文章目录
一、写在前面
好久不见。
一转眼,新的一年已经走过了两个月,距离上次更新博客也相隔好几个月,原本打算月更的我,也因为工作
和懒散,走上了拖更之路。
不过,我小宗又回来了!
今天,让我们来探究一个老生常谈的问题:Map集合的遍历。这同时也是许多Java初学者必须要掌握的基础知识,网上也有很多大神很多博客对此进行讲解。此博文从知识层面上借鉴之,并记录于2021年2月3日16:13:15。
二、正式开始探究之旅
1. Map集合一共有多少种遍历方式呢?
Map集合主要有三种遍历方式:keySet()、entrySet()、values()。但是,如果从API层面上进行细分的话有7种。这三种各自都有两种形式,for循环和Iterator迭代。还有最后一种,如果你是JDK8以上版本,还可以使用Lambda表达式forEach遍历。
2.那这几种遍历方式的具体用法是啥样的呢?
下面,我使用IDEA新建一个项目,进行demo编写演示。具体的IDEA操作不属于本文的研究重点,略去不表。直接在test下面写测试案例。
2.1 keySet()方式遍历-------for循环
//2.1 keySet()方式遍历-------for循环
long keySetForStartTime = System.nanoTime();
for (String key : map.keySet()) {
map.get(key);
}
long keySetForEndTime = System.nanoTime();
2.2 keySet()方式遍历-------Iterator迭代
//2.2 keySet()方式遍历-------Iterator迭代
long keySetIteratorStartTime = System.nanoTime();
Iterator<String> iterator1 = map.keySet().iterator();
while (iterator1.hasNext()) {
String key = iterator1.next();
map.get(key);
}
long keySetIteratorEndTime = System.nanoTime();
2.3 entrySet()方式遍历-------for循环
long entrySetForStartTime = System.nanoTime();
for (Map.Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
long entrySetForEndTime = System.nanoTime();
2.4 entrySet()方式遍历-------Iterator迭代
long entrySetIteratorStartTime = System.nanoTime();
Iterator<Map.Entry<String, String>> iterator2 = map.entrySet().iterator();
while (iterator2.hasNext()) {
Map.Entry<String, String> entry = iterator2.next();
entry.getKey();
entry.getValue();
}
long entrySetIteratorEndTime = System.nanoTime();
2.5 values()方式遍历-------for循环
long valuesForStartTime = System.nanoTime();
Collection<String> values = map.values();
for (String value : values) {
//.....
}
long valuesForEndTime = System.nanoTime();
2.6 values()方式遍历-------Iterator迭代
//2.6 values()方式遍历-------Iterator迭代
long valuesIteratorStartTime = System.nanoTime();
Iterator<String> iterator3 = map.values().iterator();
while (iterator3.hasNext()) {
String value = iterator3.next();
}
long valuesIteratorEndTime = System.nanoTime();
2.7 JDK8-------Lambda表达式forEach遍历
//2.7 JDK8-------Lambda表达式forEach遍历
long forEachStartTime = System.nanoTime();
map.forEach((key, value) -> {
//......
});
long forEachEndTime = System.nanoTime();
JDK8Lambda表达式的forEach方法,其实就是一种语法糖,让你的代码更加简洁,使用更加方便,深入源码,我们可以很轻易的发现,它其实就是对entrySet遍历方式的一种包装而已。不信你看下面我贴的forEach源码。
forEach源码。本方法since1.8版本
* @param action The action to be performed for each entry
* @throws NullPointerException if the specified action is null
* @throws ConcurrentModificationException if an entry is found to be
* removed during iteration
* @since 1.8
*/
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
3. 那这几种遍历方式的性能如何呢?哪一种更推荐使用呢?
