深入理解锁的前置条件
对象头
什么是对象头
- 在Hotspot虚拟机中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充;
- Java对象头是实现synchronized的锁对象的基础,一般而言,synchronized使用的锁对象是存储在Java对象头里。
- 它是轻量级锁和偏向锁的关键
MarkWord
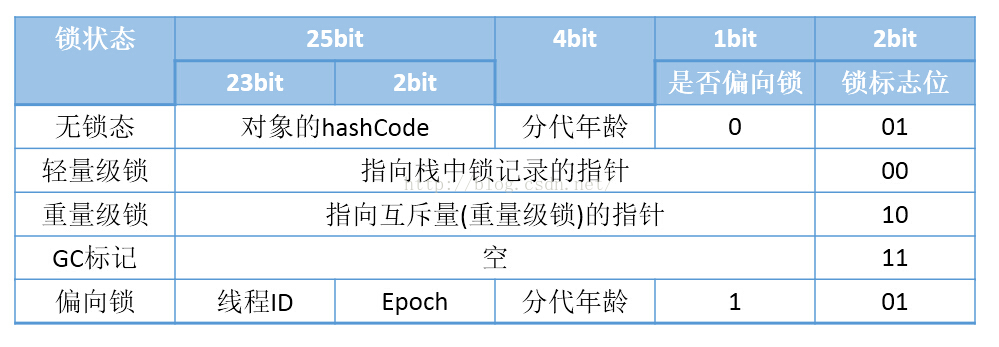
HotSpot虚拟机的对象头(Object Header)包括两部分信息,第一部分用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂 不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”
对象需要存储的运行时数据很多,其实已经超出了32、64位Bitmap结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如在32位的HotSpot虚拟机 中对象未被锁定的状态下,Mark Word的32个Bits空间中的25Bits用于存储对象哈希码(HashCode),4Bits用于存储对象分代年龄,2Bits用于存储锁标志 位,1Bit固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下表所示。
- 通俗理解来说,markword就是一个存放运行时一些数据的区域,里面包含了hashcode、分代年龄、锁的标示等
- mark word的位长度为JVM的一个Word大小,也就是说32位JVM的Mark word为32位,64位JVM为64位。
- 为了让一个字大小存储更多的信息,JVM将字的最低两个位设置为标记位,biased_lock表示是否有偏向锁
- 001 表示无锁
- 000 轻量级锁
- 010 重量级锁
- 011 GC标记
- 101 表示偏向锁
- age 4bit:分代年龄。
- 在GC中,如果对象在Survivor区复制一次,年龄增加1。
- 当对象达到设定的阈值时,将会晋升到老年代。
- 默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。
- 由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
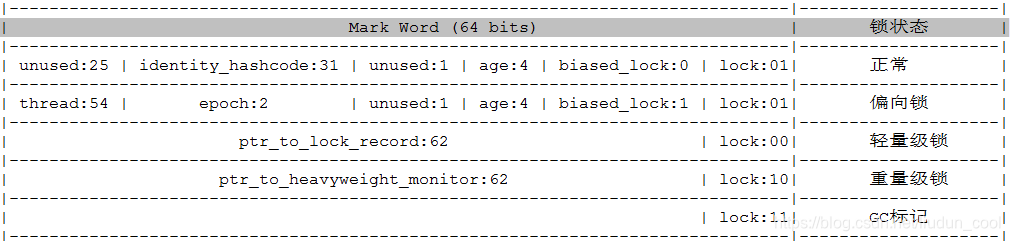
- identity_hashcode:31位的对象标识hashCode
- 采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。
- 当对象加锁后(偏向、轻量级、重量级)MarkWord的字节没有足够的空间保存hashCode,因此该值会移动到管程Monitor中
- thread:持有偏向锁的线程ID。
- epoch:偏向锁的时间戳。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。
Monitor
什么是Monitor?我们可以把它理解为一个同步工具,也可以描述为一种同步机制。所有的Java对象是天生的Monitor,每个object的对象里 markOop->monitor() 里可以保存ObjectMonitor的对象。从源码层面看一下monitor对象
markOop
oop.hpp下的oopDesc类是JVM对象的顶级基类,所以每个object对象都包含markOop
class oopDesc {//顶层基类
friend class VMStructs;
private:
volatile markOop _mark;//这也就是每个对象的mark头
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
markOop.hpp 中 markOopDesc继承自oopDesc,

并扩展了自己的monitor方法,这个方法返回一个ObjectMonitor指针对象:这个ObjectMonitor 其实就是对象监视器

内置锁(ObjectMonitor)
通常所说的对象的内置锁,是对象头Mark Word中的重量级锁指针指向的monitor对象,objectMonitor.hpp,采用ObjectMonitor类来实现monitor:该对象是在HotSpot底层C++语言编写的(openjdk里面看),简单看一下代码:
//结构体如下
ObjectMonitor::ObjectMonitor() {
_header = NULL;
_count = 0;
_waiters = 0,
_recursions = 0; //线程的重入次数
_object = NULL;
_owner = NULL; //标识拥有该monitor的线程
_WaitSet = NULL; //等待线程组成的双向循环链表,_WaitSet是第一个节点
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ; //多线程竞争锁进入时的单向链表
FreeNext = NULL ;
_EntryList = NULL ; //_owner从该双向循环链表中唤���线程结点,_EntryList是第一个节点
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
到目前位置,对于锁存在哪个位置,我们已经清楚了,锁存在于每个对象的 markOop 对象头中.对于为什么每个对象都可以成为锁呢? 因为每个 Java Object 在 JVM 内部都有一个 native 的 C++ 对象 oop/oopDesc 与之对应,而对应的 oop/oopDesc 都会存在一个markOop 对象头,而这个对象头是存储锁的位置,里面还有对象监视器,即ObjectMonitor,所以这也是为什么每个对象都能成为锁的原因之一。那么 synchronized是如何实现锁的呢?
ObjectMonitor队列之间的关系转换可以用下图表示:
既然提到了_waitSet和_EntryList(_cxq队列后面会说),那就看一下底层的wait和notify方法
wait方法的实现过程:
//1.调用ObjectSynchronizer::wait方法
void ObjectSynchronizer::wait(Handle obj, jlong millis, TRAPS) {
/*省略 */
//2.获得Object的monitor对象(即内置锁)
ObjectMonitor* monitor = ObjectSynchronizer::inflate(THREAD, obj());
DTRACE_MONITOR_WAIT_PROBE(monitor, obj(), THREAD, millis);
//3.调用monitor的wait方法
monitor->wait(millis, true, THREAD);
/*省略*/
}
//4.在wait方法中调用addWaiter方法
inline void ObjectMonitor::AddWaiter(ObjectWaiter* node) {
/*省略*/
if (_WaitSet == NULL) {
//_WaitSet为null,就初始化_waitSet
_WaitSet = node;
node->_prev = node;
node->_next = node;
} else {
//否则就尾插
ObjectWaiter* head = _WaitSet ;
ObjectWaiter* tail = head->_prev;
assert(tail->_next == head, "invariant check");
tail->_next = node;
head->_prev = node;
node->_next = head;
node->_prev = tail;
}
}
//5.然后在ObjectMonitor::exit释放锁,接着 thread_ParkEvent->park 也就是wait
总结:通过object获得内置锁(objectMonitor),通过内置锁将Thread封装成OjectWaiter对象,然后addWaiter将它插入以_waitSet为首结点的等待线程链表中去,最后释放锁。
notify方法的底层实现
//1.调用ObjectSynchronizer::notify方法
void ObjectSynchronizer::notify(Handle obj, TRAPS) {
/*省略*/
//2.调用ObjectSynchronizer::inflate方法
ObjectSynchronizer::inflate(THREAD, obj())->notify(THREAD);
}
//3.通过inflate方法得到ObjectMonitor对象
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
/*省略*/
if (mark->has_monitor()) {
ObjectMonitor * inf = mark->monitor() ;
assert (inf->header()->is_neutral(), "invariant");
assert (inf->object() == object, "invariant") ;
assert (ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is inva;lid");
return inf
}
/*省略*/
}
//4.调用ObjectMonitor的notify方法
void ObjectMonitor::notify(TRAPS) {
/*省略*/
//5.调用DequeueWaiter方法移出_waiterSet第一个结点
ObjectWaiter * iterator = DequeueWaiter() ;
//6.后面省略是将上面DequeueWaiter尾插入_EntrySet的操作
/**省略*/
}
总结:通过object获得内置锁(objectMonitor),调用内置锁的notify方法,通过_waitset结点移出等待链表中的首结点,将它置于_EntrySet中去,等待获取锁。注意:notifyAll根据policy不同可能移入_EntryList或者_cxq队列中,此处不详谈。
在了解对象头和ObjectMonitor后,接下来我们结合分析synchronzied的底层实现。
深入锁的源码
了解了对象头以及monitor以后,接下来去分析synchronized的锁的实现,就会相对简单了。前面讲过synchronized的锁是进行过优化的,引入了偏向锁、轻量级锁;锁的级别从低到高逐步升级, 无锁->偏向锁->轻量级锁->重量级锁.锁的类型:锁从宏观上分类,分为悲观锁与乐观锁。
OS内核级别锁
内核Spinlock
为什么要有锁
