表纪录操作
同样,表纪录也有增删改查的操作,但是一般我们大概70%的操作都是在查数据,所以查的操作需要单独说清楚,先简单看看增删改。
表纪录的增、删、改
1.增加一条纪录的方式:
insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......);
上一篇我们已经创建了一张员工表,现在简单一点,就留下名字和年龄信息,重新重建一张员工表:
create table emp_new( id int primary key auto_increment, name varchar(20) not null unique, birth varchar(20), salary float(7,2) );
创建好之后,我们开始增加数据,增加数据的方式有很多:
单条插入:
insert into emp_new (id,name,birth,salary) values (1,'pengfy','1993-01-01',20000); insert into emp_new values (2,'pyq','1992-12-12',10000); insert into emp_new(name,salary) values ('xiaojiang',3000);
单条插入的时候,我们可以和键一一对应的写进去,也可以不写键名(默认全部键)直接插入对应顺序的值,也可以指定键名写入对应的值,这里id设为自增,不用填写也会自己增加。
多条插入:
insert into emp_new values (4,'pyq1','1992-06-20',8000), (5,'pyq2','1994-06-20',9000);
现在我们已经插入了五条数据,可以通过select * from emp_new先看看有没有插入成功:
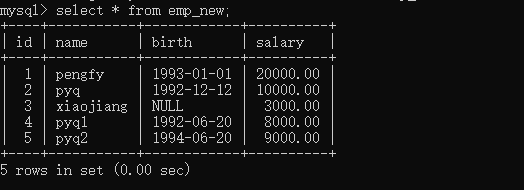
2.修改一条表纪录:
修改表记录 update tab_name set field1=value1,field2=value2,......[where 语句] /* UPDATE语法可以用新值更新原有表行中的各列。 SET子句指示要修改哪些列和要给予哪些值。 WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。*/
现在发现pyq的生日写错了,就可以通过where单独修改pyq的生日,pengfy 的工资也太低了,老板加了6000工资:
update emp_new set barth='1992-9-11'where id=2; #修改pyq的生日 update emp_new set salary=26000 where name='pengfy'; #修改pengfy的工资
现在看看有没有修改成功:
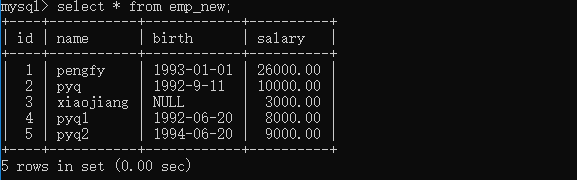
其实用set也可以增加一条纪录:
insert into emp_new set id=12,name="pyq3",salary=8800;
3.删除一条表纪录
delete from tab_name [where ....] /* 如果不跟where语句则删除整张表中的数据 delete只能用来删除一行记录 delete语句只能删除表中的内容,不能删除表本身,想要删除表,用drop TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在 事务中恢复。*/
删除表纪录也很简单,按照条件删除就行了:
我们先把最后set增加的名字为pyq3的删除掉:
delete from emp_new where name='pyq3';
也可以删除表中所有纪录,删除表中所有纪录有两种方法:
-- 删除表中所有记录。 delete from emp_new; -- 使用truncate删除表中记录。 truncate table emp_new;
那这二者的区别在哪里?一起看一下:





