三、Python数据类型 列表 list
==列表 list:
问题:如何将计算机运算的数据,临时存入一个地方,同时又方便添加,删除,修改等操作?
程序:数据、算法组成。
Memory 内存 容器
作用:存储数据
列表的定义:
列表是一种容器
列表是序列的一种
列表是可以被改变的序列
列表中由一系列特定元素组成的,元素与元素之间可以没有任何关联关系,但他们之间有先后顺序关系
1、列表的构造函数 list:
list() 生成一个空的列表,等同于[]
list(iterable) 用可迭代对象创建一个列表
示例: L = list() #L绑定空列表 L = list("hello") #L绑定[‘h','e','l','l','o'] L = list(range(1,10,2)) >>> type(L) <class 'list'> >>> s = '123' >>> type('123') <class 'str'> >>> type(2.1) <class 'float'> >>> type(int) <class 'type'>
2、列表的运算:
算术运算符:+ += * *= 规则与字符串一致
+ 用于拼接列表
+= 用原列表与右侧列表拼接,用变量绑定拼接后的列表
* 生成重复的列表,列表中元素重复;
*= x *= y 等同于 x = x * y
>>> L = [1,2,3] >>> L += [4,5,6] >>> L [1, 2, 3, 4, 5, 6] >>> L += '789' >>> L [1, 2, 3, 4, 5, 6, '7', '8', '9'] >>> L += range(10,13) >>> L [1, 2, 3, 4, 5, 6, '7', '8', '9', 10, 11, 12] >>> str: + += * *= > < <= >= == != in /not in index/slice
3、列表的比较运算:
比较运算符: < <= > >= == !=
比较的规则同字符串的规则相同!
x = [1,2,3] y = [1,2,4] x != y #True x <= y #True y > x #True ['AB','abc','123'] < ['AB','123','abc'] #False [1,'two'] > ['two',1] #TypeError 类型不一样不能比较报错
4、列表的in /not in运算符:
作用:判断一个值是否存在于列表中。如果存在返回True,否则返回False;
not in 的返回值与in 运算符相反。
示例:2 in [1,2,3] #True '2' in [1,2,3] #False
5、列表是可迭代对象:
for x in [2, 3, 5, 7]: print(x) #x绑定列表内的元素
6、列表的索引操作:
语法:列表[整数表达式]
用法:等同于字符串的索引
索引分正向索引和反向索引,规则与字符串规则一致
IndexError: list index out of range 索引超出范围
列表的索引赋值:
列表是可变的,可以通过索引赋值改变列表中的元素
示例: >>> id(L) 2043281796552 >>> L = [1,2,3,4] >>> L[2] = 3.1 >>> L [1, 2, 3.1, 4] >>> id(L) 2043281796552 id(L) 打印列表L绑定的内存地址
7、列表的切片:
语法:
列表[:]
列表[::]
说明:列表的切片取值返回一个列表,规则等同于字符串切片规则。
示例: x=list(range(10)) k = x[1:9:2] #奇数 y = x[:] #复制x列表
8、列表的切片赋值:
语法:
列表[切片slice] = 可迭代对象
作用:
可以改变原列表的排列,可以插入数据和修改数据;
可以切片改变列表对应的元素的值;
重点说明:切片赋值等号的右侧必须是一个可迭代对象;
TypeError: can only assign an iterable 必须是可迭代对象
切片注意事项:
对于步长不等于1的切片赋值,赋值运算符的右侧的可迭代对象提供的数据元素的个数一定要等于切片的段数。
9、del 语句:
作用:del 可以用来删除列表元素
语句:
del 列表[索引]
del 列表[切片]
python3中常用的序列函数 len(x) 返回序列的长度 max(x) 返回序列的最大值元素 min(x) 返回序列中最小值的元素 sum(x) 返回序列中所有元素的和(元素必须是数) any(x) 真值测试,如果列表的其中一个元素为真值,则返回True; all(x) 真值测试,如果列表中的所有元素都为真值,则返回True,否则返回False; python3中常用的列表方法(metmod) 详见: >>> help(list) L.index(obj) 从列表中找出某个值第一个匹配项的索引位置; L.insert(index, obj) 将对象插入列表; L.count(obj) 统计某个元素在列表中出现的次数; L.remove(obj) 移除列表中某个值的第一个匹配项; L.copy() 复制此列表(只复制一层,不会复制深层对象); L.append(obj) 在列表末尾追加单个元素; L.extend(seq) 在列表追加另一个序列中的多个值,类似拼接+; L.clear() 清空列表,等同于L[:] = []; L.sort(cmp=None, key=None, reverse=False) 对原列表进行排序,默认升序排列; L.reverse() 反向列表中元素,用来改变原列表的先后顺序; L.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值;
