使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来。
首先进行url分析,可以看到:
歌手网页:

薛之谦网页:

可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 30 14:18:33 2017
@author: 24630
"""
import requests
from lxml import etree
import urllib.parse as urlparse
# 获得热门的前几个有封面的歌手
def get_info_artist(url):
html = requests.get(url).text
html=etree.HTML(html)
hotlist = html.xpath('//div[@class="hot-head clearfix"]/dl/dd/a[1]/@href')
return hotlist
def get_info_single(url):
html = requests.get(url).text
html=etree.HTML(html)
songlist = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/text()')
albumlist = html.xpath('//div[@class="song-item"]//span[@class="album-title"]/a[1]/text()')
downloadUrl = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@href')
#无法找到下一页的跳转连接
#next_page = //div[@class="page-inner"]/a[last()]/text()
print(len(songlist))
url = 'http://music.baidu.com/artist'
hotlist = get_info_artist(url)
#urljoin主要是拼接URL,
#它以base作为其基地址,
#然后与url中的相对地址相结合组成一个绝对URL地址。
#函数urljoin在通过为URL基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。
#需要注意的是:
#如果基地址并非以字符/结尾的话,那么URL基地址最右边部分就会被这个相对路径所替换。
#如果希望在该路径中保留末端目录,应确保URL基地址以字符/结尾。
for u in hotlist:
#获得单个歌手的链接
url_singer = urlparse.urljoin(url,u)
get_info_single(url_singer)
可以看到,我读完一页后,想要继续进行下一页的数据的获取就没那么容易了。

有时候显示:

至于怎么获得下一页的信息:

通过上面可以分析,上面三处有数据的地方分别是点击下一页的时候产生的,可以在上面找一下。
这个时候,可以分析到:
实际上,跳转路径的动态请求隐藏在:

这样一个路径下。
因此,实际上可以构建该路径进行获取歌曲信息。

可以看到,该路径下动态请求的页面是一个json格式数据,可以通过json解析,获取其中的html源码。
代码修改为:
import requests
from lxml import etree
import urllib.parse as urlparse
import json,re,os
import sqlite3
def writeDB(song_dict):
global num
c = conn.cursor()
sql = '''insert into baiduMusic (id, songName,singer,albumname,download) values (?,?,?,?,?)'''
para = (num,song_dict['歌曲'],song_dict['歌手'],song_dict['专辑'],song_dict['下载路径'])
c.execute(sql,para)
conn.commit()
num += 1
# 获得热门的前几个有封面的歌手
def get_info_artist(url):
html = requests.get(url).text
html=etree.HTML(html)
hotlist = html.xpath('//div[@class="hot-head clearfix"]/dl/dd/a[1]/@href')
return hotlist
def get_info_single(url):
re_com = re.compile('artist/(d+)')
ting_uid = re_com.findall(url)[0]
get_info_single_page(0,ting_uid)
def get_info_single_page(i,ting_uid):
page = 'http://music.baidu.com/data/user/getsongs?start={0}&ting_uid={1}'.format(i,ting_uid)
html = requests.get(page).text
html = json.loads(html)["data"]["html"]
html=etree.HTML(html)
songlist = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/text()')
albumlist = html.xpath('//div[@class="song-item"]//span[@class="album-title"]/a[1]/text()')
downloadUrl = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@href')
try:
singer = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@title')[0]
re_com = re.compile('(S+?)《')
#这种解析歌手的方法不好,为了省事先这么弄的
singer = re_com.findall(singer)[0]
except:
singer = ' '
print(singer)
for songName,album,download in zip(songlist,albumlist,downloadUrl):
song_dict = {}
song_dict['歌曲'] = songName
song_dict['歌手'] = singer
song_dict['专辑'] = album
song_dict['下载路径'] = download
writeDB(song_dict)
#歌曲都获取全了,即获得某一页歌曲数少于25
if (len(songlist) == 25):
get_info_single_page(i+25,ting_uid)
num = 1
if not os.path.isfile('test.db'):
conn = sqlite3.connect('test.db')
c = conn.cursor()
c.execute('''create table baiduMusic (id integer primary key,songName varchar(10),singer varchar(10),
albumname varchar(10),
download varchar(10));''')
conn.commit()
else:
conn = sqlite3.connect('test.db')
url = 'http://music.baidu.com/artist'
hotlist = get_info_artist(url)
#urljoin主要是拼接URL,
#它以base作为其基地址,
#然后与url中的相对地址相结合组成一个绝对URL地址。
#函数urljoin在通过为URL基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。
#需要注意的是:
#如果基地址并非以字符/结尾的话,那么URL基地址最右边部分就会被这个相对路径所替换。
#如果希望在该路径中保留末端目录,应确保URL基地址以字符/结尾。
for u in hotlist:
#获得单个歌手的链接
url_singer = urlparse.urljoin(url,u)
get_info_single(url_singer)
conn.close()
最终获得效果:
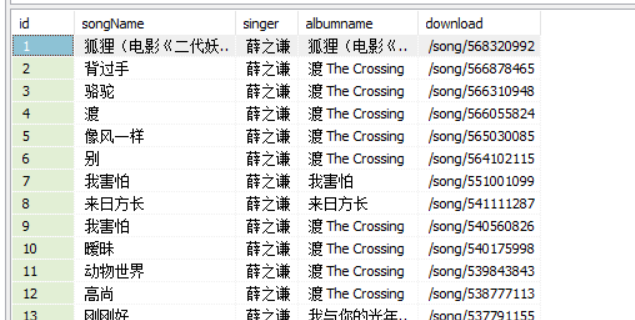
当然,上面的download链接是歌曲的跳转链接,如果需要下载的话,可以继续分析:
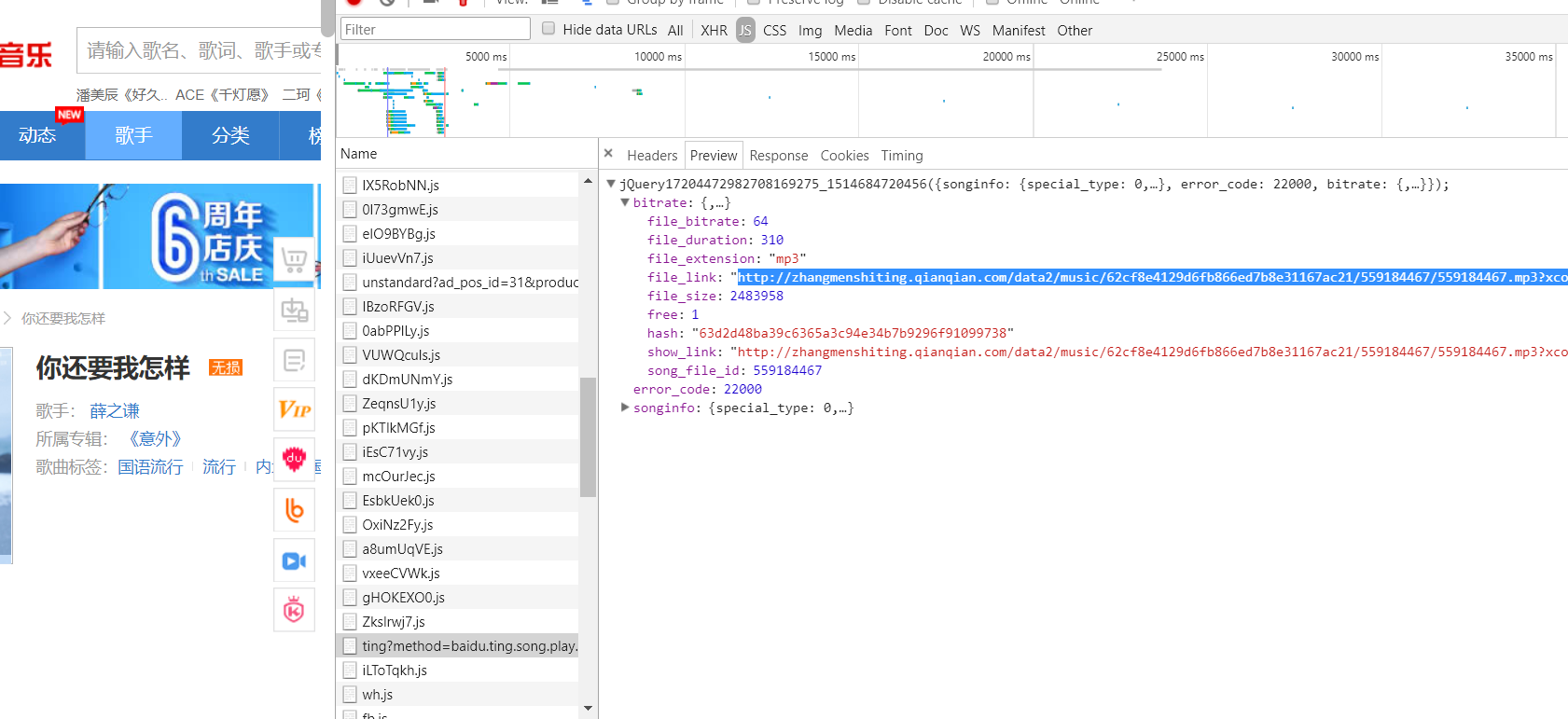
如上,可以继续分析如何构建歌曲文件的url,然后完成下载。