两份表的数据完全一样,唯一的区别在于delete删除是一条一条删除的,所以在第一张图里面可以看到5行被影响(5 rows affected,而truncate在删除的时候,是直接把整个表删除后再重新建一张名字一样的空表,所以在数据很大的时候,我们用右边的truncate去做删除表的动作,时间会更短。还有一点需要注意的是:之前设置id里的auto_increment没有被重置:alter table employee auto_increment=1;所以表中如果有数据三条,id分别为1,2,3,突然插入一个id=7,那么下次作为主键的字增长的id会从7开始增加。
表纪录之查(单表查询)
表查询表达式
SELECT *|field1,filed2 ... FROM tab_name WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数
我们重新创建一张表,是一张学校的成绩单,然后输入一些数据,有一个好习惯就是把sql命令都写成大写的,虽然sql不区分大小写,但这样可读性更强。
CREATE TABLE Result( id INT PRIMARY KEY auto_increment, name VARCHAR (20), Chinese DOUBLE , English DOUBLE , Math DOUBLE ); INSERT INTO Result VALUES (1,"pengfy",100,99,98), (2,"pyq",80,95,80), (3,"xiaojiang",43,59,22), (4,"pyq2",80,86,82), (5,"pyq3",82,90,90);
表单创建好之后,我们就开始查询了:
1.普通方式查询
select [distinct] *|field1,field2,...... from tab_name -- 其中from指定从哪张表筛选,*表示查找所有列,也可以指定一个列 -- 表明确指定要查找的列,distinct用来剔除重复行。
我们上面再增删改里面也说过一条select * from table_name,就是查询表中所有信息,就不用演示了。现在我们来查询所有学生的姓名和对应的英语成绩:
select name,english from result;
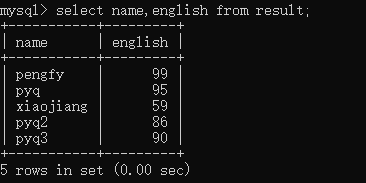
从图片看到,只显示了我们需要的名字和英语成绩,而且表头的名字大小写也和我们select命令中的显示一致。接下来我们再试一下过滤功能,我们插入两行和pengfy一样的内容,然后过滤一下:
insert into result values (6,'pengfy',100,99,98), (7,'pengfy',100,99,98);
select distinct chinese,name from result;

上面演示的是过滤掉了语文成绩和名字一样的信息,如果单独过滤语文成绩不一样的,那么80也会只保留从上往下的第一个,可以试一试。
2.表达式查询
select 也可以使用表达式,并且可以使用: 字段 as 别名或者:字段 别名
现在我要给每个学生的成绩加上10分,就可以这样写:
select name,chinese+10,english+10,math+10 from result;
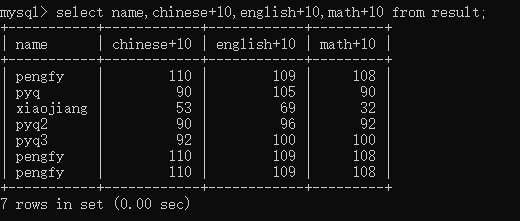
要注意的是,这仅仅是显示的给我们看的时候加上了10分,实际的成绩是没有变的,我们查看实际成绩还是select * from result。我们再看看学生的总分:
select name,chinese+english+math from result;

根据表达式所说的,我们可以使用别名来显示,比如我把name和chinese+english+math显示成中文:
select name as 姓名,chinese+english+math as 总成绩 from result;
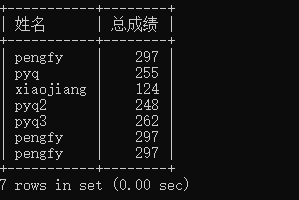
再次强调,我们改变的是我们查看的方式,并没有影响数据本身,否则那就不要查看,叫修改喽。还有需要注意的是记得在查找不容的内容之间加上逗号,你可以试试不加逗号是怎样的。
3.使用where子句,进行过滤查询
我们在修改表纪录的时候也简单使用了where子句,那这里同样可以,首先我们查一下名字是pengfy 的成绩:
select * from result where name='pengfy';