在SMP系统中,如果仅仅是需要串行地增加一个变量的值,那么使用原子操作的函数(API)就可以了。但现实中更多的场景并不会那么简单,比如需要将一个结构体A中的数据提取出来,然后格式化、解析,再添加到另一个结构体B中,这整个的过程都要求是「原子的」,也就是完成之前,不允许其他的代码来读/写这两个结构体中的任何一个。
这时,相对轻量级的原子操作API就无法满足这种应用场景的需求了,我们需要一种更强的同步/互斥机制,那就是软件层面的「锁」的机制。
同步锁的「加锁」和「解锁」是放在一段代码的一前一后,成对出现的,这段代码被称为Critical Section/Region(临界区)。但锁保护的并不是这段代码本身,而是其中使用到的多核/多线程共享的变量,它「同步」(或者说串行化)的是对这个变量的访问,通俗的语义就是“我有你就不能有,你有我就不会有”。
Linux中主要有两种同步锁,一种是spinlock,一种是mutex。spinlock和mutex都既可以在用户进程中使用,也可以在内核中使用,它们的主要区别是前者不会导致睡眠和调度,属于busy wait形式的锁,而后者可能导致睡眠和调度,属于sleep wait形式的锁。
spinlock是最基础的一种锁,像后面将要介绍的rwlock(读写锁),seqlock(读写锁)等都是基于spinlock衍生出来的。就算是mutex,它的实现与spinlock也是密不可分。
spinlock加锁
Linux中spinlock机制发展到现在,其实现方式的大致有3种。
Compare And Swap
最古老的一种做法是:spinlock用一个整形变量表示,其初始值为1,表示available的状态。当一个CPU(设为CPU A)获得spinlock后,会将该变量的值设为0,之后其他CPU试图获取这个spinlock时,会一直等待,直到CPU A释放spinlock,并将该变量的值设为1。
那么其他的CPU是以何种形式等待的,如果有多个CPU一起等待,形成了竞争又该如何处理?这里要用到经典的CAS操作(Compare And Swap)。
- 谁和谁比较
目前,sh架构的Linux实现中还保留有这种经典的实现方法(相关代码位于/arch/sh/include/asm/spinlock-cas.h)。
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
while (!__sl_cas(&lock->lock, 1, 0));
}
static inline unsigned __sl_cas(volatile unsigned *p, unsigned old, unsigned new)
{
__asm__ __volatile__("cas.l %1,%0,@r0"
: "+r"(new)
: "r"(old), "z"(p)
: "t", "memory" );
return new;
}
其中,"p"指向spinlock变量所在的内存位置,存储的是当前spinlock实际的值,"old"存储的试图获取spinlock的本地CPU希望的值(1)。
不断地把「期望的值」和「实际的值」进行比较(compare),当它们相等时,说明持有spinlock的CPU已经释放了锁,那么试图获取spinlock的CPU就会尝试将"new"的值(0)写入"p"(swap),以表明自己成为spinlock新的owner。
汇编代码看起来可能略费力一些,用一段伪代码来展示或许会更加地直观:
function cas(p, old, new)
{
if *p ≠ old
do nothing
else
*p ← new
}
这里只用了0和1两个值来表示spinlock的状态,没有充分利用spinlock作为整形变量的属性,为此还有一种衍生的方法,可以判断当前spinlock的争用情况。具体规则是:每个CPU在试图获取一个spinlock时,都会将这个spinlock的值减1,所以这个值可以是负数,而「负」的越多(负数的绝对值越大),说明当前的争抢越激烈。
- 存在的问题
基于CAS的实现速度很快,尤其是在没有真正竞态的情况下(事实上大部分时候就是这种情况), 但这种方法存在一个缺点:它是「不公平」的。 一旦spinlock被释放,第一个能够成功执行CAS操作的CPU将成为新的owner,没有办法确保在该spinlock上等待时间最长的那个CPU优先获得锁,这将带来延迟不能确定的问题。
Ticket Spinlock
为了解决这种「无序竞争」带来的不公平问题,spinlock的另一种实现方法是采用排队形式的"ticket spinlock"。这里,我想展示ticket spinlock的两个实现版本,它们的原理都是一样的,只是具体细节略有差异。
- ACRN版本
先来看下基于x86-64的ACRN hypervisor对于ticket spinlock的实现:
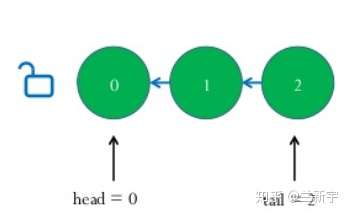
表示一个spinlock的数据结构由"head"和"tail"两个队列的索引组成。
typedef struct _spinlock {
uint32_t head;
uint32_t tail;
} spinlock_t;
"head"指向当前队列的头部,"tail"指向当前队列的尾部,其初始值都为0。
- 解锁
一个spinlock被owner释放时,该spinlock的head值会被owner通过"inc"指令加1。
static inline void spinlock_release(spinlock_t *lock)
{
asm volatile (" lock incl %[head]
" // head加1
:
: [head] "m" (lock->head)
: "cc", "memory");
}
- 加锁
其他CPU在试图获取这个spinlock时,会通过"xadd"指令将"tail"值保存在自己的eax寄存器中,然后将该spinlock的"tail"值加1(也就是将自己加到了这个等待队列的尾部)。
static inline void spinlock_obtain(spinlock_t *lock)
{
asm volatile (" movl $0x1,%%eax
" // eax = 1
" lock xaddl %%eax,%[tail]
" // eax = old tail, new tail = old tail + 1
" cmpl %%eax,%[head]
" // 比较eax(old tail)和head
" jz 1f
" // 相等,获得锁
"2: pause
" // 不相等,继续比较
" cmpl %%eax,%[head]
"
" jnz 2b
"
"1:
"
:
:
[head] "m"(lock->head),
[tail] "m"(lock->tail)
: "cc", "memory", "eax");
}
接下来就是不断的循环比较,判断该spinlock当前的"head"值,是否和自己存储在eax寄存器中的"tail"值相等,相等时则获得该spinlock,成为新的owner。
这类似于你去银行柜台办理业务,假设当前银行只有一个柜台,你需要在自助机上获得一个排队号码(相当于一个ticket),然后当柜台叫到的号码与你手中的号码一致时,你将坐上柜台前面的椅子,此时柜台为你服务,这也是这种实现方式被称为"ticket spinlock"的原因。
在ticket spinlock中,"compare"和"swap"的操作就分离了。把spinlock当前的值和旧的值进行比较(compare),还是由每个试图获得spinlock的CPU来执行的,但设置新的值(swap),则是由上一个持有spinlock的CPU来完成的。
- Linux版本
再来看下基于ARMv6的Linux中,ticket spinlock的实现(相关代码位于/arch/arm/include/asm/spinlock.h):
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
lock->tickets.owner++;
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
[LL/SC]
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
}
"owner"和"next"分别对应ACRN版本中的"head"和"tail"。"wfe"是ARM中的"wait for event"指令,和x86中的pause指令类似,目的是为了降低busy wait时的CPU功耗。
看起来比ACRN的实现简洁?没有,LL/SC这部分也是一段汇编代码,它完成的是和x86的"add"指令一样的工作,和LL/SC是一样的。
__asm__ __volatile__(
"1: ldrex %0, [%3]
" // lockval = lock->slock
" add %1, %0, %4
" // newval = lockval + (1 << TICKET_SHIFT)
" strex %2, %1, [%3]
" // try lock->slock = newval
" teq %2, #0
" // test result = 0 ?
" bne 1b" // not equal, do LL/SC again
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
这里之所以是"1<<TICKET_SHIFT"而不是1,是因为它没有把一个32位的变量全部用来表示spinlock的队列索引,而只是其中的一些bits,事实上也不可能有那么多的CPU同时等待一个spinlock。
- 公平与效率
可见,使用ticket spinlock可以让CPU按照到达的先后顺序,去获取spinlock的所有权,形成了「有序竞争」。根据硬件维护的cache一致性协议,如果spinlock的值没有更改,那么在busy wait时,试图获取spinlock的CPU,只需要不断地读取自己包含这个spinlock变量的cache line上的值就可以了,不需要从spinlock变量所在的内存位置读取。
但是,当spinlock的值被更改时,所有试图获取spinlock的CPU对应的cache line都会被invalidate,因为这些CPU会不停地读取这个spinlock的值,所以"invalidate"状态意味着此时,它们必须重新从内存读取新的spinlock的值到自己的cache line中。
而事实上,其中只会有一个CPU,也就是队列中最先达到的那个CPU,接下来可以获得spinlock,也只有它的cache line被invalidate才是有意义的,对于其他的CPU来说,这就是做无用功。内存比cache慢那么多,开销可不小。
还是用银行叫号来类比,假设现在2号客户的业务办理完了,接下来就该在大厅里叫3号,然后3号客户去办理,但是所有排号的,4号、5号……哪怕是20号,也得听一下叫的号,对于20号来说,它完全可以在叫到19号之前打个盹嘛。
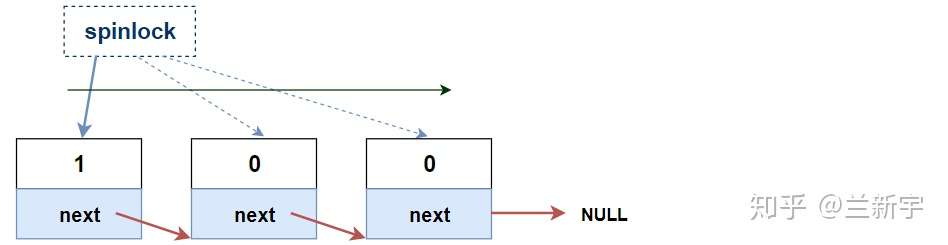
MCS Lock
每当一个spinlock的值出现变化时,所有试图获取这个spinlock的CPU都需要读取内存,刷新自己对应的cache line,而最终只有一个CPU可以获得锁,也只有它的刷新才是有意义的。锁的争抢越激烈(试图获取锁的CPU数目越多),无谓的开销也就越大。
