1.时间模块(time)
能够描述时间、获取时间的模块
1)时间戳时间(float数据类型),也叫格林威治时间-----一般机器用
①英国伦敦时间,从1970.1.1 0:0:0开始计时;对应的北京时间从1970.1.1. 08:00:00开始计时
#计算1970.1.1 08:00:00开始到现在的时间(秒)


import time print(time.time()) 输出: 1604933370.1555471
2)结构化时间(时间戳时间向格式化时间转化的一个数据类型,是一个时间对象,可以通过【.属性名】来获取对象中的值)----上下两种格式的中间状态
import time obj = time.localtime() #返回一个时间对象对象 print(obj) print(obj.tm_year) print(obj.tm_mon) print(obj.tm_mday) 输出: time.struct_time(tm_year=2020, tm_mon=11, tm_mday=9, tm_hour=23, tm_min=2, tm_sec=10, tm_wday=0, tm_yday=314, tm_isdst=0) 2020 11 9 说明:tm_isdst=0表示是否夏令时
3)格式化时间(str数据类型),也叫字符串时间,可根据需要的格式来显示时间----一般用户用
import time print(time.strftime('%Y-%m-%d')) 输出: 2020-11-08
#打印年月日,时分秒
import time print(time.strftime("%Y-%m-%d %H:%M:%S")) print(time.strftime("%y/%m/%d %H:%M:%S")) print(time.strftime('%c')) 输出: 2020-11-08 23:11:22 20/11/09 23:13:10 Sun Nov 8 23:11:22 2020
4)时间格式之间的互相转换
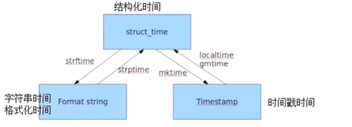
①时间戳时间转化未格式化时间(Timestamp--->Format string)
import time print(time.time()) time_obj = time.localtime(1604936213) #获取时间对象 print(time_obj) format_time = time.strftime('%Y-%m-%d',time_obj) print(format_time) 输出: 1604936387.2195988 time.struct_time(tm_year=2020, tm_mon=11, tm_mday=8, tm_hour=23, tm_min=36, tm_sec=53, tm_wday=0, tm_yday=314, tm_isdst=0) 2020-11-08
②格式化时间转化为时间戳时间
import time struct_time = time.strptime('2020-11-09','%Y-%m-%d') print(struct_time) print(time.mktime(struct_time)) 输出: time.struct_time(tm_year=2020, tm_mon=11, tm_mday=9, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=314, tm_isdst=-1) 1604851200.0
5)练习:获取本月1号的时间戳时间
#以格式化时间的方式转化时间戳时间
import time ret = time.strftime("%Y-%m-1") struct_time = time.strptime(ret,'%Y-%m-%d') print(struct_time) print(time.mktime(struct_time)) 输出: time.struct_time(tm_year=2020, tm_mon=11, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=306, tm_isdst=-1) 1604160000.0
#以结构化时间格式的方式转化为时间戳时间
import time ret = time.localtime() struct_time = time.strptime('%s-%s-%s'%(ret.tm_year,ret.tm_mon,1),'%Y-%m-%d') print(time.mktime(struct_time)) 输出: 1604160000.0
#计算两个格式化时间的时间差
略
2.sys模块
sys模块用来和python解释器打交道
1)sys.path python解释器寻找坏境变量时的路径
2)sys.moudles 当前python程序中共导入和多少个模块在内存中
3)sys.pplatform 获取当前python程序所在的操作系统,是以python角度统计的,不准
4)sys.exit() 退出,即结束程序,下面的代码不再执行
5)sys.argv
①返回一个列表,列表的第一个元素执行程序文件的时候,写在python后面的第一个值
E:pythonprojectuntitled练习>python 基础代码练习.py 123 xyz
['基础代码练习.py', '123', 'xyz']
②作用:在执行程序时,可在程序文件名后写多个值,这些值都会被一次添加到一个列表中
③使用
#改善登录程序(pycharm无法正常传入参数,因为pycharm直接使用了绝对路径)
import sys name = sys.argv[1] passwd = sys.argv[2] if name == "阿狸" and passwd == "123": print("登录成功") else: sys.exit() 执行程序: E:pythonprojectuntitled练习>python 基础代码练习.py 阿狸 123 登录成功
3.os模块-----os模块是和操作系统交互相关的
1)和工作目录有关
① os.getcwd()
#作用:在哪个地方执行这个文件,getcwd的结果就是哪个路径
import os print(os.getcwd()) 程序执行: D:>python E:pythonprojectuntitled练习基础代码练习.py D:
②os.chdir
#作用:改变当前程序的工作目录,相当于shell下的cd(一般不用)
③os.curdir(没用)
#返回当前程序的相对目录,即点
④os.pardir(没用)
#返回当前程序的上级目录,即点点
import os print(os.curdir) print(os.pardir) 输出: . ..
