【声明:本篇博客转载自http://www.cnblogs.com/ljhdo/p/5149401.html】
最近一段时间的工作主要是与SQLSERVER数据库打交道,需要对SQLSERVER有一个比较全面的认识。故也在捉急的翻阅资料,学习这个经典的关系型数据库。
性能计数器(Performance Counter)是量化系统状态或活动的一个数值,Windows Performance Monitor在一定时间间隔内(默认的取样间隔是15s)获取Performance Counter的当前值,并记录在Data Collections中,通过Performance Monitor能够查看系统的性能数据,是故障排除的极佳工具。Performance Counter数量很多,如果不了解计数器的功能,在选择计数器时,往往不知所措。由于SQL Server 是IO密集型的应用程序,经常需要进行大量的读写操作,从Disk读取数据到内存,将内存中的数据写入到Disk,因此,Disk和内存是SQL Server的生命线,监控SQL Server 的性能,经常用到的性能计数器是Disk和内存。
一,Disk性能监控
1,Disk的结构
典型的机械Disk的结构主要有:磁头(head),磁道(track),扇区(sector),盘面(Platter),柱面(cylinder)和簇(cluster)。如图,
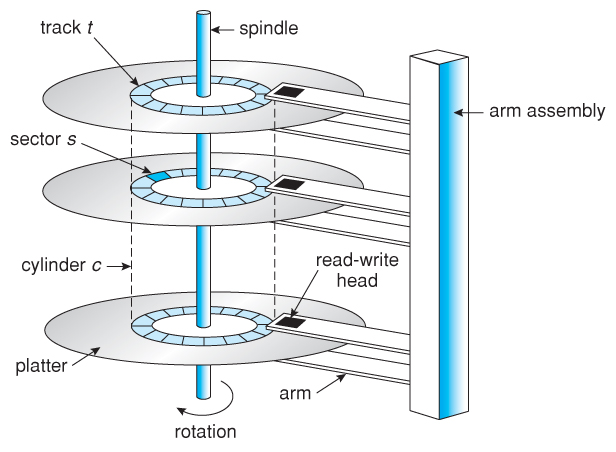
当磁盘旋转时,若磁头保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹叫做磁道。磁盘上的每个磁道被等分为若干个弧段,这些弧段是磁盘的扇区,每个磁道上的扇区数量是相等的,每个扇区存放512个字节的信息,磁盘驱动器在向磁盘读取和写入数据时,以扇区为单位。若干个连续的扇区组合为一个簇,文件存取是以簇为单位的。
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的"0"向中心开始编号,具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。所谓硬盘的CHS,是指Cylinder(柱面)、Head(磁头)、Sector(扇区),硬盘的容量=柱面数×磁头数×扇区数×512B。
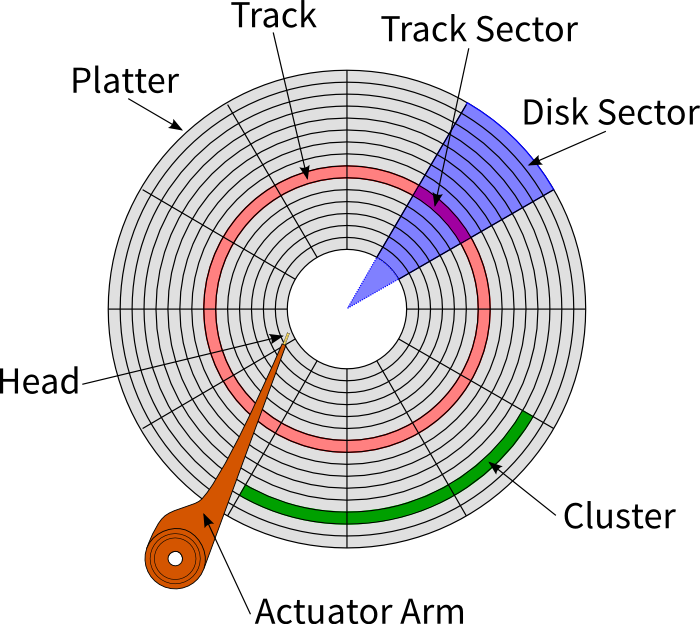
扇区是能独立寻址的最小单位,簇是资源分配的最小单位。Disk的一次读写操作,由寻道,旋转延迟和数据传输组成,由于寻道和旋转延迟占用了读写操作的大部分时间,Disk在执行每次读写操作时,采取就近原则,读写连续的N个扇区,读写的数据量是4KB的整数倍。