如果在ticket spinlock的基础上进行一定的修改,让每个CPU不再是等待同一个spinlock变量,而是基于各自不同的per-CPU的变量进行等待,那么每个CPU平时只需要查询自己对应的这个变量所在的本地cache line,仅在这个变量发生变化的时候,才需要读取内存和刷新这条cache line,这样就可以解决上述的这个问题。
要实现类似这样的spinlock的「分身」,其中的一种方法就是使用MCS lock。试图获取一个spinlock的每个CPU,都有一份自己的MCS lock。
先来看下per-CPU的MCS lock是由哪些元素构造而成的(代码位于/kernel/locking/mcs_spinlock.h):
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
};
每当一个CPU试图获取一个spinlock,它就会将自己的MCS lock加到这个spinlock的等待队列,成为该队列的一个节点(node),加入的方式是由该队列末尾的MCS lock的"next"指向这个新的MCS lock。
"locked"的值为1表示该CPU是spinlock当前的持有者,为0则表示没有持有。
- 加锁
对于一个锁的实现来说,最核心的操作无非就是「加锁」和「解锁」。先来看下MCS lock的加锁过程是怎样的:
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
// 初始化node
node->locked = 0;
node->next = NULL;
// 找队列末尾的那个mcs lock
struct mcs_spinlock *prev = xchg(lock, node);
// 队列为空,立即获得锁
if (likely(prev == NULL)) {
return;
}
// 队列不为空,把自己加到队列的末尾
WRITE_ONCE(prev->next, node);
// 等待lock的持有者把lock传给自己
arch_mcs_spin_lock_contended(&node->locked);
}
前面说过,加入队列的方式是添加到末尾(tail),所以首先需要知道这个「末尾」在哪里。函数的第一个参数"lock"就是指向这个末尾的指针,之所以是二级指针,是因为它指向的是末尾节点里的"next"域,而"next"本身是一个指向"struct mcs_spinlock"的一级指针。
第二个参数"node"是试图加锁的CPU对应的MCS lock节点。
"xchg()"的名称来源于x86的XCHG指令,其实现可简化表示成这样:
xchg(*ptr, x)
{
ret = *ptr;
*ptr = x;
return ret;
}
它干了两件事,一是给一个指针赋值,二是获取了这个指针在赋值前的值。
对应着上面的这个mcs_spin_lock(),通过xchg()获得的"prev"就是"*lock"最初的值(prev = lock)。如果这个值为"NULL",说明队列为空,当前没有其他CPU持有这个spinlock,那么试图获取这个spinlock的CPU可以成功获得锁。同时,xchg()还让lock指向了这个持有锁的CPU的node(lock = node)。
这里用了"likely()",意思是在大部分情况下,队列都是空的,说明现实的应用场景中,一个spinlock的争抢通常不会太激烈。
前面说过,"locked"的值为1表示持有锁,可此刻CPU获取锁之后,竟然没有把自己node的"locked"值设为1?这是因为在队列为空的情况,CPU可以立即获得锁,不需要基于"locked"的值进行spin,所以此时"locked"的值是1还是0,根本就无所谓。除非是在debug的时候,需要查看当前持有锁的CPU,否则绝不多留一丝「赘肉」。
如果队列不为空,那么就需要把自己这个"node"加入等待队列的末尾,"WRITE_ONCE()"的作用是赋值,在这篇文章里已经介绍过了。
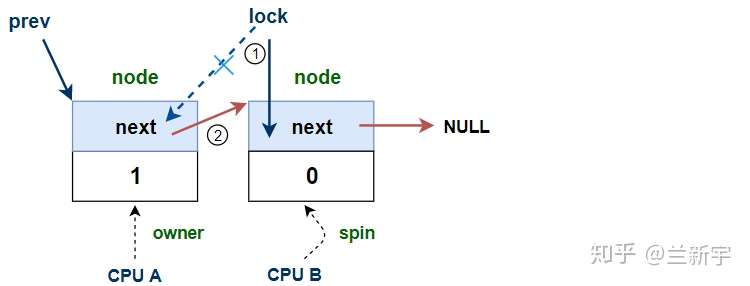
具体的等待过程是调用arch_mcs_spin_lock_contended(),它等待的,或者说"spin"的,是自己MCS lock里的"value"的值,直到这个值变为1。而将这个值设为1,是由它所在队列的前面那个node,在释放spinlock的时候完成的。
#define arch_mcs_spin_lock_contended(l)
do {
smp_cond_load_acquire(l, VAL);
} while (0)
- 解锁
那基于MCS lock的实现,释放一个spinlock的过程是怎样的呢?来看下面这个函数:
void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
// 找到等待队列中的下一个节点
struct mcs_spinlock *next = READ_ONCE(node->next);
// 当前没有其他CPU试图获得锁
if (likely(!next)) {
// 直接释放锁
if (likely(cmpxchg_release(lock, node, NULL) == node))
return;
// 等待新的node添加成功
while (!(next = READ_ONCE(node->next)))
cpu_relax();
}
// 将锁传给等待队列中的下一个node
arch_mcs_spin_unlock_contended(&next->locked);
}
两个参数的含义同mcs_spin_lock()类似,"lock"代表队尾指针,"node"是准备释放spinlock的CPU在队列中的MCS lock节点。
大概率还是没有锁的争抢,"next"为空,说明准备释放锁的CPU已经是该队列里的最后一个,也是唯一一个CPU了,那么很简单,直接将"lock"设为NULL就可以了。
"cmpxchg_release()"中的"release"代表这里包含了一个memory barrier。如果不考虑这个memory barrier,那么它的实现可简化表示成这样:
cmpxchg(*ptr, old, new)
{
ret = *ptr;
if (*ptr == old)
*ptr = new;
return ret;
}
跟前面讲到的"xchg()"差不多,也是先获取传入指针的值并作为函数的返回值,区别是多了一个compare。结合mcs_spin_unlock()来看,就是如果"*lock == node",那么"*lock = NULL"。
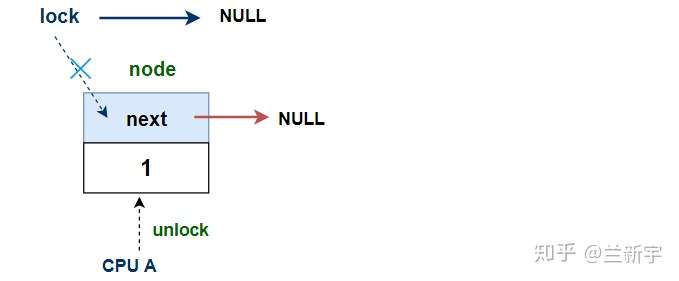
如果"*lock != node",说明当前队列中有等待获取锁的CPU……等一下,这不是和前面的代码路径相矛盾吗?其实不然,两个原因:
- 距离函数开头获得"next"指针的值已经过去一段时间了。
- 回顾前面加锁的过程,新的node加入是先让"*lock"指向自己,再让前面一个node的"next"指向自己。
所以,在这个时间间隔里,可能又有CPU把自己添加到队列里来了。于是,待新的node添加成功后,才可以通过arch_mcs_spin_unlock_contended()将spinlock传给下一个CPU。
#define arch_mcs_spin_unlock_contended(l)
smp_store_release((l), 1)
传递spinlock的方式,就是将下一个node的"locked"值设为1(next->locked = 1)。
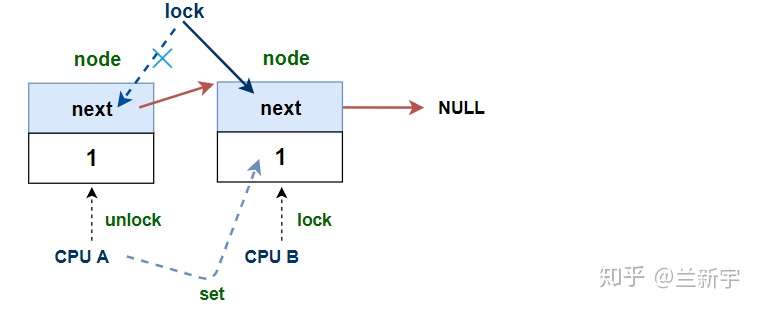
如果在释放锁的一开始,等待队列就不为空,则"lock"指针不需要移动:
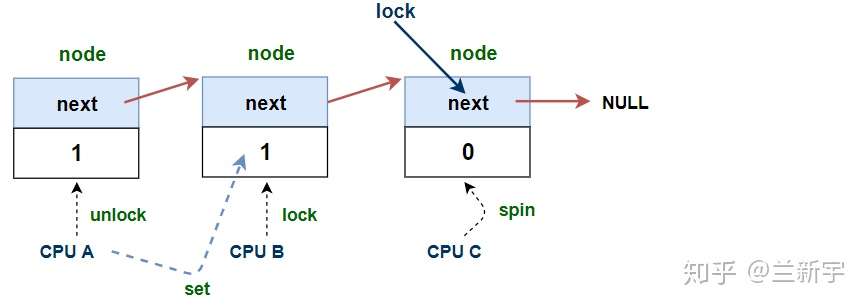
可以看到,无论哪种情况,在解锁的整个过程中,持有锁的这个CPU既没有将自己node中的"locked"设为0,也没有将"next"设为NULL,好像清理工作做的不完整?
事实上,这已经完全无所谓了,当它像「击鼓传花」一样把spinlock交到下一个node手里,它就等同于从这个spinlock的等待队列中移除了。多一事不如少一事,少2个无谓的步骤,效率又可以提升不少。
所以,分身之后的spinlock在哪里?它就在每个MCS lock的"locked"域里,像波浪一样地向前推动着。"locked"的值为1的那个node,才是spinlock的「真身」。
使用MCS lock,就实现了上文那个银行叫号的例子所提出的设想,对于20号来说,不用再听大堂的广播,让19号办理完业务告诉你就行了。
- 存在的问题
MCS lock的实现保留在了Linux的代码中,但是你却找不到任何一个地方调用了它的lock和unlock的函数。
因为相比起Linux中只占4个字节的ticket spinlock,MCS lock多了一个指针,要多占4(或者8)个字节,消耗的存储空间是原来的2-3倍。spinlock可是操作系统中使用非常广泛的数据结构,这多占的存储空间不可小视,而且spinlock常常会被嵌入到结构体中,对于像"struct page"这种对结构体大小极为敏感的,根本不可能直接使用MCS lock。
所以,真正在Linux中使用的,是下文将要介绍的,在MCS lock的基础上进行了改进的qspinlock。研究MCS lock的意义,不光是理解qspinlock的必经之路,从代码的角度,可以看出其极致精炼的设计,绝没有任何多余的步骤,值得玩味。
qspinlock
MCS lock可以解决在锁的争用比较激烈的场景下,cache line无谓刷新的问题,但它内含一个指针,所以更消耗存储空间,但这个指针又是不可或缺的,因为正是依靠这个指针,持有spinlock的CPU才能找到等待队列中的下一个节点,将spinlock传递给它。本文要介绍的qspinlock,其首要目标就是把原生的MCS lock结构体进行改进,「塞」进4字节的空间里。
【MCS Lock的改进 - qspinlock】
先来看一下有3个以上的CPU持有或试图获取spinlock时,等待队列的全貌:
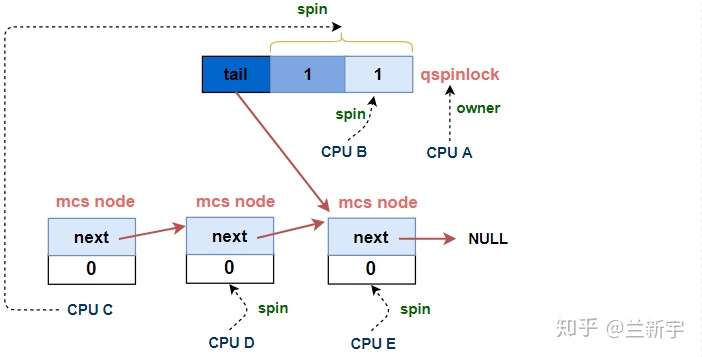
可见,这个等待队列是由一个qspinlock和若干个MCS lock节点组成的,或者说由一个qspinlock加上一个MCS node的队列组成,其中MCS node的队列和上文描述的那个队列基本是一样的,所以我们重点先来看下这个qspinlock是如何构成的(定义在/include/asm-generic/qspinlock_types.h):
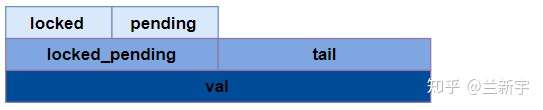
typedef struct qspinlock {
union {
atomic_t val;
#ifdef __LITTLE_ENDIAN
struct {
u8 locked;
u8 pending;
};
struct {
u16 locked_pending;
u16 tail;
};
#else
...