2)创建文件/文件夹、删除文件/文件夹相关
①os.remove() #删除一个文件
②os.rename("oldname","newname") #重命名文件/目录
③os.mkdir("dirname") #创建单级目录,相当于shell中的mkdir dirname
④os.rmdir("dirname") #删除空目录,若目录不空则无法删除,相当于linux中的rmdir
⑤os.makedirs("dir1/dir2/dir3") #创建多级目录
⑥os.removedirs('dir1/dir2/dir3') #递归向上删除文件夹,只要删除当前目录之后,发现上一级目录也为空了,就把上一级目录也删掉;如果上一级目录有其他文件,就停止
⑦os.listdir(“路径”)
#查看某个路径下的所有文件和文件夹
3)和操作系统差异相关
①os.stat("文件")
#查看文件的属性信息,包括访问时间、修改时间、权限等
②os.sep
#查看当前所在操作系统默认的目录分隔符(linux下为/ windows下为)
③os.linesep
#输出当前平台使用的行终止符(linux下位 windows下位 )
④os.pathsep
#暑促用于分割问及那路径的字符串(windows下位; linux下位:)----环境变量
⑤os.name
#输出字符串只是当前使用的操作系统平台(windows为‘nt‘ linux为posix)
作用:为了更好的支持跨平台,区分了windows和linux区别,例
base_path = "E:pythonprojectuntitled练习"
s = "基础代码练习"
ret = os.sep.join(base_path,s)
4)使用python来和操作系统命令交互相关
①os.system("命令") *****
#执行操作系统命令,直接执行命令,无返回
②os.popen() *****
#先返回一个目录执行的对象,然后通过对象操作返回的字符串
import os ret = os.popen("dir") print(ret) print(ret.read()) 输出: <os._wrap_close object at 0x00000125C461B6D8> 驱动器 E 中的卷是 新加卷 卷的序列号是 649A-5920
注:一般删除、拷贝文件等只关心结果的时候可以用system;对于查看当前路径、查看某些信息可以使用os.popen
5)查看环境变量
①os.environ
#查看操作系统的坏境变量
6)os.path
①os.path.abspath(path)
#返回path规范化的绝对路径,如果是一个相对路径 会转成一个绝对路径;如果路径是不规范的也会转成规范的(即/变为)
import os print(os.path.abspath('基础代码练习.py')) print(os.path.abspath('E:/python/project/untitled/练习基础代码练习.py')) 输出: E:pythonprojectuntitled练习基础代码练习.py E:pythonprojectuntitled练习基础代码练习.py
②os.path.split()
#将路径分割成目录和文件名,并以二元组的方式返回
import os print(os.path.split('E:/python/project/untitled/练习基础代码练习.py')) 输出: ('E:/python/project/untitled', '练习基础代码练习.py')
③os.path.dirname() *****
#返回路径的目录,相当于os.path.split的第一个元素
import os print(os.path.dirname('E:/python/project/untitled/练习基础代码练习.py')) 输出: E:/python/project/untitled
④os.path.basename()
#返回路径的文件名,相当于os.path.split的第二个元素
import os print(os.path.basename('E:/python/project/untitled/练习基础代码练习.py')) 输出: 练习基础代码练习.py
⑤os.path.exists(path)
#判断路径是否存在,存在返回True,不存在返回False
import os print(os.path.exists('E:/python/project/untitled/练习/基础代码练习.py')) print(os.path.exists('E:/python/project/untitled/123.py')) 输出: True False
⑥os.path.isabs(path)
#判断一个路径是否为绝对路径,是返回True,不是返回False
⑦os.path.isfile(path) *****
#如果path是一个存在的问及那,返回True,否则返回False
⑧os.path.isdir *****
#如果path是一个存在的目录,则返回True,否则返回False
⑧os.path.join() *****
#根据平台的分隔符,可进行目录的拼接
import os ret = os.path.join('E:/python/project/untitled/','aaa','练习') print(os.path.abspath(ret)) 输出: E:pythonprojectuntitledaaa练习
⑨os.path.getatime()
#返回path所指向的文件或者目录的最后访问时间
