1. 梯度下降
沿着目标函数梯度的反方向搜索极小值。
![]()
式中,$ heta$是模型参数,$J( heta)$目标函数(损失函数),$eta$是学习率。

2. 随机梯度下降(SGD)
每次随机选定一小批(mini-batch)数据进行梯度的计算,而不是计算全部的梯度。所有小批量数据都训练完,我们称为完成了一个迭代期(epoch)。
![]()
3. Momentum
想象损失函数是一个山谷,一个球从山谷滑下来,在一个平坦的地势,球的滑动速度会慢下来,可能会陷入一些鞍点或局部最小值,如下图(左)所示。这时候给它增加动量就可以让高处滑落的势能转化为平地滚动的动能,相当于利用惯性增加了小球在平地滑动的速度,从而帮助其跳出鞍点或局部极小点。怎么计算动量呢?动量的计算基于前面的梯度,也就是参数更新不仅基于当前的梯度,也基于之前的梯度,如下图(右)所示。
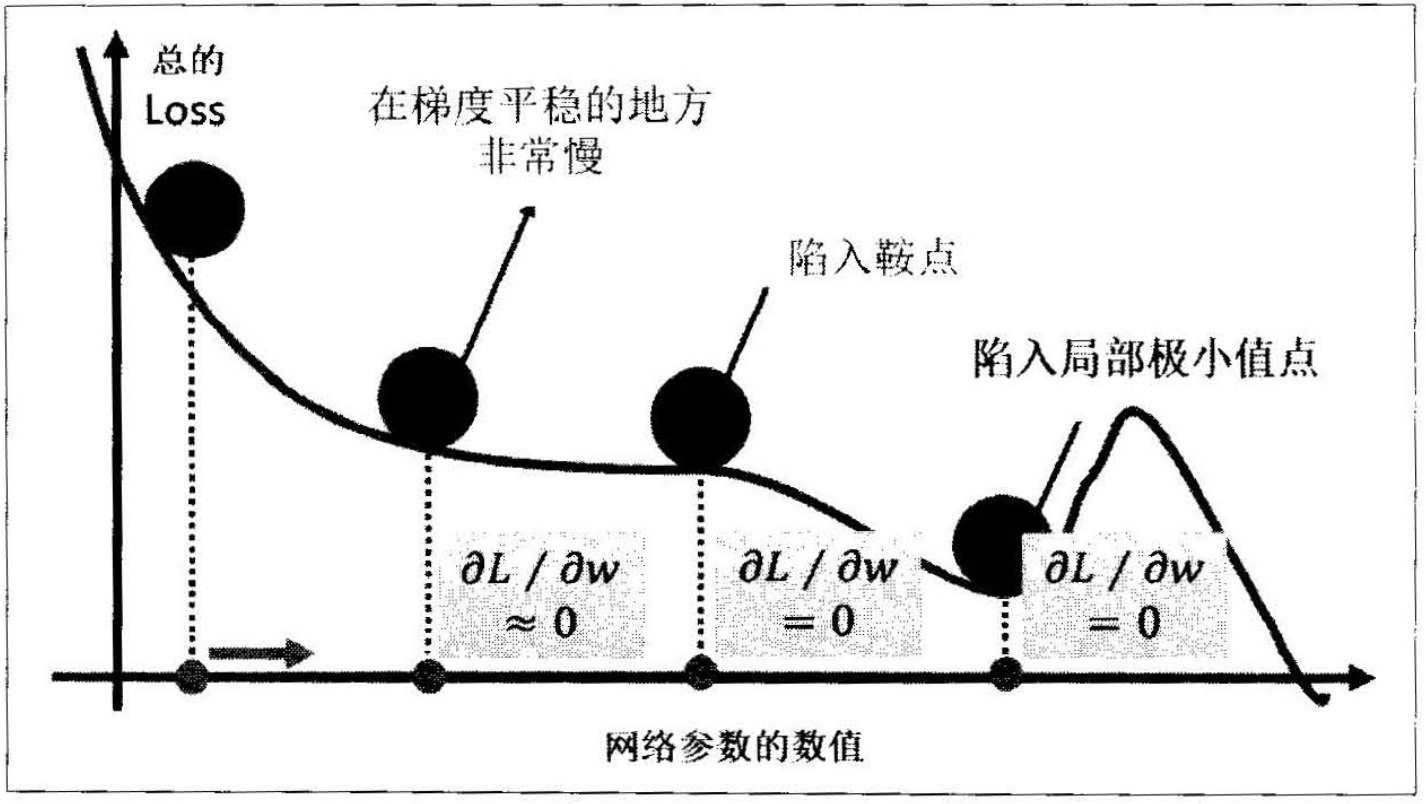
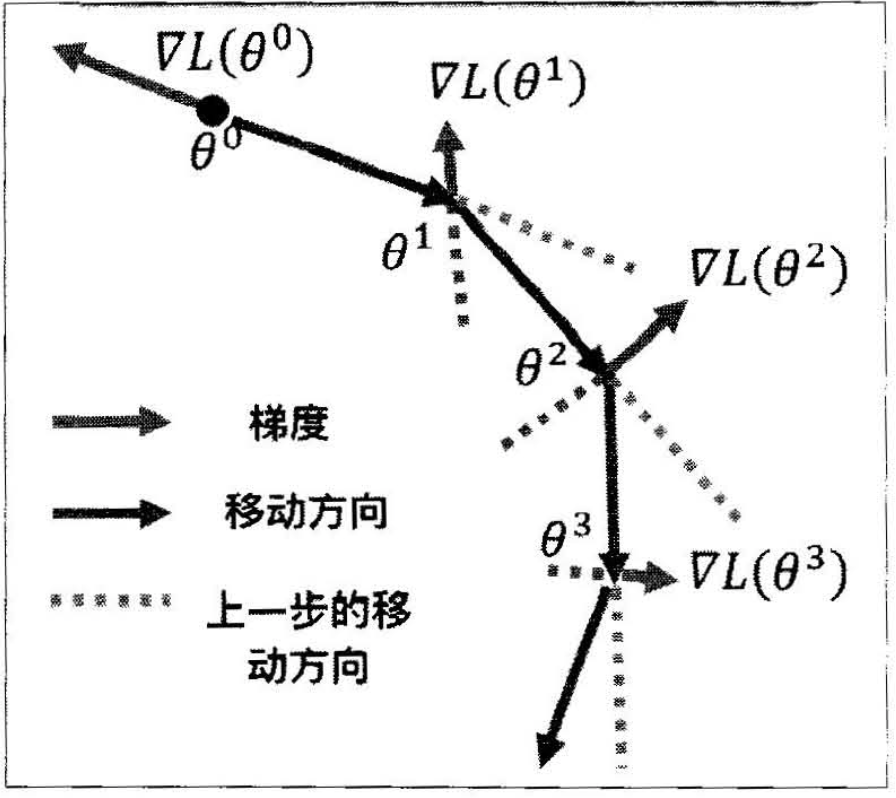
(a) 增加动量 (b) 动量的计算
模型参数更新公式:
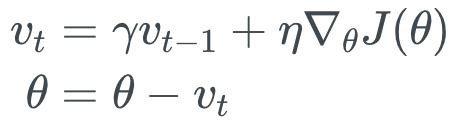
Momentum梯度下降方法在搜索极小值时,若不发生震荡,则加动量可起到加速收敛的效果;若发生震荡,则加动量可起到减少震荡的效果。具体可参考这篇博客。
4. Nesterov accelerated gradient (NAG)