}
}
这里使用的是union,目的是既可以直接引用结构体的位域,又可以直接引用整个变量。如果处理器采用的是little endian,那么它们的内存排布关系如下图所示:
如果采用的是big endian,其内存排布则是这样的:

以32位系统为例,"val"作为一个32位的变量,包含了三个部分:"locked byte", "pending"和"tail","tail"又细分为"tail index"和"tail cpu":

下面来说一下这几个部分各自代表什么含义。
MCS lock中表示是否持有锁的"locked"占据了32个bits,但它其实只需要表示0和1两个值,在qspinlock中被压缩成了8个bits,即"locked byte"(其实只需要1个bit)。
此外,MCS lock的结构体中没有专门的标识等待队列末尾的元素,它使用的是一个全局的二级指针来指向队列末尾。而qspinlock使用的是一个per-CPU的数组来表示每个MCS node(用qnode结构体表示),通过CPU编号作为数组的index,就可以获得对应 MCS node的内存位置,因而qspinlock使用的是末尾 MCS node的CPU编号加1,即"tail cpu",来记录等待队列tail的位置(加1的原因将在后面解释)。
struct qnode {
struct mcs_spinlock mcs;
};
DEFINE_PER_CPU_ALIGNED(struct qnode, qnodes[MAX_NODES]);
除了14个bits的"tail cpu"(针对CPU数目小于16K的情况),还有2个bits是用作"tail index",这是因为Linux中一共有4种context,分别是task, softirq, hardirq和nmi,而一个CPU在一种context下,至多试图获取一个spinlock(原因将在下文给出),因而一个CPU至多同时试图获取4个spinlock,"tail index"就是用来标识context的编号的。
以上说的两点是qspinlock在MCS lock已有元素的基础上进行的改进,相比于MCS lock,qspinlock还新增了一个元素:占据1个bit的"pending",它的作用将随着本文叙述的推进,慢慢揭晓。
为了方便演示,我们把一个"val"对应的"locked", "pending"和"tail"作为一个三元组"(x,y,z)"来表示:
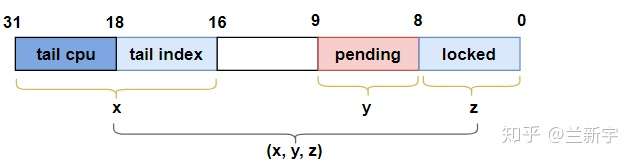
- 加锁
第一个CPU试图获取锁 - uncontended
三元组的初始值是(0, 0, 0),当第一个CPU试图获取锁时,可以立即成为该spinlock的owner,此时三元组的值变为(0, 0, 1):
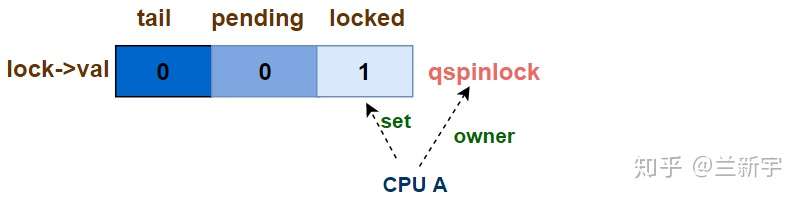
对应的代码实现是queued_spin_lock()的前半部分(位于/include/asm-generic/qspinlock.h):
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_VAL (1U << _Q_LOCKED_OFFSET)
void queued_spin_lock(struct qspinlock *lock)
{
// (0,0,0) --> (0,0,1)
u32 val = atomic_cmpxchg_acquire(&lock->val, 0, _Q_LOCKED_VAL);
if (likely(val == 0))
return;
queued_spin_lock_slowpath(lock, val);
}
通过"cmpxchg()",和当前lock的"val"值进行比较,看是否为0,如果为0,那么获得spinlock,同时将lock的值设为1(即_Q_LOCKED_VAL)。
第二个CPU试图获取锁 - pending
在第一个CPU未释放锁之前,如果有第二个CPU试图获取锁,那么它必须等待,因而其获取锁的过程被称为"slow path",对应的代码实现是queued_spin_lock_slowpath()中的[part 1](该函数的完整实现在源代码中超过200行,本文是做了适当简化,并拆成几个部分来分开讲解)。
#define _Q_LOCKED_OFFSET 0
#define _Q_LOCKED_BITS 8
#define _Q_LOCKED_MASK ((1U << _Q_LOCKED_BITS) - 1) << _Q_LOCKED__OFFSET // (*,*,1)
// "val"是在queued_spin_lock中获取的当前lock的值
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
[part 2 - 第三个CPU试图获取spinlock]
...
goto queue; // 跳转到part 3
...
[part 1 - 第二个CPU试图获取spinlock]
// 设置pending位 (0,0,1) --> (0,1,1)
val = queued_fetch_set_pending_acquire(lock);
// 等待第一个CPU移交
if (val & _Q_LOCKED_MASK)
atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));
// 第二个CPU成功获取spinlock (0,1,0) --> (0,0,1)
clear_pending_set_locked(lock);
return;
[part 3 - 进入MCS lock队列]
queue:
...
[part 4 - 第三个CPU成功获取spinlock]
locked:
...
}
它首先通过queued_fetch_set_pending_acquire()函数设置"pending"为1,然后调用atomic_cond_read_acquire()函数,开始基于"locked byte"进行等待(或者说"spin"),此时三元组的值变为(0, 1, 1)。
像atomic_cond_read_acquire()这种函数,其实就是Linux中的原子操作这篇文章介绍的atomic_read()加上"cond"和"acquire",其中"cond"代表condition,表示spin基于的对象,而"acquire"用于设置Memory Barrier。这是为了保证应该在获取spinlock之后才能执行的代码,不要因为Memory Order的调换,在成功获取spinlock之前就执行了,那样就失去了保护Critical Section/Region的目的。
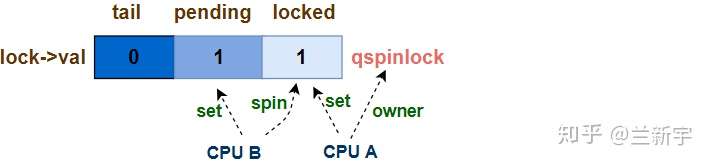
这第二个CPU可被视作是该spinlock的第一顺位继承人,可以做一个这样的类比:"locked byte"位域相当于是皇宫,而"pending"位域相当于是东宫,第二个CPU就是太子(假设按照立长的原则,先来后到),设置"pending"为1就相当于入主东宫,等待着继承大统。
皇帝大行之后(第一个CPU释放spinlock),皇位暂时空缺,三元组的的值变为(0, 1, 0)。之后,曾经的太子离开居住的东宫(将"pending"置0),进入皇宫,成为其新的主人(将"locked byte"置1)。这一过程对应的函数实现就是clear_pending_set_locked()。
第三个CPU试图获取锁 - uncontended queue
如果第二个CPU还在等待的时候,第三个CPU又来了,那么这第三个CPU就成了第二顺位继承人。它的等待路径的实现位于queued_spin_lock_slowpath()的[part 2]:
#define _Q_PENDING_OFFSET 8
#define _Q_PENDING_VAL (1U << _Q_PENDING_OFFSET) // (0,1,0)
[part 2A]
// (0,1,0)是spinlock移交的过渡状态
if (val == _Q_PENDING_VAL) {
// 等待移交完成 (0,1,0) --> (0,0,1)
int cnt = 1
val = atomic_cond_read_relaxed(&lock->val, (VAL != _Q_PENDING_VAL)|| !cnt--);
}
[part 2B]
// 已经有2个及以上的CPU持有或试图获取spinlock
if (val & ~_Q_LOCKED_MASK)
goto queue; // 进入MCS node队列
皇宫只有一个,东宫也只有一个,对于第二顺位继承人的王子来说,只能先去宫城外面自建府邸了。对应代码的实现就是[part 2B]的"goto queue",创建一个MCS node。
但前面提到,三元组的值为(0, 1, 0)时(即_Q_PENDING_VAL),是一个「政权移交」的过渡状态,此时第一顺位继承人即将成为spinlock新的持有者,那么作为第二顺位继承人,也即将递进成为第一顺位继承人,所以如果遇到了这个特殊时期,这第三个CPU会选择使用atomic_cond_read_relaxed()函数,先稍微等一会儿(即[part 2A]部分的代码)。
如果在它第二次读取"lock->val"的值时,已经不再是(0, 1, 0),说明移交已完成,变成了(0, 0, 1),那么它将绕过[part 2B],执行[part 1]的代码(也就是第二个CPU曾经走过的路)。
进入MCS node队列
(0, 1, 0)的状态毕竟是特例,大部分情况下,代码还是会跳转到名为"queue"的label位置,开始在MCS lock队列中的活动,对应的代码实现是queued_spin_lock_slowpath()的[part 3]。
首先是从前面提到的per-CPU的qnode[]数组中获取对应的MCS node,并初始化这个node,其中"idx"即表示context编号的"tail index"。
queue:
[part 3A]
struct mcs_spinlock *node = this_cpu_ptr(&qnodes[0].mcs);
int idx = node->count++;
node += idx;
node->locked = 0;
node->next = NULL;
然后是调用encode_tail()将自己的CPU编号和context编号「揉」进"tail"里,并通过xchg_tail()让qspinlock(即"lock")的"tail"指向自己。前面提到,"tail CPU"是CPU的编号加1,因为对于编号为0,tail index也为0的CPU,如果不加1,那么算出来的"tail"值就是0,而"tail"为0表示当前没有MCS node的队列。
[part 3B]
u32 tail = encode_tail(smp_processor_id(), idx);
// (p,1,1) -> (n,1,1)
u32 old = xchg_tail(lock, tail);
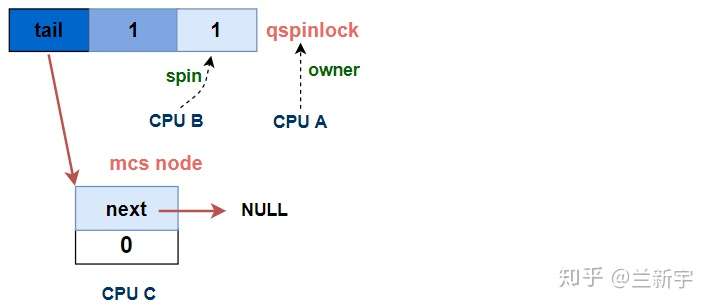
这里没有画出CPU C是基于哪个对象进行spin的,接下来的一节会给出答案。
