一、环境搭建
请参考上一篇博客:https://www.cnblogs.com/pghzl-123/p/12825669.html
参考文章:https://blog.csdn.net/zyn19950120/article/details/75948632
二、fork系统调用分析
1、进程创建概述
通过对start_kernel进行分析,我们会注意到Linux内核第一个进程的初始化;
其中,init_task为第⼀个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码⽅式固定下来的。除此之外,所有其他进程的初始化都是通过do_fork复制⽗进程的⽅式初始化的。
1号和2号进程的创建是start_kernel初始化到最后由rest_ init通kernel_thread创建了两个内核线程:⼀个是kernel_init,最终把⽤户态的进程init给启动起来,是所有⽤户进程的祖先;另⼀个是kthreadd内核线程,kthreadd内核线程是所有内核线程的祖先,负责管理所有内核线程。
kernel_thread创建进程的过程和shell命令⾏下启动⼀个进程时fork创建进程的过程在本质上是⼀样的,都要通过复制⽗进程来创建⼀个⼦进程。
_do_fork具体进程的创建⼤概就是把当前进程的描述符等相关进程资源复制⼀份,从⽽产⽣⼀个⼦进程,并根据⼦进程的需要对复制的进程描述符做⼀些修改,然后把创建好的⼦进程放⼊运⾏队列(操作系统原理中的就绪队列)。在进程调度时,新创建的⼦进程处于就绪状态有机会被调度执⾏。
2、fork系统调用概览
通过前文,我们大致了解了系统调用的大致处理过程。fork也是一个系统调用,和一般的系统执行过程大致是一样的。尤其从父进程的角度来看,fork的执行过程与一般的系统调用完全一致。
但问题是:fork系统调⽤创建了⼀个⼦进程,⼦进程复制了⽗进程中所有的进程信息,包括内核堆栈、进程描述符等,⼦进程作为⼀个独⽴的进程也会被调度,当⼦进程获得CPU开始运⾏时,它是从哪⾥开始运⾏的呢?从⽤户态空间来看,就是fork系统调⽤的下⼀条指令。但fork系统调⽤在⼦进程当中也是返回的,也就是说fork系统调⽤在内核⾥⾯变成了⽗⼦两个进程,⽗进程正常fork系统调⽤返回到⽤户态,fork出来的⼦进程也要从内核⾥返回到⽤户态。那么对于⼦进程来讲,fork系统调⽤在内核处理程序中是从何处开始执⾏的呢?⼀个新创建的⼦进程是从哪⾏代码开始执⾏的,这是⼀个关键问题。
fork与一般系统调用的不同之处在于有两次返回:
正常的⼀个系统调⽤都是陷⼊内核态,再返回到⽤户态,然后继续执⾏系统调⽤后的下⼀条指令。fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位置继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调⽤返回到⽤户态
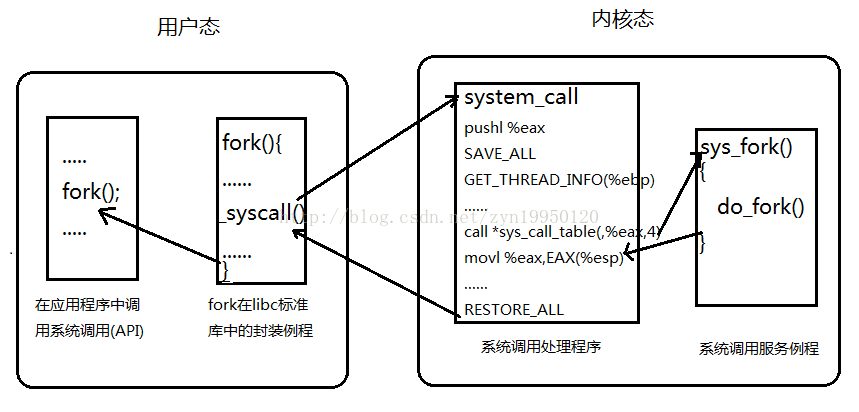
执行fork时从用户态到内核态的大致过程图如下所示:
1)通过对内核源码进行分析,fork、vfork、clone这三个系统调用和kernel_thread都可以创建一个新进程,而且都是通过do_for函数来创建的,只是传递的参数不一样。
接下来我们直接对do_fork进行分析,源码位于/linux/kernel/fork.c目录下。
fork的系统调用号

系统调用过程如下:
(1) 通过系统调用号宏以及_syscal()l函数结合cpu寄存器和0x80中断从用户空间到内核空间;
(2)进入内核空间之后,通过system_call对eax寄存器中的系统调用号以及其他寄存器传入的参数进行保存(SAVE ALL),并通过sys_call_table系统调用表进行查询,找到内部系统调用函数sys_fork(),调用完后,将返回值通过eax寄存器带回用户态,然后RESTORE_ALL,将各个寄存器的值pop.