2,顺序读写和随机读写
随机读写是指数据分布在不同的磁道上,Disk的磁头必须移动磁道,才能读取到相应的数据;顺序读写是指数据分布在同一磁道的相邻扇区中,在读写数据时,Disk的磁头不需要移动磁道。由于,Disk的磁道移动是机械运动,“很慢”,占读写数据所用时间的绝大部分,因此,Disk的顺序读写速度远远高于随机读写速速,应尽量避免随机读写。Disk,固态硬盘盒内存的读写速度对比:

3,硬盘性能计数器
在OS Level上,Windows在一块物理硬盘上分成多个逻辑分区,每一个逻辑分区叫做一个Logical Disk,通过盘符标识,运行在Windows上的Application使用盘符来寻址。对于分配在同一块物理硬盘上的逻辑分区,共享物理硬盘的读写带宽,相当于在一块物理硬盘上工作。因此,Disk计数器分为两组:PhysicalDisk 和 LogicalDisk,LogcialDisk计数器记录每个逻辑分区的读写计数,用于分析特定的Application在不同的逻辑分区上的Disk IO活动和性能参数;PhysicalDisk计数器记录整个物理Disk的性能指标,用于了解Disk的响应速度,主要使用PhysicalDisk计数器,分析Disk的性能问题。
系统级经常用到的Disk性能计数器是PhysicalDisk计数器,LogcialDisk仅供参考:
- %Disk Time :表示Disk的忙碌程度,是Disk处理读写请求的时间的百分比,经常大于100%,建议使用%IdleTime反推出Disk处于读写状态的百分比
- Disk Reads/sec :每秒向Disk请求读操作的次数
- Disk Transfers/sec:Disk每秒执行读写操作的次数
- Disk Reads Bytes/sec :在Disk执行读操作时,每秒从Disk读取的字节数量
- Disk Bytes/sec:当Disk执行读写操作时,每秒从Disk读取到内存的,或从内存写入到Disk的字节数量,好的Disk,其值在20-40MB之间,差的Disk,其值在20MB以下。
- Avg. Disk Queue Length :提供Disk阻塞程度的主要度量值,表示在 sample interval期间,Disk等待处理的IO请求队列的平均长度,即等待被Disk处理的IO请求的数量,队列的长度要考虑到RAID,如果存储后台使用100块物理disk,那么该计数值达到100,这个值是正常的,理论上,每块物理disk的队列长度不应该长时间大于2.
