布尔查询

布尔查询是最常用的组合查询,不仅将多个查询条件组合在一起,并且将查询的结果和结果的评分组合在一起。当查询条件是多个表达式的组合时,布尔查询非常有用,实际上,布尔查询把多个子查询组合(combine)成一个布尔表达式,所有子查询之间的逻辑关系是与(and);只有当一个文档满足布尔查询中的所有子查询条件时,ElasticSearch引擎才认为该文档满足查询条件。布尔查询支持的子查询类型共有四种,分别是:must,should,must_not和filter:
- must子句:文档必须匹配must查询条件;
- should子句:文档应该匹配should子句查询的一个或多个;
- must_not子句:文档不能匹配该查询条件;
- filter子句:过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score;
通常情况下,should子句是数组字段,包含多个should子查询,默认情况下,匹配的文档必须满足其中一个子查询条件。
如果查询需要改变默认匹配行为,查询DSL必须显式设置布尔查询的参数minimum_should_match的值,该参数控制一个文档必须匹配的should子查询的数量,我遇到一个布尔查询语句,其should子句中包含两个查询,如果不设置参数minimum_should_match,其默认值是0。建议在布尔查询中,显示设置参数minimum_should_match的值。
注:布尔查询的四个子句,都可以是数组字段,因此,支持嵌套逻辑操作的查询。
例如,对于以下should查询,一个文档必须满足should子句中两个以上的词条查询:
"should" : [
{ "term" : { "tag" : "azure" } },
{ "term" : { "tag" : "elasticsearch" } },
{ "term" : { "tag" : "cloud" } }
],
"minimum_should_match" : 2
布尔查询的各个子句之间的逻辑关系是与(and),这意味着,一个文档只有同时满足所有的查询子句时,该文档才匹配查询条件,作为结果返回。
在布尔查询中,对查询结果的过滤,建议使用过滤(filter)子句和must_not子句,这两个子句属于过滤上下文(Filter Context),经常使用filter子句,使得ElasticSearch引擎自动缓存数据,当再次搜索已经被缓存的数据时,能够提高查询性能;由于过滤上下文不影响查询的评分,而评分计算让搜索变得复杂,消耗更多CPU资源,因此,filter和must_not查询减轻搜索的工作负载。
查询和过滤上下文
在布尔查询中,查询被分为Query Context 和 Filter Context,查询上下文由query参数指定,过滤上下文由filter和must_not参数指定。这两个查询上下文的唯一区别是:Filter Context不影响查询的评分(score)。在布尔查询中,Filter参数和must_not参数使用Filter Context,而must和should使用Query Context,经常使用Filter Context,引擎会自动缓存数据,提高查询性能。


GET _search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
对于上述查询请求,must子句处于query context中,filter子句处于filter context中:
- 在query context中,must子句将返回同时满足匹配(match)查询的文档;
- 在filter context中,filter子句是一个过滤器,将不满足词条查询和范围查询条件的文档过滤掉,并且不影响匹配文档的score;
词条查询
字符串的完全匹配是指字符的大小写,字符的数量和位置都是相同的,词条(term)查询使用字符的完全匹配方式进行文本搜索,词条查询不会分析(analyze)查询字符串,给定的字段必须完全匹配词条查询中指定的字符串。由于词条查询的字符串是未经分析(analyzed)的词条,因此,词条查询经常用于结构化的数据,例如,数值,日期等,当用于文本搜索时,最好在索引映射中设置字符串字段不被索引,也就是说,设置index属性为not_analyzed,否则,只能对该字段进行单词条搜索,也可以使用多字段(fields)属性,定义一个不被分析的字段,原始字段用于全文搜索,而多字段用于词条搜索:
"properties":
{
"title":{ "type":"string","index":"analyzed"
"fields":{ "title_exact":{"type":"string","index":"not_analyzed"} }
},