第N个CPU试图获取锁 - contended queue
xchg_tail()除了在qspinlock中设置新的tail值,还返回了qspinlock中之前存储的tail值(即"old")。对于第N个(N > 3)试图获取spinlock的CPU,之前的tail值是指向上一个MCS node的,获得上一个node的目的是让它的"next"指向自己,这样才能加入MCS node的等待队列。
struct mcs_spinlock *prev, *next, *node;
[part 3C]
// 如果MCS node队列不为空 - 第N个CPU
if (old & _Q_TAIL_MASK) {
// 解析tail值,获取上一个MCS node
prev = decode_tail(old);
// 让上一个node指向自己,加入等待队列
WRITE_ONCE(prev->next, node); // prev->next = node
// 基于自己的locked值进行spin,在[part 4]中解除
arch_mcs_spin_lock_contended(&node->locked);
}
[part 3D]
#define _Q_LOCKED_PENDING_MASK (_Q_LOCKED_MASK | _Q_PENDING_MASK)
// 自己是MCS node队列的第一个节点 - 第二顺位继承
val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));
加入MCS node组成的队列后,这第N个CPU会基于自己node的"locked"进行spin,这就完全回到了上文描述的MCS lock的路径里了。
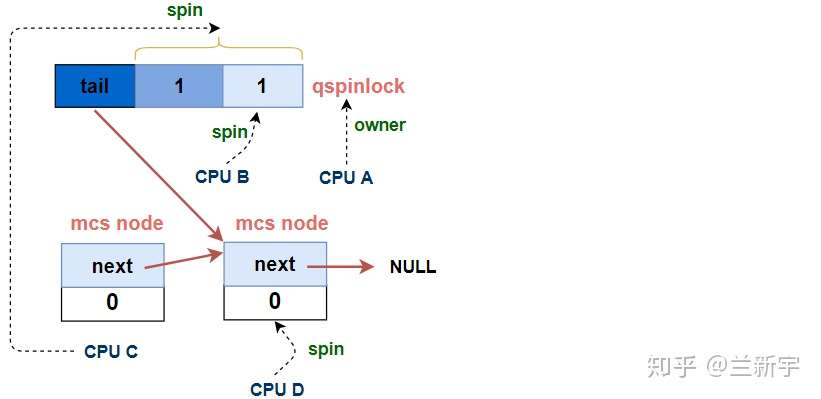
[part 3D]中的这个atomic_cond_read_acquire()函数,在本文已经是第二次出现了,上一次是在[part 1]里,所不同的是,[part 1]里是第二个CPU(第一顺位继承人,CPU B)基于代表「大位」的qspinlock的"locked byte"进行spin,而这里是第三个CPU(第二顺位继承人,CPU C)基于qspinlock的"locked byte"加上代表「嗣位」的"pending"进行spin。
也就是说,当第一顺位继承人获得spinlock,空出嗣位后,如果第二顺位继承人已经建立了MCS node,那它并不会马上占据嗣位,而是要等到CPU B也释放了spinlock,"locked byte"和"pending"都为0时,才直接获取spinlock。
[part 3D]是放在第N个CPU试图获取spinlock的代码位置之后的,说明第N个CPU在解除基于自己node的"locked"的spin之后,也会执行这段代码,原因在接下来介绍完[part 4]的代码之后,将会自然地浮出水面。
第三个CPU成功获取锁
经过等待,当qspinlock的"locked byte"和"pending"都变为0时,第三个CPU总算熬出头了,它终于可以结束spin,获取这个spinlock。
[part 4]
locked:
// 唯一node, 直接获取锁 (n,0,0) --> (0,0,1)
if (((val & _Q_TAIL_MASK) == tail) &&
atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))
goto release;
// 如果MSC node队列中还有其他node (n,0,0) --> (n,0,1)
set_locked(lock);
// 解除下一个node在MCS node队列中的spin
arch_mcs_spin_unlock_contended(&node->next->locked);
release:
__this_cpu_dec(mcs_nodes[0].count);
如果qspinlock的"tail"是指向自己的,说明它是当前MCS node队列中唯一的node,那么直接通过atomic_try_cmpxchg_relaxed()获取spinlock即可,三元组的值变为(0, 0, 1)。
如果不是,说明队列中还有其他的node在等待,那么按照上文描述的MCS node队列的规则,需要调用arch_mcs_spin_unlock_contended()函数,设置下一个node(CPU D)的"locked"为1。
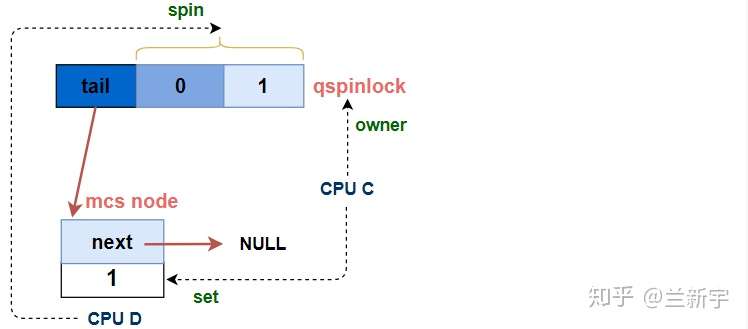
当CPU C获取spinlock,离开MCS node队列后,CPU D就成为了MCS node队列中的第一个node,它的"locked"也被CPU C设为了1。在上文描述的MCS lock实现中,"locked"为1就意味着spinlock被上一个owner递交给了自己。但在这里,"locked"为1只是结束了在MCS node队列中的的spin。
结束在MCS node队列中的的spin后,意味着CPU D在前面[part 3C]中的等待就结束了,它将执行[part 3D]的代码,切换为第二顺位继承人进行spin应该基于的对象,即qspinlock的"locked byte"加上"pending"(和之前的CPU C一样)。
可见,对于第N个(N > 3)CPU来说,从它加入MCS node等待队列,到最终成功获取spinlock,其spin基于的对象并不是从一而终的,在到达队首之前都是基于自己的node进行spin,到达队首后则是基于qspinlock进行spin。
- 解锁
相比起加锁,解锁的过程看起来简直简单地不像话:
void queued_spin_unlock(struct qspinlock *lock)
{
smp_store_release(&lock->locked, 0);
}
只需要把qspinlock中的"locked byte"置为0就可以了。这也不难理解,后面一直有CPU「盯」着呢,一旦大位空缺,马上就有人补齐,您只需要乖乖地把位子腾出来就行。
到这里,qspinlock加锁和解锁的过程就介绍完了,可以借助下面这张图片来一览它的全貌:

从中可以看出各种状态下CPU进行spin时基于的对象,以及状态之间的变化和迁移。
【总结与思考】
回过头来看一下qspinlock的组成和实现:如果只有1个或2个CPU试图获取锁,那么只需要一个4字节的qspinlock就可以了,其所占内存的大小和ticket spinlock一样。当有3个以上的CPU试图获取锁,需要一个qspinlock加上(N-2)个MCS node。
对于设计合理的spinlock,在大多数情况下,锁的争抢都不应该太激烈,最大概率是只有1个CPU试图获得锁,其次是2个,并依次递减。
这也是qspinlock中加入"pending"位域的意义,如果是两个CPU试图获取锁,那么第二个CPU只需要简单地设置"pending"为1,而不用「另起炉灶」创建一个MCS node。这是除了体积减小外,qspinlock相较于MCS lock所做的第二层优化。
试图加锁的CPU数目超过3个是小概率事件,但一旦发生,使用ticket spinlock机制就会造成多个CPU的cache line无谓刷新的问题,而qspinlock可以利用MCS node队列来解决这个问题。
可见,使用qspinlock机制来实现spinlock,具有很好的可扩展性,也就是无论当前锁的争抢程度如何,性能都可以得到保证。所以在Linux中,如果针对某个处理器架构的代码没有单独定义,qspinlock将是spinlock默认的实现方式。
#define arch_spin_lock(l) queued_spin_lock(l)
作为SMP系统中的一个高频操作,spinlock的性能毫无疑问会影响到整个系统运行的性能,所以,从ticket spinlock到MCS lock,再到qspinlock,见证了内核开发者对其一步步的优化历程。在优秀的性能背后,是对每一行代码的反复推敲和考量,最终铸就了qspinlock精妙但并不简单的实现过程。也许,它还有优化的空间……
至此,对Linux中不同处理器架构可能采用的三种spinlock的实现方式的介绍就告一段落了,下文将开始介绍Linux中spinlock的具体使用方法。
内核Mutex
结构体
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t owner;
spinlock_t wait_lock;
struct list_head wait_list;
};
- owner:记录生命周期变化
- wait_lock:是一个自旋锁变量, 用于对wait_list的操作变为原子变量
- wait_list :用于管理那些在获取mutex的进程,在无法获取互斥锁的时候,进入wait_List睡眠。
简单地说就是一个spinlock搭配一个代表等待队列的双向链表"wait_list",外加一个记录mutex生命周期的状态变化的"owner"。没有线程持有mutex时,"owner"的值为0,有线程持有时,需将"owner"转换为指向该线程的"task_struct"的指针。由于"task_struct"指针是按"L1_CACHE_BYTES"的字节数对齐,因而其最低的3个bits被用来存储其他信息。
struct task_struct *__mutex_owner(struct mutex *lock)
{
return (struct task_struct *)(atomic_long_read(&lock->owner) & ~0x07);
}
在早期(2016年前)的mutex实现中,使用了一个单独的"count"来记录mutex的持有情况,为1表示空闲,0表示持有,负数表示有其他线程等待。后经Peter Zijlstra的重构,将"count"要表达的意义融入"owner"中,并使用第三位的1个bit(MUTEX_FLAG_WAITERS)来表示有线程等待
mutex加锁
一个线程试图获取mutex的函数是mutex_lock_interruptible(),它的前身是mutex_lock(),但由于mutex_lock()不能被信号打断,因而已经基本被废弃不用了。由于mutex可能睡眠,所以不能在中断上下文中使用,也就不存在和ISR共享变量造成死锁的问题,因而也就没有像spinlock那样的防止hardirq/softirq抢占的函数。
int __sched mutex_lock_interruptible(struct mutex *lock)
{
might_sleep();
/* fast path */
if (__mutex_trylock_fast(lock))
return 0;
/* slow path */
return __mutex_lock_interruptible_slowpath(lock);
}
might_sleep()实际上什么也不做,它只是对编程人员的一种提示,表明可能导致睡眠。如果现在没有其他线程持有mutex,那么调用这个函数的线程可立即获得mutex,即"fast path"
bool __mutex_trylock_fast(struct mutex *lock)
{
...
