (x_test, y_test) = mnist.load_data()
# 预处理
x_train = x_train.astype('float32') / 255. - 0.5 # 标准化 -0.5~0.5
x_test = x_test.astype('float32') / 255. - 0.5
x_train = x_train.reshape((x_train.shape[0], -1))
x_test = x_test.reshape((x_test.shape[0], -1))
# print(x_train.shape)
# print(x_test.shape)
# 要压成的维度
encoding_dim = 2
# 原来的图片数据大小
input_img = Input(shape=(784,))
## 建立神经网路
# 编码层
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim)(encoded)
# 解码层
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded)
# 构建自动编码模型
autoencoder = Model(input=input_img, output=decoded)
# 激活模型
autoencoder.compile(optimizer='adam', loss='mse')
# 训练 非监督学习 经历压缩和解压的自己跟原来的自己比较
autoencoder.fit(x_train, x_train,epochs=20,batch_size=256,shuffle=True)
# 可视化结果
encoded_imgs = autoencoder.predict(x_test)
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test)
plt.colorbar()
plt.show()
输出:
Epoch 1/20
256/60000 [..............................] - ETA: 1:41 - loss: 0.2318
1280/60000 [..............................] - ETA: 22s - loss: 0.2211
。。。
59648/60000 [============================>.] - ETA: 0s - loss: 0.0393
60000/60000 [==============================] - 2s 41us/step - loss: 0.0393
Save&reload 保存提取
- 保存模型
训练完模型之后
from keras.models import save_model
model.save('my_model.h5) - 导入模型
导入保存好的模型
from keras.models import load_model
model = load_model(my_model.h5)
还可以只保存权重,不保存模型结构
model.save_weights('my_model_weights.h5')
model.load_weights('my_model_weights.h5')
还可以用model.to_json 保存完结构之后,然后再去加载这个json_string,只保存结构,没保存权重
from keras.models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)