(3)fork()函数在内核中的实现如图:
3、编写程序,使用fork函数:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <sys/types.h> 5 #include <sys/wait.h> 6 7 int main(int argc, char* argv[]) 8 { 9 int pid; 10 11 pid = fork(); 12 if(pid<0) 13 { 14 //error 15 fprintf(stderr,"For Failed"); 16 exit(-1); 17 } 18 else if(pid==0) 19 { 20 //child 21 printf("this is child process "); 22 } 23 else 24 { 25 //parent 26 printf("this is Parent process "); 27 wait(NULL); 28 printf("child complete "); 29 } 30 return 0; 31 }
执行结果:

gdb调试跟踪:
开启虚拟机,在__x64_sys_clone ,_do_fork,cpoy_process,dup_task_struct,copy_thread_tls下断点,shell下运行fork可执行文件,查看此时函数栈

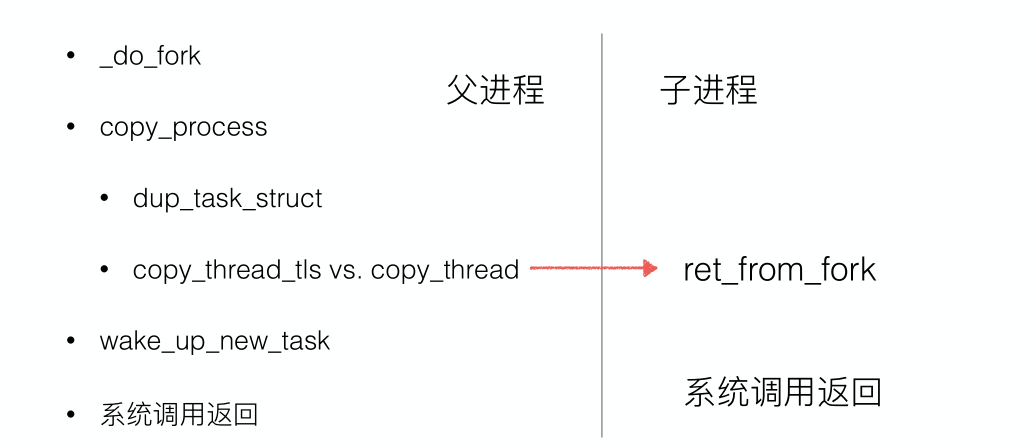
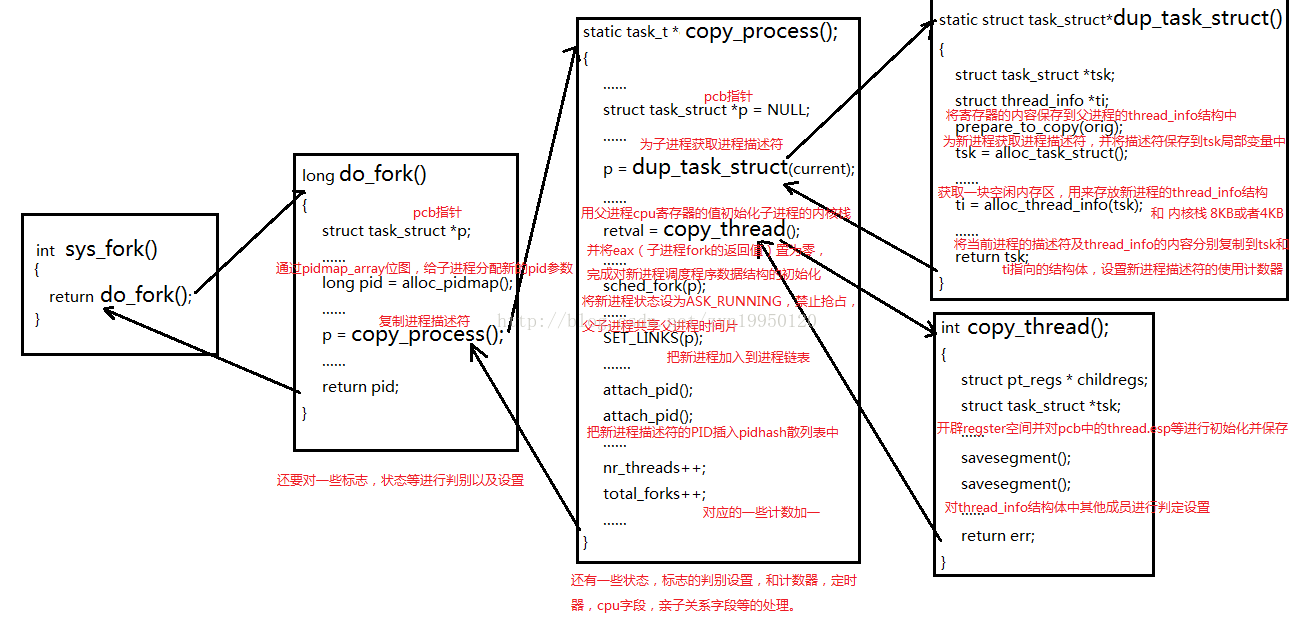
do_fork主要完成了调用copy_process()复制了父进程的信息、获得pid、调用wake_up_new_task将子进程加入调度队列等待获得分配CPU资源运行,进程的创建⼯作就完成了,⼦进程就可以等待调度执⾏,⼦进程的执⾏从这⾥设定的ret_from_fork开始。
copy_process是创建一个进程的主要代码。dup_task_struct复制当前进程(⽗进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时⼦进程置为就绪态)、采⽤写时复制技术逐⼀复制所有其他进程资源、调⽤copy_thread_tls初始化⼦进程内核栈、设置⼦进程pid等。其中最关键的就是dup_task_struct复制当前进程(⽗进程)描述符task_struct和copy_thread_tls初始化⼦进程内核栈。
如下图所示:

fork执行的整个过程图示如下 :
(copy_thread_tls在早期版本3.18.6该函数叫copy_thread)
execve系统调用:
前文指出fork和一般系统调用相比,有两次返回,execve也⽐较特殊。当前的可执⾏程序在执⾏,执⾏到execve系统调⽤时陷⼊内核态,在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏程序执⾏的起点,静态链接的可执⾏⽂件也就是main函数的⼤致位置,动态链接的可执⾏⽂件还需要ld链接好动态链接库再从main函数开始执⾏。
execve系统调⽤的内核处理过程:
Linux系统⼀般会提供了execl、execlp、execle、execv、execvp和execve等6个⽤以加载执⾏⼀个可执⾏⽂件的库函数,这些库函数统称为exec函数,差异在于对命令⾏参数和环境变量参数的传递⽅式不同。exec函数都是通过execve系统调⽤进⼊内核,对应的系统调⽤内核处理函数为sys_execve或__x64_sys_execve,它们都是通过调⽤do_execve来具体执⾏加载可执⾏⽂件的⼯作。
execve()系统调用的实质是运行的内核态的sys_execve()函数,大致处理过程如下:
整体的调⽤关系为
sys_execve()或__x64_sys_execve
-> do_execve() //读取128字节的文件头部,以此判断可执行文件的类型
–>do_execveat_common()
-> __do_execve_file
-> exec_binprm()
-> search_binary_handler() //去搜索和匹配合适的可执行文件装载处理过程
->load_elf_binary() //ELF文件由load_elf_binary()负责装载
-> start_thread() //由load_elf_binary()调用负责创建新进程的堆栈
进程切换和系统的一般执行过程:
1、进程调度的时机
1)中断:中断在本质上都是软件或者硬件发⽣了某种情形⽽通知处理器的⾏为,处理器进⽽停⽌正在运⾏的当前进程,对这些通知做出相应反应,即转去执⾏预定义的中断处理程序(内核代码⼊⼝),这就需要从进程的指令流⾥切换出来
中断能起到暂停当前进程指令流(Linux内核中称为thread)转去执⾏中断处理程序的作⽤,中断处理程序是与当前进程指令流独⽴的内核代码指令流。从⽤户程序的⻆度看进程调度的时机⼀般都是中断处理后和中断返回前的时机点进⾏,只有内核线程可以直接调⽤schedule函数主动发起进程调度和进程切换。
中断的类型:
- 硬中断:也称为外部中断,就是CPU的两根引脚(可屏蔽中断和不可屏蔽中断)的电平信号。
- 软中断/异常:也称为内部中断,包括除零错误、系统调⽤、调试断点等,在CPU执⾏指令过程中发⽣的各种特殊情况统称为异常。异常会导致程序⽆法继续执⾏,⽽跳转到CPU预设的处理函数。包括“故障、退出、陷阱(系统调用)
2)schedule函数:Linux内核通过schedule函数实现进程调度,schedule函数负责在运⾏队列中选择⼀个进程,然后把它切换到CPU上执⾏。