3.1首先,我们来准备一下测试数据
我们实例化一个HashMap对象,往Map中添加一百万条数据,以此作为测试数据。
//准备Map,装入测试数据
Map<String, String> map = new HashMap<>();
//往map里插入一百万数据,作为测试数据,别怕,家里就这条件
for (int i = 0; i < 1000000; i++) {
map.put(String.valueOf(i), "我是第" + i + "名");
}
3.2打印各种遍历方式遍历测试数据的执行时间
由于在上一部分的API使用的代码中,我们已经穿插进去计算执行时间的代码,下面我们可以直接打印时间差,作为每种遍历方式的执行时间,虽然不是很严格,但是也能从结果中看得比较明显。
System.out.println("keySet()方式遍历-------for循环用时:" + (keySetForEndTime - keySetForStartTime) / 1000000 + "毫秒");
System.out.println("keySet()方式遍历-------Iterator迭代用时:" + (keySetIteratorEndTime - keySetIteratorStartTime) / 1000000 + "毫秒");
System.out.println("entrySet()方式遍历-------for循环用时:" + (entrySetForEndTime - entrySetForStartTime) / 1000000 + "毫秒");
System.out.println("entrySet()方式遍历-------Iterator迭代用时:" + (entrySetIteratorEndTime - entrySetIteratorStartTime) / 1000000 + "毫秒");
System.out.println("values()方式遍历-------for循环用时:" + (valuesForEndTime - valuesForStartTime) / 1000000 + "毫秒");
System.out.println("values()方式遍历-------Iterator迭代用时:" + (valuesIteratorEndTime - valuesIteratorStartTime) / 1000000 + "毫秒");
System.out.println("JDK8-------Lambda表达式forEach遍历用时:" + (forEachEndTime - forEachStartTime) / 1000000 + "毫秒");
3.3测试结果
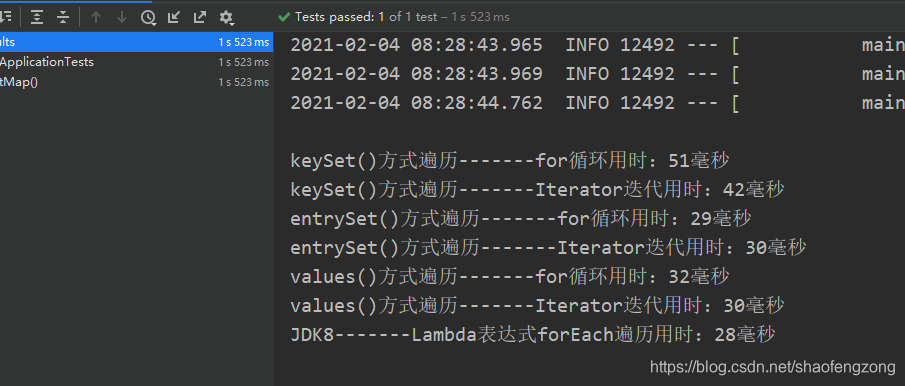
结果分析:
直接抛出结论,entrySet()方式比keySet()方式效率更高,在忽略其他条件下,对于同一种遍历方式而言,Iterator迭代比for循环效率高。
当然,上述的结论只是说出了一半。其实是分两种情况的。在元素数量大的情况下,entrySet()性能确实是优于keySet()的,越大越明显。同样的,在小数据量的情况下,keySet()效率更高一点。
为啥大数据量时,entrySet()效率高呢?
其实,keySet()遍历,其实是相当于遍历了两次,第一次是转换为Iterator对象,第二次才是根据key从Map中取出对应的value值。而entrySet()转成Entry对象,只遍历一次。
当然,还有其他的一些原因,比如,map.get(key),这一操作注定了是计算密集型操作,很耗费CPU,在此不再过多说明。
values()方式的说明
values(),顾名思义,它得到的是Map中value的集合,因此,想要获取value对应的key值比较困难,因此使用上还是看需求。
在日常的开发工作中推荐使用哪一种遍历方式呢?
直接说结论:推荐使用entrySet()遍历方式,这依然是不二之选。并不是很建议使用keySet方式。如果项目是JDK8以上的版本,直接使用forEach吧,底层原理一样,语法更好更简洁,何乐而不为呢?