sorted 函数:
作用:用于生成一个已经排序后的列表。
格式: sorted(iterable, reverse=False)
reversed(seq)函数 :返回原序列反序的可迭代对象
示例: >>> sorted('abcde') ['a', 'b', 'c', 'd', 'e'] >>> sorted('abcde',reverse=True) ['e', 'd', 'c', 'b', 'a'] L = [7, 9, 5, 1, 3] L2 = sorted(L) #L2 = [1, 3, 5, 7, 9] L3 = sorted(L, reverse=True) #L3 = [9, 7, 5, 3, 1] for x in reversed(L): print(x) #3 1 5 9 7
10、字符串的文本解析方法 split和join方法
S.split(sep=None) 将字符串S使用sep作为分隔符分割S字符串,返回分割后的字符串列表,当不给定参数时默认用空白字符作为分隔符分割;
S.join(iterable) 可迭代对象中提供的字符串,返回一个中间用S进行分隔的字符串;
示例 S = 'Beijing is capital' L = S.split(' ') #L= ['Beijing', 'is', 'capital'] L = ["C:", "Windows", "System32"] S = '\'.join(L) #S=r"C:WindowsSystem32"
11、深拷贝 deep copy 和浅白拷贝 shallow copy
浅拷贝 shallow copy 说明: 浅拷贝是指在复制过程中,只复制一层变量,不会复制深层变量绑定的对象的复制过程。 L = [3.1, 3.2] L1 = [1, 2, L] L2 = L1.copy() #浅拷贝,只复制一层 print(L1) #[1, 2, [3.1, 3.2]] print(L2) #[1, 2, [3.1, 3.2]] L[0] = 3.14 print(L1) #[1, 2, [3.14, 3.2]] print(L2) #[1, 2, [3.14, 3.2]] >>> id(L) 1923604915144 >>> id(L1) 1923611021128 >>> id(L2) 1923611076360 >>> id(L1[2]) 1923604915144 >>> id(L2[2]) 1923604915144
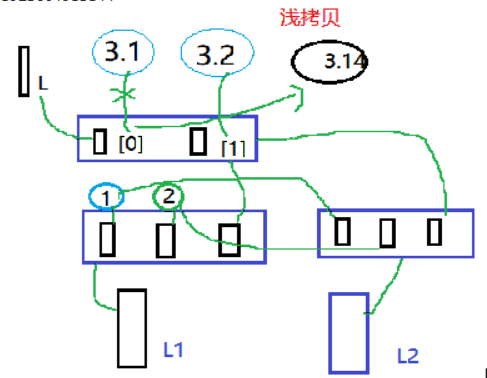
深拷贝 deep copy 说明: 对所有可变对象进行层层复制,实现对象的各自独立; import copy #导入复制模块 L = [3.1, 3.2] L1 = [1, 2, L] L2 = copy.deepcopy(L1) #实现深拷贝 print(L1) #[1, 2, [3.1, 3.2]] print(L2) #[1, 2, [3.1, 3.2]] L[0] = 3.14 print(L1) #[1, 2, [3.14, 3.2]] print(L2) #[1, 2, [3.1, 3.2]] #L2此列表不受影响
12、列表推导式 list comprehesion
列表推导式是用可迭代对象依次生成带有多个元素的列表的表达式
作用:用简易方法生成列表
语法:
[表达式 for 变量 in 可迭代对象]
或
[表达式 for 变量 in 可迭代对象 if 真值表达式] #(说明if 真值表达式返回True 才执行之前的表达式)
示例: # 生成一个列表,此列表内的数值是1~9的平方 L = [x ** 2 for x in range(1, 10)] 老方法: L = [] for x in range(1, 10): L.append(x ** 2) #用列表推导式生成1~100内的奇数的列表 1. L = [x for x in range(1, 100, 2)] 2. L1 = [x * 2 + 1 for x in range(50)] 3. L2 = [x for x in range(100) if x % 2 == 1]
列表推导式的嵌套:
语法:
[表达式 for 变量1 in 可迭代对象1 if 真值表达式1 for 变量2 in 可迭代对象2 if 真值表达式2 ...]