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr))
return true;
return false;
}
就是一个简单的原子操作,把"owner"设为自己即可。
如果这个mutex正在被其他线程持有(设为线程A,对应下图CPU 0),按理该线程(设为线程B,对应下图CPU 1)应该进入"wait_list"的等待队列上,即"slow path"。
但是进入slow path,等mutex可用后再被唤醒,将发生两次上下文切换,开销较大,所以线程B不甘心,它还要做一番挣扎。从乐观的角度想:线程A现在临界区,临界区的代码通常都是比较简短的,如果它不进入睡眠的话,那么大概率可以很快退出临界区,把mutex释放出来。在这段时间里,我就像spinlock一样spin等待,这样的代价肯定比进入slow path小。
这种介于fast path和slow path之间的代码路径被称为"mid path",也叫optimistic spinning(乐观锁),此时线程依然处于"TASK_RUNNING"的状态。以这种方式等待的线程可以叫做"spinner",使用它需要配置内核选项"CONFIG_MUTEX_SPIN_ON_OWNER"。
假设现在又来了一个试图获取这个mutex的线程(设为线程C,对应上图CPU 2),即便前面还有个CPU 1等着,它也会往好的一方面想:等mutex交到CPU 1手里,CPU 1在临界区内不睡眠的话,也会很快执行完啊。这就有点过分乐观了,如果spinner数目比较多的话,那排在后面的spinner会白白消耗不少CPU资源。
接下来,线程A退出临界区并释放mutex,线程B获取mutex后进入自己的临界区。如果线程B在执行临界区代码时被抢占了,那么线程C就只好自认倒霉,进入slow path,按照先来后到的顺序(FIFO)添加到"wait_list"上排队,并调用schedule()让出CPU,状态变更为"TASK_INTERRUPTIBLE"。使用这种方式等待的线程可以叫做"waiter"。
那spinner是如何知道持有mutex的线程被抢占了呢?它依靠的是这个"owner"线程的"task_struct"中的"on_cpu",如果"on_cpu"为0,说明该线程没有在原来的CPU上执行。
处在mid path中的线程,对mutex的获取行为就像获取spinlock一样,此时的mutex具备了spinlock的语义,因而其等待的方式采用了一种结合MCS lock和qspinlock的实现,又根据mutex的语义量身裁剪过的osq lock。
struct optimistic_spin_node {
struct optimistic_spin_node *next, *prev;
int locked; /* 1 if lock acquired */
int cpu; /* encoded CPU # + 1 value */
};
struct optimistic_spin_queue {
/* Stores an encoded value of the CPU # of the tail node in the queue */
atomic_t tail;
};
mid path不是随便进的,必须满足当前CPU上没有更高优先级的线程要执行的条件(通过need_resched()判断)。
mutex_optimistic_spin(struct mutex *lock, struct mutex_waiter *waiter, ...)
{
if (!mutex_can_spin_on_owner(lock))
goto fail;
osq_lock(&lock->osq)
...
}
int mutex_can_spin_on_owner(struct mutex *lock)
{
if (need_resched())
return 0;
...
}
否则,就算进了mid path,也会被高优先级的线程抢占(如下图CPU 1所示),这和临界区内不能抢占/调度的spinlock是不同的。
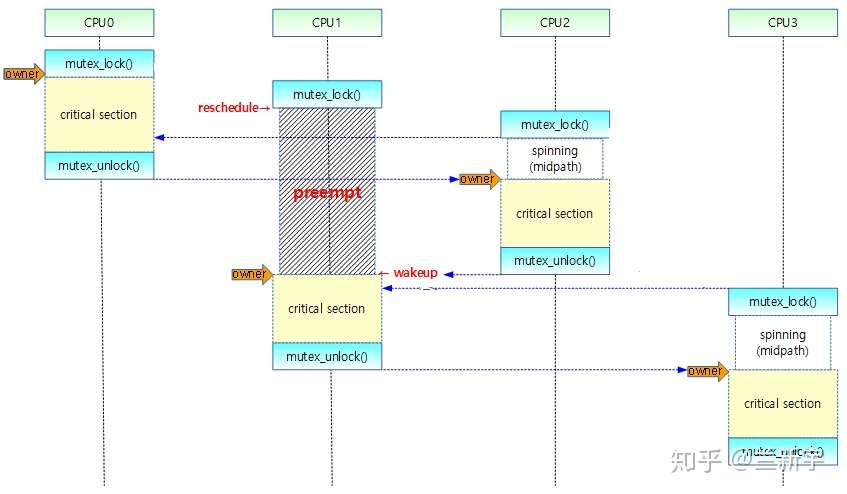
如果线程确实是进了mid path才被抢占的,那么需要从osq lock的等待队列中移除,添加到"wait_list"的slow path等待队列,身份从spinner变成了waiter。还有一种场景也会产生同样的结果,就是前面讲的spinner监测到owner线程进入了睡眠。
公平与效率
optimistic spinning机制虽然有助于提高mutex的使用效率,但同时也增加了相当的复杂性。维护的队列从1个变成了2个,而且它们之间还存在着转换。如果一个线程发现owner进入睡眠,那么只能以waiter的方式等待,之后owner结束睡眠,新来的线程就会以spinner的方式等待。
owner释放mutex后,因为spinner是处在运行态,cache也是“热”的,而waiter处在休眠态,cache大概率是“冷”的。从执行效率的角度讲,应该让spinner优先获取锁,可是这样对更早进入等待的waiter就不公平。
至此,mutex的加锁过程就介绍完了
mutex解锁
mutex同spinlock一样,必须由持有lock的线程来释放这个lock。如果当前没有其他线程在等待,那么"owner"的低3个bits为0,"owner"的值也就直接等于当前线程的"task_struct"指针的值,此时释放mutex要做的只是将"owner"的值设为0。
bool __mutex_unlock_fast(struct mutex *lock)
{
if (atomic_long_cmpxchg_release(&lock->owner, curr, 0UL) == curr)
return true;
...
}
如果有线程在等待,那么释放mutex时需要保留"owner"中作为标志位的低3个bits。
void __sched __mutex_unlock_slowpath(struct mutex *lock, ...)
{
// 释放mutex,同时获取记录状态的低3个bits
unsigned long old = atomic_long_cmpxchg_release(&lock->owner,
owner, __owner_flags(owner));
...
spin_lock(&lock->wait_lock);
if (!list_empty(&lock->wait_list)) {
// 获取等待队列中的第一个线程
struct mutex_waiter *waiter = list_first_entry
(&lock->wait_list, struct mutex_waiter, list);
// 将该线程加入wake_q
struct task_struct *next = waiter->task;
wake_q_add(&wake_q, next);
}
spin_unlock(&lock->wait_lock);
// 唤醒该线程
wake_up_q(&wake_q);
}
获取"wait_list"队列头部的等待线程,并调用wake_up_q()唤醒该线程。
【死锁问题】
Linux内核中的mutex同spinlock一样,也存在AB-BA的死锁问题。前面讨论spinlock的AB-BA死锁时曾讲到,在这个时候,如果其中一方能主动让出自己持有的锁,「僵局」就可以迎刃而解。
2013年,Marten Lankhorst基于传统的mutex开发了一种新的机制。如下图所示,当检测到死锁发生时,Task-2主动unlock(B),那么Task-1就可以继续往下执行,Task-1执行完后释放lock B和lock A,那么Task-2也可以继续往下执行。
这种机制被命名为"ww-mutex",其中"ww"代表wound-wait,可理解为是主动让出mutex的一方在“受伤地等待”,不过一方受伤总比双方都死掉好。ww-mutex需要能够识别mutex获取路径的依赖,并制定一套选择哪个线程作为让出一方的规则。
struct ww_mutex {
struct mutex base;
struct ww_acquire_ctx *ctx;
};
此外,ww-mutex还支持按stamp,而不是FIFO的顺序选择等待队列中的waiter。这样可以避免上文所说的“较晚进入等待的spinner先于较早进入等待的waiter获得mutex”的情况,当一个线程发现有比它自己的stamp更早的waiter存在,它就不会成为spinner。
bool ww_mutex_spin_on_owner(...)
{
if (!waiter && (atomic_long_read(&lock->owner) & MUTEX_FLAG_WAITERS))
return false;
...