- Avg. Disk sec/Transfer:Disk每一次读写操作所用的平均时间
- Avg. Disk sec/Read:Disk每一次读操作所用的平均时间
- Avg. Disk sec/Write:Disk每一次写操作所用的平均时间
avg.Disk sec/(Transfer,Read,Write),能够很好的反映Disk的IO速度,所以这三个计数值经常用来衡量Disk的IO速度:
- 很好:<10ms
- 一般:10-20ms
- 有点慢:20-50ms
- 非常慢:>50ms
二,系统物理内存性能计数器
SQL Server在运行的过程中,会持续地向内存中加载大量数据,如果数据长期驻留在内存中,那么SQL Server 不需要申请Disk IO请求,就能直接访问数据,快速响应用户的请求。如果SQL Server访问的数据不在内存中,将会产生一个Hard Page Fault,那么SQL Server首先指示存储引擎将数据页从Disk加载到内存中,产生PageIOLatch等待,等到数据被加载到内存之后,SQL Server在内存中访问数据,处理用户请求,由于Disk 的IO速度较慢,延迟高,大量的Hard Page Fault将严重影响SQL Server响应用户请求的速度,因此,常用的系统级内存计数器跟缺页中断有关:
- Memory:Page Faults/sec :每秒发生的Page Fault的数量,Page Fault包括Hard Fault 和 Soft Fault,Hard fault表示需要从Disk中读取数据页,Soft fault表示需要从Physical Memory中读取数据页,Soft Fault不会影响性能,由于Hard Fault需要访问Disk,会产生显著的延迟。
- Memory:Pages Input/sec:每秒发生的Hard Fault的数量,用于计算Hard Fault的百分比: Pages Input / Page Faults = % Hard Page Faults,如果百分比经常大于40%,说明系统需要经常访问Disk获取数据,在一定程度上说明系统存在内存压力。
- Memory:Pages/sec:每秒从Disk读取或写入Disk的Page数量,表示内存和Disk交互的Page的数量:将Page存储到Disk或从Disk读取数据到内存的Page的数量。
三,SQL Server的Buffer Manager计数器
Buffer Manager计数器用于监视SQL Server如何使用内存数据页和计划缓存,读取和写入数据页时的Disk IO。由于Buffer Pool是SQL Server内存最活跃,使用最多的部分,所以也是最容易出现性能瓶颈的部分,计数值尤其重要:
- Buffer Cache hit ration:从Buffer Pool中直接读取,不需要从Disk中读取的数据页的百分比,也叫命中率,这个计数器表示,在SQL Server读取数据时,数据存在于内存中,跟数据驻留在内存中的时间和内存压力关系不大,仅供参考。
- Page Writes/sec:每秒写入到Disk的数据页数,和内存使用关系不大,跟用户修改的数据量有关
- CheckPoint Pages/sec:将数据刷新到Disk的Dirty Pages的数量,和内存使用关系不大,跟用户修改的数据量有关,如果用户对数据库做了很多修改操作,那么内存中修改过的数据脏页就会比较多,每次刷新的脏页数量就会比较大
- Lazy Writes/sec:被LazyWriter刷新的buffer数量,如果是脏页,那么将buffer写入到Disk,并将buffer空间标记为Free,如果不是脏页,那么该buffer空间也被标记为Free,LazyWriter的作用是维护一定数量的Free buffer,SQL Server使用Free buffer来加载新的数据页。
- Page Life Expectancy:PLE,数据页驻留在内存中的时间。如果SQL Server没有新的内存需求,或有空闲的内存来完成新的内存需求,那么Lazy Writer不会被处罚,Page会一直驻留在Buffer Pool中,那么Page Life Expectancy会维持在一个比较高的水平;如果Page Life总是高高低低,表明SQL Server存在内存压力。PLE的参考数值是:Max Server Memory/4GB*300s,如果PLE值长期低于参考值,内存可能存在瓶颈。
- Page Reads/sec:每秒从Disk读取的数据页数,即物理读的次数,如果用户访问的数据都缓存在内存中,那么SQL Server不需要从物理Disk上读取页面。由于物理IO的开销大,Page Reads操作一定会影响SQL Server的性能。
- Free list stalls/sec:等待一个Free Page的请求数量,SQL Server申请从Disk加载一个Page到内存中,必须在内存中分配一个Buffer,Buffer Manager负责维护Free Buffer List,如果Free List没有任何Free Buffer,那么请求必须等待,直到有空闲的Buffer使用,才能将Disk中的Page加载到内存中。
经常使用后四种计数器,探测系统的内存压力,前三种,仅供参考,在此,感谢 wy123 的帮助。
四,SQL Server的Memory Manager计数器
Memory Manager计数器用于监控服务器内存总体使用情况,在一个非常繁忙的系统中,Lock内存和授予内存是常用的计数器:
- Total Server Memory (KB):SQL Server当前使用的内存总量
- Target Server Memory (KB):SQL Server能够使用的内存总量
- Lock Memory (KB):SQL Server用于锁的内存总量
- Grant Workspace Memory (KB):授予内存,SQL Server用于执行hash,排序和创建Index操作而消耗的内存总量
- Memory Grants Pending (KB):等待内存授予的进程数量,如果进程不能获得指定数量的内存,那么进程将不会开始执行
五,使用Performance Counter监控SQL Server数据库系统的整体性能
创建两个Data Set:Disk Activity,用于监控物理磁盘的活动;Memory Activity ,用于监控系统内存的Hard Fault和SQL Server的内存使用。

下文摘抄自《硬盘的读写原理》,作者是真实的归宿,写的非常详细:
访盘请求完成过程
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。 为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘 旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
即一次访盘请求(读/写)完成过程由三个动作组成:
- 寻道(时间):磁头移动定位到指定磁道
- 旋转延迟(时间):等待指定扇区从磁头下旋转经过