示例: #用字符串“ABC”和“123”生成如下列表:['A1', 'B2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3'] L = [x + y for x in "ABC" for y in "123"]
四、Python数据类型 元组tuple
1、元组 tuple
定义:元组是不可改变的序列,同list一样,元组是可以存放任意类型的容器;
2、元组的表示方法:
用小括号()括起来,单个元素括起来后加逗号(,)区分单个对象还是元组;
创建空元组的字面值: t = () #t绑定空元组 创建非空元组 t = 200, t = (20,) t = (1, 2, 3) t = 100, 200, 300 type(x) 函数用来返回x的类型
3、元组的构造(创建)函数 tuple
tuple() 生成一个空的元组,等同于()
tuple(iterable) 用可迭代对象生成一个元组
示例: t = tuple() t = tuple([2,3,5,7]) t = tuple(range(10))
4、元组的运算:
元组的运算: + 加号用于元组的拼接操作 * 税号 用于原元组生成重复的元组 += *= 元组的比较运算: > >= < <= == != 规则与列表的比较规则完全相同 ... 示例:(1,2,3)< (1,3,2) #True (1,2,3)!= (1,3,2) #True (1, '二') != ('二', 1) #True
5、in / not in 运算符:
in / not in 运算符: 与列表的in / not in 规则完全相同 2 in (1, 2, 3, 4) #True '2' not in (1, 2, 3, 4) #True
6、索引和切片:
索引:
元组[整数]
切片:
元组[整数:整数]
元组[整数:整数:整数]
规则同字符串的切片规则
元组不支持索引赋值和切片赋值
7、元组的方法:
T.index(v[, begin[, end]]) 返回对应元素的索引下标,begin为开始索引,end为结束索引,v不存在时触发ValueErorr错误;
T.count(x) 返回元组中的对应元素个数;
序列的种类: 有序排列
字符串 str, 列表 list, 元组 tuple,
字节串 bytes, 字节数组 bytearray,
能用于序列的函数总结:
len(x),man(x),min(x),sum(x),any(x),all(x)
str(obj) 将对象转为字符串
list(iterable) 将可迭代对象转为列表
tuple(iterable) 将可迭代对象转为元组
reversed(seq) 返回反向顺序的可迭代对象(反转)
sorted(iterable, reverse=False) 排序,返回列表
五、Python数据类型 字典dict
1、字典 dict:
什么是字典?