NAG方法和momentum方法相似。momentum方法计算的是当前位置的梯度,NAG方法计算的是经过更新之后的位置的梯度,其参数更新公式为

经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。
5. Adagrad
上文提到的梯度下降方法中,模型所有的参数在每次更新时使用的是相同的学习率,在Adagrad算法中,每个参数的学习率各不相同。计算某参数的学习率时需将该参数前面所有时间步的梯度求和,随着时间步的增加,学习率将减小。

式中,$ heta_{t,i}$表示第$t$时间步的第$i$个参数,$g_{t,i}$表示第$t$时间步的第$i$个参数的梯度。Adgrad方法中,学习率一直在衰减,所以可以起到抑制震荡的作用,一个简单的例子可以参考这篇文章。
6. RMProp
Adagrad方法的学习率有时衰减得太快了,RMProp改善了这个问题。
![]()
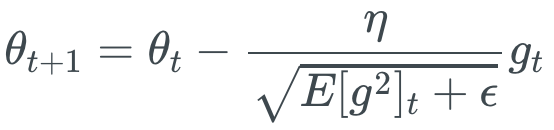
式中,$gamma$常设置为0.9,$ heta$常设置为0.001。
越靠前面的梯度,对学习率的影响越小,这样可以避免学习率过快衰减。
7. Adam
Adam方法可以看作是RMProp方法加上动量(momentum)的学习方法。

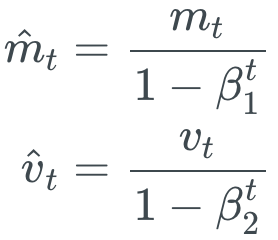
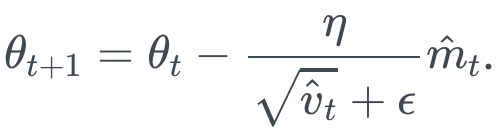
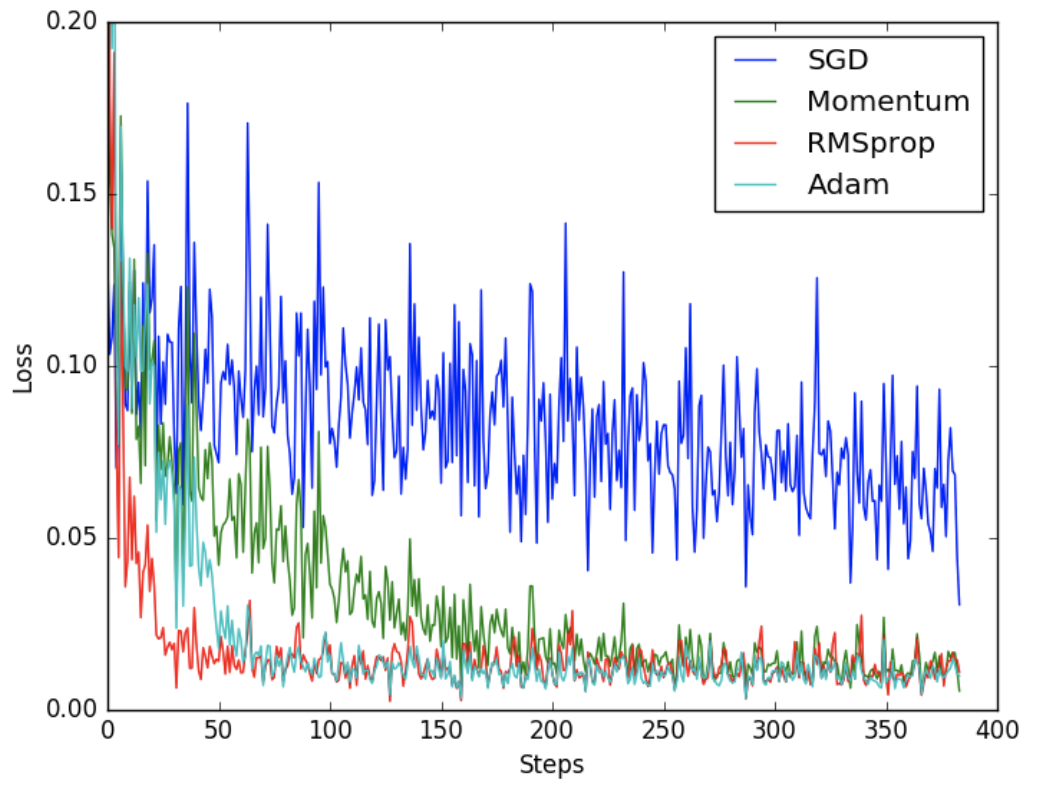
8. 各方法收敛效果比较[3]
代码:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
# torch.manual_seed(1) # reproducible
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
# put dateset into torch dataset
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
# default network
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
if __name__ == '__main__':
# different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss
# training
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
收敛效果比较:
参考文献
[1] An overview of gradient descent optimization algorithms
[2] 深度学习之PyTorch. 廖星宇.
[3] optimizer优化器
[4] 比Momentum更快:揭开Nesterov Accelerated Gradient的真面目
[6] 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)