- 数据传输(时间):数据在磁盘与内存之间的实际传输
因此在磁盘上读取扇区数据(一块数据)所需时间:Ti/o=寻道时间 +旋转时间 + n *传输时间
磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。系统也以相同的顺序读出数据。读出数据时通过告诉磁盘控制器要读出扇区所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘控制器则直接使磁头部件移动到相应的柱面,选通相应的磁头,等待要求的扇区移动到磁头下。在扇区到来时,磁盘控制器对扇区进行读写操作。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
- 当一个数据被用到时,其附近的数据也通常会马上被使用。
- 程序运行期间所需要的数据通常比较集中。
- 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数,页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
拓展阅读:常用的系统内存性能计数器的描述
Page Faults/sec is the average number of pages faulted per second. It is measured in number of pages faulted per second because only one page is faulted in each fault operation, hence this is also equal to the number of page fault operations. This counter includes both hard faults (those that require disk access) and soft faults (where the faulted page is found elsewhere in physical memory.) Most processors can handle large numbers of soft faults without significant consequence. However, hard faults, which require disk access, can cause significant delays.
Page Reads/sec is the rate at which the disk was read to resolve hard page faults. It shows the number of reads operations, without regard to the number of pages retrieved in each operation. Hard page faults occur when a process references a page in virtual memory that is not in working set or elsewhere in physical memory, and must be retrieved from disk. This counter is a primary indicator of the kinds of faults that cause system-wide delays. It includes read operations to satisfy faults in the file system cache (usually requested by applications) and in non-cached mapped memory files. Compare the value of Memory\Pages Reads/sec to the value of Memory\Pages Input/sec to determine the average number of pages read during each operation.
Pages Input/sec is the rate at which pages are read from disk to resolve hard page faults. Hard page faults occur when a process refers to a page in virtual memory that is not in its working set or elsewhere in physical memory, and must be retrieved from disk. When a page is faulted, the system tries to read multiple contiguous pages into memory to maximize the benefit of the read operation. Compare the value of Memory\Pages Input/sec to the value of Memory\Page Reads/sec to determine the average number of pages read into memory during each read operation.
Pages/sec is the rate at which pages are read from or written to disk to resolve hard page faults. This counter is a primary indicator of the kinds of faults that cause system-wide delays. It is the sum of Memory\Pages Input/sec and Memory\Pages Output/sec. It is counted in numbers of pages, so it can be compared to other counts of pages, such as Memory\Page Faults/sec, without conversion. It includes pages retrieved to satisfy faults in the file system cache (usually requested by applications) non-cached mapped memory files.
参考文档:
Measuring Disk Latency with Windows Performance Monitor (Perfmon)
SQL Server disk performance metrics – Part 1 – the most important disk performance metrics