1.字典是一种可变的容器,可以存储任意类型的数据;
2.字典中的每个数据都是用“键”进行索引,而不象序列可以用下标来进行索引;
3.字典中的数据无先后顺序关系,字典的存储是无序的,
4.字典中的数据以键(key)-值(value)对形式进行映射存储;
5.字典的键不能重复,必需唯一,且只能用不可变类型作为字典的键;
2、字典的字面值表式:
{} 括起来,以冒号(:)分隔键-值对,各键-值对用逗号分隔开
创建空字典: d = {} #空字典 创建非空字典: d = {'name': 'tarena', 'age': 15} d = {1:'星期一', 2:'星期二'}
3、字典的构造(创建)函数 dict:
dict() #创建空字典,等同于 {}
dict(iterable) 用可迭代对象初始化一个字典
dict(**kwargs) 关键字传参形式生成一个字典
>>> bool({}) False 示例: d = dict() d = dict([('name', 'tarena'),('age', 15)]) d = dict(name='tarena', age=15) #关键字传参 d = dict(name=[1,2,3,4], age=[5,6,7,8])
4、字典的基本操作:
字典的基本操作: 字典的键索引: 用[]运算符可以获取和修改键所对应的值 语法: 字典[键] 示例: d = {'name': 'tarena', 'age': 15}
添加/修改字典的元素:
字典[键] = 值
示例:
d = {}
d['name'] = 'tarena'
键索引赋值说明:
当键不存在时,创建键并绑定键对应的值,当键存在时,修改键绑定的对象;
5、删除字典的元素:
del 语句 可以用来删除字典的键
语法:
del 字典[键]
示例: d = {1:'星期一',2:'星期二'} del d[2]
6、in /not in 运算符(成员资格判断运算符)
1.可以用in运算符来判断 一个键是否存在于字典中,如果存在则返回True,否则返回False;
2.not in 与in 相反;
>>> d = {1:'one', 2:'Two', '三':'three'}
>>> 1 in d
True
>>> 3 in d
False
>>> 'one' in d
False
>>> '三' in d
True
>>>
7、字典的迭代访问:
字典的可迭代对象,字典只能对键进行迭代访问;
>>> d {1: 'one', 2: 'Two', '三': 'three'} >>> for k in d: ... print(k, ':', d[k], end=' ') ... 1 : one 2 : Two 三 : three >>> 可以用于字典的内建(built-in)函数: len(x) 返回字典的健值对的个数 max(x) 返回字典的键的最大值 min(x) 返回字典的键的最小值 sum(x) 返回字典的键的和 any(x) 真值测试,如果字典中的一个键为真,则结果为真 all(x) 真值测试,字典中所有键为真,则结果才为真 字典方法: D代表字典对象 D.clear() 清空字典 D.pop(key) 移除键,同时返回此键所对应的值 D.copy() 返回字典D的副本,只复制一层(浅拷贝) D.update(D2) 将字典D2合并到D中,如果键相同,此键的值取D2 D.get(key,default) 返回键key所对应的值,如果没有此键,则返回default D.keys() 返回可迭代的dict_keys集合对象 D.values() 返回可迭代的dict_values值对象 D.items() 返回可迭代的dict_items对象 d = {'a': 'one', 'b': 'Two', 'c': 'three', 1: 'name'} >>> for k,v in d.items(): ... print('键值:',k, '值为:',v) ... 键值: a 值为: one 键值: b 值为: Two 键值: c 值为: three 键值: 1 值为: name >>>
8、字典推导式:
字典推导式是用可迭代的对象依次生成字典的表达式;
语法:
{ 键表达式:值表达式 for 变量 in 可迭代对象 [if 真值表达式] }
注:[] 及其中的内容代表可省略
说明:
1.先从可迭代对象中取值
2. 用变量绑定
3. 用if进行条件判断,如果为真值则执行下一步
4.执行’键表达式‘和'值表达式' 然后加入到新字典中
示例: 生成一个字典,键为1-9的整数奇数,值为键平方 d = {x: x ** 2 for x in range(1,10) if x % 2 == 1} >>> L = ['tarena', 'china', 'beijing'] >>> {x:len(x) for x in L} {'tarena': 6, 'china': 5, 'beijing': 7} >>> #练习2 # No = [1001, 1002, 1005, 1008] # names = ['Tom', 'Jerry', 'Spike', 'Tyke'] # 用上面No列表 中的数据做为键,用names中的数据作为值 ,生成相应的字典: 方法一: >>>d = {No[i]: names[i] for i in range(len(No))} >>> d {1001: 'Tom', 1002: 'Jerry', 1005: 'Spike', 1008: 'Tyke'} >>> 方法三:用index反回No的索引下标 d = {n:names[No.index(n)] for n in No}