调⽤schedule函数的时机主要分为两类:
- 中断处理过程中的进程调度时机,中断处理过程中会在适当的时机检测need_resched标记,决定是否调⽤schedule()函数
- 内核线程主动调⽤schedule(),如内核线程等待外设或主动睡眠等情形下,或者在适当的时机检测need_resched标记,决定是否主动调⽤schedule函数。
2、上下文
一般来说,CP任何时刻都处于以下三种情况之一:
- 运⾏于⽤户态,执⾏⽤户进程上下⽂。
- 运⾏于内核空间,处于进程(内核线程)上下⽂。
- 运⾏于内核空间,处于中断(中断处理程序ISR,包括系统调⽤处理过程)上下⽂。
3、简单总结进程调度时机
- ⽤户进程上下⽂中主动调⽤特定的系统调⽤进⼊中断上下⽂,系统调⽤返回⽤户态之前进⾏进程调度。
- 内核线程或可中断的中断处理程序,执⾏过程中发⽣中断进⼊中断上下⽂,在中断返回前进⾏进程调度。
- 内核线程主动调⽤schedule函数进⾏进程调度。
- 中断处理程序执⾏过程主动调⽤schedule函数进⾏进程调度,与前述两类调度时机对应
4、Linux调度策略
Linux系统中常⽤的⼏种调度策略为
- SCHED_NORMAL:引⼊的CFS(Complete Fair Scheduler)调度管理程序。
- SCHED_FIFO:采⽤先进先出的策略,对于所有相同优先级的进程,最先进⼊就绪队列的进程总能优先获得调度,直到其主动放弃CPU
- SCHED_RR:采⽤更加公平的轮转策略,⽐FIFO多⼀个时间⽚,使得相同优先级的实时进程能够轮流获得调度,每次运⾏⼀个时间⽚。
- SCHED_BATCH
SCHED_NORMAL是⽤于普通进程的调度类,
SCHED_FIFO和SCHED_RR是⽤于实时进程的调度类,优先级⾼于SCHED_NORMAL
CFS即为完全公平调度算法,其基本原理是基于权重的动态优先级调度算法。每个进程使⽤CPU的顺序由进程已使⽤的CPU虚拟时间(vruntime)决定,已使⽤的虚拟时间越少,进程排序就越靠前,进程再次被调度执⾏的概率也就越⾼。每个进程每次占⽤CPU后能够执⾏的时间(ideal_runtime)由进程的权重决定,并且保证在某个时间周期(__sched_period)内运⾏队列⾥的所有进程都能够⾄少被调度执⾏⼀次。
5、进程上下文切换
为了控制进程的执⾏,内核必须有能⼒挂起正在CPU上运⾏的进程,并恢复执⾏以前挂起的某个进程。这种⾏为被称为进程切换,任务切换或进程上下⽂切换。尽管每个进程可以拥有属于⾃⼰的地址空间,但所有进程必须共享CPU及寄存器。因此在恢复⼀个进程执⾏之前,内核必须确保每个寄存器装⼊了挂起进程时的值。进程恢复执⾏前必须装⼊寄存器的⼀组数据,称为进程的CPU上下⽂。