三、写在最后
虽然本文比较基础,但对于初学者而言,依然是比较重要的一节课,毕竟这种数据结构的使用在日常的项目开发中,不可或缺。算是写了一篇水文,也算是延续继续更下去的习惯吧。
后续有时间可能会更一篇Java的数据结构,LIst、Map、Set等的底层原理以及JDK7、8版本底层的升级。
也有可能会研究一下Redis的使用。
谁又说的准呢?
毕竟下一次更文,还不知道呢。哈哈
我是小宗,Java学习,我和你一样,一直在路上。加油!
四、附录–全部测试源码
@Test
void testMap() {
//准备Map,装入测试数据
Map<String, String> map = new HashMap<>();
//往map里插入一百万数据,作为测试数据,别怕,家里就这条件
for (int i = 0; i < 1000000; i++) {
map.put(String.valueOf(i), "我是第" + i + "名");
}
//2.1 keySet()方式遍历-------for循环
long keySetForStartTime = System.nanoTime();
for (String key : map.keySet()) {
map.get(key);
}
long keySetForEndTime = System.nanoTime();
//2.2 keySet()方式遍历-------Iterator迭代
long keySetIteratorStartTime = System.nanoTime();
Iterator<String> iterator1 = map.keySet().iterator();
while (iterator1.hasNext()) {
String key = iterator1.next();
map.get(key);
}
long keySetIteratorEndTime = System.nanoTime();
//2.3 entrySet()方式遍历-------for循环
long entrySetForStartTime = System.nanoTime();
for (Map.Entry<String, String> entry : map.entrySet()) {
entry.getKey();
entry.getValue();
}
long entrySetForEndTime = System.nanoTime();
//2.4 entrySet()方式遍历-------Iterator迭代
long entrySetIteratorStartTime = System.nanoTime();
Iterator<Map.Entry<String, String>> iterator2 = map.entrySet().iterator();
while (iterator2.hasNext()) {
Map.Entry<String, String> entry = iterator2.next();
entry.getKey();
entry.getValue();
}
long entrySetIteratorEndTime = System.nanoTime();
//2.5 values()方式遍历-------for循环
long valuesForStartTime = System.nanoTime();
Collection<String> values = map.values();
for (String value : values) {
//.....
}
long valuesForEndTime = System.nanoTime();
//2.6 values()方式遍历-------Iterator迭代
long valuesIteratorStartTime = System.nanoTime();
Iterator<String> iterator3 = map.values().iterator();
while (iterator3.hasNext()) {
String value = iterator3.next();
}
long valuesIteratorEndTime = System.nanoTime();
//2.7 JDK8-------Lambda表达式forEach遍历
long forEachStartTime = System.nanoTime();
map.forEach((key, value) -> {
//......
});
long forEachEndTime = System.nanoTime();
System.out.println("keySet()方式遍历-------for循环用时:" + (keySetForEndTime - keySetForStartTime) / 1000000 + "毫秒");
System.out.println("keySet()方式遍历-------Iterator迭代用时:" + (keySetIteratorEndTime - keySetIteratorStartTime) / 1000000 + "毫秒");
System.out.println("entrySet()方式遍历-------for循环用时:" + (entrySetForEndTime - entrySetForStartTime) / 1000000 + "毫秒");
System.out.println("entrySet()方式遍历-------Iterator迭代用时:" + (entrySetIteratorEndTime - entrySetIteratorStartTime) / 1000000 + "毫秒");
System.out.println("values()方式遍历-------for循环用时:" + (valuesForEndTime - valuesForStartTime) / 1000000 + "毫秒");
System.out.println("values()方式遍历-------Iterator迭代用时:" + (valuesIteratorEndTime - valuesIteratorStartTime) / 1000000 + "毫秒");
System.out.println("JDK8-------Lambda表达式forEach遍历用时:" + (forEachEndTime - forEachStartTime) / 1000000 + "毫秒");
}