}
【spinlock和mutex】
Linux中的spinlock和mutex机制都介绍完了,下面通过对比来说明两者分别适合于什么样的应用场景。
spinlock的开销在于暂时获取不到锁时,对所在CPU的持续占有,而传统的mutex的开销则在于释放CPU和重新获取CPU所带来的上下文切换。不过,现在的mutex设计已经通过optimistic spinning糅合了spinlock的行为,在资源不足时是否主动让出CPU已经不再构成两者真正的区别。
两者语义上的差异(或者说spinlock和mutex能同时存在的原因)是在线程试图获取和持有spinlock期间,调度都是关闭的,因而要求临界区的执行时间必须较短。相比而言,使用mutex的限制条件更加宽松。如果支持的操作可能会导致睡眠,比如copy_from_user()或者kmalloc(GFP_KERNEL),则只能使用mutex。
多种锁机制
乐观锁
乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作。java中的乐观锁基本都是通过CAS操作实现的,CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。
悲观锁:
悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会block直到拿到锁。java中的悲观锁就是Synchronized,AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如RetreenLock。
自旋锁(CAS):
自旋锁就是让不满足条件的线程等待一段时间,而不是立即挂起。看持有锁的线程是否能够很快释放锁。怎么自旋呢?其实就是一段没有任何意义的循环。虽然它通过占用处理器的时间来避免线程切换带来的开销,但是如果持有锁的线程不能在很快释放锁,那么自旋的线程就会浪费处理器的资源,因为它不会做任何有意义的工作。所以,自旋等待的时间或者次数是有一个限度的,如果自旋超过了定义的时间仍然没有获取到锁,则该线程应该被挂起。JDK1.6中-XX:+UseSpinning开启; -XX:PreBlockSpin=10 为自旋次数; JDK1.7后,去掉此参数,由jvm控制;
偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成01(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。执行同步块。这个时候线程2也来访问同步块,也是会检查对象头的Mark Word里是否存储着当前线程2的偏向锁,发现不是,那么他会进入 CAS 替换,但是此时会替换失败,因为此时线程1已经替换了。替换失败则会进入撤销偏向锁,首先会去暂停拥有了偏向锁的线程1,进入无锁状态(01).偏向锁存在竞争的情况下就回去升级成轻量级锁。
- 开启:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0 -client -Xmx1024m -Xms1024m
- 关闭:-XX:+UseBiasedLocking -client -Xmx512m -Xms512m
轻量级锁及源码:
引入轻量级锁的主要目的是在多没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。这个时候 JVM会尝试使用 CAS 将 mark Word 更新为指向栈帧中的锁记录(Lock Record)的空间指针。并且把锁标志位设置为 00(轻量级锁标志),与此同时如果有另外一个线程2也来进行 CAS 修改 Mark Word,那么将会失败,因为线程1已经获取到该锁,然后线程2将会进行 CAS操作不断的去尝试获取锁,这个时候将会引起锁膨胀,就会升级为重量级锁,设置标志位为 10.
由轻量锁切换到重量锁,是发生在轻量锁释放锁的期间,之前在获取锁的时候它拷贝了锁对象头的markword,在释放锁的时候如果它发现在它持有锁的期间有其他线程来尝试获取锁了,并且该线程对markword做了修改,两者比对发现不一致,则切换到重量锁。轻量级解锁时,会使用原子的CAS操作来将Displaced Mark Word替换回到对象头,如果成功,则表示同步过程已完成。如果失败,表示有其他线程尝试过获取该锁,则要在释放锁的同时唤醒被挂起的线程进入等待。
重量级锁
重量级锁通过对象内部的监视器(monitor)实现,其中monitor的本质是依赖于底层操作系统的Mutex Lock实现,操作系统实现线程之间的切换需要从用户态到内核态的切换,切换成本非常高。主要是,当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。这就是说为什么重量级线程开销很大的。
monitor这个对象,在hotspot虚拟机中,通过ObjectMonitor类来实现 monitor。他的锁的获取过程的体现会简单很多。每个object的对象里 markOop->monitor() 里可以保存ObjectMonitor的对象。

这里提到的 CXQ跟 EnterList 是什么呢? 见下图:

这里我们重新回到 objectMonitor.cpp 这个源码中来看以下:
void ATTR ObjectMonitor::enter(TRAPS) {//获取重量级锁的过程
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;//进行CAS自旋操作
if (cur == NULL) {
// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
// CONSIDER: set or assert OwnerIsThread == 1
return ;
}
//自旋结果相等,则重入(重入的原理)
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}//接下去就是有并发的情况下竞争的过程了
....
Synchronized
反编译修饰代码块
反编译一下syn的java代码
/**
* ...
**/
public void testSyn();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter //申请获得对象的内置锁
4: aload_1
5: monitorexit //释放对象内置锁
6: goto 14
9: astore_2
10: aload_1
11: monitorexit //释放对象内置锁
12: aload_2
13: athrow
14: return
重量级锁(ObjectMonitor)获取
void ATTR ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD ;
void * cur ;
//通过CAS操作尝试把monitor的_owner字段设置为当前线程
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
//获取锁失败
if (cur == NULL) {
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
return ;
}
//如果之前的_owner指向该THREAD,那么该线程是重入,_recursions++
if (cur == Self) {
_recursions ++ ;
return ;
}
//如果当前线程是第一次进入该monitor,设置_recursions为1,_owner为当前线程
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ; //_recursions标记为1
_owner = Self ; //设置owner
OwnerIsThread = 1 ;
return ;
}
/**
*此处省略锁的自旋优化等操作,统一放在后面synchronzied优化中说
**/
总结:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的owner
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权
反编译修饰方法
/**
* ...
**/
public synchronized void testSyn();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 3: 0
结果和synchronized修饰代码块的情况不同,仔细比较会发现多了ACC_SYNCHRONIZED这个标识,test.java通过javac编译形成的test.class文件,在该文件中包含了testSyn方法的方法表,其中ACC_SYNCHRONIZED标志位是1,当线程执行方法的时候会检查该标志位,如果为1,就自动的在该方法前后添加monitorenter和monitorexit指令,可以称为monitor指令的隐式调用。
上面所介绍的通过synchronzied实现同步用到了对象的内置锁(ObjectMonitor),而在ObjectMonitor的函数调用中会涉及到Mutex lock等特权指令,那么这个时候就存在操作系统用户态和核心态的转换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,这也是为什么早期的synchronized效率低的原因。在jdk1.6之后,从jvm层面做了很大的优化,下面主要介绍做了哪些优化。
锁优化
在了解了synchronized重量级锁效率特别低之后,jdk自然做了一些优化,出现了偏向锁,轻量级锁,重量级锁,自旋等优化,我们应该改正monitorenter指令就是获取对象重量级锁的错误认识,很显然,优化之后,锁的获取判断次序是偏向锁->轻量级锁->重量级锁。
偏向锁源码
//偏向锁入口
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
//UseBiasedLocking判断是否开启偏向锁
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
//获取偏向锁的函数调用
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
}
//不能偏向,就获取轻量级锁
slow_enter (obj, lock, THREAD) ;
}
BiasedLocking::revoke_and_rebias调用过程如下流程图:
偏向锁的撤销过程如下:
轻量级锁获取源码
//轻量级锁入口
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark(); //获得Mark Word
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
//是否无锁不可偏向,标志001
if (mark->is_neutral()) {
//图A步骤1
lock->set_displaced_header(mark);
//图A步骤2
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) { //如果Mark Word指向本地栈帧,线程重入
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);//header设置为null
return;
}
lock->set_displace
d_header(markOopDesc::unused_mark());
//轻量级锁膨胀,膨胀完成之后尝试获取重量级锁
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
轻量级锁获取流程如下:
轻量级锁撤销源码:
void ObjectSynchronizer::fast_exit(oop object, BasicLock* lock, TRAPS) {
assert(!object->mark()->has_bias_pattern(), "should not see bias pattern here");
markOop dhw = lock->displaced_header();
markOop mark ;
if (dhw == NULL) {//如果header为null,说明这是线程重入的栈帧,直接返回,不用回写
mark = object->mark() ;
assert (!mark->is_neutral(), "invariant") ;
if (mark->has_locker() && mark != markOopDesc::INFLATING()) {
assert(THREAD->is_lock_owned((address)mark->locker()), "invariant") ;
}
if (mark->has_monitor()) {
ObjectMonitor * m = mark->monitor() ;
}
return ;
}
mark = object->mark() ;
if (mark == (markOop) lock) {
assert (dhw->is_neutral(), "invariant") ;
//CAS将Mark Word内容写回
if ((markOop) Atomic::cmpxchg_ptr (dhw, object->mark_addr(), mark) == mark) {
TEVENT (fast_exit: release stacklock) ;
return;
}
}
//CAS操作失败,轻量级锁膨胀,为什么在撤销锁的时候会有失败的可能?
ObjectSynchronizer::inflate(THREAD, object)->exit (THREAD) ;
}
轻量级锁撤销流程如下:
轻量级锁膨胀源码
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
assert (Universe::verify_in_progress() ||
!SafepointSynchronize::is_at_safepoint(), "invariant") ;
for (;;) { // 为后面的continue操作提供自旋
const markOop mark = object->mark() ; //获得Mark Word结构
assert (!mark->has_bias_pattern(), "invariant") ;
//Mark Word可能有以下几种状态:
// * Inflated(膨胀完成) - just return
// * Stack-locked(轻量级锁) - coerce it to inflated
// * INFLATING(膨胀中) - busy wait for conversion to complete
// * Neutral(无锁) - aggressively inflate the object.
// * BIASED(偏向锁) - Illegal. We should never see this
if (mark->has_monitor()) {//判断是否是重量级锁
ObjectMonitor * inf = mark->monitor() ;
assert (inf->header()->is_neutral(), "invariant");
assert (inf->object() == object, "invariant") ;
assert (ObjectSynchronizer::verify_objmon_isinpool(inf), "monitor is invalid");
//Mark->has_monitor()为true,说明已经是重量级锁了,膨胀过程已经完成,返回
return inf ;
}
if (mark == markOopDesc::INFLATING()) { //判断是否在膨胀
TEVENT (Inflate: spin while INFLATING) ;
ReadStableMark(object) ;
continue ; //如果正在膨胀,自旋等待膨胀完成
}
if (mark->has_locker()) { //如果当前是轻量级锁
ObjectMonitor * m = omAlloc (Self) ;//返回一个对象的内置ObjectMonitor对象
m->Recycle();
m->_Responsible = NULL ;
m->OwnerIsThread = 0 ;
m->_recursions = 0 ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ;//设置自旋获取重量级锁的次数
//CAS操作标识Mark Word正在膨胀
markOop cmp = (markOop) Atomic::cmpxchg_ptr (markOopDesc::INFLATING(), object->mark_addr(), mark) ;
if (cmp != mark) {
omRelease (Self, m, true) ;
continue ; //如果上述CAS操作失败,自旋等待膨胀完成
}
m->set_header(dmw) ;
m->set_owner(mark->locker());//设置ObjectMonitor的_owner为拥有对象轻量级锁的线程,而不是当前正在inflate的线程
m->set_object(object);
/**
*省略了部分代码
**/
return m ;
}
}
}
轻量级锁膨胀流程图:
现在来回答下之前提出的问题:为什么在撤销轻量级锁的时候会有失败的可能?