⑩os.path.getmtime(path)
#返回path所指向的文件或者目录的最后修改时间
⑪os.path.getsize() *****
#返回文件和目录的大小(目录的大小固定为4096 )
import os print(os.path.getsize('E:/python/project/untitled/练习/基础代码练习.py')) print(os.path.getsize('E:/python/project/untitled/day01')) print(os.path.getsize('E:/python/project/untitled/day03')) print(os.path.getsize('E:/python/project/untitled/day02')) 输出: 69750 4096 4096 4096
补充:获取到程序项目目录(最终版,不再需要品阶了)
import os print(__file__) print(os.path.dirname(__file__)) #获取当前文件的上一级目录 print(os.path.dirname(os.path.dirname(__file__))) #获取到项目目录 输出: E:/python/project/untitled/练习/基础代码练习.py E:/python/project/untitled/练习 E:/python/project/untitled
4.序列化
即得到一个序列的结果,或者将一个序列改变为其他的
1)序列:一般一个有序的结构就是一个序列,但是一般值的序列是可以通过索引取访问的,如列表、元组、字符串(字典不可以使用索引访问)
2)在序列化中序列:只指字符串,例如进行了一系列操作,得到了一个字符串的结果。这个过程就叫做序列化
一般是将字典、列表、数字、对象等数据类型转化为字符串的过程,就叫做序列化
3)为什么要序列化:
①若要把内容写入文件,可以使用序列化
②当使用网络传输数据的时候,使用序列化
4)反序列化
将字符串转化为字典、列表、数字、对象等数据类型的过程叫做反序列化
5)
#补充:可以利用强转的方式,将一个字典或者列表转化为字符串类型
dic = {'k':'v'}
lst = ["阿狸",'泽拉斯','塞拉斯']
print(str(dic),type(str(dic)))
print(str(lst),type(str(lst)))
print([eval(str(dic))])
输出:
{'k': 'v'} <class 'str'>
['阿狸', '泽拉斯', '塞拉斯'] <class 'str'>
[{'k': 'v'}]
#虽然可以使用eval()进行反序列化但是eval()不能随便使用
6)json模块
①json.dumps() ---------序列化
#将字典数据类型,转化为字符串(通过dumps转化的字符产都带双引号)
dic = {'九尾妖狐':'阿狸','远古巫灵':'塞拉斯','光辉女郎':'拉克丝'}
ret_str = json.dumps(dic)
print(ret_str,type(ret_str))
输出:
{"u4e5du5c3eu5996u72d0": "u963fu72f8", "u8fdcu53e4u5debu7075": "u585eu62c9u65af", "u5149u8f89u5973u90ce": "u62c9u514bu4e1d"}
<class 'str'>
②json.loads()----------反序列化
import json dic = {'九尾妖狐':'阿狸','远古巫灵':'塞拉斯','光辉女郎':'拉克丝'} ret_str = json.dumps(dic) print(ret_str,type(ret_str)) ret_dit = json.loads(ret_str) print(ret_dit) print(type(ret_dit)) 输出: {"u8fdcu53e4u5debu7075": "u585eu62c9u65af", "u4e5du5c3eu5996u72d0": "u963fu72f8", "u5149u8f89u5973u90ce": "u62c9u514bu4e1d"} <class 'str'> {'远古巫灵': '塞拉斯', '九尾妖狐': '阿狸', '光辉女郎': '拉克丝'} <class 'dict'>
③json.dump()
#将一个字典以字符串的数据类型写入到文件中
import json dic = {'九尾妖狐':'阿狸','远古巫灵':'塞拉斯','光辉女郎':'拉克丝'} with open('dump.txt','w') as f: json.dump(dic,f)
④json.load()
#从文件中读取字符串并转化为其原本的类型
import json dic = {'九尾妖狐':'阿狸','远古巫灵':'塞拉斯','光辉女郎':'拉克丝'} with open('dump.txt','r') as f: print(json.load(f)) 输出: {'九尾妖狐': '阿狸', '远古巫灵': '塞拉斯', '光辉女郎': '拉克丝'}
7)pickle模块
pickle模块的方法和json的一模一样,但是pickle支持python几乎所有的数据类型,而json只支持字符串、列表、元组;但是json可以跨语言传输数据,而python不能够跨语言传输数据
练习:
1)计算器
2)发红包
3)计算时间差:计算两个时间之间的格式化时间差
4)统计文件夹中所有文件的总大小