Show and Tell: A Neural Image Caption Generator-阅读总结
笔记不能简单的抄写文中的内容,得有自己的思考和理解。
一、基本信息
| 标题 | 作者 | 作者单位 | 发表期刊/会议 | 发表时间 |
|---|---|---|---|---|
| Show and Tell: A Neural Image Caption Generator |
Oriol Vinyals vinyals@google.com Alexander Toshevtoshev@google.com Samy Bengio bengio@google.com Dumitru Erhan dumitru@google.com |
Google_DeepMind Google Brain Google Brain |
CVPR | 2015 |
二、看本篇论文的目的
了解image caption 的较为早期的神经网络相关的研究成果。
三、场景和问题
scene: computer vision and natural language processing, natural image.
problem: automatically describing the content of an image using properly formed English sentences.
四、研究目标
present a single joint model that is more accurate, both qualitatively and quantitatively, and it just takes an image I as input, and is trained to maximize the likelihood p(S|I) of producing a target sequences of words (S={{S_1,S_2,...}}) where each word (S_t) comes from a given dictionary, that describes the image adequately.
五、主要思路/创新
Main inspiration:
Recent advances in machine translation---to transform a sentence S written in a source language, into its translation T in the target language, by maximizing (p(T|S)). An "encoder" RNN reads the source sentence and transforms it into a rich fixed-length vector representation, which in turn in used as the initial hidden state of a "decoder" RNN that generates the target sentence.
Main innovation:
Replacing the encoder RNN by a deep CNN(using a CNN as an image "encoder"). CNNs can produce a rich representation of the input image by embedding it to a fixed-length vector. By pre-training the CNN for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences.
Using stochastic gradient decent.
Model name:
An end-to-end system: Neural Image Caption--NIC.
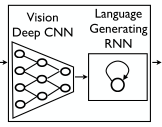
六、核心算法

1.Directly maximize the probability of the correct description given the image by using formulation:
( heta) are the parameters of the model, (I) is an image, (S) is its correct transcription.
(N) is the length of the sentence: (log\, p(S|I)=sum_limits{t=0}^N log\,p(S_t|I,S_0,...,S_{t-1}))
2.Model (p(S_t|I,S_0,...,S_{t-1})) with a RNN, the variable number of words which we condition upon up to (t-1) is expressed by a fixed length hidden state or memory (h_t). The (h_t) is updated after seeing a new input (x_t) by using a non-linear function (f) : (h_{t+1}=f(h_t,x_t)).
3.CNN uses a novel approachto batch normalization and yields the current best performance on the ILSVRC 2014 classification competition. (f) is a Long-Short Term Memory (LSTM) net.
4.Implementation details of LSTM model:
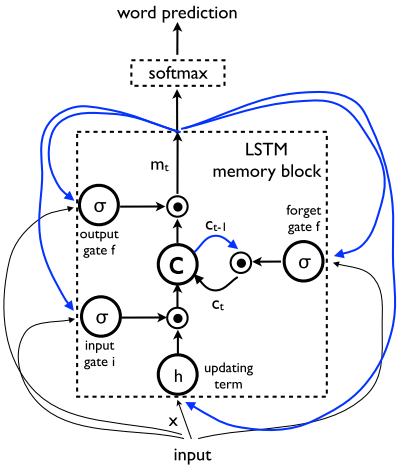
七、模型实现细节
The unrolling procedure:
1.each word is represented as a one-hot vector (S_t) of dimension equal to the size of the dictionary.
2.(S_0) is a special denoted start word and (S_N) is a special denoted stop word which designates the start and end of the sentence.
3.both the iamge and the words are mapped to the same space, the image by using a vision CNN, the words by using word embedding (W_e).
4.The image is only input once, at (t=-1), to inform the LSTM about the image contents.
5.the loss is the sum of the negative log likelihood of the correct word at each step:(L(I,S)=-sum_limits{t=1}^Nlog\, p_t(S_t)).
6.two sentence generation approaches:
the first one: Sampling-just sample the first word according to (p_1), then provide the corresponding embedding as input and sample (p_2), continuing like this until we sample the special end-of-sentence token or some maximum length.
the second one: BeamSearch-iteratively consider the set of the k best sentences up to time (t) as candidates to generate sentences of size (t+1), and keep only the resulting best k of them. This better approximates (S=arg\,max_{S'}\,p(S'|I)).
this paper used the BeamSearch approach in the experimens, beam size is 20 and it's verified that beam size of 1 did degrade the results by 2 BLEU points on average.
八、采用的评价指标&数据集
1.Amazon Mechanical Turk: The most reliable metrics-ask for raters to give a subjective score on the usefulness of each description given the iamge-each image was rated by 2 workers, in case of disagreement, just simply average the scores.
2.Automatically computed metrics: BLEU score, METEOR, Cider
3.Datasets:
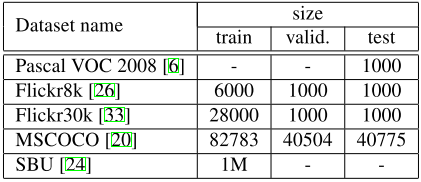
九、实验细节
Training Details:
1.Overfitting: high quality datasets have less than 100000 images
--initialize the weights of the CNN component of the system to a pretrained model.
--initialize the (W_e), the word embeddings from a large news corpus but no significant gains were observed, so just leave them uninitialized for simplicity.
--some model level overfitting-avoiding techniques: dropout, ensembling models, exploring the size of the model by trading off number of hidden units versus depth.(dropout and ensembling gave a few BLEU points improvement)
--using 512 dimensions for the embeddings and the size of the LSTM memory.
十、验证的问题&效果
Question 1:
whether we could transfer a model to a different dataset, and how much the mismatch in domain would be compensated with e.g. higer quality labels or more training data.
transfer learning -- data size:
1.Flickr30k and Flickr8k (30k is about 4 times more training data than 8k): Flickr30k results obtained 4 BLEU points better.
2.MSCOCO and Flickr30k (MSCOCO has 5 times more training data than 30k): more differences in vocabulary and a larger mismatch, all the BLEU scores degrade by 10 points.
3.PASCAL - transfer learning from Flickr30k, yielded worse results - BLEU-1 at 53 (cf. 59).
4.SBU (i.e., the labels were captions and not human generated descriptions): task is much harder with a much larger and noiser vocabulary, transfer MSCOCO model on SBU - performance degrades from 28 down to 16.
Question 2:
whther the model generates novel captions, and whether the generated captions are both diverse and high quality.
1.agreement in BLEU score between the top 15 genetated sentences is 58 .
2.80% of the best candidates are present in the training set, beacuse of the small amount of training data.
3.half of the times, we can see a completely novel description when analyze the top 15 generated sentences.
Question 3:
how the learned representations have captured some semantic from the statistics of the language.

hypothesis: a few examples of a class (e.g., "unicorn"), its proximity to other word embeddings (e.g., "horse") should provide a lot more information that would be completely lost with more traditional bag-of-words based approaches.