这就把名字为pengfy的成绩全找到了,当然,我们使用id或者成绩也可以找到,比如where Chinese=100,因为只有pengfy是10嘛,但我还是习惯用name,因为条件是找名字是pengfy的信息。除了这种,我们还可以做判断,比如找到英语成绩大于90分的人:
select name,english from result where english>90;
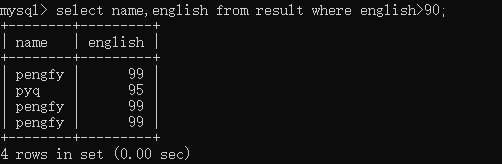
也可以配合上面的表达式使用, 比如找到总分大于260分的人,只显示名字和总分:
select name,chinese+english+math from result where chinese+english+math>260;
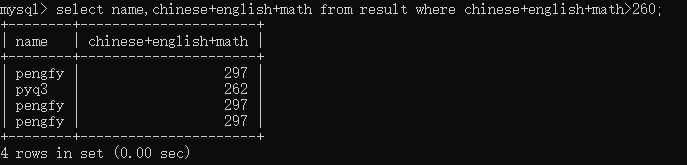
这时候你可能有疑问,为什么不把chinese+english+math换一个别名,然后where就不用写那么长一大串了,先告诉你这样会报错的,具体为什么,就是运行的优先级问题,后面再讲。除了这些,在where中还可以使用这些:
比较运算符: > < >= <= <> != between 80 and 100 值在10到20之间 in(80,90,100) 值是10或20或30 like 'pengfy%' /* pattern可以是%或者_, 如果是%则表示任意多字符,此例如唐僧,唐国强 如果是_则表示一个字符唐_,只有唐僧符合。两个_则表示两个字符:__ */ 逻辑运算符 在多个条件直接可以使用逻辑运算符 and or not
这里可能有点问题的是like,这里就举一个例子,现在要找到名字是p开头的所有信息:
select * from result where name like 'p%';
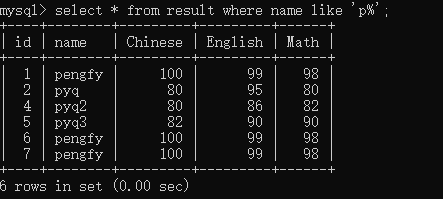
这里可以看到%可以代表任意长度的字符,但如果你要定长的字符,就要使用下划线_,比如要查找名字p开头且4个字节的所有信息:
select * from result where name like 'p___';

看着这个下划线有点长,其实是三个,一个就代表一个字符,加上p就一共4个字符。
4.Order by 指定排序的列
Order by 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名。 -- select *|field1,field2... from tab_name order by field [Asc|Desc] -- Asc 升序、Desc 降序,其中asc为默认值 ORDER BY 子句应位于SELECT语句的结尾。
除了上面的操作,我们在现实中遇到的情况也有很多是排序显示的,现在我们按语文成绩排序来显示:
select * from result order by chinese;

可以看到默认的是从小到大来显示的,如果要从大到小,只需要在最后加上一个desc即可:
select * from result order by chinese desc;
我们再按总成绩排个名看看,在这之前先加入一个插班生lily,Lily这个时候还没有考试,所以还没有成绩:
insert into result (id,name) values (8,'lily'); select name,chinese+english+math as 总成绩 from result order by 总成绩 desc;

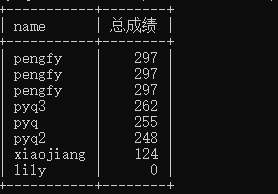
细心的朋友就发现了,怎么这里就可以弄个别名放在order后面用呢,where确不可以,还是优先级的事。不过这里先看一个问题,Lily是没有成绩的,但成绩应该是一个数字,放一个null算怎么回事,怎么办?在排序前先做一个判断,看是不是空,是空就变为0:
select name,(ifnull(chinese,0)+ifnull(english,0)+ifnull(math,0)) as 总成绩 from result order by 总成绩 desc;
这还没完,如果我只要名字p开头的总成绩排名怎么办?怎么放置where和order呢?
select name,(ifnull(chinese,0)+ifnull(english,0)+ifnull(math,0)) as 总成绩 -> from result where name like 'p%' -> order by 总成绩 desc;
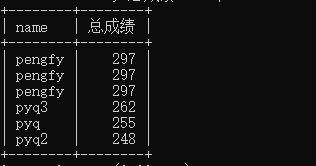
搞定了,order放在后边。查询的方式可不止这些,下一篇继续查看表单的其他方式。