进程上下文包含了进程执行需要的所有信息:
- ⽤户地址空间:包括程序代码、数据、⽤户堆栈等。
- 控制信息:进程描述符、内核堆栈等
- 进程的CPU上下⽂,相关寄存器的值
进程切换就是变更进程上下文,最核心的是几个关键寄存器的的保存与变换:
- CR3寄存器代表进程⻚⽬录表,即地址空间、数据。
- 内核堆栈栈顶寄存器sp代表进程内核堆栈(保存函数调⽤历史),进程描述符(最后的成员thread是关键)和内核堆栈存储于连续存取区域中,进程描述符存在内核堆栈的低地址,栈从⾼地址向低地址增⻓,因此通过栈顶指针寄存器还可以获取进程描述符的起始地址。
- 指令指针寄存器ip代表进程的CPU上下⽂,即要执⾏的下条指令地址。
进程切换关键环节示意图:
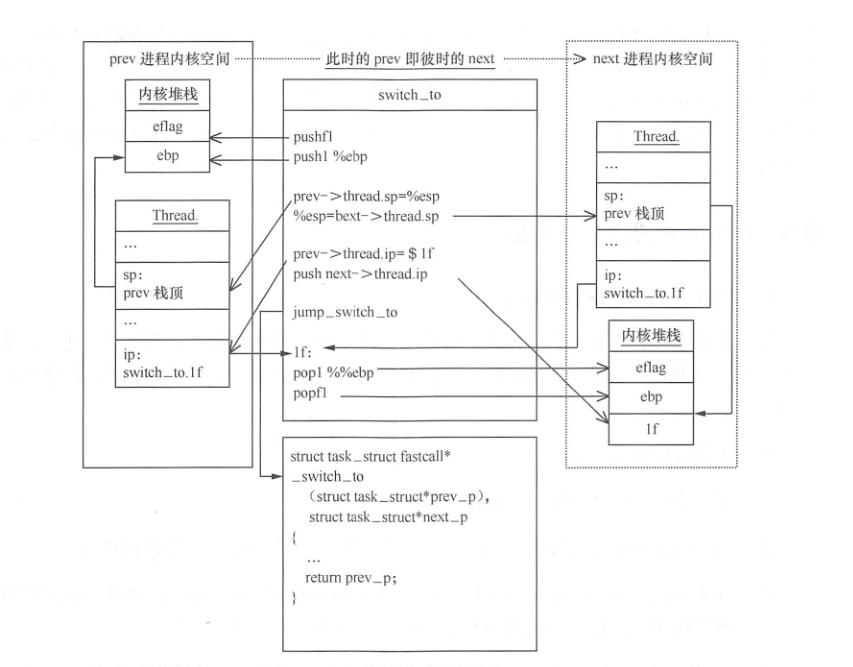
进程上下⽂切换时需要保存要切换进程的相关信息(如thread.sp与thread.ip),这与中断上下⽂的切换是不同的。
- 中断是在⼀个进程当中从进程的⽤户态到进程的内核态,或从进程的内核态返回到进程的⽤户态,
- 切换进程需要在不同的进程间切换。但⼀般进程上下⽂切换是嵌套到中断上下⽂切换中的,
- ⽐如前述系统调⽤作为⼀种中断先陷⼊内核,即发⽣中断保存现场和系统调⽤处理过程。其中调⽤了schedule函数发⽣进程上下⽂切换,当系统调⽤返回到⽤户态时会恢复现场,⾄此完成了保存现场和恢复现场,即完成了中断上下⽂切换
6、Linux系统的一般执行过程
以正在运行的用户态进程X切换到用户态进程Y为例具体表述如下:
- 正在运行的用户态进程X
- 发生中断(包括异常、系统调用等),硬件完成以下动作:1)save cs:eip/ss:eip/eflags:当前CPU上下文压入用户态进程X的内核堆栈;2)load cs:eip/ss:esp:加载当前进程内核堆栈相关信息,跳转到中断处理程序处,即中断处理程序的起点
- SAVE_ALL,保存现场,此时完成了中断上下文的切换,即从进程X的用户态到进程X的内核态
- 中断处理过程中或中断返回前调用了schedule函数进行进程上下文切换。将当前用户进程X的内核堆栈切换到挑选出的next进程Y的内核堆栈,并完成进程上下文所需的EIP等寄存器的状态切换;
- 标号1,即$1f,之后开始运行用户态进程Y
- restore_all,恢复现场,与SAVE_ALL保存现场相对应
- 从Y进程的内核堆栈弹出步骤2硬件完成的压栈内容,此时完成中断上下文的切换,即从进程Y的内核态返回进程Y的用户态;
- 继续运行进程Y
关键点包括:
- 中断和中断返回有CPU硬件上下文的切换
- 进程调度过程中有进程上下文的切换,而进程上下文的切换包括:从一个进程的地址空间切换到另一个进程的地址空间;从一个进程的内核堆栈切换到另一个进程的内核堆栈;还有诸如EIP等寄存器状态的切换