9、字典 与 列表区别:
1. 都是可变对象;
2. 索引方式不同,列表用整数索引,字典用键索引;
3. 字典的查看速度可能会快于列表(重要);
4.列表 的存储是有序的,字典的存储是无序的;
列表 和 字典的内部存储原理:
列表,顺序存储
字典,映射存储
1.容器类: 元组tuple 存储任意类型的数据,是不可改变序列,创建后无法添加和删除; 所有的序列都有相同的操作:+ += * *= ;< <= > >= == != ; in / not in ; 索引 index/ 切片 slice; 列表可以索引赋值和切片赋值; 2.字典dict : 任意类型数据,键-值对(key-value对) ,使用键访问值;字典是无序的,可变的容器;字典是映射存储,在查找、插入、添加速度快; 3.字典dict: 键索引 ;in /not in 运算符(判断键);内建函数 len(x) max(x),min(x)...; 4.del 语句可以删除字典的键; 5.字典的方法:d.clear() d.pop(key) d.copy() d.update(d2) d.get(key, default) d.keys() d.values() d.items(); D.clear() 清空字典 D.pop(key) 移除键,同时返回此键所对应的值 D.copy() 返回字典D的副本,只复制一层(浅拷贝) D.update(D2) 将字典D2合并到D中,如果键相同,此键的值取D2 D.get(key,default) 返回键key所对应的值,如果没有此键,则返回default D.keys() 返回可迭代的dict_keys集合对象 D.values() 返回可迭代的dict_values值对象 D.items() 返回可迭代的dict_items对象 for k,v in d.items(): 6.字典推导式 { key表达式:value表达式 for 变量 in 可迭代对象 if 真值表达式 } s.center(18)
六、Python数据类型 集合 set
1、集合简介 set:
集合是可变的容器;
集合内的数据对象都是唯一的(不能重复多次的);
集合是无序的存储结构,集合中的数据没有先后顺序关系;
集合内的元素必须是不可变的对象;
集合是可迭代对象;
集合是相当于只有键,没有值的字典(键则是集合的数据);
创建空的集合: set() 创建非空集合: s = {1,2,3} 集合的构造(创建)函数 set: set() 创建一个空的集合对象(不能用{}来创建空集合); set(iterable) 用可迭代对象创建一个新的集合; 示例: s = set() #空集合 s = {1, 2, 3, 4} s = set("ABC") #s = {'A', 'B', 'C'} s = set("ABCCBA") #s = {'A', 'B', 'C'} s = set({1:'一', 2:‘二’,5:‘五’}) #s = {1, 2, 5} s = set([1, 2, 3, 2, 4, 3]) #s = {1, 2, 3} >>> set(range(10)) {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} >>> s = {1, 2, (3.1, 3.2)} >>> s {1, 2, (3.1, 3.2)} >>>
2、集合的运算符:
交集,并集,补集,子集,超集,对称补集 交集& 与字符 :生成两个集合的交集 s1 = {1, 2, 3} s2 = {2, 3, 4} s3 = s1 & s2 #s3 = {2, 3} 并集| 或字符 : 生成两个集合的并集 s1 = {1, 2, 3} s2 = {2, 3, 4} s3 = s1 | s2 #s3 = {1, 2, 3, 4} 补集- : s1 = {1, 2, 3} s2 = {2, 3, 4} s3 = s1 - s2 #s3 = {1} 生成属于s1但不属于s2的所有元素集合; 对称补集^ 脱字符 : s1 = {1, 2, 3} s2 = {2, 3, 4} s3 = s1 ^ s2 #s3 = {1,4} 生成两个并集去除交集后的元素; 子集< :< 判断一个集合是别一个集合的子集; 超集> :> 判断一个集合是另一个集合的超集; == != : 判断集合是否相同; <= >= : 判断包含,被包含关系; {1,2,3} == {2,3,1} # True 集合是无序的。 {1, 2} != {3, 4} #True
3、in /not in 运算符:
判断一个元素是否存在于集合中(同其它容器类型的in相同);
集合和字典的优点: in / not in 运算符的查找速度快 集合的内建函数操作: len(x),man(x),sum(x),min(x),any(x),all(x) 集合的常用方法:增add,删remove,改modify,查find S.add(e) 在集合中添加一个新的元素e;如果元素已经存在,则不添加 S.remove(e) 从集合中删除一个元素,如果元素不存在于集合中,则会产生一个KeyError错误 S.discard(e) 从集合S中移除一个元素e,在元素e不存在时什么都不做; S.clear() 清空集合内的所有元素 S.copy() 将集合进行一次浅拷贝 S.pop() 从集合S中删除一个随机元素;如果此集合为空,则引发KeyError异常 S.update(s2) 用 S与s2得到的全集更新变量S S | s2 <!