基于Mysql5.7版本的explain参数详解…
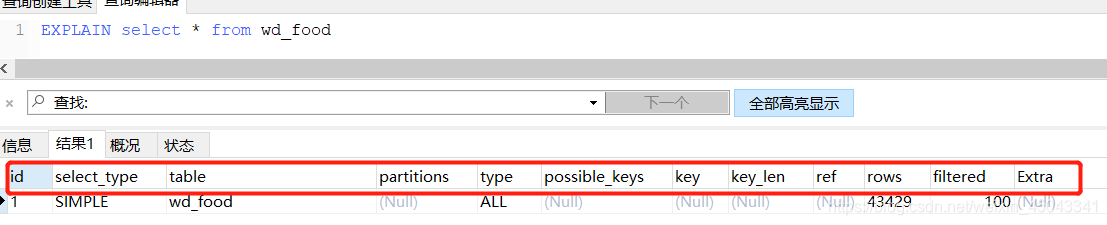
mysql官网相关参数解读
一:id SELECT标识符
1.id越大越先执行
2.相同id,从从往下执行
二:select_type
1.SIMPLE :最简单的查询(没有关联查询没有子查询没有union的查询语句)

2:PRIMARY:子查询最外层的查询语句
3.SUBQUERY:子查询内层查询语句
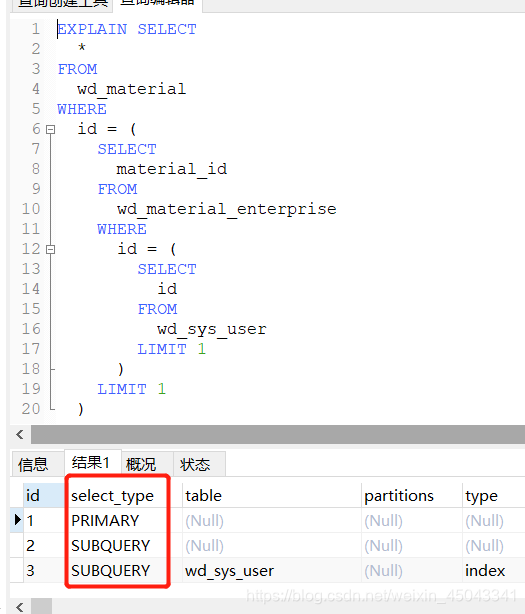
4.DERIVED:派生表查询, FROM后的不是表而是查询后的结果集
5.UNION:union或union all中的第二个以后的查询表
6.UNION RESULT:union后的结果集

三: table 输出行所引用的表的名称
<unionM,N>:指id值为M和N的行的并集。
<derived N:该行引用id值为N的行的派生表结果。
<subquery N:该行是指该行的物化子查询的结果,其id 值为N

四:partitions 分区
查询将从中匹配记录的分区。对于未分区的表,该值为NULL。
五:type: the join type 关联类型
ordered from the best type to the worst 从最优到最劣
1.system: 该表为系统表而且只有一行。这是const联接类型的特例 。
2.const: 在PRIMARY KEY或 UNIQUE index的所有部分与常量值进行比较时使用

3.eq_ref:关联的被驱动表的字段时主键索引或者唯一索引

4.ref:对于先前表中的每个行组合,将从该表中读取具有匹配索引值的所有行。ref如果联接仅使用键的最左前缀,或者如果键不是aPRIMARY KEY或 UNIQUE索引(换句话说,如果联接无法基于键值选择单个行),则使用。如果使用的键仅匹配几行,则这是一种很好的联接类型。
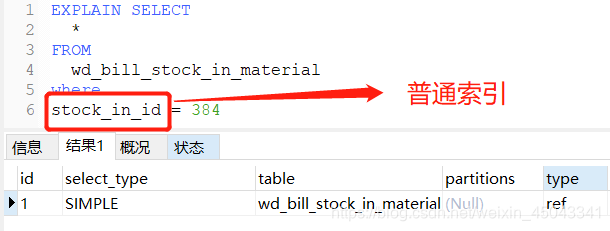
5.range:使用索引选择行,仅检索给定范围内的行

6.index:查询覆盖索引的所有数据

7.all:全表扫描
六:possible_keys:可能用到的索引
七:key 该key列指示MySQL实际决定使用的索引
注意:possible_keys 为null,key可能会用到索引

虽然不满足联合索引的最左匹配原则,但是用到了覆盖索引,还是走了联合索引树
八:key_len 索引的长度
九:ref 该ref列显示将哪些列或常量与该key列中命名的索引进行比较,以从表中选择行
十:rows 预计需要扫描的行数,不是一个精确的值
十一:filtered 表示按表条件过滤的表行的估计百分比。最大值为100,这表示未过滤行。值从100减小表示过滤量增加。 rows显示了检查的估计行数,rows× filtered显示了与下表连接的行数。例如,如果 rows为1000且 filtered为50.00(50%),则与下表连接的行数为1000×50%= 500。
十二:extra 有关MySQL如何解析查询的其他信息
1.Using where: using where 意味着mysql服务器将在存储引擎检索行后再进行过滤。
2.Using index: 表示Mysql将使用覆盖索引,以避免回表;
3.Using index condition: 全称Using index condition pushdown ICP 索引下推
ICP:MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。

4.Using filesort 用到的索引不是排序字段

5.Using temporary 用到了临时表。如果查询包含GROUP BY和 ORDER BY子句以不同的方式列出列,通常会发生这种情况。
6.Using join buffer:关联表没有用到索引,需要连接缓冲区来存储中间结果。需要添加索引来优化