1.1、精准查询:term【相当于sql:field = 1】
词条(term)查询和全文(fulltext)查询最大的不同之处是:
全文查询首先分析(Analyze)查询字符串,使用默认的分析器分解成一系列的分词,term1,term2,termN,然后从索引中搜索是否有文档包含这些分词中的一个或多个,如果执行的match查询,默认的操作符(operator)是,只要文档的字段值能够匹配任意一个词条,该文档就匹配查询条件;而词条查询是字符的完全匹配,只有当字段的字符完全匹配【包括大小写】查询字符串时,ElasticSearch引擎才判定文档匹配查询条件:
词条查询:词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜索。当在未被分析的字段中进行搜索时,和查询字符串完全匹配的文档会被返回;如果在已分析(Analyzed)的字段中进行搜索,词条必须是小写的单个词条,否则,匹配不到任何文档;
全文查询:ElasticSearch引擎会先分析(analyze)查询字符串,将其拆分成小写的分词,只要已分析的字段中包含词条的任意一个,或全部包含,就匹配查询条件,返回该文档;如果不包含任意一个分词,表示没有任何文档匹配查询条件。
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"full_text": {
"type": "string"
},
"exact_value": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
PUT my_index/my_type/1
{
"full_text": "Quick Foxes!",
"exact_value": "Quick Foxes!"
}
字段full_text 默认值被分析的(analyzed),字段exact_value显式设置不被分析,索引文档的结果是:在倒排索引中,字段full_text包含两个分词:quick和foxes,分词都是小写的;而exact_value由于未被分析,只是整个短语“Quick Foxes!”,只能进行完全匹配,在查询条件中,少一个字符或多一个字符,甚至大小写不同都不能匹配。
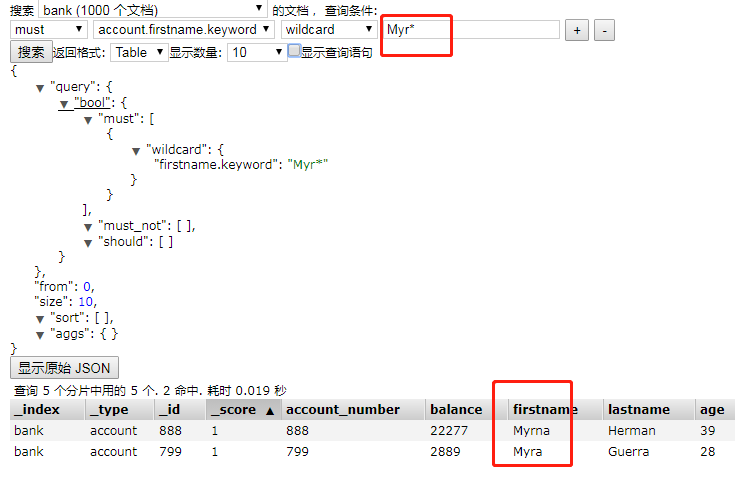
1.2、通配符查询:wildcard【相当于sql:field like '张_三*'】
ElsticSearch支持的通配符(wildcard)有2个,分别是:
- *:0个或多个任意字符
- ?:任意单个字符
在通配符查询中,ElasticSearch引擎不会分析查询字符串,当文档的字段 匹配通配符查询条件时,文档匹配。通配符查询会使查询性能变差,为了提高查询性能,推荐:查询字符串不要以通配符开头,只在查询字符串中间或末尾使用通配符。
{
"query": {
"wildcard": {
"firstname": "Myr*"
}
}
}
1.3、前缀查询:prefix【相当于sql:field like '张*'】
前缀匹配查询是指,文档的字段包含 以指定的字符(不会被分析)为前缀的分词,前缀匹配适用于已分析字段,只能匹配单个分词的前缀;
也适用于未被分析的字段,这样,字符串将从原始值的第一个字符开始前缀匹配
{ "query": { "prefix": {
"firstname": "Ma" }}}
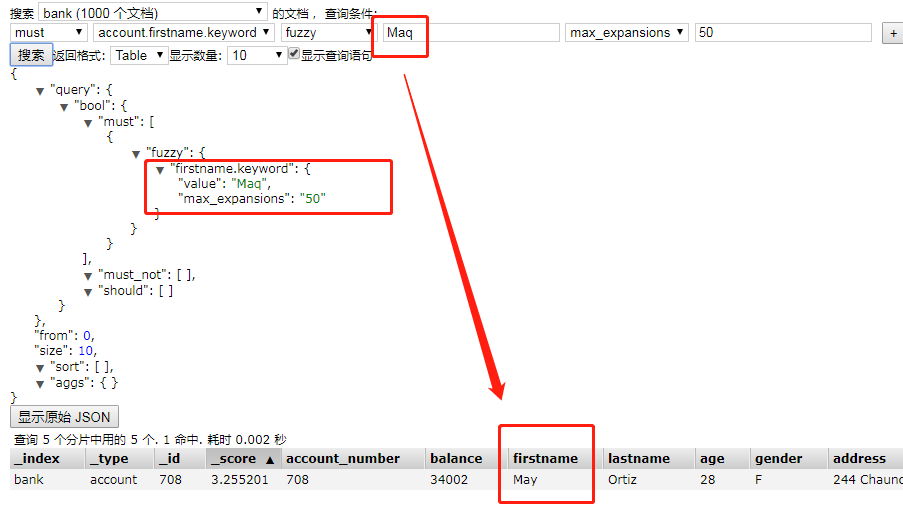
1.4、模糊度查询:fuzzy【通过fuzziness设置可以错几个】
查找指定字段 包含与指定术语模糊相似的术语的文档。模糊度是以Levenshtein编辑距离1或2来衡量的。
- fuzzy搜索技术
- 搜索的时候,可能输入的搜索文本会出现误拼写的情况
- 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据
- 纠正在一定的范围内如果差别大无法搜索出来
参数:fuzziness,你的搜索文本最多可以纠正几个字母去跟你的数据进行匹配,默认如果不设置,就是2
参数:min_similarity是查询字符串与数据库中的字符串匹配的百分比。
参数:max_expansions是Levenshtein距离,通过该距离搜索应该执行。默认50。
1.5、范围查询:range【相当于sql:field > 1 and field<30】
查找指定字段包含指定范围内的值(日期,数字或字符串)的文档。
{
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
}
}
}
范围查询使用的比较操作符:
- gte:大于或等于(Greater-than or equal to)
- gt:大于(Greater-than)
- lte:小于或等于(Less-than or equal to)
- lt:小于(Less-than)
1.6、查询字符串:query_string

1.7、缺失查询:missing
missing 过滤可以用于查找文档中 没有某个字段的文档

总共有3个文档,查询一下就剩2个,实际的查询是转换为must_not