-- 以下内容不讲 --> S.difference(s2) 用S - s2 运算,返回存在于在S中,但不在s2中的所有元素的集合 S.difference_update(s2) 等同于 S = S - s2 S.intersection(s2) 等同于 S & s2 S.intersection_update(s2) 等同于S = S & s2 S.isdisjoint(s2) 如果S与s2交集为空返回True,非空则返回False S.issubset(s2) 如果S与s2交集为非空返回True,空则返回False S.issuperset(...) 如果S为s2的子集返回True,否则返回False S.symmetric_difference(s2) 返回对称补集,等同于 S ^ s2 S.symmetric_difference_update(s2) 用 S 与 s2 的对称补集更新 S S.union(s2) 生成 S 与 s2的全集</td>
集合是无序的,无法通过索引来修改,只能删除后再添加;
4、集合是可迭代对象:
用for语句可以得到集合中的全部数据元素;
s = {1, '二', 3.14, 'Four'}
for x in s:
print(x)
5、集合推导式:
集合推导式是用可迭代对象生成集合的表达式;推导式内的for 子句可以嵌套。
语法:
{ 表达式 for 变量 in 可迭代对象 [if 真值表达式]}
注:[] 括起的部分代表可省略
示例: >>> s = { x ** 2 for x in range(10)} >>> s {0, 1, 64, 4, 36, 9, 16, 49, 81, 25} >>> s = { x ** 2 for x in range(10) if x % 2 == 1} >>> s {1, 9, 81, 49, 25} >>>
frozen 冰冻 set集合
6、固定集合 frozenset: 不可变的集合
固定集合是不可变的,无序的,含有唯一元素的集合;
作用:
固定集合可作为字典的键,也可作为集合的值;
创建空的固定集合:
fz = frozenset()
创建非空的固定集合:
frozenset(iterable) 用可迭代对象创建集合。
示例: fz = frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> fz frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}) >>> d = {fz:'None'} >>> d {frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}): 'None'} >>> s = {fz,1,2,3} >>> s {frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}), 1, 2, 3} >>> >>> fz1 = frozenset([1,2,3,frozenset([1.1,2.2])]) >>> fz1 frozenset({1, 2, 3, frozenset({1.1, 2.2})}) >>> 固定集合的运算: 同set运算完全一致; &交集, |并集, -补集, ^对称补集, > ,>=, <, <=, ==, != in , not in 固定集合的方法: 相当于集合的全部方法去掉修改集合的方法
==总结:== 数据类型: 不可变的类型:bool, int, float, complex , str, tuple, frozenset, bytes; 可变的类型:list , dict, set, bytearray; 值: None, False, True 运算符:组成表达式使用,表达式是组成语句的; +,-,*,/, //,%,** >,>=,<,<=,==,!= not ,and,or in,not in &,|,-,^ +(正号),-(负号) 表达式: 100 100 + 200 len([1,2,3]) + max([1,2,3]) #函数调用是表达式 print('hello') 条件表达式:x if x > y else y 全部的推导式(列表,字典,集合):[x for x in range(5)] 语句:statement 表达式语句: print('hello world') 'hello' 赋值语句:创建变量(绑定对象)和修改变量 a = 100 a = b = c = 200 x , y , z = 100, 200, 300 if 语句: while 语句:可无限循环,也可根据可迭代对象循环 for 语句:访问可迭代对象的 break 语句: continue 语句: pass 语句: del 语句: 内建函数: len(x),max(x),min(x),sum(x),any(x),all(x) 构造函数: bool(x) int(x, base=10) float(x) complex(real=0, image=0) str(x) list(x) tuple(x) dict(x) set(x) frozenset(x) 数字处理函数: abs(x) 绝对值 round(x) 四舍五入 pow(x, y, z=0) 字符串相关函数: bin(x) 转二进制字符串 oct(x) 转八进制字符串 hex(x) 转十六进制 chr(x) 编码转字符 ord(x) 字符转编码 迭代器相关函数: range(start, stop, step) reversed(x) 反转 sorted(x) 排序 输入输出相关函数: input(x) 输入 print(...) 输出 详见: >>>help(__builtins__)