假设thread1拥有了轻量级锁,Mark Word指向thread1栈帧,thread2请求锁的时候,就会膨胀初始化ObjectMonitor对象,将Mark Word更新为指向ObjectMonitor的指针,那么在thread1退出的时候,CAS操作会失败,因为Mark Word不再指向thread1的栈帧,这个时候thread1自旋等待infalte完毕,执行重量级锁的退出操作
重量级锁获取入口
void ATTR ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD ;
void * cur ;
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
return ;
}
if (cur == Self) {
_recursions ++ ;
return ;
}
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// Commute owner from a thread-specific on-stack BasicLockObject address to
// a full-fledged "Thread *".
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
/**
*上述部分在前面已经分析过,不再累述
**/
Self->_Stalled = intptr_t(this) ;
//TrySpin是一个自旋获取锁的操作,此处就不列出源码了
if (Knob_SpinEarly && TrySpin (Self) > 0) {
Self->_Stalled = 0 ;
return ;
}
/*
*省略部分代码
*/
for (;;) {
EnterI (THREAD) ;
/**
*省略了部分代码
**/
}
}
进入EnterI (TRAPS)方法
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
if (TryLock (Self) > 0) {
//这下不自旋了,我就默默的TryLock一下
return ;
}
DeferredInitialize () ;
//此处又有自旋获取锁的操作
if (TrySpin (Self) > 0) {
return ;
}
/**
*到此,自旋终于全失败了,要入队挂起了
**/
ObjectWaiter node(Self) ; //将Thread封装成ObjectWaiter结点
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
ObjectWaiter * nxt ;
for (;;) { //循环,保证将node插入队列
node._next = nxt = _cxq ;//将node插入到_cxq队列的首部
//CAS修改_cxq指向node
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
if (TryLock (Self) > 0) {//我再默默的TryLock一下,真的是不想挂起呀!
return ;
}
}
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
// Try to assume the role of responsible thread for the monitor.
// CONSIDER: ST vs CAS vs { if (Responsible==null) Responsible=Self }
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
TEVENT (Inflated enter - Contention) ;
int nWakeups = 0 ;
int RecheckInterval = 1 ;
for (;;) {
if (TryLock (Self) > 0) break ;//临死之前,我再TryLock下
if ((SyncFlags & 2) && _Responsible == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
if (_Responsible == Self || (SyncFlags & 1)) {
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ; //终于挂起了
}
if (TryLock(Self) > 0) break ;
/**
*后面代码省略
**/
}
try了那么多次lock,接下来看下TryLock:
int ObjectMonitor::TryLock (Thread * Self) {
for (;;) {
void * own = _owner ;
if (own != NULL) return 0 ;//如果有线程还拥有着重量级锁,退出
//CAS操作将_owner修改为当前线程,操作成功return>0
if (Atomic::cmpxchg_ptr (Self, &_owner, NULL) == NULL) {
return 1 ;
}
//CAS更新失败return<0
if (true) return -1 ;
}
}
重量级锁获取入口流程图:
重量级锁的出口:
void ATTR ObjectMonitor::exit(TRAPS) {
Thread * Self = THREAD ;
if (THREAD != _owner) {
if (THREAD->is_lock_owned((address) _owner)) {
_owner = THREAD ;
_recursions = 0 ;
OwnerIsThread = 1 ;
} else {
TEVENT (Exit - Throw IMSX) ;
if (false) {
THROW(vmSymbols::java_lang_IllegalMonitorStateException());
}
return;
}
}
if (_recursions != 0) {
_recursions--; // 如果_recursions次数不为0.自减
TEVENT (Inflated exit - recursive) ;
return ;
}
if ((SyncFlags & 4) == 0) {
_Responsible = NULL ;
}
for (;;) {
if (Knob_ExitPolicy == 0) {
OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lock
OrderAccess::storeload() ;
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
TEVENT (Inflated exit - complex egress) ;
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
return ;
}
TEVENT (Exit - Reacquired) ;
} else {
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::storeload() ;
if (_cxq == NULL || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
TEVENT (Inflated exit - reacquired succeeded) ;
return ;
}
TEVENT (Inflated exit - reacquired failed) ;
} else {
TEVENT (Inflated exit - complex egress) ;
}
}
ObjectWaiter * w = NULL ;
int QMode = Knob_QMode ;
if (QMode == 2 && _cxq != NULL) {
/**
*模式2:cxq队列的优先权大于EntryList,直接从cxq队列中取出一个线程结点,准备唤醒
**/
w = _cxq ;
ExitEpilog (Self, w) ;
return ;
}
if (QMode == 3 && _cxq != NULL) {
/**
*模式3:将cxq队列插入到_EntryList尾部
**/
w = _cxq ;
for (;;) {
//CAS操作取出cxq队列首结点
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ; //更新w,自旋
}
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ; //改变ObjectWaiter状态
//下面两句为cxq队列反向构造一条链,即将cxq变成双向链表
p->_prev = q ;
q = p ;
}
ObjectWaiter * Tail ;
//获得_EntryList尾结点
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;//_EntryList为空,_EntryList=w
} else {
//将w插入_EntryList队列尾部
Tail->_next = w ;
w->_prev = Tail ;
}
}
if (QMode == 4 && _cxq != NULL) {
/**
*模式四:将cxq队列插入到_EntryList头部
**/
w = _cxq ;
for (;;) {
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
if (_EntryList != NULL) {
//q为cxq队列最后一个结点
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
}
w = _EntryList ;
if (w != NULL) {
ExitEpilog (Self, w) ;//从_EntryList中唤醒线程
return ;
}
w = _cxq ;
if (w == NULL) continue ; //如果_cxq和_EntryList队列都为空,自旋
for (;;) {
//自旋再获得cxq首结点
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
/**
*下面执行的是:cxq不为空,_EntryList为空的情况
**/
if (QMode == 1) {//结合前面的代码,如果QMode == 1,_EntryList不为空,直接从_EntryList中唤醒线程
// QMode == 1 : drain cxq to EntryList, reversing order
// We also reverse the order of the list.
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant") ;
t->TState = ObjectWaiter::TS_ENTER ;
//下面的操作是双向链表的倒置
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
_EntryList = s ;//_EntryList为倒置后的cxq队列
} else {
// QMode == 0 or QMode == 2
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
//构造成双向的
p->_prev = q ;
q = p ;
}
}
if (_succ != NULL) continue;
w = _EntryList ;
if (w != NULL) {
ExitEpilog (Self, w) ; //从_EntryList中唤醒线程
return ;
}
}
}
ExitEpilog用来唤醒线程,代码如下:
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {
assert (_owner == Self, "invariant") ;
_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;
ParkEvent * Trigger = Wakee->_event ;
Wakee = NULL ;
OrderAccess::release_store_ptr (&_owner, NULL) ;
OrderAccess::fence() ;
if (SafepointSynchronize::do_call_back()) {
TEVENT (unpark before SAFEPOINT) ;
}
DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);
Trigger->unpark() ; //唤醒线程
// Maintain stats and report events to JVMTI
if (ObjectMonitor::_sync_Parks != NULL) {
ObjectMonitor::_sync_Parks->inc() ;
}
}
重量级锁出口流程图:
自旋
通过对源码的分析,发现多处存在自旋和tryLock操作,那么这些操作好不好,如果tryLock过少,大部分线程都会挂起,因为在拥有对象锁的线程释放锁后不能及时感知,导致用户态和核心态状态转换较多,效率低下,极限思维就是:没有自旋,所有线程挂起,如果tryLock过多,存在两个问题:1. 即使自旋避免了挂起,但是自旋的代价超过了挂起,得不偿失,那我还不如不要自旋了。 2. 如果自旋仍然不能避免大部分挂起的话,那就是又自旋又挂起,效率太低。极限思维就是:无限自旋,白白浪费了cpu资源,所以在代码中每个自旋和tryLock的插入应该都是经过测试后决定的。
编译期间锁优化
编译期间锁优化
锁消除
还是先看一下简洁的代码
public class test {
public String test(String s1,String s2) {
return s1+s2;
}
}
javac javap后:
public class test {
public test();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public java.lang.String test(java.lang.String, java.lang.String);
Code:
0: new #2 // class java/lang/StringBuilder
3: dup
4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V
7: aload_1
8: invokevirtual #4 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
11: aload_2
12: invokevirtual #4 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: invokevirtual #5 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
18: areturn
}
上述字节码等价成java代码为:
public class test {
public String test(String s1,String s2) {
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
}
sb的append方法是同步的,但是sb是在方法内部,每个运行的线程都会实例化一个StringBuilder对象,在私有栈持有该对象引用(其他线程无法得到),也就是说sb不存在多线程访问,那么在jvm运行期间,即时编译器就会将锁消除
锁粗化
将前面的代码稍微变一下:
public class test {
StringBuilder sb = new StringBuilder();
public String test(String s1,String s2) {
sb.append(s1);
sb.append(s2);
return sb.toString();
}
}
首先可以确定的是这段代码不能锁消除优化,因为sb是类的实例变量,会被多线程访问,存在线程安全问题,那么访问test方法的时候就会对sb对象,加锁,解锁,加锁,解锁,很显然这一过程将会大大降低效率,因此在即时编译的时候会进行锁粗化,在sb.appends(s1)之前加锁,在sb.append(s2)执行完后释放锁。
总结
引入偏向锁的目的:在只有单线程执行情况下,尽量减少不必要的轻量级锁执行路径,轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只依赖一次CAS原子指令置换ThreadID,之后只要判断线程ID为当前线程即可,偏向锁使用了一种等到竞争出现才释放锁的机制,消除偏向锁的开销还是蛮大的。如果同步资源或代码一直都是多线程访问的,那么消除偏向锁这一步骤对你来说就是多余的,可以通过-XX:-UseBiasedLocking=false来关闭
引入轻量级锁的目的:在多线程交替执行同步块的情况下,尽量避免重量级锁引起的性能消耗(用户态和核心态转换),但是如果多个线程在同一时刻进入临界区,会导致轻量级锁膨胀升级重量级锁,所以轻量级锁的出现并非是要替代重量级锁
重入:对于不同级别的锁都有重入策略,偏向锁:单线程独占,重入只用检查threadId等于该线程;轻量级锁:重入将栈帧中lock record的header设置为null,重入退出,只用弹出栈帧,直到最后一个重入退出CAS写回数据释放锁;重量级锁:重入_recursions++,重入退出_recursions--,_recursions=0时释放锁